爬虫福音:Github星标14K+,一个开源的IP代理池
Posted Dream丶Killer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫福音:Github星标14K+,一个开源的IP代理池相关的知识,希望对你有一定的参考价值。
大家好,我是丁小杰!
时间过得真快,一眨眼就到了元宵节,大家记得吃元宵哦~
为什么要使用代理?
不知道大家在写爬虫时是否遇到过这样的情况,测试时爬虫可以正常工作,但运行一段时间,就会发现报错或是没有数据返回,网页可能会提示“IP访问频繁”。这就说明网站对IP方面是有反爬措施的(IP一定时间内的请求次数及速度)。如果超过了某个阈值,就会直接拒绝服务,也就是经常说的“封IP”。
这种情况下,就到了代理IP出场了。代理实际就是代理服务器,它的工作原理其实很简单,在我们正常请求一个网站时,是直接发送请求给Web服务器,Web服务器把响应数据传给我们。而用了代理IP,就像是在本机和Web服务器之间搭建了一个“桥”,此时本机会先向代理服务器发出请求,再由代理服务器发送给Web服务器。响应数据的返回也是同样的道理,都需要代理服务器来中转。这样Web服务器就不容易识别出本机IP了。
但代理IP也有优劣之分,以隐匿性来分有3种:高匿代理,普匿代理,透明代理。
接下来就看看 Github 热门的开源项目 ProxyPool ,如何使用吧!
ProxyPool简介
一个爬虫代理IP池,定时采集网上发布的免费代理并验证入库,定时检测代理的可用性,提供 API 和 CLI 两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
下载代码
通过 git clone 下载代码
git clone git@github.com:jhao104/proxy_pool.git
下载对应zip文件

安装依赖库
pip install -r requirements.txt
修改配置文件
打开代码文件中的 setting.py ,根据自己的需求修改项目配置。
# 配置API服务
HOST = "0.0.0.0" # IP
PORT = 5000 # 监听端口
# 配置数据库
DB_CONN = 'redis://:pwd@127.0.0.1:8888/0'
# 无密码
DB_CONN = 'redis://:@127.0.0.1:8888/0'
# proxy table name 表名(自己建的)
TABLE_NAME = 'use_proxy'
# 配置 ProxyFetcher
PROXY_FETCHER = [
"freeProxy01", # 这里是启用的代理抓取方法名,所有fetch方法位于fetcher/proxyFetcher.py
"freeProxy02",
# ....
]
运行项目
启动 redis 服务:redis-server.exe(可执行文件在 redis 安装路径下)。

1.启动调度程序
启动调度程序,在 Proxy_pool 项目路径下打开 cmd 输入:
python proxyPool.py schedule
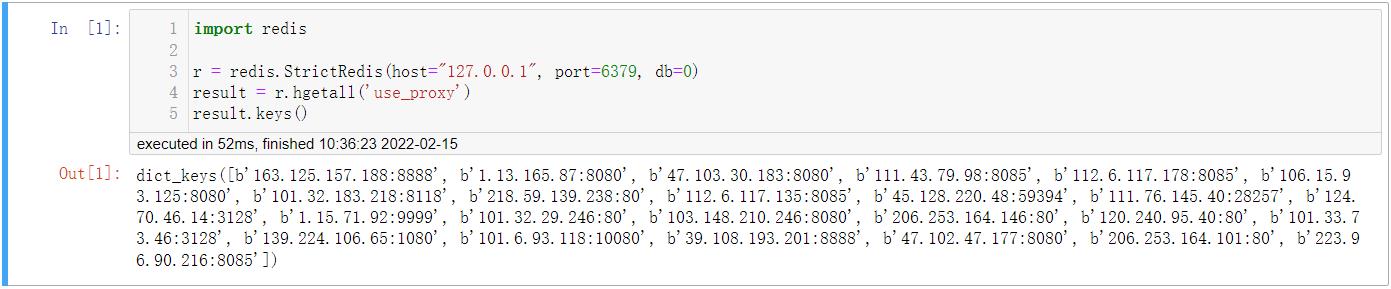
读取数据库中的代理。
import redis
r = redis.StrictRedis(host="127.0.0.1", port=6379, db=0)
result = r.hgetall('use_proxy')
result.keys()
2.启动webApi服务
python proxyPool.py server
启动web服务后, 默认配置下会开启 http://127.0.0.1:5010 的api接口服务:
| api | method | Description | params |
|---|---|---|---|
| / | GET | api介绍 | None |
| /get | GET | 随机获取一个代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /pop | GET | 获取并删除一个代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /all | GET | 获取所有代理 | 可选参数: ?type=https 过滤支持https的代理 |
| /count | GET | 查看代理数量 | None |
| /delete | GET | 删除代理 | ?proxy=host:ip |
在爬虫中使用
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy=".format(proxy))
# your spider code
def gethtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies="http": "http://".format(proxy))
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None
代理池中的代理毕竟是爬取的免费代理,IP质量那真是一言难尽,但也足够日常开发使用。
对于使用还有不懂的话,可以看一下完整文档。
项目地址:
| https://github.com/jhao104/proxy_pool |
|---|
对于刚入门 Python 或是想要入门 Python 的朋友,可以通过关注公众号“Python新视野”,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。
以上是关于爬虫福音:Github星标14K+,一个开源的IP代理池的主要内容,如果未能解决你的问题,请参考以下文章