)
Posted wyy_persist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了)相关的知识,希望对你有一定的参考价值。
ImageNetBundle阅读笔记
//2022.2.4日上午11:50开始阅读
2.介绍
欢迎访问Python计算机视觉深度学习ImageNet包,这是该系列的最后一卷。这本书在内容方面是最先进的,涵盖的技术将使你能够重现最先进的出版物、论文和谈话的结果。为了使这项工作有条理,我将ImageNet Bundle分为两部分。
在第一部分,我们将详细探索ImageNet数据集,并学习如何训练最先进的深度网络,包括AlexNet, VGGNet, GoogLeNet, ResNet,和SqueezeNet从scratch,获得尽可能相似的精度作为各自的原始作品。为了实现这个目标,我们需要从Starter Bundle和实践者Bundle中调用我们所有的技能。
我们需要确保理解卷积神经网络的基本原理,特别是层类型和正则化,因为我们要实现一些更“奇特”的架构。幸运的是,您已经在实践者包中看到了这些深层架构的更浅层的实现,因此实现VGGNet、googlet和ResNet之类的网络会有点熟悉。
我们还需要确保我们能够轻松地处理训练过程,因为我们很容易在ImageNet数据集上过度适应我们的网络架构,特别是在后期。学习如何正确监测损失和精度图,以确定是否/何时应该更新参数更新是一项需要掌握的技能,因此,为了帮助您更快地发展这一技能,并在大型、具有挑战性的数据集上训练深入的架构,我将这些章节作为应用科学方法的“实验期刊”来编写。
在每个章节中,你会发现:
- 和我训练这个网络时使用的完全一样。
- 特定的结果。
- 我决定在下次实验中做的改变。
因此,每一章读起来就像一个“故事”:你会发现什么对我有效,什么不有效,以及最终什么获得了最好的结果,使我能够复制给定出版物的工作。读完这本书后,您将能够使用这些知识在ImageNet上从头开始训练您自己的网络架构,而不会浪费几周(甚至几个月)的时间来调整参数。
本书的第二部分侧重于案例研究——应用深度学习和计算机视觉解决特定问题的实际应用。首先,我们将从零开始训练CNN来识别实时视讯流中人们的情绪/面部表情。然后,我们将通过特征提取使用迁移学习来自动检测和纠正图像方向。第二个关于迁移学习的案例研究(这次是通过微调)将使我们能够在图像中识别超过164个汽车品牌和车型。这样的模型可以使您创建一个“智能”高速公路广告牌系统,该系统根据驾驶的车辆类型向驾驶员显示目标信息或广告。我们最后的案例研究将演示如何训练CNN正确预测照片中一个人的年龄和性别。
最后,我想提醒您,本卷中涉及的技术比Starter Bundle和实践者Bundle都要高级得多。前两卷书都给了你成功阅读这本书所需的知识,但这一点是你从深度学习实践者和真正的深度学习大师分开的地方。要想最终转变为深度学习专家,只需翻开这一页。
3.使用多gpu的训练网络
在大规模数据集上训练深度神经网络可能需要很长时间,甚至单个实验也可能需要几天时间才能完成。为了加快训练过程,我们可以使用多个gpu。虽然后端如Theano和TensorFlow(以及Keras)确实支持多GPU训练,但设置多GPU实验的过程是艰巨而非繁琐的。我确实希望这个过程在未来变得更好,变得更容易。
因此,对于深度神经网络和大型数据集,我强烈建议使用mxnet库[5],我们将在本书其余部分的大部分实验中使用它。mxnet深度学习库(用c++编写)提供了对Python编程语言的绑定,并专门从事分布式、多机器学习——当在大规模数据集(如ImageNet)上训练最先进的深度神经网络体系结构时,跨gpu /设备/节点并行化训练的能力至关重要。
mxnet库也很容易使用——考虑到您使用过本书前几章中的Keras库的背景,您会发现使用mxnet非常简单、直接,甚至非常自然。
需要注意的是,ImageNet Bundle中的所有神经网络都可以使用单个GPU进行训练——唯一需要注意的是时间。有些网络,如AlexNet和SqueezeNet,只需要几天时间就可以在单个GPU上进行训练。其他架构,如VGGNet和ResNet,在单个GPU上训练可能需要一个多月的时间。
在本章的第一部分,我将重点介绍我们将讨论的网络架构,它们可以很容易地在单个GPU上进行训练,以及哪些架构应该在可能的情况下使用多个GPU。然后,在本章的后半部分,我们将研究在使用多个gpu训练卷积神经网络时可以预期的一些性能增益。
3.1 我需要多少gpu ?
如果你问任何经验丰富的深度学习从业者,在一个大数据集上训练一个相当深度的神经网络需要多少gpu,他们的回答几乎总是“越多越好”。使用多个gpu的好处是显而易见的——并行化。我们的gpu越多,我们能越快地训练一个特定的网络。然而,我们中的一些人在阅读本书时可能只有一个GPU。这就提出了问题:
- 仅仅使用一个GPU是徒劳的吗?
- 阅读这一章是浪费时间吗?
- 购买ImageNet Bundle是一项糟糕的投资吗?
所有这些问题的答案都是响亮的“不”——您在这里学到的知识将适用于您自己的深度学习项目。然而,您确实需要管理您的期望,并意识到您正在跨越一个门槛,一个将教育深度学习问题与先进的、现实世界的应用程序分开的门槛。你现在进入的是最先进的深度学习世界,在这里,实验可能需要几天、几周,甚至在极少数情况下,需要几个月才能完成——这个时间线是完全正常的。
无论你有一个GPU还是八个GPU,你都可以复制本章中详细描述的网络的性能,但是,再次记住时间的警告。gpu越多,训练的速度就越快。如果你有一个单独的GPU,不要沮丧-只要耐心和理解这是过程的一部分。ImageNet Bundle的主要目标是为您提供实际的案例研究和如何在具有挑战性的ImageNet数据集上训练最先进的深度神经网络的详细信息(以及一些额外的应用程序)。无论您拥有一个GPU还是八个GPU,您都将能够从这些案例研究中学习并在您自己的应用程序中使用这些知识。
对于使用单一GPU的读者,我强烈建议您将大部分时间花在ImageNet数据集上训练AlexNet和SqueezeNet。这些网络更浅,在单个GPU系统上训练速度更快(AlexNet需要3-6天,SqueezeNet需要7-10天,这取决于你的机器)。更深层的卷积神经网络,如GoogLeNet,也可以在单个GPU上进行训练,但可能需要7-14天。
ResNet的较小变体也可以在单个GPU上进行训练,但对于本书中介绍的更深入的版本,我建议使用多个GPU。
我不推荐的唯一网络体系结构试图使用一个训练GPU VGGNet——它不仅能优化网络是一个痛苦hyperparameters(我们将在这本书的后面看到),但网络非常慢,由于其深度和全连通的节点的数量。如果您决定从头开始培训VGGNet,请记住,培训网络可能需要多达14天的时间,即使使用4个gpu。
正如我在本节前面提到的,你现在已经跨越了从深度学习从业者到深度学习专家的门槛。我们正在研究的数据集是巨大的,具有挑战性的——我们将在这些数据集上训练的网络是深刻的。随着深度的增加,执行向前和向后传递所需的计算也会增加。现在花一秒钟的时间来设定你的期望,这些实验不是你可以在一夜之间跑完,然后第二天早上再收集结果——你的实验将会花更长的时间来跑。这是每个深度学习研究者都必须接受的事实。
但是,即使您在单个GPU上训练自己的最先进的深度学习模型,也不要担心。我们在多个gpu上使用的技术也可以应用到单个gpu上。ImageNet Bundle的唯一目的是为您提供在自己的项目中成功应用深度学习所需的知识和经验。
3.2 使用多个gpu获得性能
在理想的情况下,如果给定数据集和网络架构的单个epoch在单个GPU上需要N秒完成,那么我们期望两个GPU的相同epoch在N/2秒内完成。然而,实际情况并非如此。培训性能严重依赖于系统上的PCIe总线、您正在培训的特定架构、网络中的层数,以及您的网络是通过计算还是通信绑定的。
一般来说,使用两个gpu进行训练可以提高约1.8倍的速度。当使用4个gpu时,根据您的系统[6],性能扩展到≈2.5 - 3.5倍。因此,培训不会随着系统上gpu的数量线性减少。与依赖于通信(即较小的批处理大小)的网络相比,受计算约束的体系结构(更大的批处理大小随着gpu数量的增加而增加)将更好地适应多个gpu,因为延迟开始在性能下降中发挥作用。
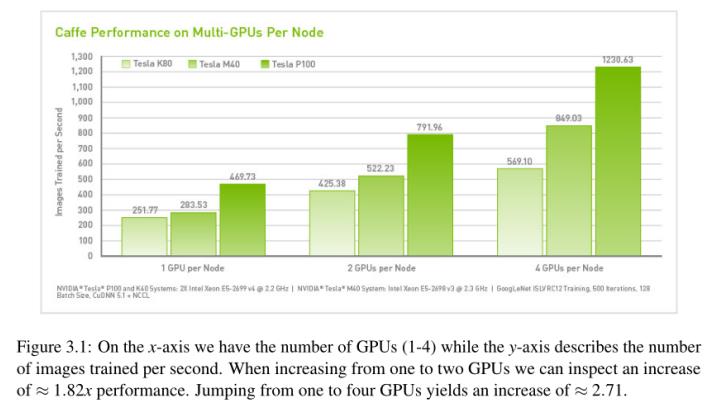
为了进一步研究GPU扩展,让我们看看NVIDIA在图3.1中发布的官方基准测试。在这里,我们可以看到三种类型的gpu(特斯拉K80,特斯拉M40和特斯拉P400),使用Caffe[7]深度学习库在ImageNet数据集上训练GoogLeNet。x轴表示gpu的数量(分别为1、2和4),y轴表示每秒训练的图像数量(向前和向后)。从一个GPU切换到两个GPU,平均性能提高≈1.82倍。当1个GPU与4个GPU比较时,性能≈2.71x。
性能将继续增加更多的GPU被添加到系统,但是,请记住,训练速度不会与GPU数量成线性比例——如果你训练一个网络使用一个GPU,然后使用四个GPU,train一遍不要期望的时间需要训练网络减少四倍。也就是说,通过使用更多gpu来训练深度学习模型可以获得性能上的提升,所以如果你有可用的gpu,请务必使用它们。
3.3 总结
在本章中,我们讨论了使用多个gpu来训练深度学习架构的概念。为了完成本书中的大部分实验,我们将使用mxnet库,该库对多gpu训练进行了高度优化。考虑到您在本书的前几章中使用Keras库的经验,您会发现使用mxnet是很自然的,因为函数名和类名非常相似。
在那里,我们讨论了使用单个GPU和多个GPU训练网络时的基本期望。是的,用一个GPU在一个大数据集上训练一个深层网络需要更长的时间,但不要气馁-同样的技术,你使用的单个GPU实例将适用于多GPU实例,以及。请记住,您现在正在跨越深度学习从业者到深度学习专家的门槛——我们在这里进行的实验将更具挑战性,需要更多的时间和精力。就像所有深度学习研究者在他们的职业生涯中所做的那样,现在就设定这个期望。
在第6章中,我们将在ImageNet数据集上训练我们的第一个卷积神经网络AlexNet,复制Krizhevsky等人在2012年的开创性工作[8]中的性能,该工作永远改变了图像分类的前景。
4.ImageNet是什么?
在本章中,我们将讨论ImageNet数据集和相关的ImageNet大规模视觉识别挑战(ILSVRC)[9]。这一挑战实际上是评估图像分类算法的基准。自2012年Krizhevsky等人发表了他们在AlexNet上的开创性工作[8]以来,ILSVRC的排行榜一直由卷积神经网络和深度学习技术主导。
4.1 ImageNet数据集
在计算机视觉和深度学习社区中,您可能会对ImageNet是什么和不是什么感到困惑。ImageNet实际上是一个项目,它的目标是根据一组定义的单词和短语,将图片归类到22,000个类别中。在撰写本文时,ImageNet项目中有超过1400万张图片。
ImageNet是如何组织的呢?为了对如此大量的数据进行排序,ImageNet实际上遵循WordNet的层次结构[10]。WordNet内部的每个有意义的单词/短语称为“同义词集”或简称为synset。在ImageNet项目中,图像是根据这些synsets进行分类的;该项目的目标是每个synset拥有1000 +图像。
4.1.1 ILSVRC
在计算机视觉和深度学习的背景下,每当你听到人们谈论图像网,他们很可能指的是ImageNet大规模视觉识别挑战[9],简称ILSVRC。在这个挑战中,图像分类跟踪的目标是训练一个模型,能够正确地将图像分为1000个单独的对象类别,其中一些被认为是细粒度分类,其他则不是。ImageNet数据集中的图像是通过编译之前的数据集和抓取流行的在线网站收集的。然后对这些图像进行手动标记、注释和标记。
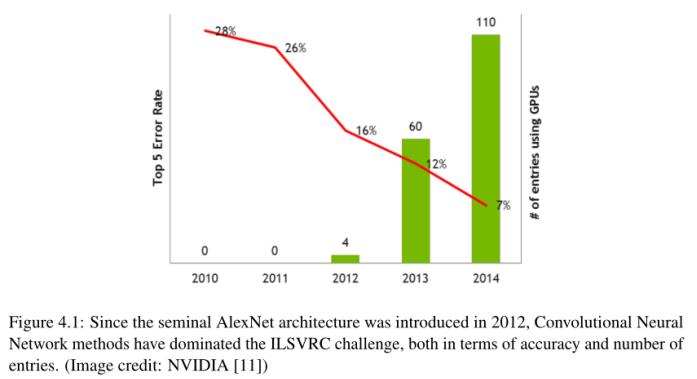
自2012年引入开创性的AlexNet架构以来,卷积神经网络方法一直主导着ILSVRC的挑战,无论是在准确性还是条目数量方面。(图片来源:NVIDIA [11])
自2012年以来,ILSVRC挑战的排行榜一直由基于深度学习的方法主导,秩1和秩5的准确率每年都在增加(图4.1)。模型在120万张训练图像上进行训练,另外有5万张图像用于验证(每个同步集50张图像)和10万张图像用于测试(每个同步集100张图像)。
这1000个图像类别代表了我们在日常生活中可能遇到的各种物体类别,比如狗、猫、各种家居用品、车辆类型等等。您可以在ImageNet官方文档页面(http://pyimg.co/1ogm0)上找到ILSVRC挑战中对象类别的完整列表。
在Starter Bundle的第5章中,我展示了来自ImageNet大规模视觉识别挑战的ImageNet数据集的一些挑战。与通用的“鸟”、“猫”和“狗”类不同,ImageNet包含了比以前的图像分类基准数据集(如PASCAL VOC[12])更细粒度的类。PASCAL VOC将“狗”限制在单一类别,而ImageNet则包含120种不同品种的狗。这种手指分类要求意味着,我们的深度学习网络不仅需要将图像识别为“狗”,还需要有足够的辨别能力来确定狗的种类。
此外,ImageNet中的图像在对象尺度、实例数量、图像杂波/遮挡、可变形性、纹理、颜色、形状和真实世界的大小上变化很大。至少可以说,这个数据集是具有挑战性的,在某些情况下,甚至人类也很难正确地进行标记。由于这个数据集具有挑战性,在ImageNet上表现良好的深度学习模型很可能可以很好地推广到验证和测试集之外的图像——这正是我们将迁移学习应用到这些模型的确切原因。
在第5章中,当我们开始探索ImageNet数据集并编写代码来为训练图像做准备时,我们将讨论更多图像和特定类的例子。然而,在此之前,我强烈建议您花10-20分钟在web浏览器中浏览synsets (http://pyimg.co/1ogm0),以了解正确分类这些图像的规模和挑战。
4.2 得到ImageNet数据集
ImageNet分类挑战数据集相当大,训练图像的权重为138GB,验证图像的权重为6.3GB,测试图像的权重为13GB。在您下载ImageNet之前,您首先需要获得访问ILSVRC挑战的权限,并下载图像和相关的类标签。本节将帮助您获得ImageNet数据集。
4.2.1 获得ILSVRC的权限
ILSVRC的挑战是普林斯顿大学和斯坦福大学的联合工作,因此,是一个学术项目。ImageNet并不拥有这些图像的版权,并且只允许在非商业研究和/或教育目的下访问原始图像文件(尽管这一点有待讨论——见下面的4.2.5节)。如果你属于这一阵营,你可以简单地在ILSVRC网站(http://pyimg.co/fy844)注册一个帐户。
然而,请注意ImageNet不接受免费提供的电子邮件地址,如Gmail、Yahoo等,你需要提供你的大学或政府/研究机构的电子邮件地址。如图4.2所示,我只需要提供我的大学电子邮件地址,这样我就可以验证我的电子邮件地址,然后接受访问条款。

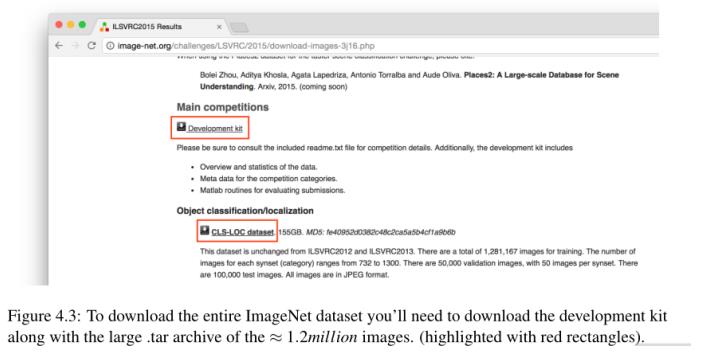
一旦您接受了访问条款,您就可以访问下载原始图像页面-点击ILSVRC 2015图像数据链接。从那里确保你下载了Development Kit,一个包含README的.zip文件,关于培训/测试分割的信息,不应该用于培训的黑名单文件,等等(图4.3)。
然后,您需要下载CLS-LOC数据集,其中包含ImageNet数据集中的120万张图像(图4.3)。请记住,这是一个较大的文件,根据您的互联网连接(和image-net.org的稳定性),这个下载可能需要几天时间。我个人的建议是使用wget命令行程序下载存档,使您能够从停止下载的地方重新开始下载,以防出现连接问题(可能会有一些连接问题)。解释如何使用wget超出了本书的范围,所以请参考下面的页面,了解如何使用wget重新启动下载(http://pyimg.co/97u59)。
下载了.tar文件后,下一步就是解压缩它,这也是一个计算成本很高的过程,因为您需要解压缩120万张图像——我建议让您的系统在夜间处理这个任务。
4.2.2 编程下载图片
如果您被拒绝访问ILSVRC的原始图像数据,不要担心——还有其他方法可以获取数据,尽管这些方法稍微乏味一些。记住ImageNet不“拥有”数据集内的图像,因此他们可以自由分发图像的url。数据集中每一个图像的URL(一个。txtfile,每行一个URL)可以在这里找到:

同样,您需要使用wget来下载图像。在这里,你可能会遇到一个常见的问题,即一些图片url可能天生就有404,因为最初的web抓取,你无法访问它们。因此,以编程方式下载图像会非常繁琐,我不推荐这种方法。但是不要担心——还有另一种方法可以获得ImageNet。
4.2.3 使用额外的服务
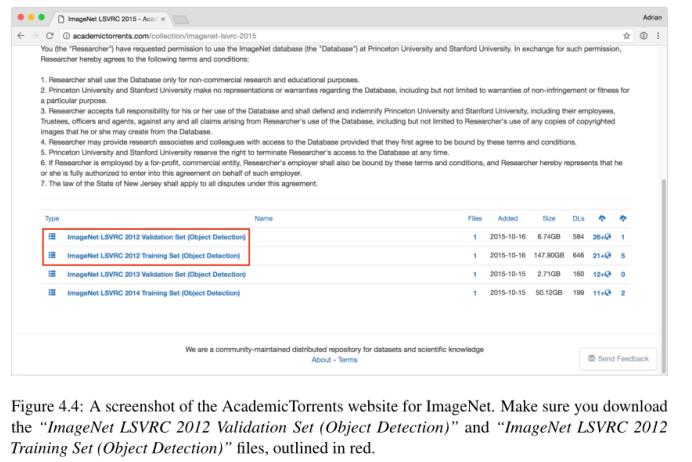
由于ImageNet数据集的巨大规模和需要它在全球范围内分布,该数据集适合通过BitTorrent进行分布。网站AcademicTorrents.com为培训集和验证集提供下载(http://pyimg.co/asdyi)[13]。网页的截图如图4.4所示。
测试集不包括在种子中,因为我们将不能访问ImageNet评估服务器提交我们对测试数据的预测。请记住,即使您使用外部服务,如AcademicTorrents来下载ImageNet数据集,您仍然会隐式地受到访问条款的约束。你可以使用ImageNet来研究和开发你自己的模型,但你不能重新打包ImageNet并使用它来盈利——这是一个严格的学术数据集,由斯坦福大学和普林斯顿大学的合资企业提供。尊重科学界,不要违反获取条款。
4.2.4 ImageNet开发工具包
当你下载实际的ImageNet数据集时,请确保你下载了ImageNet开发工具包(http://pyimg.co/wijj7),我们以后简单地称它为“DevKit”。
我还在这里放置了一个DevKit的镜像:http://pyimg.co/ounw6
DevKit包含:
- 数据集的概述和统计信息。
- 类别的元数据(允许我们构建从imagefilename到类标签的映射)。
- MATLAB程序的评估(我们将不需要)。
DevKit是一个只有7.4MB的小下载,应该在几秒钟内完成。下载完DevKit后,将其解压缩,并花些时间熟悉目录结构,包括许可(copy)和readme.txt。我们将在下一章中详细回顾DevKit,当我们构建ImageNet数据集并为训练CNN做准备时。
4.2.5 ImageNet 版权问题
乍一看,ImageNet数据集和相关的ILSVRC挑战似乎是一个版权声明的雷区——谁到底拥有ImageNet数据集中的什么?为了回答这个问题,让我们将问题分解为三种具体的资产类别:
- 资产#1:图像本身。
- 资产#2:预编译的ILSVRC数据集。
- 资产#3:通过在ILSVRC上训练一个网络获得的输出模型权重。
首先,原始图像本身属于捕获图像的人/实体——他们拥有这些图像的全部版权。ImageNet项目的运作受到和搜索引擎一样的限制,如谷歌,必应等,他们被允许提供原始版权图片的链接,前提是保留版权。这就是为什么ImageNet网站可以在不要求你注册和创建帐户的情况下提供数据集中原始图像的url——实际上下载它们是你的责任。
这个过程似乎相当清晰;然而,一旦我们看到ILSVRC的实际挑战,水就开始变得浑浊了。由于最终用户不再负责逐一下载每个图像(而是可以下载数据集的整个存档),我们就会遇到版权问题——为什么用户可以下载(可能)受版权保护的图像的预编译存档?这是否侵犯了拍摄照片原件的人的版权?这是艺术界和科学界争论的焦点,但就目前而言,我们是被允许下载ILSVRC图像档案,由于我们在参与ILSVRC时接受的访问条款:
- 您可以自由地将ImageNet数据集用于学术和非商业用途。
- 您不能将ILSVRC数据作为最终产品的一部分分发。
最初的版权问题没有被直接回答,但是在预先编译的数据集存档上设置的限制在一定程度上平息了这个问题。此外,ImageNet网站还为那些希望将自己的图像从数据集中删除的版权所有者提供了DMCA删除申请。
最后,让我们来看看资产#3,在ImageNet数据集上训练卷积神经网络后,给定模型的序列化权重——这些模型权重也受版权保护吗?
答案是有点不清楚,但据我们目前对法律的理解,没有限制的开放版本学模型权重[14]因此,我们是免费分发训练模型我们seefit,只要我们记住合理使用的精神和正确的归因。
我们被允许发布我们自己的模型(甚至使用我们自己的限制对它们进行版权保护)的原因是由于参数化学习(Starter Bundle,第8章)——我们的CNN不存储原始图像的“内部副本”(比如k-NN算法)。由于模型不存储原始图像(无论是全部还是部分),因此模型本身不受原始ImageNet数据集相同版权声明的约束。因此,我们可以自由地分配我们的模型权重,或者对它们赋予额外的版权(例如,最终用户可以自由地使用我们现有的体系结构,但是在将其用于商业应用程序之前,必须在原始数据集上从头开始重新训练网络)。
但是,在ImageNet上训练的用于商业应用的模型呢?
在ImageNet数据集上训练并用于商业应用程序的模型是否违反了访问条款?根据访问条款的措辞,是的,从技术上讲,这些商业应用程序有违反合同的风险。
另一方面,对于使用ImageNet数据集从零开始培训自己的网络的深度学习公司/初创公司,还没有人提起过诉讼。请记住,版权是没有权力的,除非它被强制执行- ImageNet从来没有这样的强制执行。
简而言之:这是深度学习领域的一个灰色地带。有大量的深度学习初创公司依赖于在ImageNet数据集上训练的cnn(故意省略公司名称)——他们的收入完全基于这些网络的性能。事实上,如果没有ImageNet和ILSVRC,这些公司就不会有创建他们的产品所需的数据集(除非他们自己投资了数百万美元和多年来收集和注释数据集)。
作者的观点
作者的观点是,ImageNet数据集的合理使用有一套不言而喻的规则。作者相信这些规则如下(尽管肯定有很多人不同意作者的观点):
规则#1:您需要通过某种方式获取ILSVRC数据集,并接受(显式或隐式)访问条款
规则2:在获得ILSVRC挑战相关的数据后,你需要在数据集上训练你自己的卷积神经网络。您可以自由地使用现有的网络架构,如AlexNet、VGGNet、ResNet等,只要您在ILSVRC数据集上从头开始训练网络。您不需要开发新的网络架构。
规则3:一旦你获得了你的模型权重,你就可以根据你自己的限制来分配它们,包括开放访问,使用属性,甚至是被限制的商业用途。
第三条规则将会受到激烈的争论,我肯定我会收到很多关于它的电子邮件——但重点是——虽然规则并不明确,但关于如何使用从ILSVRC获得的网络权重,包括商业应用程序,还没有提起诉讼。同样,请记住,版权只有在实际执行时才有效——仅仅持有版权并不能作为一种保护形式。
此外,在ILSVRC上训练的深度学习模型的使用既是一个法律问题,也是一个经济问题——计算机科学行业正在经历深度学习应用的巨大繁荣。如果全面立法通过限制商业使用cnn从头训练在版权图像数据(即使没有复制原始数据的参数化的学习),我们会造成经济的一部分经历高增长和数十亿美元的估值。这种高度限制、广泛的立法方式很容易引发另一个AI冬天(Starter Bundle,第二章)。
关于深度学习社区中“谁拥有什么”的进一步信息(数据集、模型权重等),可以看看深度学习和大数据:谁拥有什么?这是Tomasz Malisiewicz关于[15]主题的一篇优秀文章。
4.3 总结
在本章中,我们回顾了ImageNet数据集和相关的ILSVRC挑战,事实上的基准用于评估图像分类算法。然后,我们研究了获取ImageNet数据集的多种方法。
在本书的其余章节中,我将假设您没有访问测试集和相关的ImageNet评估服务器;因此,我们将从训练数据中推导出我们自己的测试集。这样做将确保我们可以在本地评估我们的模型,并获得一个合理的代理来保证我们的网络的准确性。
现在花点时间开始在您的计算机上下载ImageNet数据集。我建议使用ILSVRC官方挑战网站下载ImageNet数据,因为这种方法是最简单和最可靠的。如果你没有进入大学,政府,或研究附属电子邮件地址,请提出来你的同事再次访问,但请记住,你还绑定到访问,不管你如何获取数据(即使你下载通过AcademicTorrents)。
我的观点是,通过ILSVRC数据集上的训练获得的模型权重可以作为你最适合的使用;但是,请记住,这仍然是一个争论点。在部署利用ImageNet训练的模型的商业应用程序之前,我建议您咨询适当的法律顾问。
在我们的下一章中,我们将探索ImageNet数据集,了解它的文件结构,并编写Python帮助工具来帮助我们从磁盘加载图像,并为训练做准备。
//截止到2022.2.5日晚上17:52
以上是关于)的主要内容,如果未能解决你的问题,请参考以下文章