索引的访问-SQL Server
Posted nogos
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了索引的访问-SQL Server相关的知识,希望对你有一定的参考价值。
目录
全表扫描
无序扫描
表扫描/无序聚集索引扫描
表扫描或无序聚集索引扫描都连续地扫描表中的所有数据页。
表扫描
在堆上进行无序全表扫描称为表扫描。
例如,Order表按堆结构组织(没有聚集索引),执行如下查询:
SELECT orderid, custid, empid, shipperid, orderdate FROM Orders;

SQL Server将根据该表的IAM页指示磁臂按物理顺序扫描属于该表的区,逻辑读取数等于该表所包含的页数。但是在这种扫描中,SQL Server通常使用非常高效的预读策略(针对连续I/O),利用该策略可以在大于8 KB(页)的大块(区)中读取数据,因此实际读取数会小于该表所包含的页数。磁盘读取的时间主要在磁臂的移动,读取一个页与读取一个区的区别不大。
无序聚集索引扫描
在聚集表上进行无序全表扫描称为无序聚集索引扫描。尽管表上有聚集索引,SQL Server仍然使用聚集索引(聚集表)的IAM页来连续地扫描数据,这就意味着该访问方法并不依赖于维护聚集索引逻辑顺序的链接列表,而是按聚集索引叶级页在磁盘上的物理顺序进行。
因为该操作与表扫描没有什么不同,所以统称表扫描。

无序覆盖非聚集索引扫描
无序覆盖非聚集索引扫描概念类似于无序聚集索引扫描。覆盖索引表示非聚集索引(索引列)包含查询中的所有列。换句话所,覆盖索引不是一个具有特殊属性的索引,而是关于特定查询的覆盖索引。SQL Server只访问索引数据(非聚集索引叶级页)就可以找到满足查询所需要的全部数据,而不用访问完整的数据行。另一方面,该访问方法与无序聚集索引扫描相同,只不过覆盖非聚集索引的叶级比聚集索引的叶级包含的页要少,因此行的大小更小(只包含索引列),每个页可以容纳更多的行。
例如,Order表在orderid列上具有非聚集索引,这就意味着该表的所有orderid (订单ID)都位于非聚集索引的叶级上,也就是说非聚集索引覆盖了上面的查询。执行如下查询:
SELECT orderid FROM Orders;
SQL Server使用非聚集索引的IAM页来连续扫描非聚集索引的叶级页,按照非聚集索引的叶级页在磁盘中的物理顺序进行访问。

有序扫描
有序聚集索引扫描
有序聚集索引扫描是按链接列表对聚集索引叶级执行的完整扫描。
例如,Order表在orderdate列上具有聚集索引,执行如下查询:
SELECT orderid, custid, empid, shipperid, orderdate
FROM Orders
ORDER BY orderdate;
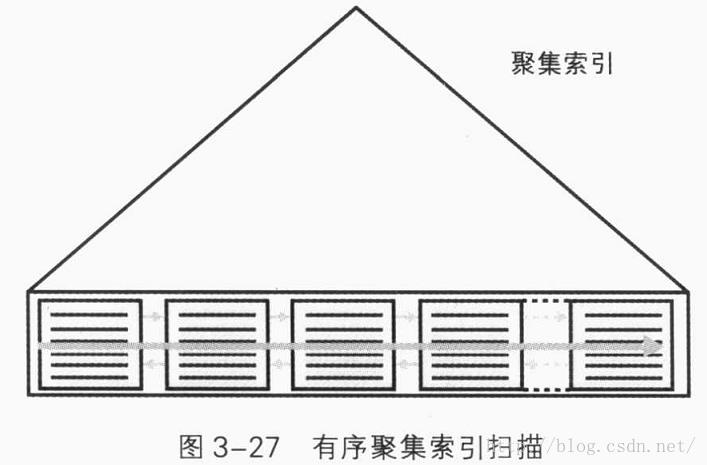
不同于无序索引扫描,有序扫描的性能取决于索引的碎片级别。也就是说,索引叶级别中无序页占总页数的百分比。无序页是指,根据链接表逻辑上出现在一页后面,但物理上却在其前面的。对于没有碎片的索引,有序索引扫描的性能接近于无序扫描,因为两者都是连续地读取物理上的数据。然而,随着碎片级别越来越高,他们性能差异就越来越显著。当然,无序扫描性能更高。
有序覆盖非聚集索引扫描
有序覆盖非聚集索引扫描概念上类似于有序聚集索引扫描,只不过前者只需要访问非聚集索引叶级页。因为只涉及更少的页,它的成本肯定比聚集索引扫描低。
例如,Order表在orderid列上具有非聚集索引,并且非聚集索引覆盖了我们的查询,执行如下查询:
SELECT orderid FROM Orders ORDER BY orderid;

局部扫描
有序扫描
非聚集索引查找+有序局部扫描+lookups
这种访问方式通常用于小范围查询(包括点查询),且用到的非聚集索引没有覆盖该查询。
第一步,在非聚集索引内执行查找以定位被查询范围的第一个键(orderid=101)。
第二步,从该范围内的第一个键开始在叶级别执行有序局部扫描,直到找到最后一个键。
第三步,为找的每个键查找(lookup)对应的数据行。
注意第三步不需要等到第二步执行完。对于该范围内找到的每个键都应用lookup,在堆中执行lookup只需读取一页,而聚集表中执行lookup所读取的页数等于聚集索引的级数。
这种访问方法中,第三步lookup操作通常会占查询成本的一大部分,因为它涉及大量的I/O,理解这一点对评估性能很重要。Lookup为每个找到的键在堆中读取一页或在聚集索引中执行完整的查找(seek),而且lookup总是随机的I/O(不是连续I/O)。
要估算这种查询的I/O成本,你通常可以重点关注lookups的成本,如果你想要更精确的估计I/O成本,还可以考虑对非聚集索引的查找和有序局部扫描。不过随着范围越来越大,这部分的成本可以忽略不计。一次非聚集索引的查找操作的成本大约是3(非聚集索引的级数)次逻辑读取。有序局部扫描的I/O成本取决于该范围内的行数和非聚集索引叶级页可容纳的行数。一般局部扫描实际上并不包含额外的读取,因为我们查找范围内的所有键一般都位于查找操作所到达的叶级页,或者在链接列表随后的一页或多页。Lookups操作的I/O成本等于该范围内的行数乘以一次lookup的成本。对于堆上的lookup,成本为一次逻辑读取。对于聚集表上的lookup,逻辑读取数为聚集索引的级数。由于在聚集表中的所有的lookup操作都会查询聚集索引的非叶级,聚集索引的非叶级通常位于缓存,所以你不用过于担心在聚集表中进行lookup表面上的高成本。
在堆上应用
例如,Orders表(按堆组织)在orderid列上具有非聚集索引,但是该索引没有覆盖如下查询。
SELECT orderid, custid, empid, shipperid, orderdate
FROM Orders
WHERE orderid BETWEEN 101 AND 120;

在聚集表上应用
例如,Orders表在orderid列上具有聚集索引,在orderdate列上具有非聚集索引,表中没有覆盖该查询的索引。
SELECT orderid, custid, empid, shipperid, orderdate
FROM Orders
WHERE orderdate >= '20060101' AND orderdate < '20070101';

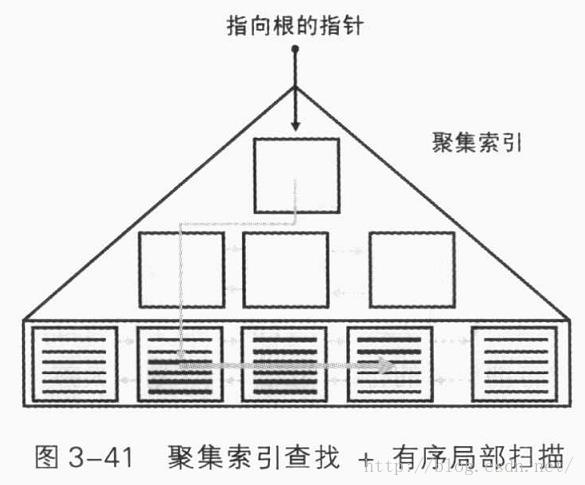
聚集索引查找+有序局部扫描
对于按聚集索引的第一个键列进行筛选的范围查询,采用这种访问方法。这种方法先执行查找操作(seek)找到该范围内的第一个键,然后在聚集索引叶级应用局部扫描,从第一个键扫描到最后一个键。这种方法主要好处是它不涉及lookups。对于较大的范围,lookups的成本非常高,随着范围的越来越大,不涉及lookups的访问方法和使用非聚集索引及lookups的访问方法在性能方面差异会越来越大。
例如,表Orders在(orderdate,orderid)上具有聚集索引。执行如下查询:
SELECT orderid, custid, empid, shipperid, orderdate
FROM Orders
WHERE orderdate = '20060212';
虽然筛选器使用了等于运算符,但它本质上还是一个范围查找,因为表中存在多个符合条件的行,点查询也可以被看作是范围查询的一个特例。这种访问方法的成本包括在聚集索引上的查找成本(聚集索引级数)和聚集索引叶级页内有序局部扫描的成本。有序扫描通常占查询成本的大部分,因为它涉及大部分的I/O。对于有序索引扫描,索引碎片具有至关重要的作用。当碎片处于最低级别,物理读取几乎是连续的。不过随着碎片级别不断增大,磁臂必须疯狂地来回移动,从而严重降低扫描的性能。
覆盖非聚集索引查找+有序局部扫描
覆盖非聚集索引查找+有序局部扫描这种访问方法几乎与上一个访问方法相同,唯一的区别是前者使用覆盖非聚集索引,而不是聚集索引。要使用这种方法,被筛选列必须是索引的第一个键列。相对于上一个方法,这个访问方法的好处是在于非聚集索引的一个叶级页可以比聚集索引的一个页级页容纳更多的行,因此该访问方法的大部分成本,即叶级的局部扫描成本显得更低,即在相同范围内,被扫描的页更少,当然索引碎片也对性能有重要的影响,因为局部扫描是有序的。
例如,表Orders在(custid,orderdate)具有非聚集索引,并且该聚集索引覆盖了如下查询。
SELECT orderdate, custid
FROM Orders
WHERE custid= 'C0000000001' AND orderdate >= '20060101' AND orderdate < '20070101';

无序扫描
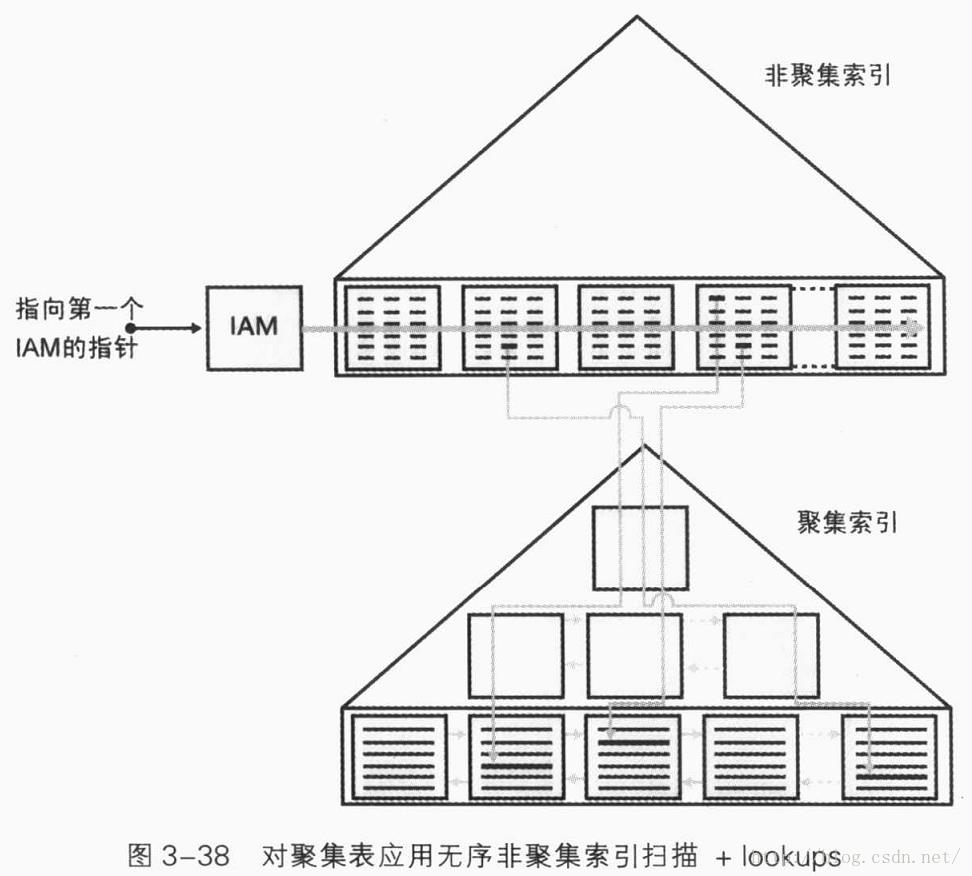
无序非聚集索引扫描+lookups
适用条件:
1、该查询的选择性足够高。选择性被定义为查询返回的行占表中总行数的百分比。
2、非聚集索引没有按顺序维护被查找的键。例如,当你筛选的列不是非聚集索引的第一个键列时就属于这种情况。
该访问方法将对索引叶级执行无序的完全扫描,然后再执行一系列的lookups。查询的选择性必须足够高才能适用这种访问方法,否则,太多的lookup会使得该方法访问成本比直接扫描整个表还高。要计算查询的选择性,SQL Server需要有被筛选列的统计信息(包含值分布的直方图)。
该查询的成本包括对非聚集索引的无序扫描(使用IAM页的连续I/O)成本和lookups成本(随机I/O)。扫描非聚集索引的页数等于非聚集索引叶级的页数。lookups的成本等于符合条件的行数乘以一次lookup的成本。在堆上lookup成本为1次页读取,在聚集表上,逻辑读取数为聚集索引的级数。
在堆上的应用
例如,表Order上具有非聚集索引(orderdate ,custid),其中custid不是非聚集索引中的第一个键列。执行如下查询:
SELECT orderid, custid, empid, shipperid, orderdate FROM Orders WHERE custid = 'C0000000001';

在聚集表上的应用
例如,表Order上具有非聚集索引(orderdate ,custid),其中custid不是非聚集索引中的第一个键列,此外表Order在列orderid上有聚集索引。执行如下查询:
SELECT orderid, custid, empid, shipperid, orderdate FROM Orders WHERE custid = 'C0000000001';
以上是关于索引的访问-SQL Server的主要内容,如果未能解决你的问题,请参考以下文章