Meta-learning原来有这么多用途,一文汇总元学习在5个问题中的应用
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Meta-learning原来有这么多用途,一文汇总元学习在5个问题中的应用相关的知识,希望对你有一定的参考价值。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
在Meta-learning核心思想及近年顶会3个优化方向一文中,我们从meta-learning的基础思想出发,并介绍了MAML经典模型,以及在此基础上最近3年学术界对meta-learning算法本身的不同角度优化。Meta-learning可以理解为是一个工具,它可以应用于很多不同的场景中,利用meta-learning两层优化目标的思路解决特定场景下的问题。本文梳理了业内近几年利用meta-learning解决不同场景问题的顶会论文,涉及meta-learning在域自适应、迁移学习、图学习、正负样本不均衡、知识蒸馏等多个场景的应用,帮助大家更深入的理解meta-learning的本质思想,以及如何在不同问题中应用meta-learning这个工具。
本篇文章的介绍过程中,默认已经理解了meta-learning的核心思想和原理,包括内循环、外循环等概念。如果对这些原理还不熟悉的同学,建议先阅读Meta-learning核心思想及近年顶会3个优化方向一文。
1. 在迁移学习场景中的应用
在迁移学习中,Pretrain-Finetune是一种常用的方式。这种方式的问题在于,经常需要尝试不同的迁移策略来达到最优效果。例如,某一层的参数是迁移还是随机初始化;当pretrain阶段模型和finetune阶段模型模型结构不一致时,pretrain模型某一层的参数应该迁移到finetune模型的哪一层;每层迁移的强度多大等。对这些策略的尝试,会耗费大量时间。
Learning What and Where to Transfer(ICML 2019)中提出基于meta-learning的迁移学习方法,利用meta-learning学习什么样的迁移策略能够达到最优效果。首先,本文的迁移方法采用了FITNETS: HINTS FOR THIN DEEP NETS(ICLR 2015)提出的思路,在finetune阶段通过对target模型参数和pretrain模型参数添加L2正则化损失,来控制target模型的某一层迁移pretrain模型的哪层参数、迁移的强度为多少。针对迁移目标的不同,又分为what to transfer和where to transfer。在What to transfer阶段,对每一个channel的迁移做一个权重学习,每个channel的权重是通过一个单独的网络输入图片在Source模型的输出计算得到的(T代表Target模型,S代表Source模型,与FitNet中的Guided和Hint相对应):
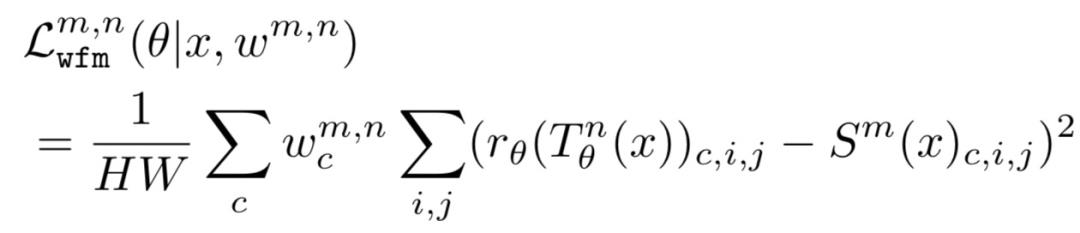
在Where to transfer阶段,主要决定Source模型到Target模型的迁移层pair,即Source模型的第i层参数要迁移到Target模型的哪一层。类似What to transfer,通过一个单独的网络学习(i,j)这组Source模型到Target模型pair对的迁移强度:
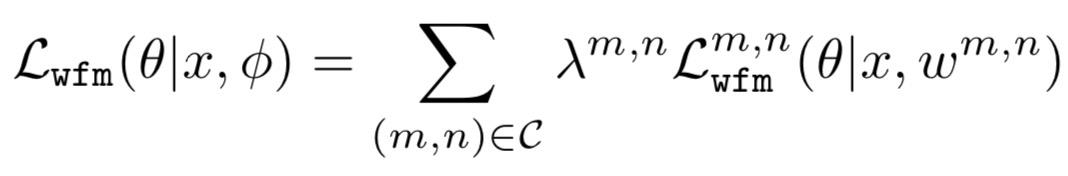
模型最终的损失函数可以表示为具体任务损失加上上述的迁移损失:
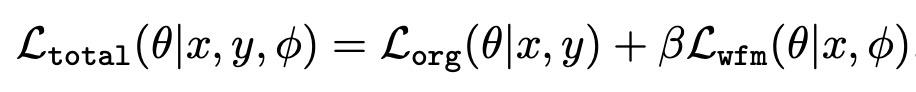
模型的训练过程采用了meta-learning的思想。内循环的目标为最小化总损失,外循环评估当前的迁移策略下训练出的模型,在目标任务上的效果。为了理解内循环和外循环在这里的含义,首先要明确这个模型的目的是什么。模型的目标是,通过以总loss为目标训练模型,能够达到在目标任务上最好的效果。这其实就是一个两层优化问题,总loss训练模型对应内循环,目标任务上效果最好对应外循环。通过这种方式,实现了迁移策略(即wfm损失中的各项参数)的自动学习。

2. 在Domain Adaptation场景的应用
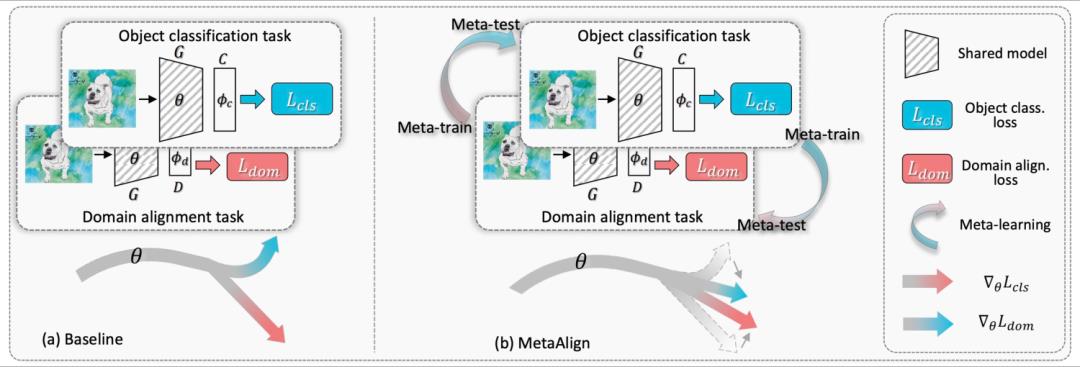
我们曾经在Domain Adaptation:缺少有监督数据场景下的迁移学习利器一文中介绍了多种域自适应顶会模型,meta-learning也被应用到了这个领域。在MetaAlign: Coordinating Domain Alignment and Classification for Unsupervised Domain Adaptation(CVPR 2021)中提出了利用meta-learning生成和目标任务相关的对齐后的表示。对Domain Adaptation还不了解的同学建立先去看一下Domain Adaptation:缺少有监督数据场景下的迁移学习利器这篇文章。在图像实体识别任务的Domain Adaptation中,传统的思路是利用对抗学习对齐source domain和target domain的特征表示。但是这种方法完全没有考虑下游任务,生成的表示在下游任务可能表现并不好。本文的目标是,生成能够让下游任务效果好的对齐表示。在meta-learning的思想中,这自然而然形成了内循环和外循环一个两层优化问题:内循环的优化目标是domain alignment,即生成两个domain对齐后的表示;外循环为利用对齐后的表示,评估该表示在目标任务上的效果。通过这种训练模式,domain alignment这一步可以更有针对性的生成服务于下游任务的表示,进而提升domain adapttaion在目标任务上的效果。
值得一提的是,这个团队通过对该方法结果的分析,发现经过meta-learning得到的对齐特征,会更注重对齐实体部分,而忽略背景部分。这也带来了该团队的另一篇工作ToAlign: Task-oriented Alignment for Unsupervised Domain Adaptation(NIPS 2021),感兴趣的同学可以阅读Domain Adaptation:缺少有监督数据场景下的迁移学习利器进一步了解。
3. 在图学习场景的应用
图学习方法的一种常见范式为,首先在大量无标签数据上预训练,再在下游目标任务上有标签数据上finetune。这种两阶段方法的问题是,两个阶段的优化目标不同,因此pretrain阶段得到的模型可能并不是最适用于下游任务的。Learning to Pre-train Graph Neural Networks(AAAI 2021)在图的pretrain阶段引入meta-learning的思想,在图的pretrain过程中同时模拟finetune过程,并利用MAML的思路以finetune后的效果作为外循环更新模型参数。
首先先不考虑meta-learning,介绍一下本文提出的图预训练方法。本文提出了node-level和graph-level两个pretrain优化目标,分别学习模型中的node aggregation对应的参数以及graph pooling对应的参数。Node-level任务是一个link prediction任务,即预测两个node之间是否连有边,并通过负采样构造负样本。Graph-level任务是一个图匹配任务,让图中所有节点pooling得到的embedding,和各个link predictoin任务中的节点pooling得到的embedding计算匹配loss,并通过random shifting的方式构造负样本。
接下来我们引入meta-learning。将link prediction任务划分成support set和query set。内循环中,使用support set中的link prediction任务loss,以及graph-level任务的loss更新模型得到临时参数;外循环中,使用query set中的节点构造的link prediction任务和graph-level任务评估当前临时参数的效果,并进一步更新模型。这个过程模拟了pretrain+finetune的过程,以finetune效果最优为目标。该方法的整体思路如下图,其中parent task指的是graph-level任务,child task指的是node-level任务。
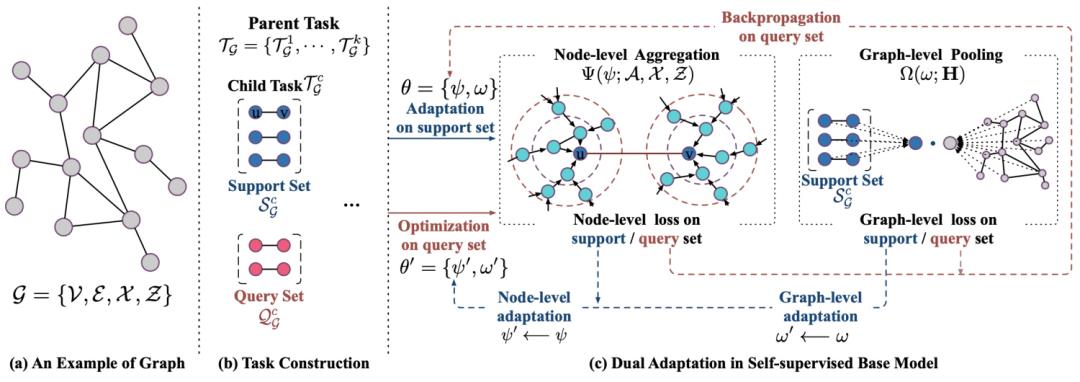
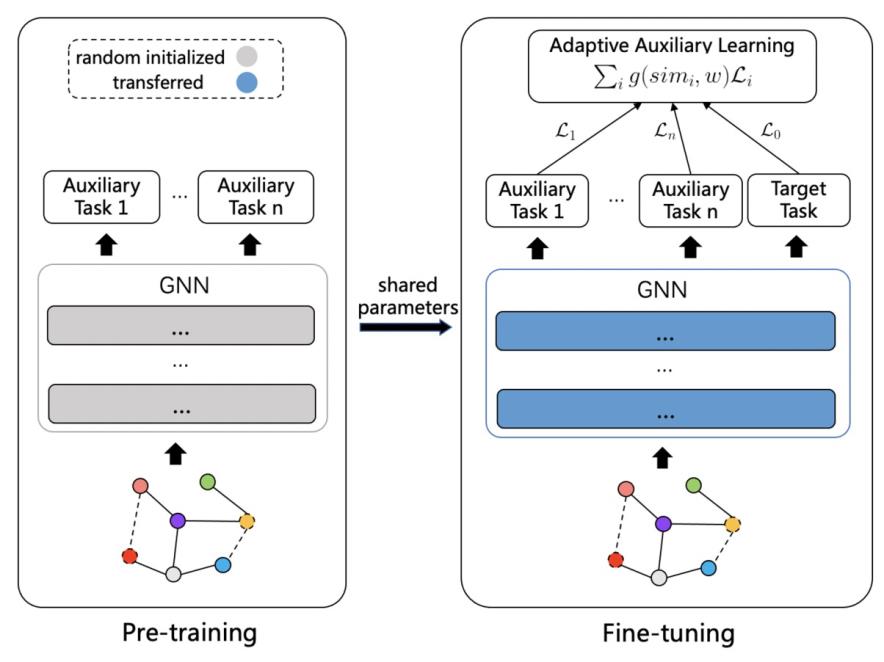
另一篇meta-learning在图学习的应用也是和迁移学习相关的,利用meta-learning学习pretrain阶段不同任务的权重,论文为Adaptive Transfer Learning on Graph Neural Networks(KDD 2021)。和上一篇文章不同的是,本文修改的是finetune阶段而非pretrain阶段。在finetune阶段,除了使用目标任务外,还会使用预训练阶段的多个辅助任务一起训练,并且给不同辅助任务设定不同的权重。这样相当于在finetune阶段进一步从辅助任务中提取信息,而提取这些信息的目标是让目标任务效果更好。
问题的关键就在于如何在finetune阶段得到各个辅助任务的权重。如果在模型训练过程中,两个task的梯度相似度较高,则表明这两个task的一致性较高。因此,本文提出的方法为根据目标任务和各个辅助任务提出的cosine相似度计算辅助任务权重。辅助任务权重采用一个NN模型拟合,NN模型输入为梯度cosine相似度,输出为辅助任务权重。这个NN模型的训练采用了meta-learning的思路。内循环使用目标任务loss+权重生成NN模型loss更新模型参数到一个中间参数;外循环使用目标任务loss评估当前权重NN模型的效果,并更新权重生成NN模型参数。
4. 在样本权重生成场景的应用
当训练样本中噪声比较大,有很多样本的标签标注有问题时,会严重影响模型的训练效果。一种常见的解决方法是sample-reweighting,如对于某些噪声样本给予较小的权重。Sample-reweighting一般需要根据每个样本的training loss作为输入,设计一个weighting生成函数,生成每个样本的weight。但是这种方法需要预先设计weighting函数。Meta-Weight-Net: Learning an Explicit Mapping For Sample Weighting(NIPS 2019)提出了一种利用meta-learning学习权重生成函数的方式。寻找分类模型最优参数的过程可以表示为如下优化目标:
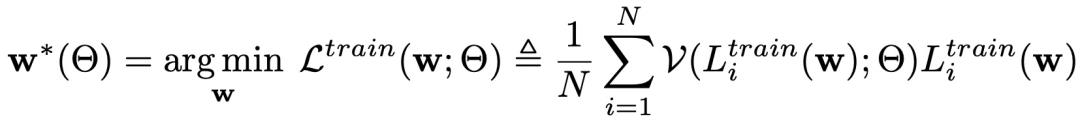
其中V代表权重生成函数,它是一个NN网络,输入某个样本的训练loss,输出该样本的权重,文中称其为meta-weight net。关键在于如何学习这个meta-weight net的参数。本文采用了meta-learning的思路,内循环为使用上面的优化目标更新几轮分类器模型参数(不包括meta-weight net的参数)得到模型的中间参数;外循环为评估当前模型在meta data(一组数量比较小的无噪声样本)上的效果,并以此为优化目标更新meta-weight net参数。这样训练得到的meta-weight net为使用其生成的权重训练模型,能够在无偏样本上表现更好。
5. 在知识蒸馏中的应用
知识蒸馏中一种常见的方法是teacher-student架构。首先用teacher模型(一般尺寸比较大的模型)在数据上训练,然后用student模型迁移teacher模型学习到的知识。这个迁移过程可以采用伪标签(pseudo label)的方式,即使用teacher模型预测训练数据得到teacher对每个样本的打分,再用这个打分作为student模型的预测目标,以此实现将teacher学到的信息蒸馏到student的目标。但是,这种方式使teacher和student模型训练是两个割裂的过程,teacher生成的pesudo label可能并不是最适用于student训练的目标。基于这个问题,Meta Pseudo Labels(CVPR 2021)提出了一种基于meta-learning的优化方法,利用meta-learning将teacher和student两个过程联合到一起,其核心思路是让teacher产出的pseudo label在student上的表现,反向作用于teacher。由于student模型是根据teacher产出的label进行训练的,因此student最优参数可以看成是一个关于teacher的函数,可以表示为如下公式,进而可以用student的表现反向更新teacher的参数。
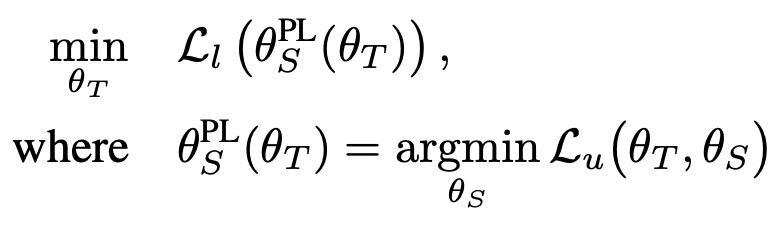
该方法的整体流程为,使用当前teacher产出的pesudo label更新一步student参数,然后用该参数在任务上的loss更新teacher。Meta pesudo label和原始的pesudo label的差异如下图。
6. 总结
本文介绍了近几年来meta-learning在迁移学习、domain adaptation、图学习、样本权重生成、知识蒸馏等5个领域的应用,包括6篇近3年的顶会论文。可以看出,meta-learning是一个工具,可以通过内循环和外循环的方式建立两个优化目标的关系。Meta-learning经常被用于改进原来两阶段训练的模型,让两阶段的训练更加统一,通过meta-learning建立起两阶段训练的桥梁
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
以上是关于Meta-learning原来有这么多用途,一文汇总元学习在5个问题中的应用的主要内容,如果未能解决你的问题,请参考以下文章