Java--LinkedList集合,链表
Posted MinggeQingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java--LinkedList集合,链表相关的知识,希望对你有一定的参考价值。
一、LinkedList
LinkedList 继承了 AbstractSequentialList 类,实现了 List 接口,可进行列表的相关操作
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
* Constructs an empty list.
*/
public LinkedList()
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public LinkedList(Collection<? extends E> c)
this();
addAll(c);
/**
* Links e as first element.
*/
private void linkFirst(E e)
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
/**
* Links e as last element.
*/
void linkLast(E e)
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
/**
* Returns the first element in this list.
*
* @return the first element in this list
* @throws NoSuchElementException if this list is empty
*/
public E getFirst()
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
/**
* Returns the last element in this list.
*
* @return the last element in this list
* @throws NoSuchElementException if this list is empty
*/
public E getLast()
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
/**
* Removes and returns the first element from this list.
*
* @return the first element from this list
* @throws NoSuchElementException if this list is empty
*/
public E removeFirst()
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
/**
* Removes and returns the last element from this list.
*
* @return the last element from this list
* @throws NoSuchElementException if this list is empty
*/
public E removeLast()
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
/**
* Inserts the specified element at the beginning of this list.
*
* @param e the element to add
*/
public void addFirst(E e)
linkFirst(e);
/**
* Appends the specified element to the end of this list.
*
* <p>This method is equivalent to @link #add.
*
* @param e the element to add
*/
public void addLast(E e)
linkLast(e);
public int size()
return size;
public boolean add(E e)
linkLast(e);
return true;
public boolean remove(Object o)
if (o == null)
for (Node<E> x = first; x != null; x = x.next)
if (x.item == null)
unlink(x);
return true;
else
for (Node<E> x = first; x != null; x = x.next)
if (o.equals(x.item))
unlink(x);
return true;
return false;
public E get(int index)
checkElementIndex(index);
return node(index).item;
Node<E> node(int index)
// assert isElementIndex(index);
if (index < (size >> 1))
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
else
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
ArrayList之所以检索效率比较高,不是单纯因为下标的原因,是因为底层数组发挥的作用。LinkedList集合照样有下标,但是检索/查找某个元素的时候效率比较低,因为只能从头节点开始一个一个遍历。
链表的优点: 由于链表上的元素在空间存储上内存地址不连续。 所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。 遇到随机增删集合中元素的业务比较多时,优先使用LinkedList。
链表的缺点: 不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止。因此LinkedList集合检索/查找的效率 较低。
二、链表
链表是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。
一个单向链表包含两个值:当前节点的数据data和一个指向下一个节点的内存地址Node(链接)
一个双向链表有三个整数值:当前节点数据data、向后的节点内存地址 、向前的节点内存地址
1、单向链表
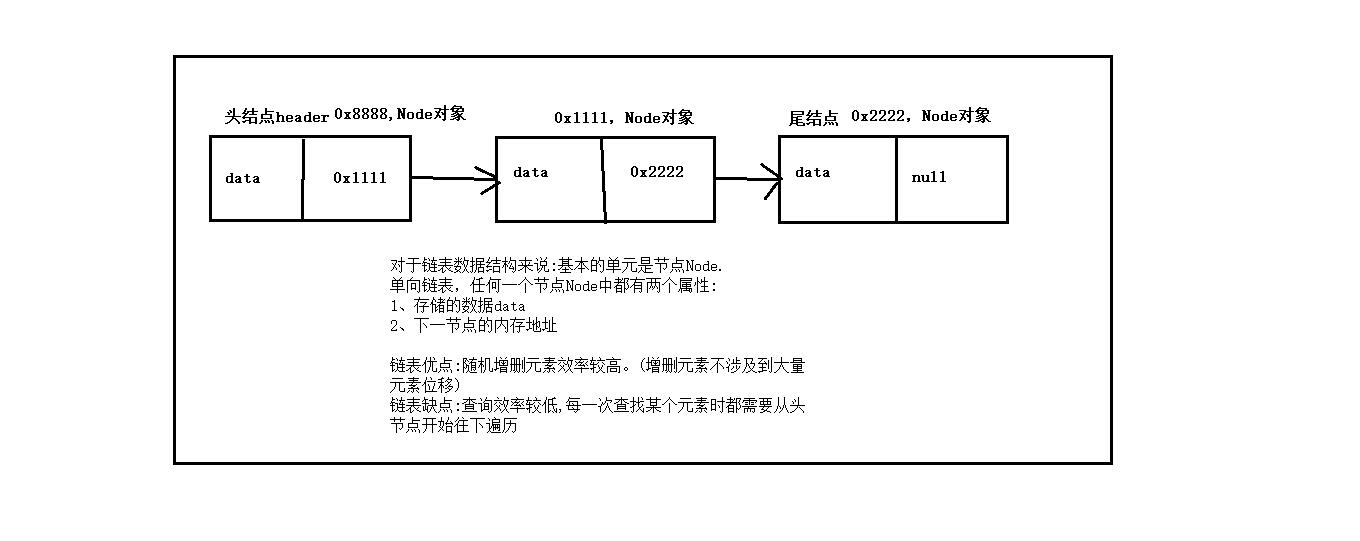
对于链表数据结构来说:基本的单元是节点Node
单向链表,任何一个节点Node中都有两个属性:
(1)存储的数据data(每个结点的数据域都是一个 Object 类的对象)
(2)下一节点的内存地址
因为只有一个指针结点,称为单链表
单向链表的第一个结点和最后一个结点,分别称为链表的 首结点和 尾结点
尾结点的特征是其 下一节点next 引用为空(null)
链表中每个结点的 下一节点next 引用都相当于一个指针,指向另一个结点,借助这些 next 引用,
我们可以从链表的首结点移动到尾结点。
在单链表中通常使用 head 引用来指向链表的首结点,由 head 引用可以完成对整个链表中所有节
点的访问。
单链表的一个重要特性就是只能通过前驱结点找到后续结点,而无法从后续结点找到前驱结点
链表优点:随机增删元素效率较高。(增删元素不涉及到大量元素位移)
链表缺点:查询效率较低,每一次查找某个元素时都需要从头节点开始往下遍历
2、双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直
接前驱。从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点
双向链表的这种结构比起单链表,其改进之处正在于此,通过对前后节点的引用可以使得在整个
链表中,通过给定的值,可以从前或者向后遍历,大大提升了遍历查询的效率,一定程度上解决了
单链表的性能问题

以上是关于Java--LinkedList集合,链表的主要内容,如果未能解决你的问题,请参考以下文章