Hadoop大数据
Posted xiaotanggao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop大数据相关的知识,希望对你有一定的参考价值。
Hadoop
大数据
概述
- 数据量越来越大,数据分析的实时性越来越强,数据结果的应用越来越广泛,大数据技术应运而生
- 大数据:大数据是收集、整理、处理大容量数据集,并从中获得结果的技术总称
大数据处理框架
- 处理框架:实际负责处理数据操作的一系列组件
- 常见框架
- 批处理框架:用于批量处理大数据集的处理框架,可对整个数据集进行操作。如Apache Hadoop
- 流处理框架:用于对随时进入系统的数据进行实时计算,是一种“无数据边界”的操作方式。如Apache Storm,Apache Samza
- 混合处理框架:一些大数据处理框架可同时处理批处理和流处理工作负载。如:Apache Spark,Apache Flink
hadoop介绍
简介
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。主要解决海量数据的存储与分析计算问题。
- 广义上来说,Hadoop通常指一个更加广阔到概念——Hadoop生态圈
- Hadoop是一个可靠,可扩展的分布式计算的开源软件,可以从单个服务器扩展到数千台计算机。集群中每台计算机都提供本地计算和存储
- Hadoop把硬件故障认为常态,通过软件把控故障,在软件水平实现高可用
- Hadoop是一个大数据处理框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集
项目
核心项目
- Hadoop HDFS:分布式文件系统,可提供对应用程序数据的高吞吐量访问
- Hadoop YARN:作业调度和集群资源管理的框架
- Hadoop MapReduce:基于YARN的系统,用于并行处理大型数据集
- Hadoop Common:支持其他Hadoop模块的常用实用程序
- Hadoop Ozone: Hadoop集群所提供的对象存储
其他项目
- Ambari:基于Web的工具,用于配置,管理和监控Apache Hadoop集群,包括对Hadoop HDFS,HadoopMapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop的支持。Ambari还提供了一个用于查看集群运行状况的仪表板,例如热图,以及可视化查看MapReduce,Pig和Hive应用程序的功能,以及以用户友好的方式诊断其性能特征的功能
- Avro:数据序列化系统
- HBase:可扩展的分布式数据库,支持大型表的结构化数据存储。
- Mahout:可扩展的机器学习和数据挖掘库
- Spark:用于Hadoop数据的快速通用计算引擎。Spark提供了一种简单而富有表现力的编程模型,支持广泛的应用程序,包括ETL,机器学习,流处理和图形计算。
- ZooKeeper:用于分布式应用程序的高性能协调服务
HDFS
介绍
- HDFS:Hadoop Distributed File System,Hadoop分布式文件系统
- HDFS它是一个高度容错性的系统,可以部署在廉价机上,提供高吞吐量的数据访问,适合具有超大数据集(海量数据分析,机器学习等)的应用程序
- 特点:
- 支持大数据文件:适合TB级别数据
- 文件分块存储
- 支持一次写入,多次读取,顺序读取
- 支持廉价硬件
- 支持硬件故障
读写流程
相关名词
-
Block:最基本的存储单位。将文件进行分块处理,通常是128M/块
-
Hadoop集群:一主多从架构
-
NameNode:主节点
用于保存整个文件系统的目录信息、文件信息及分块信息
功能:
- 接收用户的操作请求
- 维护文件系统的目录结构
- 管理文件和Block之间的映射管理
- 管理 block 和 DataNode 之间的映射
-
DataNode:从节点
分布在廉价的计算机上,用于存储Block块文件
具体储存方式:文件被分成块存储到 DataNode 的磁盘上,每个Block(块)可以设置多副本
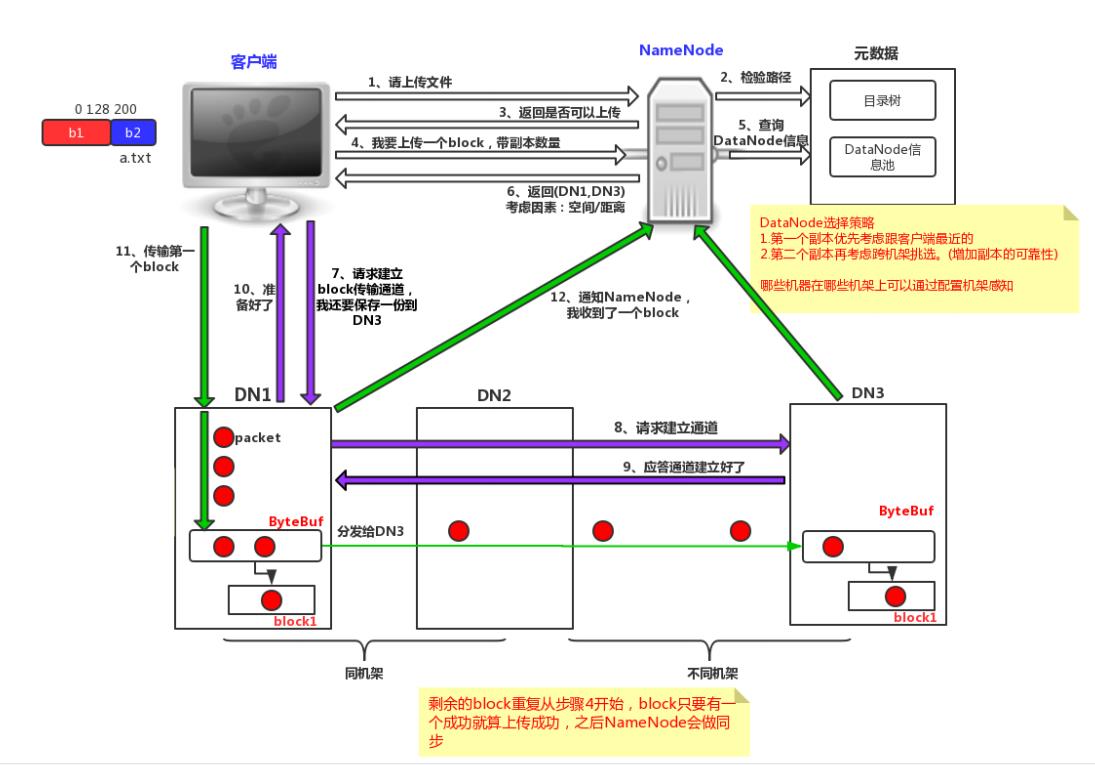
写流程
- 客户端向namenode发起请求
- 客户端向datenode发起建立连接请求
- 客户端向datenode存储数据
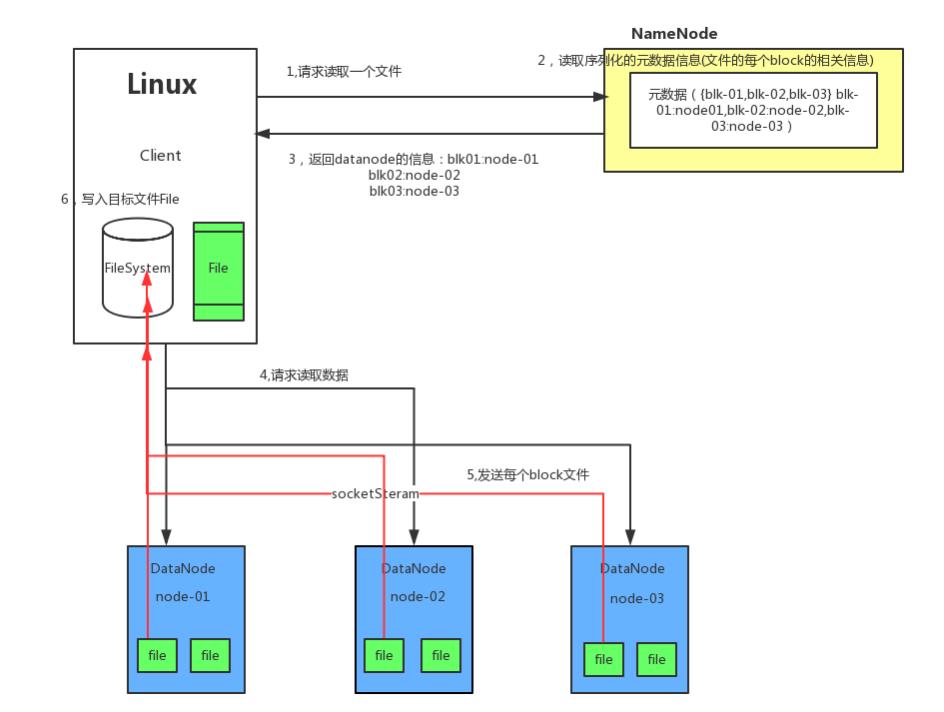
读流程
MapReduce
介绍
- MapReduce:是一套从海量源数据提取、分析元素,最后返回结果集的方法
- MapReduce框架的核心步骤主要分两部分:Map 和Reduce
- Map把大数据分成小数据,进行分析计算,将结果通过洗牌的方式给Reduce。Reduce对Map的结果进行汇总。
- 举例说明:
- 求和:1+5+7+3+4+9+3+5+6=?
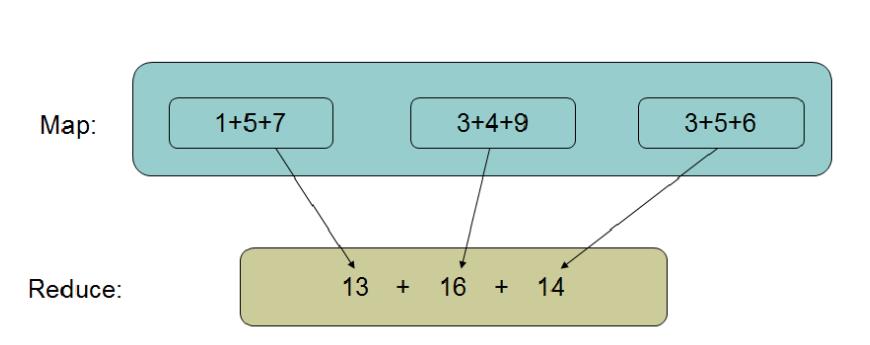
- 求和:1+5+7+3+4+9+3+5+6=?
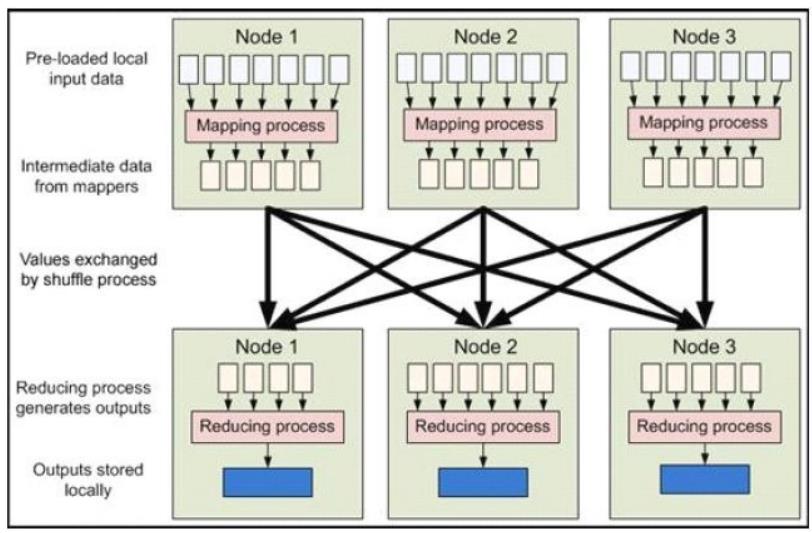
工作流程
-
当向MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map 任务,然后分配到不同的节点(DataNode)上去执行,每一个Map 任务处理输入数据中的一部分,当Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个Map 的输出汇总到一起并输出。
YARN
-
YARN: Yet An other Resouce Negotiator,另一种资源协调者
-
主要功能:任务调度和集群资源管理,让hadoop平台性能及扩展性得到更好发挥
-
YARN是Hadoop 2.0新增加的一个子项目,弥补了Hadoop 1.0(MRv1)扩展性差、可靠性资源利用率低以及无法支持其他计算框架等不足,Hadoop的下一代计算框架MRv2将资源管理功能抽象成一个通用系统YARN。也就是说,YARN由MapReduce拆分而来
-
优点:降低集群资源空闲,提高集群资源利用率。维护成本低。数据共享。 避免了集群之间移动数据。
-
主从架构
-
ResourceManager:资源管理(主)
负责对各个NodeManager上的资源进行统一管理和任务调度
-
NodeManager:节点管理(从)
在各个计算节点运行,用于接收RM中ApplicationsManager的计算任务、启动/停止任务、和RM中Scheduler汇报并协商资源、监控并汇报本节点的情况
-
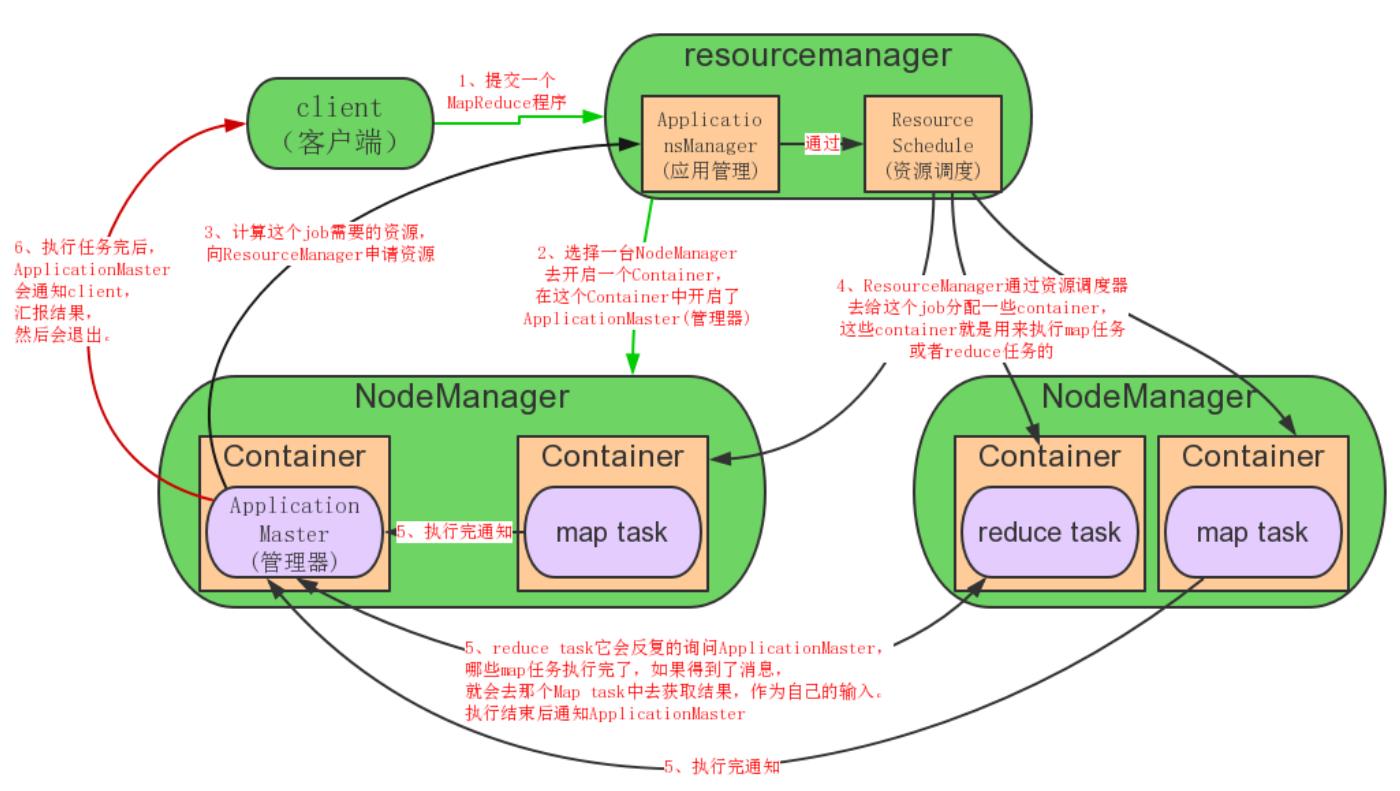
Hadoop部署
常见部署分类
单机
- 单机(本地模式)是Hadoop的默认部署模式
- 当配置文件为空时,Hadoop完全运行在本地
- 不需要与其他节点交互,单机(本地模式)就不使用HDFS,也不加载任何Hadoop的守护进程
- 该模式主要用于开发调试MapReduce程序的应用逻辑
伪分布式
- Hadoop守护进程运行在本地机器上,模拟一个小规模的的集群
- 该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入/输出,以及其他的守护进程交互
完全分布式
介绍
- 单机和伪分布式部署仅用于测试环境,生产环境需要完全分布式部署
- 完全分部式是真正利用多台Linux主机来进行部署Hadoop,对Linux机器集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上
- 由于NameNode和ResourceManager一主多从的架构模式,需要对其做高可用
NameNode HA故障切换
-
一个NameService下面有两个NameNode,分别处于Active和Standby状态。通过Zookeeper进行协调选举,确保只有一个活跃的NameNode。一旦主(Active)宕掉,standby会切换成Active
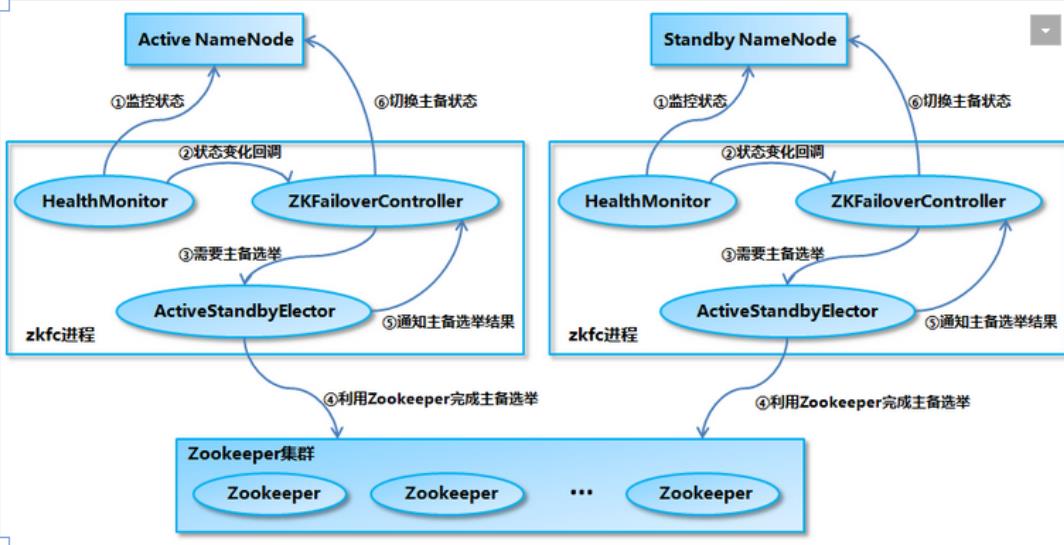
-
ZKFailoverController作为一个ZK(ZooKeeper)集群的客户端,用来监控NN的状态信息。每个运行NN的节点必须要运行一个ZKFC(ZKFailoverControlle)
-
ZKFC功能
- Health monitoring健康检查:zkfc定期对本地的NN发起health-check的命令,如果NN正确返回,那么这个NN被认为是OK的。否则被认为是失效节点
- ZooKeeper session management:当本地NN是健康的时候,zkfc将会在zk中持有一个session。如果本地NN又正好是active的,那么zkfc还有持有一个"ephemeral"的节点作为锁,一旦本地NN失效了,那么这个节点将会被自动删除
- ZooKeeper-based election主备选举:如果本地NN是健康的,并且zkfc发现没有其他的NN持有那个独占锁。那么他将试图去获取该锁,一旦成功,那么它就需要执行Failover,然后成为active的NN节点。
NameNode HA数据共享
- Namenode主要维护两个文件,一个是fsimage,一个是editlog
- fsimage保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
- editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中,editlog保存在JournalNode节点
- StandBy从JournalNode节点里读取editlog中数据进行同步
单机部署
-
软件包获取
-
java环境准备
[root@server5 ~]# java -version
openjdk version "1.8.0_312"
OpenJDK Runtime Environment (build 1.8.0_312-b07)
OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode)
更换jdk(提前下载好)
[root@server5 ~]# tar xf jdk-8u191-linux-x64.tar.gz
[root@server5 ~]# mv jdk1.8.0_191/ /usr/local/jdk
导入环境变量(注意顺序)
[root@server5 ~]# vim /etc/profile
[root@server5 ~]# tail -2 /etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
[root@server5 ~]# source /etc/profile
[root@server5 ~]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
- Hadoop安装
[root@server5 ~]# rz
[root@server5 ~]# tar xf hadoop-2.8.5.tar.gz
[root@server5 ~]# mv hadoop-2.8.5 /opt/
导入环境变量
[root@server5 ~]# echo 'PATH=$PATH:/opt/hadoop-2.8.5/bin' >> /etc/profile
[root@server5 ~]# source /etc/profile
- 词频统计,验证可用性
准备文件
[root@server5 ~]# mkdir /tmp/input
[root@server5 ~]# vim /tmp/input/test.txt
[root@server5 ~]# cat /tmp/input/test.txt
zhangsan
lisi
zhangsan 192.168.139.10
lisi 192.168.139.20
zhangsan 192.168.139.10
jack 192.168.139.30
词频统计
[root@server5 ~]# hadoop jar /opt/hadoop-2.8.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /tmp/input /tmp/output
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
查看结果
[root@server5 ~]# ls /tmp/output/
part-r-00000 _SUCCESS
# _SUCCESS仅说明运行成功;part-r-00000保存输出结果文件
[root@server5 ~]# cat /tmp/output/part-r-00000
192.168.139.10 2
192.168.139.20 1
192.168.139.30 1
jack 1
lisi 2
zhangsan 3
伪分布式部署
- 在单机部署的基础上实现伪分布式部署,具体步骤见单机部署
- 修改java jdk环境
[root@server5 ~]# cd /opt/hadoop-2.8.5/etc/
[root@server5 etc]# cd hadoop/
[root@server5 hadoop]# ls
capacity-scheduler.xml hadoop-policy.xml kms-log4j.properties ssl-client.xml.example
configuration.xsl hdfs-site.xml kms-site.xml ssl-server.xml.example
container-executor.cfg httpfs-env.sh log4j.properties yarn-env.cmd
core-site.xml httpfs-log4j.properties mapred-env.cmd yarn-env.sh
hadoop-env.cmd httpfs-signature.secret mapred-env.sh yarn-site.xml
hadoop-env.sh httpfs-site.xml mapred-queues.xml.template
hadoop-metrics2.properties kms-acls.xml mapred-site.xml.template
hadoop-metrics.properties kms-env.sh slaves
修改java jdk环境
[root@server5 hadoop]# vim hadoop-env.sh
[root@server5 hadoop]# grep -Ev '^#|^$' hadoop-env.sh |head -1
export JAVA_HOME=/usr/local/jdk
[root@server5 hadoop]# vim mapred-env.sh
[root@server5 hadoop]# grep -Ev '^#|^$' mapred-env.sh |head -1
export JAVA_HOME=/usr/local/jdk
[root@server5 hadoop]# vim yarn-env.sh
[root@server5 hadoop]# grep -Ev '#|^$' yarn-env.sh |grep 'export JAVA_HOM'E
export JAVA_HOME=/usr/local/jdk
- 配置fs和NameNode数据的存放位置
[root@server5 hadoop]# echo '192.168.139.50 hd1' >> /etc/hosts
[root@server5 hadoop]# vim core-site.xml
[root@server5 hadoop]# tail -12 core-site.xml
<configuration>
<!-- 配置fs -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hd1:8020</value>
</property>
<!-- 配置NameNode的数据临时存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
</configuration>
- 配置副本数量
[root@server5 hadoop]# vim hdfs-site.xml
[root@server5 hadoop]# tail -7 hdfs-site.xml
<configuration>
<!-- 配置副本数目 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- 格式化hdfs
[root@server5 hadoop]# hdfs namenode -format
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hd1/192.168.139.50
************************************************************/
[root@server5 hadoop]# ls /opt/data/tmp/
dfs
[root@server5 hadoop]# ls /opt/data/tmp/dfs/name/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
- 启动角色
将/opt/hadoop-2.8.5/sbin导入环境变量
[root@server5 ~]# vim /etc/profile
[root@server5 ~]# tail -1 /etc/profile
PATH=$PATH:/opt/hadoop-2.8.5/sbin
[root@server5 ~]# . /etc/profile
启动角色
[root@server5 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/hadoop-2.8.5/logs/hadoop-root-namenode-server5.out
[root@server5 ~]# hadoop-daemon.sh start datanode
starting datanode, logging to /opt/hadoop-2.8.5/logs/hadoop-root-datanode-server5.out
查看java进程,验证启动
[root@server5 ~]# jps
5072 DataNode
5157 Jps
4941 NameNode
- hdfs文件测试
[root@server5 ~]# hdfs dfs --help
--help: Unknown command
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
创建目录
[root@server5 ~]# hdfs dfs -mkdir /test
查看
[root@server5 ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2021-12-19 16:30 /test
上传文件
[root@server5 ~]# echo 'this is a test file' > 1.txt
[root@server5 ~]# hdfs dfs -put 1.txt /test
[root@server5 ~]# hdfs dfs -ls /test
Found 1 items
-rw-r--r-- 1 root supergroup 20 2021-12-19 16:32 /test/1.txt
读取文件内容
[root@server5 ~]# hdfs dfs -cat /test/1.txt
this is a test file
下载文件
[root@server5 ~]# rm -rf 1.txt
[root@server5 ~]# hdfs dfs -get /test/1.txt
[root@server5 ~]# cat 1.txt
this is a test file
- 配置yarn
[root@server5 ~]# cd /opt/hadoop-2.8.5/etc/hadoop/
[root@server5 hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@server5 hadoop]# vim mapred-site.xml
[root@server5 hadoop]# tail -7 mapred-site.xml
<configuration>
<!-- 指定运行框架为yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@server5 hadoop]# vim yarn-site.xml
[root@server5 hadoop]# tail -12 yarn-site.xml
<configuration>
<!-- 指定resourcemanager运行在hd1节点上 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd1</value>
</property>
<!-- 指定yarn的默认洗牌方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 启动yarn
[root@server5 hadoop]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/hadoop-2.8.5/logs/yarn-root-resourcemanager-server5.out
[root@server5 hadoop]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/hadoop-2.8.5/logs/yarn-root-nodemanager-server5.out
[root@server5 hadoop]# jps
5072 DataNode
8565 ResourceManager
8392 NodeManager
4941 NameNode
8781 Jps
- 词频统计,验证
[root@server5 hadoop]# hadoop jar /opt/hadoop-2.8.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /test/2.txt /output/00
21/12/19 20:42:49 INFO mapreduce.Job: Counters: 13
Job Counters
Failed map tasks=4
Killed reduce tasks=1
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=13
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=13
Total time spent by all reduce tasks (ms)=0
Total vcore-milliseconds taken by all map tasks=13
Total vcore-milliseconds taken by all reduce tasks=0
Total megabyte-milliseconds taken by all map tasks=13312
Total megabyte-milliseconds taken by all reduce tasks=0
# 报错信息
Container launch failed for container_1639916924136_0003_01_000002 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
报错:Container launch failed for container_1639916924136_0003_01_000002 : org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:mapreduce_shuffle does not exist
原因:yarn-site.xml配置文件编写不正确
解决:如下
- 重新修改yarn-site.xml
[root@server5 hadoop]# vim yarn-site.xml [root@server5 hadoop]# tail -12 yarn-site.xml <configuration> <!-- 指定resourcemanager运行在hd1节点上 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hd1</value> </property> <!-- 指定yarn的默认洗牌方式 -->