Hadoop生态圈(二十一)- MapReduce编程基础
Posted 一位木带感情的码农
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop生态圈(二十一)- MapReduce编程基础相关的知识,希望对你有一定的参考价值。
目录
- 1. MapReduce Partition、Combiner
- 2. MapReduce编程指南
- 3. 案例:美国新冠疫情COVID-19统计
1. MapReduce Partition、Combiner
1.1 MapReduce Partition分区
1.1.1 默认情况下MR输出文件个数
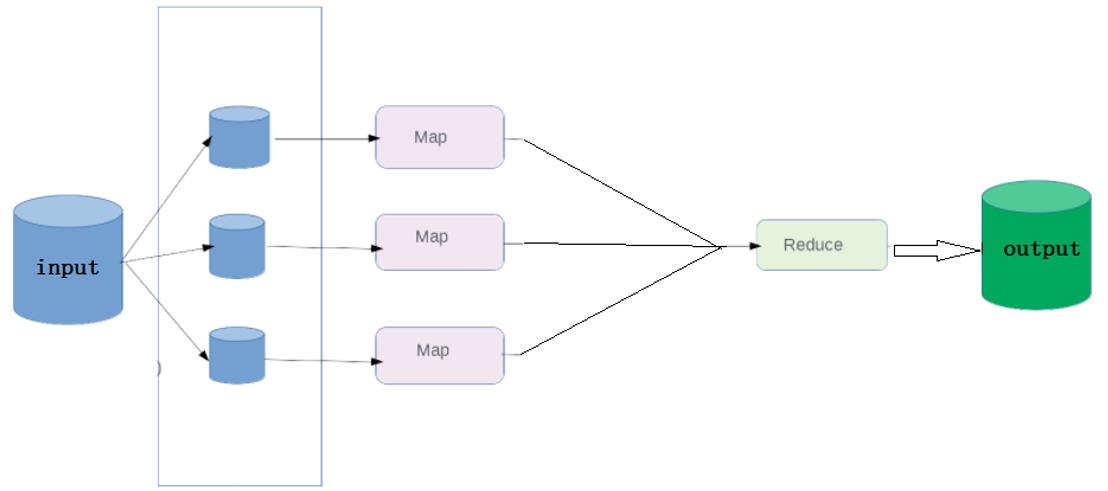
在默认情况下,不管 map 阶段有多少个并发执行 task,到 reduce 阶段,所有的结果都将有一个 reduce 来处理,并且最终结果输出到一个文件中。
此时,MapReduce 的执行流程如下所示:
1.1.2 修改reducetask个数
在 MapReduce 程序的驱动类中,通过 job 提供的方法,可以修改 reducetask 的个数。
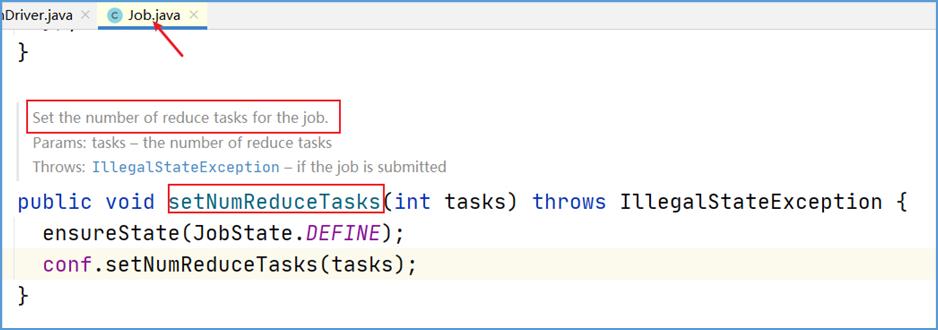
默认情况下不设置,reducetask 个数为 1,结果输出到一个文件中。
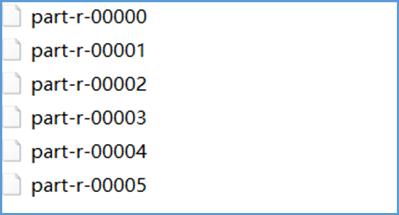
使用 api 修改 reducetask 个数之后,输出结果文件的个数和reducetask个数对应。比如设置为 6 个,此时的输出结果如下所示:
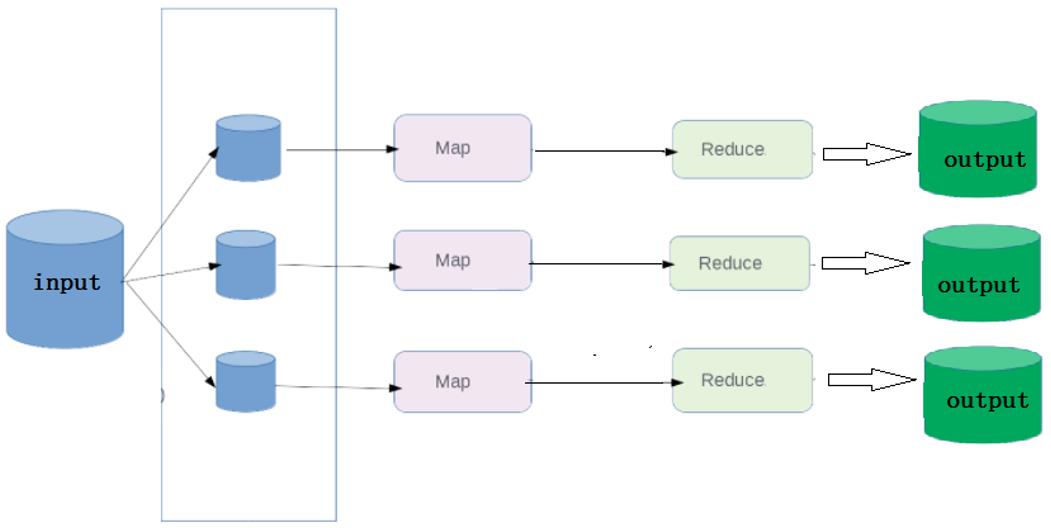
此时,MapReduce 的执行流程如下所示:
1.1.3 数据分区概念
当 MapReduce 中有多个reducetask执行的时候,此时maptask的输出就会面临一个问题:究竟将自己的输出数据交给哪一个reducetask来处理,这就是所谓的数据分区(partition)问题。
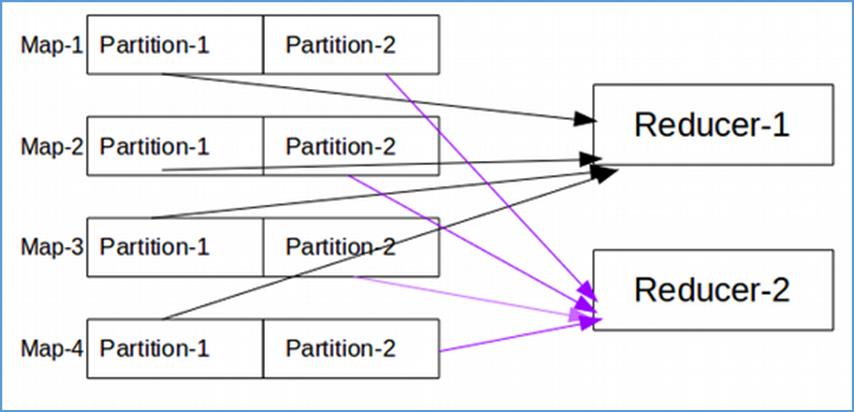
1.1.4 默认分区规则
MapReduce 默认分区规则是HashPartitioner。跟 map 输出的数据 key 有关。
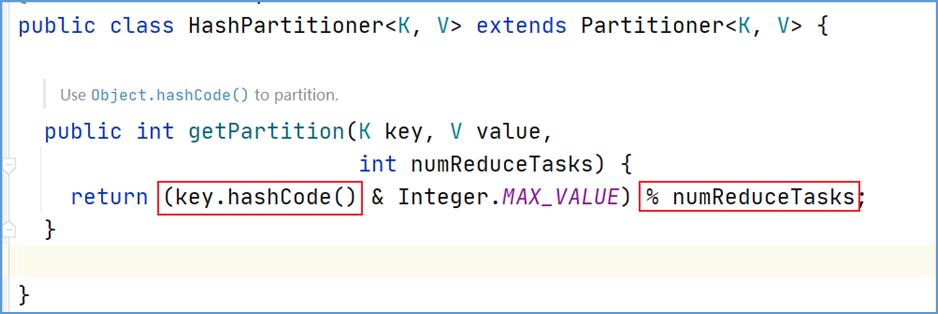
当然用户也可以自己自定义分区规则。
1.1.5 Partition注意事项
reducetask个数的改变导致了数据分区的产生,而不是有数据分区导致了 reducetask 个数改变。- 数据分区的核心是分区规则。即如何分配数据给各个 reducetask。
- 默认的规则可以保证只要
map阶段输出的key一样,数据就一定可以分区到同一个reducetask,但是不能保证数据平均分区。 - reducetask 个数的改变还会导致输出结果文件不再是一个整体,而是输出到多个文件中。
1.2 MapReduce Combiner规约
1.2.1 数据规约的含义
数据规约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量。
1.2.2 MapReduce弊端
- MapReduce 是一种具有两个执行阶段的分布式计算程序,Map 阶段和 Reduce 阶段之间会涉及到
跨网络数据传递。 - 每一个 MapTask 都可能会产生大量的本地输出,这就导致跨网络传输数据量变大,网络 IO 性能低。
比如 WordCount 单词统计案例,假如文件中有 1000 个单词,其中 999 个为 hello,这将产生 999 个 <hello,1>的键值对在网络中传递,性能及其低下。
1.2.3 Combiner组件概念
Combiner中文叫做数据规约,是 MapReduce 的一种优化手段。- Combiner 的作用就是
对map端的输出先做一次合并,以减少在map和reduce节点之间的数据传输量。
1.2.4 Combiner组件使用
- combiner 是 MapReduce 程序中 Mapper 和 Reducer 之外的一种组件,
默认情况下不启用。 combiner本质就是Reducer,combiner 和 reducer的区别在于运行的位置:- combiner 是在每一个 maptask 所在的节点运行,是局部聚合;
- Reducer是对所有 maptask 的输出结果计算,是全局聚合;
- 具体实现步骤:
- 自定义一个 CustomCombiner 继承 Reducer,重写 reduce 方法;
- 在 job 中设置:
job.setCombinerClass(CustomCombiner.class);
1.2.5 Combiner使用注意事项
- Combiner 能够应用的前提是不能影响最终的业务逻辑,而且,Combiner 的输出 kv 应该跟 reducer 的输入 kv 类型要对应起来。
- 下述场景禁止使用Combiner,不仅优化了数据量,还改变了最终的结果:
- 业务和数据个数相关的;
- 业务和整体排序相关的;
- Combiner 组件不是禁用,而是慎用。
用的好提升程序性能,用不好,改变程序结果且不易发现。
2. MapReduce编程指南
2.1 编程技巧
MapReduce执行流程了然于心,能够知道数据在 MapReduce 中的流转过程。业务需求解读准确,即需要明白做什么。牢牢把握住key的选择,因为 MapReduce 很多行为跟key相关, 比如:排序、分区、分组。- 学会
自定义组件修改默认行为,当默认的行为不满足业务需求,可以尝试自定义规则。 - 通过
画图梳理业务执行流程,确定每个阶段的数据类型。
2.2 MapReduce执行流程图
2.2.1 执行流程图
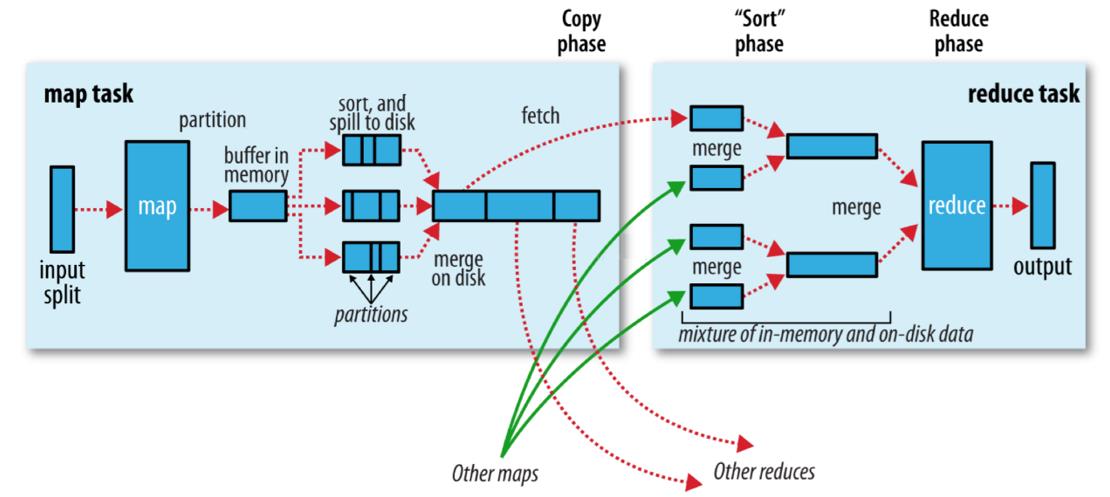
2.2.2 Map阶段执行过程
- 第一阶段是把输入目录下文件按照一定的标准逐个进行
逻辑切片,形成切片规划。默认情况下,Split size=Block size。每一个切片由一个 MapTask 处理(getSplits)。 - 第二阶段是对切片中的数据按照一定的规则
解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key 是每一行的起始位置(单位是字节),value 是本行的文本内容(TextInputFormat)。 - 第三阶段是调用 Mapper 类中的 map 方法。上阶段中
每解析出来的一个<k,v>,调用一次map方法。每次调用 map 方法会输出零个或多个键值对。 - 第四阶段是按照一定的规则对第三阶段输出的
键值对进行分区。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个 Reducer 任务。 - 第五阶段是对每个
分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对 <2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是 <1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。 - 第六阶段是对数据进行
局部聚合处理,也就是 combiner 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
2.2.3 Redue阶段执行过程
- 第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
- 第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次 reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中。
2.3 key的重要性体现
- 在 MapReduce 编程中,核心是
牢牢把握住每个阶段的输入输出key是什么。 - 因为 MapReduce 中很多默认行为都跟 key 相关。
排序:key 的字典序a-z 正序分区:key.hashcode % reducetask 个数分组:key 相同的分为一组
- 最重要的是,如果觉得默认的行为不满足业务需求,MapReduce 还支持自定义排序、分区、分组的规则,这将使得编程更加灵活和方便。
3. 案例:美国新冠疫情COVID-19统计
现有美国 2021-1-28 号,各个县 county 的新冠疫情累计案例信息,包括确诊病例和死亡病例,数据格式如下所示:
2021-01-28,Juneau City and Borough,Alaska,02110,1108,3
2021-01-28,Kenai Peninsula Borough,Alaska,02122,3866,18
2021-01-28,Ketchikan Gateway Borough,Alaska,02130,272,1
2021-01-28,Kodiak Island Borough,Alaska,02150,1021,5
2021-01-28,Kusilvak Census Area,Alaska,02158,1099,3
2021-01-28,Lake and Peninsula Borough,Alaska,02164,5,0
2021-01-28,Matanuska-Susitna Borough,Alaska,02170,7406,27
2021-01-28,Nome Census Area,Alaska,02180,307,0
2021-01-28,North Slope Borough,Alaska,02185,973,3
2021-01-28,Northwest Arctic Borough,Alaska,02188,567,1
2021-01-28,Petersburg Borough,Alaska,02195,43,0
字段含义如下:date(日期),county(县),state(州),fips(县编码code),cases(累计确诊病例),deaths(累计死亡病例)。
完整数据集链接:https://pan.baidu.com/s/1AdWWprwEdeyfELOY7YP6ug,提取码:6666
3.1 MapReduce自定义对象序列化
3.1.1 需求
统计美国 2021-1-28,每个州 state 累积确诊案例数、累计死亡案例数。
3.1.2 分析
自定义对象CovidCountBean,用于封装每个县的确诊病例数和死亡病例数。- 注意需要
实现Hadoop的序列化机制。 以州state作为map阶段输出的key,以 CovidCountBean 作为 value,这样经过 MapReduce 的默认排序分组规则,属于同一个州的数据就会变成一组进行 reduce 处理,进行累加即可得出每个州累计确诊病例。
3.1.3 代码实现
3.1.3.1 自定义JavaBean
public class CovidCountBean implements Writable
private long cases;//确诊病例数
private long deaths;//死亡病例数
public CovidCountBean()
public CovidCountBean(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
public void set(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
public long getCases()
return cases;
public void setCases(long cases)
this.cases = cases;
public long getDeaths()
return deaths;
public void setDeaths(long deaths)
this.deaths = deaths;
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException
out.writeLong(cases);
out.writeLong(deaths);
/**
* 反序列化方法 注意顺序
*/
@Override
public void readFields(DataInput in) throws IOException
this.cases = in.readLong();
this.deaths =in.readLong();
@Override
public String toString()
return cases +"\\t"+ deaths;
3.1.3.2 Mapper类
public class CovidSumMapper extends Mapper<LongWritable, Text, Text, CovidCountBean>
Text outKey = new Text();
CovidCountBean outValue = new CovidCountBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
String[] fields = value.toString().split(",");
//州
outKey.set(fields[2]);
//Covid数据 确诊病例 死亡病例
outValue.set(Long.parseLong(fields[fields.length-2]),Long.parseLong(fields[fields.length-1]));
//map输出结果
context.write(outKey,outValue);
3.1.3.3 Reducer类
public class CovidSumReducer extends Reducer<Text, CovidCountBean,Text,CovidCountBean>
CovidCountBean outValue = new CovidCountBean();
@Override
protected void reduce(Text key, Iterable<CovidCountBean> values, Context context) throws IOException, InterruptedException
long totalCases = 0;
long totalDeaths =0;
//累加统计
for (CovidCountBean value : values)
totalCases += value.getCases();
totalDeaths +=value.getDeaths();
outValue.set(totalCases,totalDeaths);
context.write(key,outValue);
3.1.3.4 程序驱动类
public class CovidSumDriver
public static void main(String[] args) throws Exception
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidSumDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidSumDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidSumMapper.class);
job.setReducerClass(CovidSumReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CovidCountBean.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CovidCountBean.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1])))
fs.delete(new Path(args[1]),true);
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
3.1.4 代码执行结果
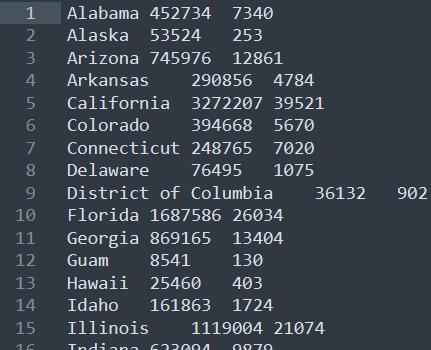
3.2 MapReduce自定义排序
3.2.1 需求
统计美国 2021-01-28,每个州state的累积确证案例数、累积死亡案例数。
将美国 2021-01-28,每个州state的确证案例数进行倒序排序。
3.2.2 分析
如果你的需求中需要根据某个属性进行排序 ,不妨把这个属性作为 key。因为 MapReduce 中key有默认排序行为的。但是需要进行如下考虑:
- 如果你的需求是正序,并且数据类型是 Hadoop 封装好的基本类型。这种情况下不需要任何修改,直接使用基本类型作为 key 即可。因为 Hadoop 封装好的类型已经实现了排序规则。
- 比如,LongWritable 类型:

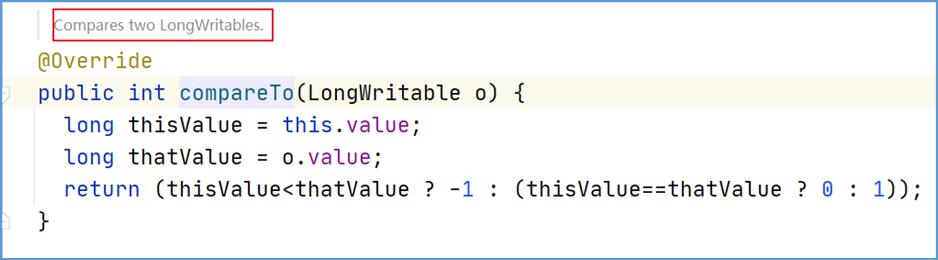
- 比如,LongWritable 类型:
- 如果你的需求是倒序,或者数据类型是自定义对象。需要重写排序规则。需要对象
实现Comparable接口,重写ComparTo方法。

3.2.3 代码实现
3.2.3.1 自定义JavaBean
public class CovidCountBean implements WritableComparable<CovidCountBean>
private long cases;//确诊病例数
private long deaths;//死亡病例数
public CovidCountBean()
public CovidCountBean(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
public void set(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
public long getCases()
return cases;
public void setCases(long cases)
this.cases = cases;
public long getDeaths()
return deaths;
public void setDeaths(long deaths)
this.deaths = deaths;
/**
* 序列化方法
*/
@Override
public void write(DataOutput out) throws IOException
out.writeLong(cases);
out.writeLong(deaths);
/**
* 反序列化方法 注意顺序
*/
@Override
public void readFields(DataInput in) throws IOException
this.cases = in.readLong();
this.deaths =in.readLong();
@Override
public String toString()
return cases +"\\t"+ deaths;
/**
* 排序比较器 本业务中根据确诊案例数倒序排序
*/
@Override
public int compareTo(CovidCountBean o)
return this.cases - o.getCases()> 0 ? -1:(this.cases - o.getCases() < 0 ? 1 : 0);
3.2.3.2 Mapper类
public class CovidSortSumMapper extends Mapper<LongWritable, Text, CovidCountBean,Text>
CovidCountBean outKey = new CovidCountBean();
Text outValue = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
String[] fields = value.toString().split("\\t");
outKey.set(Long.parseLong(fields[1]),Long.parseLong(fields[2]));
outValue.set(fields[0]);
context.write(outKey,outValue);
3.2.3.3 Reducer类
public class CovidSortSumReducer extends Reducer<CovidCountBean, Text,Text,CovidCountBean>
@Override
protected void reduce(CovidCountBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException
Text outKey = values.iterator().next();
context.write(outKey,key);
3.2.3.4 驱动程序类
public class CovidSortSumDriver
public static void main(String[] args) throws Exception
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidSortSumDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidSortSumDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidSortSumMapper.class);
job.setReducerClass(CovidSortSumReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(CovidCountBean.class);
job.setMapOutputValueClass(Text.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text<以上是关于Hadoop生态圈(二十一)- MapReduce编程基础的主要内容,如果未能解决你的问题,请参考以下文章