pandas.dataframe怎么把列变成索引
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas.dataframe怎么把列变成索引相关的知识,希望对你有一定的参考价值。
在dataframe中根据一定的条件,得到符合要求的某行元素所在的位置。
代码如下所示:
[python] view plain copy
df = pd.DataFrame('BoolCol': [1, 2, 3, 3, 4],'attr': [22, 33, 22, 44, 66],
index=[10,20,30,40,50])
print(df)
a = df[(df.BoolCol==3)&(df.attr==22)].index.tolist()
print(a)
df如下所示,以上通过选取“BoolCol”取值为3且“attr”取值为22的行,得到该行在df中的位置注意:返回的位置为index列表,根据index的不同而不同,这点易于数组中默认的下标。
[python] view plain copy
BoolCol attr
10 1 22
20 2 33
30 3 22
40 3 44
50 4 66
[30]
df = pd.read_csv("你的文件名.csv")
df_new_index=df.set_index('要设成索引的列名')#列可以有重复值
Ps. 用索引访问loc函数 df_new_index.loc['索引'] 参考技术B pandas.DataFrame.set_index() 参考技术C
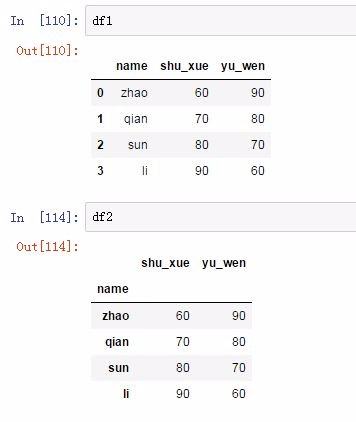
使用set_index函数,示例如下:
from pandas import DataFramedf1 = DataFrame('name': ['zhao', 'qian', 'sun', 'li'], 'yu_wen': [90, 80, 70, 60], 'shu_xue': [60, 70, 80, 90])
df2 = df1.set_index('name')
结果如下:
1.根据字典创造:
In [1]: import pandas as pd
In [3]: aa='one':[1,2,3],'two':[2,3,4],'three':[3,4,5]
In [4]: bb=pd.DataFrame(aa)
In [5]: bb
Out[5]:
one three two
0 1 3 2
1 2 4 3
2 3 5 4`123456789123456789
字典中的keys就是DataFrame里面的columns,但是没有index的值,所以需要自己设定,不设定默认是从零开始计数。
bb=pd.DataFrame(aa,index=['first','second','third'])
bb
Out[7]:
one three two
first 1 3 2
second 2 4 3
third 3 5 412345671234567
2.从多维数组中创建
import numpy as np
In [9]: del aa
In [10]: aa=np.array([[1,2,3],[4,5,6],[7,8,9]])
In [11]: aa
Out[11]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [12]: bb=pd.DataFrame(aa)
In [13]: bb
Out[13]:
0 1 2
0 1 2 3
1 4 5 6
2 7 8 9123456789101112131415123456789101112131415
从多维数组中创建就需要为DataFrame赋值columns和index,否则就是默认的,很丑的。
bb=pd.DataFrame(aa,index=[22,33,44],columns=['one','two','three'])
In [15]: bb
Out[15]:
one two three
22 1 2 3
33 4 5 6
44 7 8 912345671234567
3.用其他的DataFrame创建
bb=pd.DataFrame(aa,index=[22,33,44],columns=['one','two','three'])
bb
Out[15]:
one two three
22 1 2 3
33 4 5 6
44 7 8 9
cc=bb[['one','three']].copy()
Cc
Out[17]:
one three
22 1 3
33 4 6
44 7 912345678910111213141234567891011121314
这里的拷贝是深拷贝,改变cc中的值并不能改变bb中的值。
cc['three'][22]=5
bb
Out[19]:
one two three
22 1 2 3
33 4 5 6
44 7 8 9
cc
Out[20]:
one three
22 1 5
33 4 6
44 7 912345678910111213141234567891011121314
二.DataFrame的索引操作:
对于一个DataFrame来说,索引是最烦的,最易出错的。
.索引一列或几列,比较简单:
bb['one']
Out[21]:
22 1
33 4
44 7
Name: one, dtype: int32123456123456
多个列名需要将输入的列名存在一个列表里,才是个collerable的变量,否则会报错。
bb[['one','three']]
Out[29]:
one three
22 1 3
33 4 6
44 7 9123456123456
2.索引一条记录或几条记录:
bb[1:3]
Out[27]:
one two three
33 4 5 6
44 7 8 9
bb[:1]
Out[28]:
one two three
22 1 2 3123456789123456789
这里注意冒号是必须有的,否则是索引列的了。
3.索引某几列的变量的某几条记录,这个折磨了我好久:
第一种
bb.loc[[22,33]][['one','three']]
Out[30]:
one three
22 1 3
33 4 61234512345
这种不能改变这里面的值,你只是能读值,不能写值,可能和loc()函数有关:
bb.loc[[22,33]][['one','three']]=[[2,2],[3,6]]
In [32]: bb
Out[32]:
one two three
22 1 2 3
33 4 5 6
44 7 8 912345671234567
第二种:也是只能看
bb[['one','three']][:2]
Out[33]:
one three
22 1 3
33 4 61234512345
想要改变其中的值就会报错。
In [34]: bb[['one','three']][:2]=[[2,2],[2,2]]
-c:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_index,col_indexer] = value instead
F:\Anaconda\lib\site-packages\pandas\core\frame.py:1999: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame
return self._setitem_slice(indexer, value)1234512345
第三种:可以改变数据的值!!!
Iloc是按照数据的行列数来索引,不算index和columns
bb.iloc[2:3,2:3]
Out[36]:
three
44 9
bb.iloc[1:3,1:3]
Out[37]:
two three
33 5 6
44 8 9
bb.iloc[0,0]
Out[38]: 1123456789101112123456789101112
下面是证明:
bb.iloc[0:4,0:2]=[[9,9],[9,9],[9,9]]
In [45]: bb
Out[45]:
one two three
22 9 9 3
33 9 9 6
44 9 9 912345671234567
三、在原有的DataFrame上新建一个columns或几个columns
1.什么都不用的,只能单独创建一列,多列并不好使,亲测无效:
bb['new']=[2,3,4]
bb
Out[51]:
one two three new
22 9 9 3 2
33 9 9 6 3
44 9 9 9 4
bb[['new','new2']]=[[2,3,4],[5,3,7]]
KeyError: "['new' 'new2'] not in index"123456789123456789
赋予的list基本就是按照所给index值顺序赋值,可是一般我们是要对应的index进行赋值,想要更高级的赋值就看后面的了。
2.使用字典进行多列按index赋值:
aa=33:[234,44,55],44:[657,77,77],22:[33,55,457]
In [58]: bb=bb.join(pd.DataFrame(aa.values(),columns=['hi','hello','ok'],index=aa.keys()))
In [59]: bb
Out[59]:
one two three new hi hello ok
22 9 9 3 2 33 55 457
33 9 9 6 3 234 44 55
44 9 9 9 4 657 77 771234567812345678
这里aa是一个字典和列表的嵌套,相当于一条记录,使用keys当做index名而不是一般默认的columns名。达到了按index多列匹配的目的。由于dict()储存是混乱的,之间用dict()而不给他的index赋值会记录错乱,这一点注意值得注意。
四、删除多列或多记录:
删除列
bb.drop(['new','hi'],axis=1)
Out[60]:
one two three hello ok
22 9 9 3 55 457
33 9 9 6 44 55
44 9 9 9 77 77123456123456
删除记录
bb.drop([22,33],axis=0)
Out[61]:
one two three new hi hello ok
44 9 9 9 4 657 77 7712341234
DataFrame还有很多功能还没有涉及,等以后有涉及到,看完官网的API之后,还会继续分享,everything is ok。本回答被提问者和网友采纳
以上是关于pandas.dataframe怎么把列变成索引的主要内容,如果未能解决你的问题,请参考以下文章