ElasticSearch进阶篇之聚合(aggregations)和映射(mapping)
Posted 波波烤鸭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch进阶篇之聚合(aggregations)和映射(mapping)相关的知识,希望对你有一定的参考价值。

本文在上一篇文章的基础上我们继续来介绍ElasticSearch中聚合(aggregations)和映射(mappings)相关的内容。
聚合和映射
1.聚合(aggregations)
聚合可以让我们极其方便的实现对数据的统计、分析。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。
语法规则
"aggregations" :
"<aggregation_name>" :
"<aggregation_type>" :
<aggregation_body>
[,"meta" : [<meta_data_body>] ]?
[,"aggregations" : [<sub_aggregation>]+ ]?
[,"<aggregation_name_2>" : ... ]*
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/search-aggregations.html
1.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫 桶,一个叫 度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个 桶,例如我们根据国籍对人划分,可以得到 中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- ……
bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为 度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
1.2 案例讲解
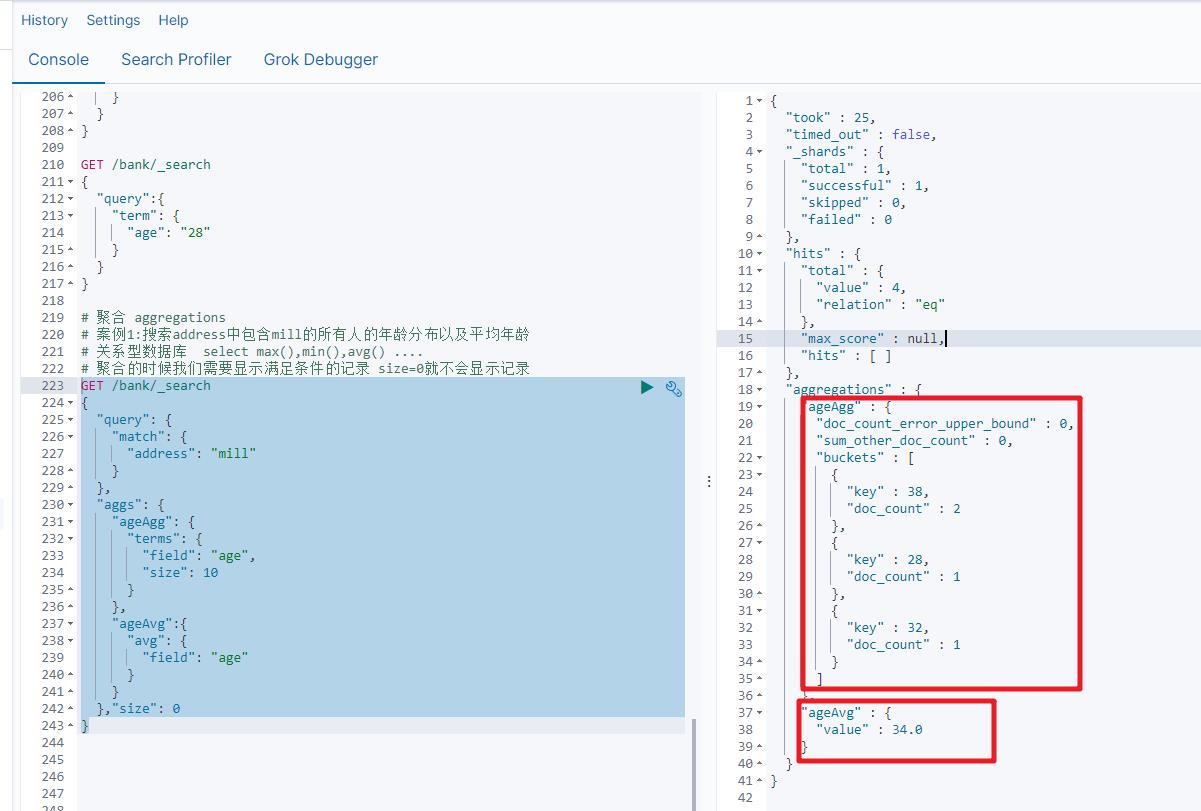
案例1:搜索address中包含mill的所有人的年龄分布以及平均年龄
GET /bank/_search
"query":
"match":
"address": "mill"
,
"aggs":
"ageAgg":
"terms":
"field": "age",
"size": 10
,
"ageAvg":
"avg":
"field": "age"
,"size": 0
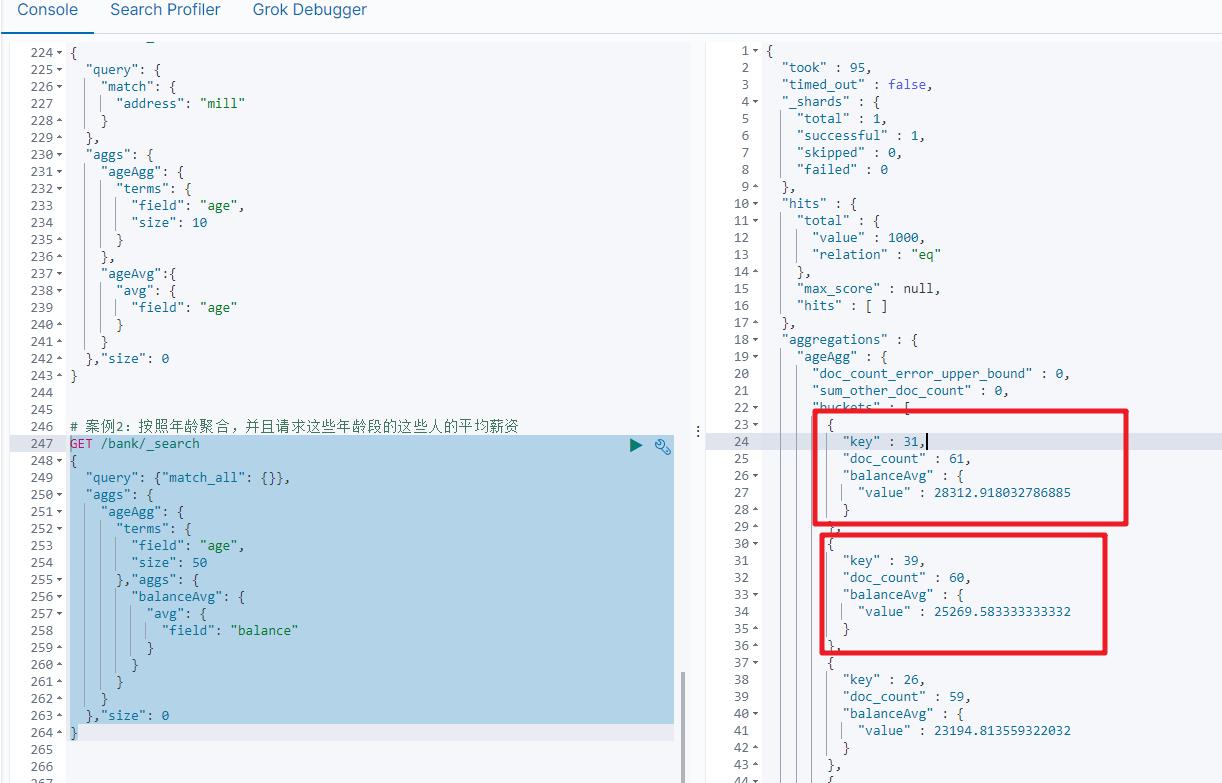
案例2:按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET /bank/_search
"query": "match_all": ,
"aggs":
"ageAgg":
"terms":
"field": "age",
"size": 50
,"aggs":
"balanceAvg":
"avg":
"field": "balance"
,"size": 0
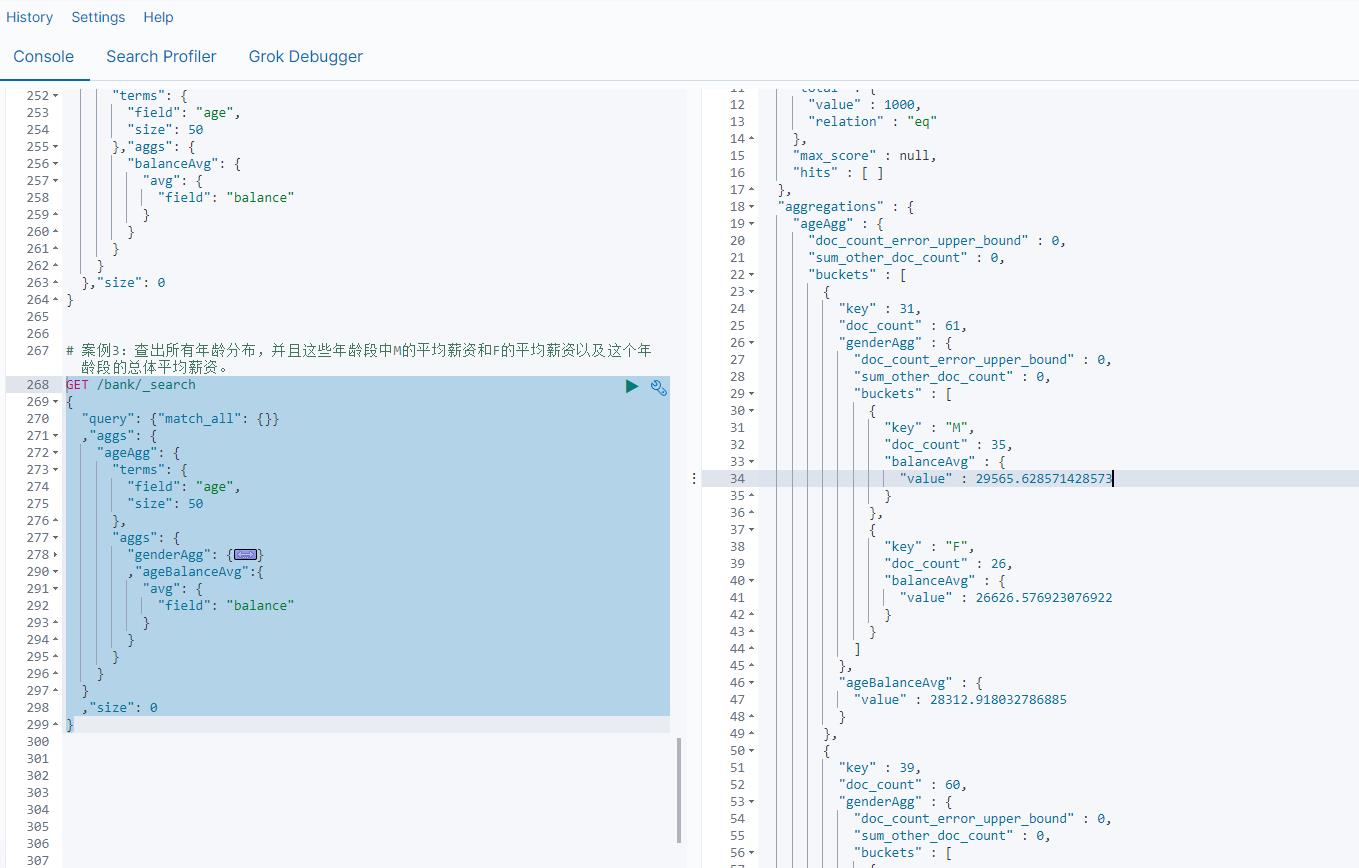
案例3:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资。
GET /bank/_search
"query": "match_all":
,"aggs":
"ageAgg":
"terms":
"field": "age",
"size": 50
,
"aggs":
"genderAgg":
"terms":
"field": "gender.keyword",
"size": 10
,"aggs":
"balanceAvg":
"avg":
"field": "balance"
,"ageBalanceAvg":
"avg":
"field": "balance"
,"size": 0
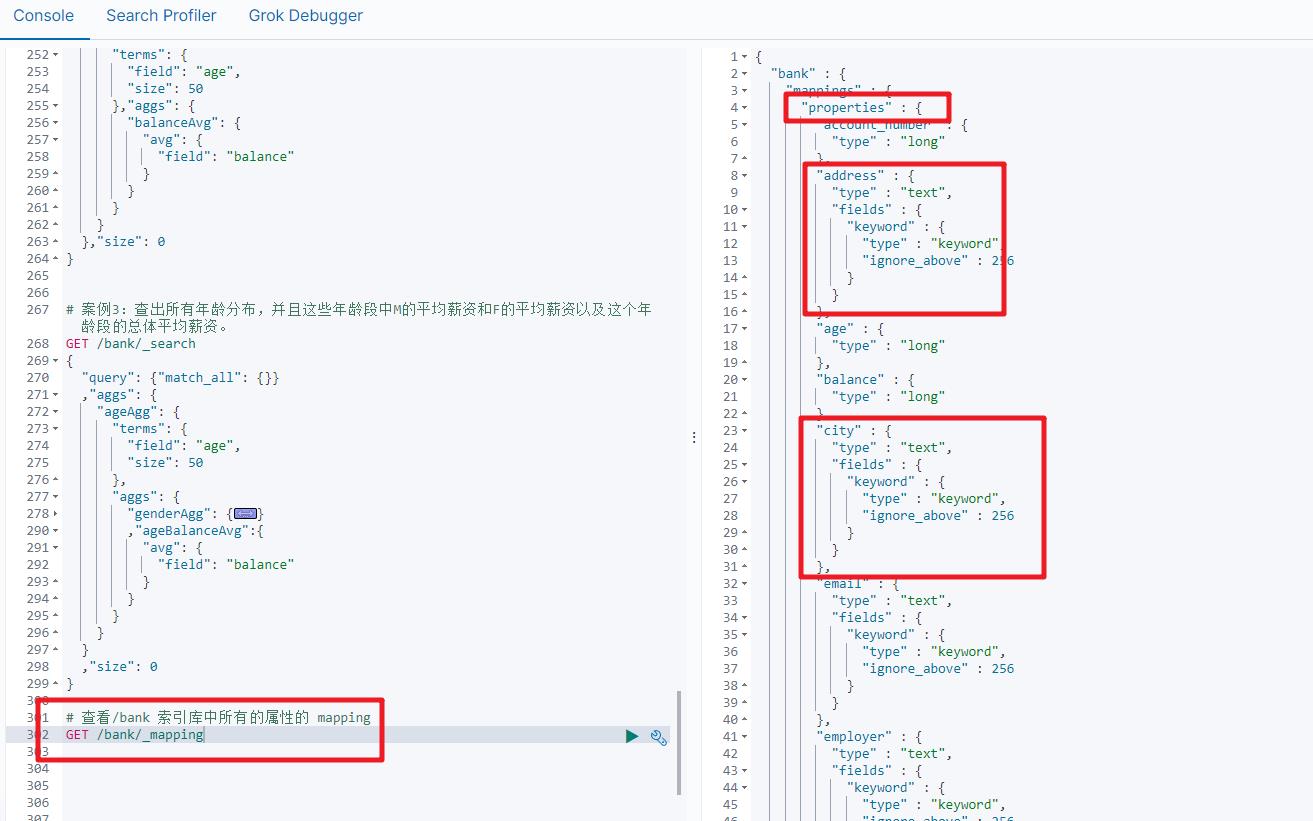
2.映射配置(_mapping)
查看索引库中所有的属性的_mapping
2.1 ElasticSearch7-去掉type概念:
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。
两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type就是为了提高ES处理数据的效率。
Elasticsearch 7.x
URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
不再支持URL中的type参数。
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
2.2 什么是映射?
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
2.3 创建映射字段
PUT /索引库名/_mapping/类型名称
"properties":
"字段名":
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:类似于列名,properties下可以指定许多字段。
每个字段可以有很多属性。例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里使用ik分词器:
ik_max_word或者ik_smart
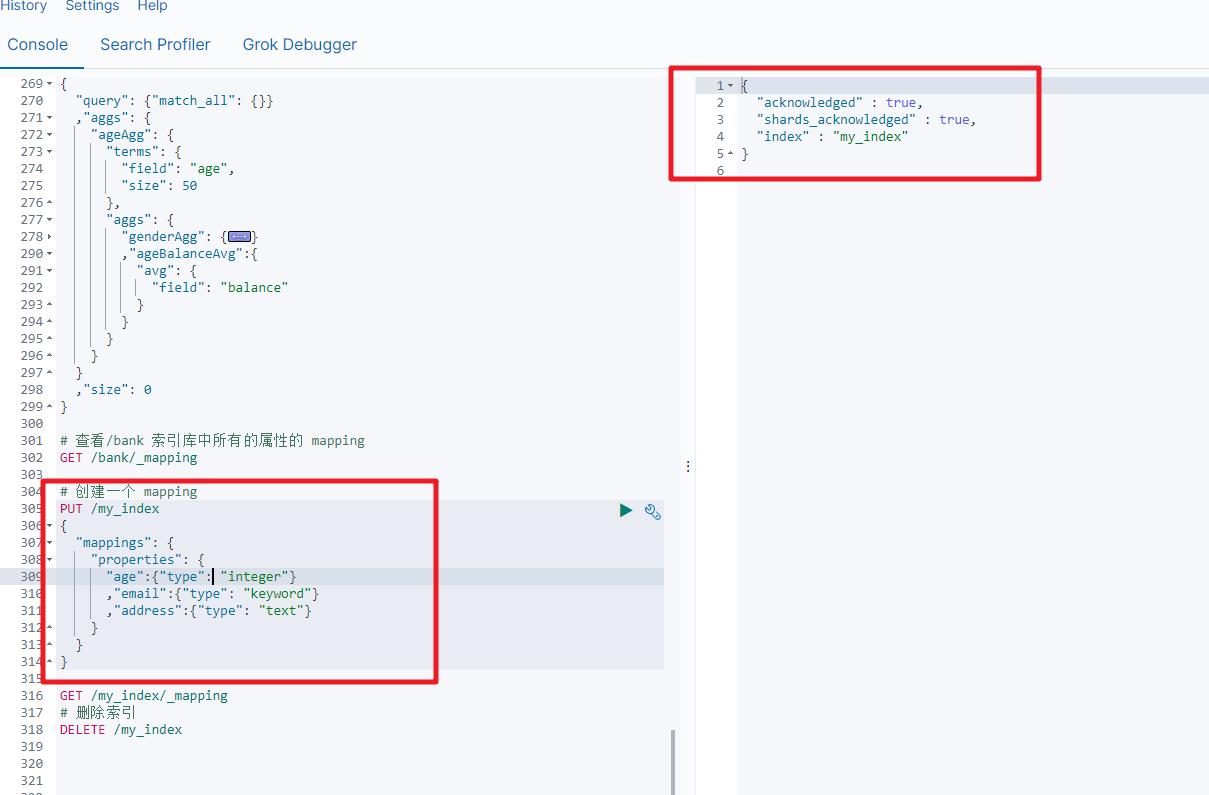
2.4 新增映射字段
如果我们创建完成索引的映射关系后,又要添加新的字段的映射,这时怎么办?第一个就是先删除索引,然后调整后再新建索引映射,还有一个方式就在已有的基础上新增。
PUT /my_index/_mapping
"properties":
"employee-id":
"type":"keyword"
,"index":false
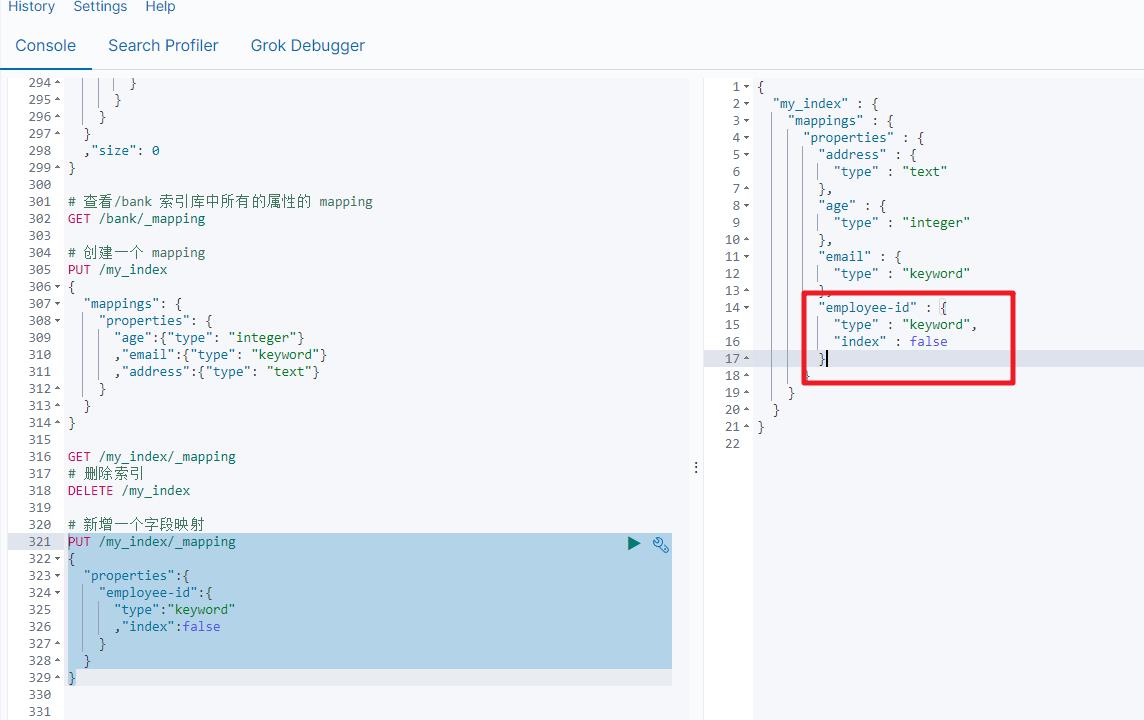
2.5 更新映射
对于存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移
2.6 数据迁移
先创建出正确的索引,然后使用如下的方式来进行数据的迁移
| POST_reindex [固定写法] “source”: “index”:“twitter” , “dest”: “index”:“new_twitter” |
|---|
老的数据有type的情况
| POST_reindex [固定写法] “source”: “index”:“twitter”, “type”:“account” , “dest”: “index”:“new_twitter” |
|---|
案例:新创建了索引,并指定了映射属性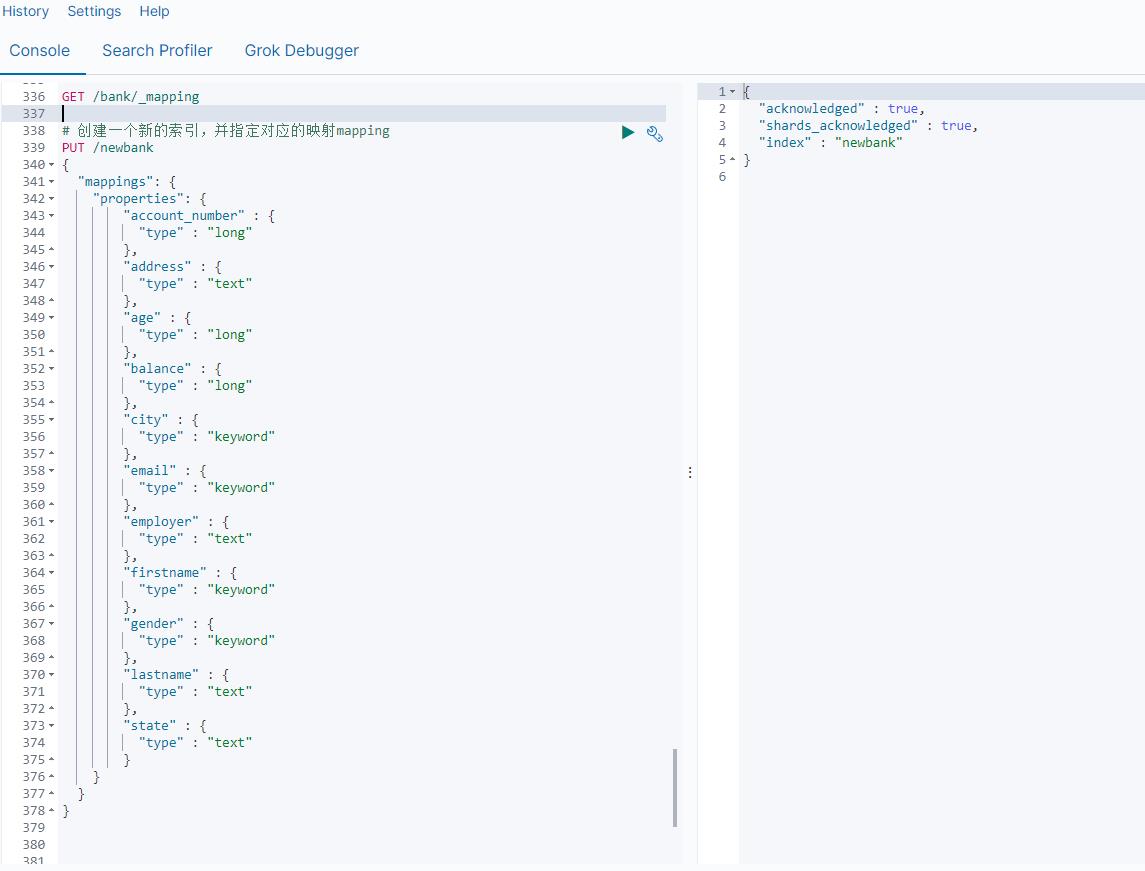

好了聚合和映射的内容就介绍这么多了,如果有问题欢迎留言讨论或者加V联系我哦(boge_java)

以上是关于ElasticSearch进阶篇之聚合(aggregations)和映射(mapping)的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch进阶篇之IK分词器和自定义词库实现
【ES从入门到实战】十七、全文检索-ElasticSearch-进阶-aggregations聚合分析