[OC学习笔记]块与大中枢开发
Posted Billy Miracle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[OC学习笔记]块与大中枢开发相关的知识,希望对你有一定的参考价值。
当前在开发应用程序时,每位程序员都应留意多线程问题。你可能会说自己要开发的应用程序用不到多线程,即便如此,它也很可能依然是多线程的,因为系统框架通常会在UI线程之外再使用一些线程来执行任务。开发应用程序时,最糟糕的事莫过于程序因UI线程阻塞而挂起了。在Mac OS X系统中,这将使鼠标指针一直呈现令人焦急的旋转彩球状;而在ios系统中,阻塞过久的程序可能会终止执行。
所幸公司以全新方式设计了多线程。当前多线程编程的核心就是“块”(block)与“大中枢派发”(Grand Central Dispatch,GCD)。这虽然是两种不同的技术,但它们是一并引入的。“块”是一种可在C、C++及Obiective-C代码中使用的“词法闭包”(lexical closure),它极为有用,这主要是因为借由此机制,开发者可将代码像对象一样传递,令其在不同环境(context)下运行。还有个关键的地方是,在定义“块”的范围内,它可以访问到其中的全部变量。
GCD是一种与块有关的技术,它提供了对线程的抽象,而这种抽象则基于“派发队列”(dispatch queue)。开发者可将块排入队列中,由GCD负责处理所有调度事宜。GCD 会根据系统资源情况,适时地创建、复用、摧毁后台线程(background thread),以便处理每个队列此外,使用GCD还可以方便地完成常见编程任务,比如编写“只执行一次的线程安全代码(thread-safe single-code execution),或者根据可用的系统资源来并发执行多个操作。
块与GCD都是当前Objective-C编程的基石。因此,必须理解其工作原理及功能。
一、理解“块”这一概念
块可以实现闭包。这项语言特性是作为“扩展”(extension)而加GCC编译器中的,在近期版本的Clang中都可以使用(Clang是开发Mac OS X及iOS程序所用的编译器)。10.4版及其后的Mac OS X系统,与4.0版及其后的iOS系统中,都含有正常执行块所需的运行期组件。从技术上讲,这是个位于C语言层面的特性,因此,只要有支持此特性的编译器,以及能执行块的运行期组件,就可以在C、C++、Objective-C、Objective-C++代码中使用它。
(一)块的基础知识
块与函数类似,只不过是直接定义在另一个函数里的,和定义它的那个函数共享同一个范围内的东西。块用“^”符号来表示,后面跟着一对花括号,括号里面是块的实现代码。例如,下面就是个简单的块:
^
//Block implementation here
块其实就是个值,而且自有其相关类型。与int、float或OC对象一样,也可以把块赋给变量,然后像使用其他变量那样使用它。块类型的语法与函数指针近似。下面列出的这个块很简单,没有参数,也不返回值:
void (^someBlock)() = ^
//Block implementation here);
这段代码定义了一个名为someBlock的变量。由于变量名写在正中间,所以看上去也许有点怪,不过一旦理解了语法,很容易就能读懂。块类型的语法结构如下:
return_type (^block name)(parameters)
下面这种写法所定义的块,返回int值,并且接受两个int做参数:
int (^addBlock)(int a, int b) = ^(int a, int b)
return a+b;
;
定义好之后,就可以像函数那样使用了。比方说,addBlock块可以这样用:
int add = addBlock(2,5); //add = 7
块的强大之处是:在声明它的范围里,所有变量都可以为其所捕获。这也就是说,那个范围里的全部变量,在块里依然可用。比如,下面这段代码所定义的块,就使用了块以外的变量:
int additional = 5;
int (^addBlock)(int a, int b) = ^(int a, int b)
return a + b + additional;
;
int add = addBlock(2,5); //add = 12
默认情况下,为块所捕获的变量,是不可以在块里修改的。在本例中,假如块内的代码改动了additional变量的值,那么编译器就会报错。不过,声明变量的时候可以加上__block修饰符,这样就可以在块内修改了。例如,可以用下面这个块来枚举数组中的元素,以判断其中有多少个小于2的数:
NSArray *array = @[@0, @1,@2, @3, @4,@5];
__block NSInteger count = 0;
[array enumerateObjectsUsingBlock:
^(NSNumber *number, NSUInteger idx, BOOL *stop)
if([number compare:@2] == NSOrderedAscending)
count++;
];
//count=2
这段范例代码也演示了“内联块”(inline block)的用法。传给“numerateObjects UsingBlock:”方法的块并未先赋给局部变量,而是直接内联在函数调用里了。由这种常见的编码习惯也可以看出块为何如此有用。在OC语言引人块这一特性之前,想要编出与刚才那段代码相同的功能,就必须传入函数指针或选择子的名称,以供枚举方法调用。状态必须手工传人与传出,这一般通过“不透明的void 指针”(opaque void pointer)实现,如此一来。就得再写几行代码了,而且还会令方法变得有些松散。与之相反,若声明内联形式的块,则可把所有业务逻辑都放在一处。
如果块所捕获的变量是对象类型,那么就会自动保留它。系统在释放这个块的时候,也会将其一并释放。这就引出了一个与块有关的重要问题。块本身可视为对象。实际上,在其他OC对象所能响应的选择子中,有很多是块也可以响应的。而最重要之处则在于,块本身也和其他对象一样,有引用计数。当最后一个指向块的引用移走之后,块就回收了。回收时也会释放块所捕获的变量,以便平衡捕获时所执行的保留操作。
如果将块定义在OC类的实例方法中,那么除了可以访问类的所有实例变量之外,还可以使用self变量。块总能修改实例变量,所以在声明时无须加__block。不过,如果通过读取或写人操作捕获了实例变量,那么也会自动把self变量一并捕获了,因为实例变量是与self所指代的实例关联在一起的。例如,下面这个块声明在MyClass类的方法中:
@interface MyClass
- (void)anInstanceMethod
//...
void (^someBlock)() = ^
_anInstanceVariable = @"Something";
NSLog(@" anInstanceVariable==@", _anInstanceVariable);
;
//...
@end
如果某个MyClass实例正在执行anInstanceMethod方法,那么self变量就指向此实例。由于块里没有明确使用self变量,所以很容易就会忘记 self变量其实也为块所捕获了。直接访问实例变量和通过self来访问是等效的:
self->_anInstanceVariable = @"Something";
之所以要捕获self变量,原因正在于此。我们经常通过属性访问实例变量,在这种情况下,就要指明self了:
self.aProperty = @"Something";
然而,注意:self也是一个对象,因而块在捕获它时也会将其保留。如果self所指代的那个对象同时也保留了块,那么这种情况通常会导致“保留环”。
(二)块的内部结构
每个OC对象都占据着某个内存区域。因为实例变量的个数及对象所包含的关联数据互不相同,所以每个对象所占的内存区域也有大有小。块本身也是对象,在存放块对象的内存区域中,首个变量是指向Class对象的指针,该指针叫做isa。其余内存里含有块对象正常运转所需的各种信息。如图:
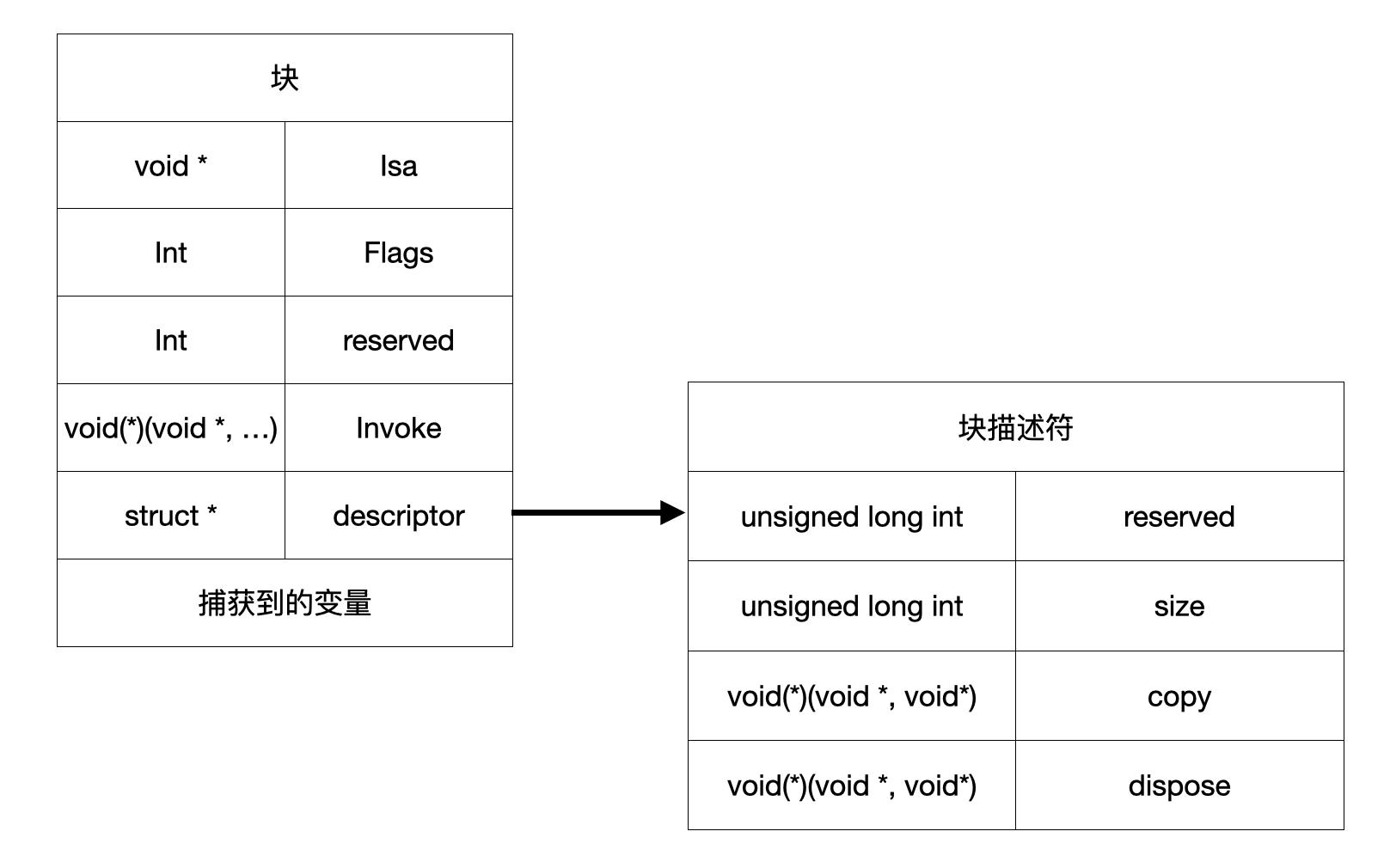
在内存布局中,最重要的就是invoke变量,这是个函数指针,指向块的实现代码。函原型至少要接受一个void*型的参数,此参数代表块。刚才说过,块其实就是一种代替函数指针的语法结构,原来使用函数指针时,需要用“不透明的void指针”来传递状态。而改用块之后,则可以把原来用标准C语言特性所编写的代码封装成简明且易用的接口。
descriptor变量是指向结构体的指针,每个块里都包含此结构体,其中声明了块对象的总体大小,还声明了copy与dispose这两个辅助函数所对应的函数指针。辅助函数在拷贝及丢弃块对象时运行,其中会执行一些操作,比方说,前者要保留捕获的对象,而后者则将之释放。
块还会把它所捕获的所有变量都拷贝一份。这些拷贝放在descriptor变量后面,捕获了多少个变量,就要占据多少内存空间。请注意,拷贝的并不是对象本身,而是指向这些对象的指针变量。invoke函数为何需要把块对象作为参数传进来呢?原因就在于,执行块时,要从内存中把这些捕获到的变量读出来。
(三)全局块、栈块及堆块
定义块的时候,其所占的内存是分配在栈中的。这就是说,块只在定义它的那个范围内有效,如下面的代码就有危险:
void (^block) ();
if (/**/)
block = ^
NSLog(@"Block A");
;
else
block = ^
NSLog(@"B;ock B");
;
block();
定义在if及else语句中的两个块都分配在栈内存中。编译器会给每个块分配好栈内存。然而等离开了相应的范围之后,编译器有可能把分配给块的内存覆写掉。于是,这两个块只能保证在对应的if或else语句范围内有效。这样写出来的代码可以编译,但是运行起来时而正确,时而错误。若编译器未覆写待执行的块,则程序照常运行,若覆写,则程序崩溃。
为解决此问题,可给块对象发送copy消息以拷贝之。这样的话,就可以把块从栈复制到堆了。拷贝后的块,可以在定义它的那个范围之外使用。而且,一旦复制到堆上,块就成了带引用计数的对象了。后续的复制操作都不会真的执行复制,只是递增块对象的引用计数。如果不再使用这个块,那就应将其释放,在ARC环境下会自动释放,而手动管理引用计数时则需要自己来调用release方法。当引用计数降为0后,“分配在堆上的块”(heap block)会像其他对象一样,为系统所回收。而“分配在栈上的块”(stackblock)则无须明确释放,因为栈内存本来就会自动回收,刚才那段范例代码之所以有危险,原因也在于此。
明白这一点后,我们只需给代码加上两个copy方法调用,就可令其变得安全了:
明白这一点了后,我们只需给代码加上两个copy方法调用,就可以令其变得安全了:
void (^block) ();
if (/**/)
block = [^
NSLog(@"Block A");
copy];
else
block = [^
NSLog(@"B;ock B");
copy];
block();
现在代码就安全了。如果手动管理引用计数,那么在用完块后还需将其释放。
除了“栈块”和“堆块”之外,还有一类块叫做“全局块”(globalblock)。这种块不会捕捉任何状态(比如外围的变量等),运行时也无须有状态来参与。块所使用的整个内存区域,在编译期已经完全确定了,因此,全局块可以声明在全局内存里,而不需要在每次用到的时候于栈中创建。另外,全局块的拷贝操作是个空操作,因为全局块决不可能为系统所回收。这种块实际上相当于单例。下面就是个全局块:
void (^block)() = ^
NSLog(@"This is a block");
;
由于运行该块所需的全部信息都能在编译期确定,所以可以把它做成全局块。这完全是种优化技术:若把如此简单的块当作复杂的块来处理,那就会在复制及丢弃该块时执行一些无谓的操作。
二、为常用的块类型创建typedef
每个块都具备其“固有类型”(inherent type),因而可将其赋给适当类型的变量。这个类型由块所接受的参数及其返回值组成。例如下面这个块:
^(BOOL flag, int value)
if (flag)
return value * 5;
else
return value * 10;
此块接受两个类型分别为BOOL及int的参数,并返回类型为int的值。如果想把它赋给变量,则需注意其类型。变量类型及相关赋值语句如下:
int (^variableName)(BOOL flag, int value) =
^(BOOL flag, int value)
// Implementation
return someInt;
这个类型似乎和普通的类型大不相同,然而如果习惯函数指针的话,那么看上去就会觉得眼熟了。块类型的语法结构如下:
return_type (^block_name)(parameters)
与其他类型的变量不同,在定义块变量时,要把变量名放在类型之中,而不要放在右侧。这种语法非常难记,也非常难读。鉴于此,我们应该为常用的块类型起个别名,尤其是打算把代码发布成API供他人使用时,更应这样做。开发者可可以起个更为易读的名字来表示块的用途,而把块的类型隐藏在其后面。
为了隐藏复杂的块类型,需要用到C语言中名为“类型定定义”(type definition)的特性。typedef关键字用于给类型起个易读的别名。比方说,想定义人新类型,用以表示接受BOOL及int参数并返回int值的块,可通过下列语句来做:
typedef int(^SomeBlock)(BOOL, int value);
声明变量时,要把名称放在类型中间,并在前面加上“^”符号,而定义新类型时也得这么做。上面这条语句向系统中新增了一个名为SomeBlock的类型。此后,不用再以复杂的块类型来创建变量了,直接使用新类型即可:
SomeBlock block = ^(BOOL flag, int value)
// Implementation
;
这次代码读起来就顺畅多了:与定义其他变量时一样,变量类型在左边,变量名在右边。
通过这项特性,可以把使用块的API做得更为易用些。类里面有些方法可能需要用块来做参数,比如执行异步任务时所用的“completion handler”(任务完成后所执行的处理程序)参数就是块,凡遇到这种情况,都可以通过定义别名使代码变得更为易读。比方说,类里有个方法可以启动任务,它接受一个块作为处理程序,在完成任务之后执行这个块。若不定义别名,则方法签名会像下面这样:
-(void)startWithCompletionHandler:
(void(^)(NSData *data, NSError *error))completion:
注意,定义方法参数所用的块类型语法,又和定义变量时不同。若能把方法签名中的参数类型写成一个词,那读起来就顺口多了。于是,可以给参数类型起个别名。然后使用此名称来定义:
typedef void(^CompletionHandler)(NSData *data, NSError *error);
-(void)startWithCompletionHandler:(CompletionHandler)completion;
现在参数看上去就简单多了。而且易于理解。当前,优秀的集成开发环境(Integrated Development Environment,IDE)都可以自动把类型定义展开,所以typedef这个功能变得很实用。
使用类型定义还有个好处,就是当你打算重构块的类型签名时会很方便。比方说,要给原来的completion handler块再加一个参数,用以表示完成任务所花的时间,那么只需修改类型定义语句即可:
typedef void(^CompletionHandler)(NSData *data, NSTimeInterval duration, NSError *error);
修改之后,凡是使用了这个类型定义的地方,比如方法签名等处,都会无法编译,而且报的是同一种错误,于是开发者可据此逐个修复。若不用类型定义,而直接写块类型,那么代码中要修改的地方就更多了。开发者很容易忘掉其中一两处,从而引发难于排查的bug。
最好在使用块类型的类中定义这些typedef,而且还应该把这个类的名字加在由typedef所定义的新类型名前面,这样可以闸明块的用途。还可以用typedef给同一个块签名类型创建数个别名。在这件事上,多多益善。
Mac OS X 与 iOS 的Accounts框架就是个例子。在该框架中可以找到下面这两个类型定义语句:
typedef void(^ACAccountStoreSaveCompletionHandler)
(BOoL success, NSError *error);
typedef void(^ACAccountstoreRequestAccessCompletionHandler)
(BOOL granted, NSError *error);
这两个类型定义的签名相同,但用在不同的地方。开发者看到类型别名及签名中的参数之后,很容易就能理解此类型的用途。它们本来也可以合并成一个typedef,比如叫做ACA-ccountStoreBooleanCompletionHandler,使用那两个别名的地方,都可以统一使用此名称。然而,这么做之后,块与参数的用途看上去就不那么明显了。
与此相似,如果有好几个类都要执行相似但各有区别的异步任务,而这几个类又不能放人同一个继承体系,那么,每个类就应该有自己的completion handler类型。这几个completion handler的签名也许完全相同,但最好还是在每个类里都各自定义一个别名,而不要共用同一个名称。反之,若这些类能纳入同一个继承中,则应该将类型定义语句放在超类中,以供各子类使用。
三、用handler块降低代码分散程度
为用户界面编码时,一种常用的范式就是“异步执行任务”(perform task asynchronously)。这种范式的好处在于:处理用户界面的显示及触摸操作所用的线程,不会因为要执行I/O或网络通信这类耗时的任务而阻塞。这个线程通常常称为主线程(main thread)。假设把执行异步任务的方法做成同步的,那么在执行任务时,用户界面就变得无法响应用户输入了。某些情况下,如果应用程序在一定时间内无响应,那么就会自动终止。iOS系统上的应用程序就是如此,“系统监控器”(system watchdog)在发现某个应用程序的主线程已经阻塞了一段时间之后,就会令其终止。
异步方法在执行完任务之后,需要以某种手段通知相关代码。实现此功能有很多办法。常用的技巧是设计一个委托协议,令关注此事件的对象遵从该协议。对象成为delegate之后,就可以在相关事件发生时(例如某个异步任务执行完毕时)得到通知了。
比方说,要写一个从 URL 中获取数据的类。使用委托模式设计出来的类会是这个样子:
#import <Foundation/Foundation.h>
@class NetworkFetcher;
@protocol NetworkFetcherDelegate <NSObject>
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data;
@end
@interface NetworkFetcher : NSObject
@property (nonatomic, weak) id<NetworkFetcherDelegate> delegate
- (id)initWithURL:(NSURL*)url;
- (void)start;
@end
而其他类则可像下面这样使用此类所提供的API:
- (void)fetchFooData
NSURL *url = [[NSURL alloc] initwithstring:@"..."];
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initwithurl:url];
fetcher.delegate = self;[fetcher start];
// ...
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data
fetchedFooData = data;
这种做法确实可行,而且没有什么错误。然而如果改用块来写的话,代码会更清晰。块可以令这种API变得更紧致,同时也令开发者调用起来更加方便。办法就是:把 completion handler定义为块类型,将其当作参数直接传给start方法:
#import <Foundation/Foundation.h>
typedef void(^EOCNetworkFetcherCompletionHandler)(NSData *data)
@interface NetworkFetcher :NSObject
(id)initWithURL:(NSURL*)url;
-(void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)handler;
@end
这和使用委托协议很像,不过多了个好处,就是可以在调用start方法时直接以内联形式定义completion handler,以此方式来使用“网络数据获取器”(network fetcher),可以令代比原先易懂很多。例如,下面这个类就以块的形式来定义completion handler,并以此为参娄调用API:
- (void)fetchFooData
NSURL *url = [[NSURL alloc] initwithstring:@"..."];
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initWithURL;url];
[fetcher startWithCompletionHandler:^(NSData *data)
_fetchedFooData = data;
];
与使用委托模式的代码相比,用块写出来的代码显然更为整洁。异步任务执行完毕后所运行的业务逻辑,和启动异步任务所用的代码放在了一起。而且,由于块声明在创建获取据的范围里,所以它可以访问此范围内的全部变量。本例比较简单,体现不出这一点,然而在更为复杂的场景中,会大有裨益。
委托模式有个缺点:如果类要分别使用多个获取器下载不同数据,那么就得在delegate回调方法里根据传人的获取器参数来切换。这种代码的写法如下:
- (void)fetchFooData
NSURL *url = [[NSURLalloc] initWithString:@"..."];
fooFetcher = [[NetworkFetcher alloc] initWithUrl:url];
fooFetcher.delegate = self;
[_fooFetcher start];
- (void)fetchBarData
NSURL *url = [[NSURLalloc] initwithstring:@"..."];
barFetcher = [[NetworkFetcher alloc] initWithURL:url];
_barFetcher.delegate = self;
[barFetcher start];
- (void)networkFetcher:(NetworkFetcher*)networkFetcher didFinishWithData:(NSData*)data
if (networkFetcher == _fooFetcher)
fetchedFooData = data;
fooFetcher = nil;
else if (networkFetcher == _barFetcher)
fetchedBarData = data;
barFetcher = nil;
// etc.
这么写代码,不仅会令delegate 回调方法变得很长,而且还要把网络数据获取器对象保存为实例变量,以便在判断语句中使用。这么做可能有其他原因,比如稍后要根据情况解除监听等,然而这种写法有副作用,通常很快就会使类的代码激增。改用块来写的好处是:无须保存获取器,也无须在回调方法里切换。每个completion handler的业务逻辑,都是和相关的获取器对象一起来定义的:
- (void)fetchFooData
NSURL *url = [[NSURL alloc] initWithString:@"..."];
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initwithURL:url];
[fetcher startWithCompletionHandler:^(NSData *data)
_fetchedFooData = data;
];
- (void)fetchBarData
NSURL *url = [[NSURL alloc] initwithstring:@"..."];
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initwithUrL:url];
[fetcher startWithCompletionHandler:^(NSData *data)
fetchedBarData =data;
];
这种写法还有其他用途,比如,现在很多基于块的API都使用块来处理错误。这又分为两种办法。可以分别用两个处理程序来处理操作失败的情况和操作成功的情况。也可以把处理失败情况所需的代码,与处理正常情况所用的代码,都封装到同一个completion handler里。如果想采用两个独立的处理程序,那么可以这样设计PI:
#import <Foundation/Foundation.h>
@class NetworkFetcher;
typedef void(^NetworkFetcherCompletionHandler)(NSData *data);
typedef void(^NetworkFetcherErrorHandler)(NSError *error);
@interface NetworkFetcher : NSObject
- (id)initwithURL:(NSURL*)url;
- (void)startWithCompletionHandler:(NetworkFetcherCompletionHandler)completion failureHandler:(NetworkFetcherErrorHandler)failure;
@end
依照此风格设计出来的API,其调用方式如下:
NetworkFetcher *fetcher = [[NetworkFetcher alloc] initWithUrl:url];
[fetcher startWithCompletionHander:^(NSData *data)
//Handle success
failureHandler:^(NSError *error)
//Handle failure
];
这种设计很好于功的情况分别处理,所以调用此API的代码也就会按照逻辑,把应对成功和失败情况的代码分开来写,这将令代码更易读懂。而且,若有需要,还可以把处理失败情况或成功情况所用的代码省略。
另一种风格则是像下面这样,把处理成功情况和失败情况所用的代码全放在一个块里:
#import <Foundation/Foundation.h>
@class NetworkFetcher;
typedef void(^NetworkFetcherCompletionHandler)(NSData *data, NSError *error);
@interface NetworkFetcher : NSObject
- (id)initWithURL:(NSURL*)url;
- (void)startWithCompletionHandler:
(NetworkFetcherCompletionHandler)completion;
dend
此种API的调用方式如下
NetworkFetcher *fetcher = [[EOCNetworkFetcher alloc] initwithURL:url];
[fetcher startWithCompletionHander:^(NSData *data, NSError *error)
if (error)
// Handle failur
else
//Handle success
];
这种方式需要在块代码中检测传人的error变量,并且要把所有逻辑代码都放在一处。这种写法的缺点是:由于全部逻辑都写在一起,所以会令块变得比较长,且比较复杂。然而只用一个块的写法也有好处,那就是更为灵活。比方说,在传人错误信息时,可以把数据也传进来。有时数据正下载到一半,突然网络故障了。在这种情况下,可以把数据及相关的错误都回传给块。这样的话,completion handler就能据此判断问题并适当处理了,而且还可利用已下载好的这部分数据做些事情。
把成功情况和失败情况放在同一个块中,还有个优点:调用API的代码可能会在处理成功响应的过程中发现错误。比方说,返回的数据可能太短了。这种情况需要和网络
以上是关于[OC学习笔记]块与大中枢开发的主要内容,如果未能解决你的问题,请参考以下文章