)
Posted wyy_persist
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了)相关的知识,希望对你有一定的参考价值。
从本章开始将仅记录书中的重点内容翻译并记录,供日后复习使用
8. 参数化学习
本章的大部分灵感来自Andrej Karpathy在斯坦福cs231n课堂中出色的线性分类注释[74]。非常感谢卡帕西和其他的cs231n助教把这些可访问的笔记放在一起。
8.1线性分类简介
8.1.1参数化学习的四个组成部分
简单地说:参数化是定义给定模型的必要参数的过程。在机器学习的任务中,参数化涉及到根据四个关键组件定义问题:数据、评分函数、损失函数、权重和偏差。我们将在下面逐一回顾。
数据
这个组件是我们将要学习的输入数据。这些数据包括数据点(例如,来自图像的原始像素强度,提取的特征等)和它们相关的类标签。通常我们用多维设计矩阵[10]表示我们的数据。
设计矩阵中的每一行代表一个数据点,而矩阵的每一列(它本身可以是一个多维数组)对应一个不同的特征。例如,考虑一个RGB颜色空间中100张图像的数据集,每张图像的大小为32 × 32像素。该数据集的设计矩阵为X三角形数据集R100×(32×32×3),其中Xi定义了r中的第i张图像。使用这种表示法,X1是第一张图像,X2是第二张图像,以此类推。
除了设计矩阵,我们还定义了一个向量y,其中yi为数据集中的第i个示例提供了类标签。
得分函数
计分函数接受我们的数据作为输入,并将数据映射到类标签。例如,给定我们的一组输入图像,评分函数获取这些数据点,应用某个函数f(我们的评分函数),然后返回预测的类标签,类似于下面的伪代码:
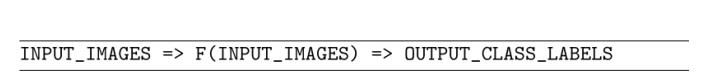
损失函数
损失函数量化了我们预测的类别标签与基本事实标签的吻合程度。这两组标签之间的一致性水平越高,我们的损失就越低(并且我们的分类准确性就越高,至少在训练集上是这样)。
我们在训练机器学习模型时的目标是最小化损失函数,从而提高分类精度。
权重和偏差
权重矩阵,通常记作W和偏差向量b被称为我们要优化的分类器的权重或参数。根据我们的评分函数和损失函数的输出,我们将调整和摆弄权重和偏差的值,以提高分类准确性。
8.1.2线性分类:从图像到标签
首先,我们需要我们的数据。让我们假设我们的训练数据集表示为xi,其中每个图像都有一个相关的类标签yi。我们假设i = 1,…,N和yi = 1,…,K,这意味着我们有N个维数为D的数据点,分为K个独特的类别。
为了使这个想法更具体,考虑我们第7章中的“动物”数据集。在这个数据集中,我们总共有N = 3000幅图像。每幅图像为32 × 32像素,以RGB颜色空间表示。每张图像三个通道)。我们可以将每个图像表示为D = 32 × 32 × 3 = 3072个不同的值。最后,我们知道总共有K = 3个类标签:一个分别用于狗、猫和熊猫类。
给定这些变量,我们现在必须定义一个评分函数f,它将图像映射到类标签scores。一种实现这种得分的方法是通过一个简单的线性映射:
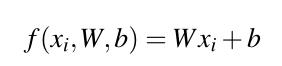
让我们假设每个xi被表示为一个形状为[D × 1]的列向量(在这个例子中,我们将把32 × 32 × 3的图像平展成一个包含3,072个整数的列表)。权重矩阵W的形状为[K × D](按输入图像的维数计算的类别标签的数量)。最后b,偏差向量的大小为[K × 1]。偏差向量允许我们在不影响权重矩阵W的情况下,向一个或另一个方向移动和转换我们的评分函数。偏差参数对于成功的学习通常是至关重要的。
回到Animals数据集示例,每个xi由一个包含3072个像素值的列表表示,因此xi的形状为[3072 × 1]。权矩阵W的形状为[3 × 3072],最后偏差向量b的大小为[3 × 1]。
图8.1为线性分类评分函数f。在左边,我们有我们的原始输入图像,表示为32 × 32 × 3图像。然后,我们通过获取3D数组并将其重塑为1D列表,将该图像平展成3072像素强度的列表。
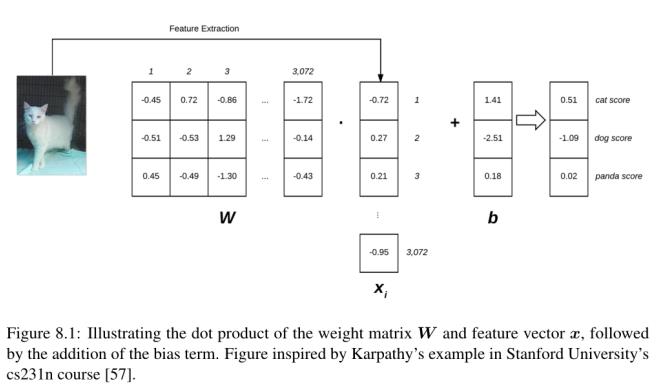
我们的权重矩阵W包含三行(每个类标签对应一行)和3072列(图像中的每个像素对应一行)。在计算W和的点积之后,我们加上偏置向量b -结果就是我们实际的得分函数。我们的评分函数在右边产生三个值:分别与狗、猫和熊猫标签相关的分数。
不熟悉点乘的读者应该阅读这个快速简明的教程:http://pyimg.co/fgcvp。对于有兴趣深入学习线性代数的读者,我强烈推荐阅读Philip N. Klein的《通过应用于计算机科学来编码矩阵线性代数》[75]。
看看上面的图和方程,你可以确信输入xi和yi是固定的,不是我们可以修改的。当然,我们可以通过对输入图像应用不同的转换来获得不同的轴向坐标——但是一旦我们将图像传递给评分函数,这些值就不会改变。事实上,我们有控制的唯一参数(参数化的学习)是我们的权重矩阵W和偏差向量b。因此,我们的目标是利用我们的得分函数和损失函数优化(例如,以系统的方式修改)重量和偏见向量,这样我们的分类精度提高。
8.1.3参数化学习和线性分类的优点
参数学习的优势:
- 一旦我们完成了对模型的训练,我们就可以丢弃输入数据,只保留权重矩阵W和偏差向量b。这大大减少了模型的大小,因为我们需要存储两组向量(而不是整个训练集)。
- 分类新的测试数据是快速的。为了进行分类,我们所需要做的就是取W和xi的点积,然后加上偏差b(即应用我们的评分函数)。这样做比需要比较每个测试点和每个训练示例的k-NN算法要快得多。
8.1.4 Python中的简单线性分类器
python代码实现:
import numpy as np
import cv2
# 初始化类标签并设置伪随机的种子数字生成器,这样我们就可以重现我们的结果
labels = ["dog", "cat", "panda"]
np.random.seed(1)
# 初始化权重矩阵和偏差向量
# 第14行初始化权矩阵W,其值来自均匀分布的随机值,采样范围为[0,1]。这个权重矩阵有3行(每个类标签对应一行)和3072列(32 × 32 × 3图像中的每个像素对应一行)。
# 然后我们在第15行初始化偏置向量——这个向量也被随机填充为分布[0,1]上均匀采样的值。偏差向量有3行(对应于类标签的数量)和1列。
W = np.random.randn(3, 3072)
b = np.random.randn(3)
# 加载图像
# 第19行通过cv2.imread从磁盘加载图像。然后我们在第20行将图像的大小调整为32×32像素(忽略长宽比)——我们的图像现在被表示为(32,32,3)NumPy数组,我们将其平化为3072 -dim向量。
#
orig = cv2.imread("beagle.png")
image = cv2.resize(orig, (32, 32)).flatten()
# 计算分类标签的分数
scores = W.dot(image) + b
# 将每一个评分值写入终端
for (label, score) in zip(labels, scores):
print("[INFO] : :.2f".format(label, score))
cv2.putText(orig, "Label : ".format(labels[np.argmax(scores)]), (10, 30),cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,0.9,(0, 255, 0), 2)
cv2.imshow("Image",orig)
cv2.waitKey(0)
import numpy as np
import cv2
# 初始化类标签并设置伪随机的种子数字生成器,这样我们就可以重现我们的结果
labels = ["dog", "cat", "panda"]
np.random.seed(1)
# 初始化权重矩阵和偏差向量
# 第14行初始化权矩阵W,其值来自均匀分布的随机值,采样范围为[0,1]。这个权重矩阵有3行(每个类标签对应一行)和3072列(32 × 32 × 3图像中的每个像素对应一行)。
# 然后我们在第15行初始化偏置向量——这个向量也被随机填充为分布[0,1]上均匀采样的值。偏差向量有3行(对应于类标签的数量)和1列。
W = np.random.randn(3, 3072)
b = np.random.randn(3)
# 加载图像
# 第19行通过cv2.imread从磁盘加载图像。然后我们在第20行将图像的大小调整为32×32像素(忽略长宽比)——我们的图像现在被表示为(32,32,3)NumPy数组,我们将其平化为3072 -dim向量。
#
orig = cv2.imread("beagle.png")
image = cv2.resize(orig, (32, 32)).flatten()
# 计算分类标签的分数
scores = W.dot(image) + b
# 将每一个评分值写入终端
for (label, score) in zip(labels, scores):
print("[INFO] : :.2f".format(label, score))
cv2.putText(orig, "Label : ".format(labels[np.argmax(scores)]), (10, 30),cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,0.9,(0, 255, 0), 2)
cv2.imshow("Image",orig)
cv2.waitKey(0)
同样,请记住,这是一个有效的例子。我故意设置了Python脚本的随机状态,以生成W和b值,这些值将导致正确的分类(您可以在第8行更改伪随机种子值,亲自看看不同的随机初始化将如何产生不同的输出预测)。
在实践中,您永远不会初始化W和b值,并假定它们在没有某种学习过程的情况下会给您正确的分类。相反,当我们从头开始训练我们自己的机器学习模型时,我们需要通过一个优化算法来优化和学习W和b,比如梯度下降。
我们将讨论优化和梯度下降在接下来的一章,但与此同时,只是花时间,以确保你理解第24行以及一个线性分类器进行分类的点积权重矩阵和一个输入数据点,然后通过添加的偏见。因此,我们的整个模型可以通过两个值来定义:权重矩阵和偏差向量。当我们从零开始训练机器学习模型时,这种表示不仅紧凑,而且相当强大。
8.2 损失函数的作用
在上一节中,我们讨论了参数化学习的概念。这种类型的学习允许我们获取一组输入数据和类标签,并通过定义一组参数并对它们进行优化,实际学习一个将输入映射到输出预测的函数。
但为了通过评分函数真正“学习”从输入数据到类标签的映射,我们需要讨论两个重要的概念:
- 损失函数;
- 参数优化方法
8.2.1什么是损失函数
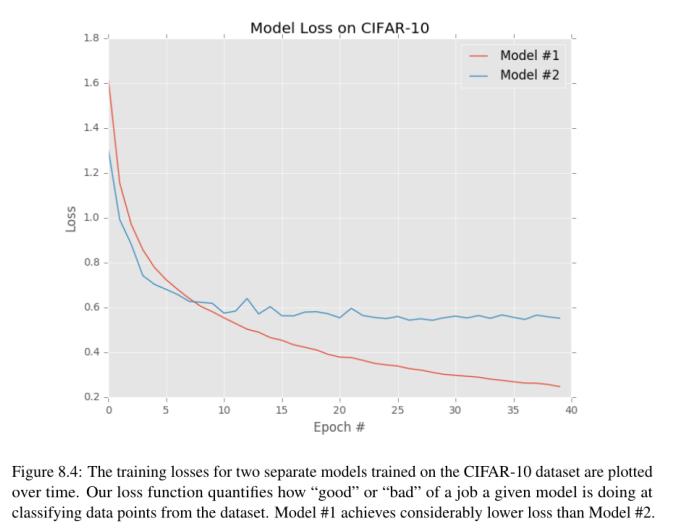
就目前而言,简单地理解损失函数可以用来量化我们的评分函数在分类输入数据点方面的表现。
理想情况下,当我们调整模型参数时,我们的损失应该随着时间的推移而减少。如图8.4所示,模型1的损失开始时略高于模型2,但随后迅速减少,并在CIFAR-10数据集上继续保持较低的水平。相反,模型2的损失最初有所减少,但很快就停滞了。在这个特定的示例中,模型#1实现了更低的总体损失,可能是用于从CIFAR-10数据集对其他图像进行分类的更理想的模型。我说“可能”是因为模型1有可能对训练数据过度拟合。我们将在第17章中介绍过拟合的概念以及如何发现它。
8.2.2多类SVM损失
多类SVM Loss(顾名名状)的灵感来自于(Linear) Support V ector Machines (SVM)[43],它使用一个评分函数f将我们的数据点映射到每个类别标签的数字分数。函数f是一个简单的学习映射:

现在我们有了评分函数,我们需要确定这个函数(给定权重矩阵W和偏差向量b)在进行预测时是“好”还是“坏”。为了做出这个决定,我们需要一个损失函数。
回想一下,在创建机器学习模型时,我们有一个设计矩阵X,其中X中的每一行都包含一个我们希望分类的数据点。在图像分类的背景下,X中的每一行都是一个图像,我们寻求正确的标签这个图像。我们可以通过语法xi访问X中的第i个图像。
类似地,我们还有一个向量y,它包含每个x的类标签。这些y值是我们的基本事实标签,以及我们希望评分函数能够正确预测的值。就像我们可以访问一个给定的图像xi一样,我们可以通过yi访问相关的类标签。
为了简单起见,我们将我们的评分函数缩写为s:

这意味着我们可以通过第i个数据点得到第j类的预测分数:

使用这个语法,我们可以把它们放在一起,得到铰链损失函数:

几乎所有的损失函数都包含一个正则化项。我现在跳过这个想法,因为我们将在第九章中回顾正则化,一旦我们更好地理解损失函数。
看看上面的铰链损耗方程,你可能会对它的实际作用感到困惑。实际上,hinge loss函数是对所有不正确的类(i6 = j)求和,并比较评分函数s为第j个类标签(不正确的类)和第i个类(正确的类)返回的输出。我们对零处的值应用最大值操作,这对于确保不对负值求和很重要。
当损失Li = 0时,给定的xi被正确分类(在下一节中我将提供一个数值示例)。为了得出整个训练集的损失,我们只需取每个个体的平均值。

你可能遇到的另一个相关的损失函数是铰链损失的平方:

平方项通过对输出的平方来惩罚我们的损失,这导致了错误预测中损失的二次增长(相对于线性增长)。
至于应该使用哪个丢失函数,这完全取决于您的数据集。标准铰链损失函数的使用较多,但在一些数据集上,平方变异可以获得较好的精度。总之,这是一个您应该考虑调优的超参数。
一个多类SVM损失实例

注意我们这里的方程是如何包含两个术语的——预测的狗的分数与猫和熊猫的分数之间的差异。同时观察一下“狗”的损失是如何为零的——这意味着狗的预测是正确的。对图8.5中的图像1的快速调查证明了这个结果是正确的:“狗”的得分大于“猫”和“熊猫”的得分。
类似地,我们可以计算图片#2的铰链损失,这张图片包含一只猫:

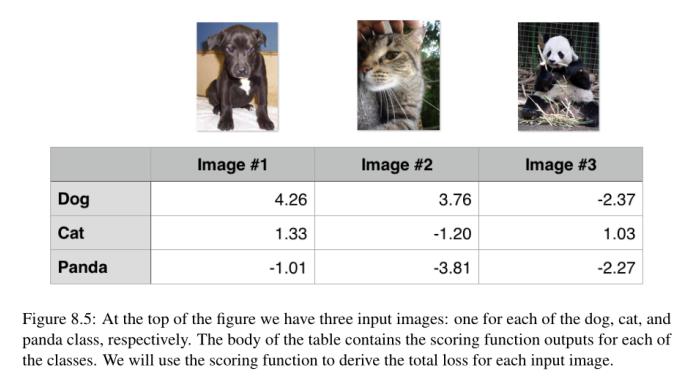
在这种情况下,我们的损失函数大于零,表明我们的预测是不正确的。看看我们的评分函数,我们看到我们的模型预测dog是得分为3.76的提议标签(因为这是得分最高的标签)。我们知道这个标签是不正确的——在第9章中,我们将学习如何自动调整权重来纠正这些预测。

同样,我们的损失是非零的,所以我们知道我们的预测是错误的。看看我们的评分函数,我们的模型错误地将这个图像标记为“猫”,而它应该是“熊猫”。
然后我们可以通过取平均值来得到这三个例子的总损失:
因此,给定我们的三个训练示例,对于参数W和b,总的铰链损耗为3.72。
还请注意,我们的损失为零,只有一个输入图像,这意味着我们的两个预测是不正确的。在下一章中,我们将学习如何优化W和b,通过使用损失函数来帮助引导我们走向正确的方向,从而做出更好的预测。
8.2.3交叉熵损失和Softmax分类器
重点:
虽然铰链丢失非常流行,但在深度学习和卷积神经网络的环境中,你更有可能遇到交叉熵丢失和Softmax分类器。
Softmax分类器给你每个类别标签的概率,而铰链损失给你的边际。
作为人类,我们更容易解释概率而不是边际得分。此外,对于像ImageNet这样的数据集,我们经常查看卷积神经网络的5级精度(我们检查ground-truth标签是否在给定输入图像的网络返回的前5个预测标签中)。看看(1)真实的类标签是否存在于前5个预测中,(2)与每个标签相关的概率是一个很好的属性。
理解熵损失
Softmax分类器是Logistic回归的二元形式的推广。就像在铰链损失或平方铰链损失中,我们的映射函数f的定义是,它取一个数据xi的输入集,并通过数据xi与权重矩阵W(为简洁起见省略了偏差项)的点积将它们映射到输出类标签:

然而,与铰链损失不同的是,我们可以将这些分数解释为每个类别标签的未归一化对数概率,这相当于用交叉熵损失交换铰链损失函数:

那么,我是如何来到这里的呢?让我们把函数拆开来看一下。首先,我们的loss函数应该最小化正确类的负对数可能性:

概率语句可以解释为:

我们使用标准的得分函数形式:

总的来说,这将生成单个数据点的最终损失函数,如上所示:

注意这里的对数实际上是以e为底(自然对数)因为我们之前求的是e的幂的逆。通过指数和进行的实际指数化和归一化是Softmax函数。负对数产生了实际的交叉熵损失。
就像铰链损失和平方铰链损失一样,计算整个数据集的交叉熵损失是通过取平均值:

我故意省略了损失函数中的正则化项。我们将回到正则化,解释它是什么,如何使用它,以及为什么它对神经网络和深度学习至关重要。如果上面的等式看起来很可怕,不要担心——我们将在下一节通过数值示例来确保您理解交叉熵损失是如何工作的。
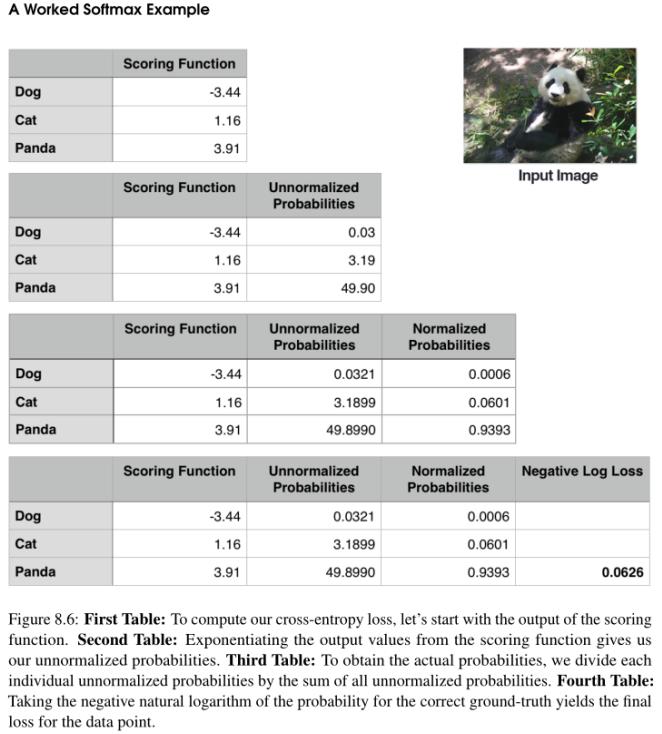
解释:
第一个表分别包含三个类中每个类的得分函数f的输出。这些值是三个类的非标准化对数概率。让我们对得分函数(es,其中s是我们的得分函数值)的输出取幂,得到我们的非标准化概率(第二个表)。
下一步是取分母,对指数求和,然后除以总和,从而得到与每个类标签相关联的实际概率(第三张表)。注意概率总和是1。最后,我们可以取负自然对数- ln(p),其中p是归一化概率,产生最终的损失(第4张表,也是最后一张表)。
在这种情况下,我们的Softmax分类器能够以93.93%的信誉度正确地报告图像为熊猫。然后,我们可以对训练集中的所有图像重复这个过程,取平均值,得到训练集中的总体交叉熵损失。这个过程允许我们量化一组参数在训练集中表现的好坏。
我使用一个随机数生成器来获取这个特定示例的得分函数值。这些值只是用来演示Softmax分类器/交叉熵损失函数的计算是如何执行的。在现实中,这些值不会随机生成,取而代之的应该是你的得分函数f的输出基于参数W和b。我们将看到如何参数化学习的所有组件组合在一起在我们的下一章,但就目前而言,我们正在与示例数据来演示损失函数是如何工作的。
8.3 总结
在本章中,我们回顾了参数化学习的四个组成部分:
- 数据
- 评分函数
- 损失函数
- 权重和偏差
在图像分类的上下文中,我们的输入数据是我们的图像数据集。评分函数生成对给定输入图像的预测。然后损失函数量化一组预测对数据集的好坏程度。最后,权重矩阵和偏差向量使我们能够真正地从输入数据中“学习”——这些参数将通过优化方法进行调整和调整,以获得更高的分类精度。
然后我们回顾了两个流行的损失函数:铰链损失和交叉熵损失。虽然铰链损失在许多机器学习应用程序中使用(如svm),但我几乎可以绝对肯定地保证,您将看到更多的交叉熵损失,主要是因为Softmax分类器输出的是概率而不是边际。概率对于我们人类来说更容易解释,所以这个事实是交叉熵损失和Softmax分类器的一个特别好的特性。关于损失铰链损失和交叉熵损失的更多信息,请参考斯坦福大学的cs231n课程[57,74]。
在下一章中,我们将回顾用于调整权重矩阵和偏置向量的优化方法。优化方法允许我们的算法通过更新基于得分和损失函数输出的权重矩阵和偏差向量,从我们的输入数据中实际学习。使用这些技术,我们可以逐步获得更低的损耗和更高的精度的参数值。优化方法是现代神经网络和深度学习的基石,没有它们,我们将无法从输入数据中学习模式,所以请务必关注下一章。
重点:
9. 优化方法和正则化
“几乎所有的深度学习都是由一个非常重要的算法驱动的:随机梯度下降(SGD)”- Goodfellow等人[10]
有了这些构建模块,我们现在可以转移到机器学习、神经网络和深度学习最重要的方面——优化。优化算法是驱动神经网络的引擎,使它们能够从数据中学习模式。在整个讨论中,我们已经了解到,获得一个高精度的分类器依赖于找到一组权重W和b,以便我们的数据点被正确分类。
与其依赖于纯粹的随机性,我们需要定义一种优化算法,允许我们从字面上改进W和b。在本章中,我们将看看最常用的用于训练神经网络和深度学习模型的算法——梯度下降。梯度下降有许多变体(我们也会提到),但在每种情况下,其理念都是相同的:迭代评估你的参数,计算你的损失,然后朝着最小化损失的方向迈出一小步。
9.1梯度下降
两种形式:
- 标准的“香草”实现。
- 更常用的优化“随机”版本。
在本节中,我们将回顾基本的基本实现,为我们的理解形成一个基线。在我们理解了梯度下降的基本原理之后,我们将继续学习随机版本。然后,我们将回顾一些我们可以添加到梯度下降的“bells and whistles”,包括动量和Nesterov加速度。
9.1.1损失景观及优化面
梯度下降法是一种迭代优化算法,可在损失景观(也称为优化表面)上运行。标准梯度下降的例子是将我们的权值沿着x轴可视化,然后将给定的一组权值沿着y轴的损失可视化(图9.1,左):
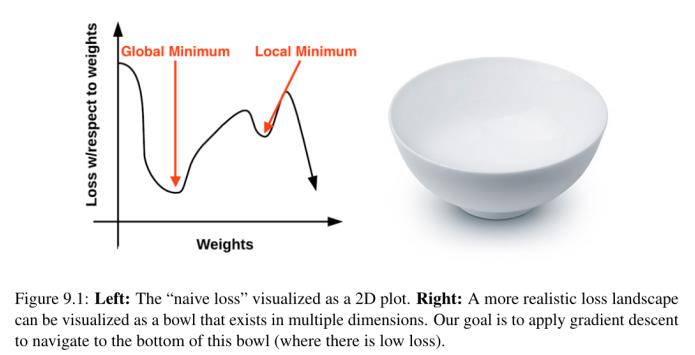
整个损失景观中损失最小的局部最小值就是我们的全局最小值。在理想世界中,我们希望找到这个全局最小值,确保我们的参数具有最优的可能值。
问题就在这里——损失的景象是我们看不见的。我们不知道它长什么样。如果我们是一个优化算法,我们就会被盲目地放置在某个地方,不知道我们面前的风景是什么样子的,我们将不得不导航到损失最小的地方,而不意外地爬到局部最大值的顶部。
沿碗表面的每个位置对应于给定一组参数W(权重矩阵)和b(偏差向量)的特定损失值。我们的目标是尝试不同的W和b值,评估它们的损失,然后向更理想的损失更低的最优值迈进一步。
9.1.2梯度下降中的“梯度”
为了让我们更直观地解释梯度下降,让我们假设我们有一个机器人——让我们把它命名为Chad(图9.2,左)。当我们执行梯度下降时,我们会随机将Chad放置在我们的损失区域的某个地方。
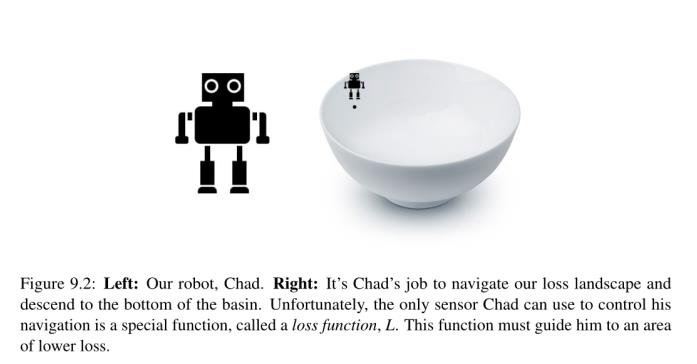
查德该怎么办?答案是运用梯度下降法。查德要做的就是沿着W的斜率走。我们可以使用以下公式计算所有维度的梯度W:

在> 1维中,梯度变成了偏导数的向量。这个方程的问题是:
1. 这是梯度的近似值。2. 它是缓慢。
为了便于讨论,我们只需内化梯度下降是什么:尝试通过迭代过程,在损失最小化的方向上迈出一步,以优化我们的参数,实现低损失和高分类精度。
9.1.3把它当作一个凸问题(即使它不是)
使用图9.1(右)中的碗形图作为损失景观的可视化,也可以让我们在现代神经网络中得出一个重要的结论——我们将损失景观视为一个凸问题,即使它不是。如果某个函数F是凸的,那么所有的局部极小值也是全局极小值。这个想法很好地符合碗的可视化。我们的优化算法只需要在碗的顶部绑上一对滑雪板,然后慢慢地沿着斜坡向下滑行,直到到达底部。
问题是,几乎所有我们应用神经网络和深度学习算法解决的问题都不是简洁的凸函数。相反,在这个碗状区域内,我们会发现尖峰状的山峰,更类似于峡谷的山谷,陡峭的下降,甚至是损失急剧下降又急剧上升的槽。
“优化算法可能不能保证在合理的时间内达到局部最小值,但它通常会在足够快的时间内找到一个非常低的[损失]函数值,从而变得有用。”
在训练深度学习网络时,我们可以设定很高的期望,即找到局部/全局最小值,但这种期望很少与现实相符。相反,我们最终找到了一个低损耗的区域——这个区域甚至可能不是一个局部最小值,但在实践中,这已经足够了。
9.1.4偏差技巧
在我们继续执行梯度下降之前,我想花点时间讨论一种叫做“偏差技巧”的技术,一种将我们的权矩阵W和偏差向量b组合成一个单一参数的方法。回想一下我们之前的决定,我们的评分函数定义为:

在解释和实现方面,跟踪两个独立的变量通常很繁琐——为了完全避免这种情况,我们可以将W和b结合在一起。为了结合偏差和权重矩阵,我们在输入数据X中添加一个额外的维度(即列),它持有一个常量1——这是我们的偏差维度。
通常,我们要么将新维度附加到每个xi上作为第一个维度,要么将其作为最后一个维度。事实上,这并不重要。我们可以选择任意位置插入一列1,到我们设计的矩阵中,只要它存在。这样做可以让我们通过一个矩阵乘法来重写我们的评分函数:

同样,我们可以省略这里的b项因为它被嵌入到我们的权重矩阵中。在前面的“Animals”数据集示例中,我们使用了32 × 32 × 3的图像,总像素为3,072。每个xi都用一个向量[3072 × 1]表示。增加一个常数值为1的维度,现在将向量扩展为[3073 × 1]。同样,将偏差矩阵和权值矩阵结合起来,也将权值矩阵W扩展为[3 × 3073],而不是[3 × 3072]。通过这种方式,我们可以将偏差视为权值矩阵中的一个可学习参数,而不必明确地在一个单独的变量中跟踪它。
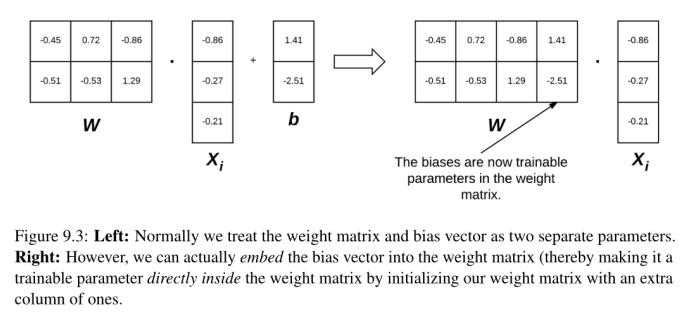
为了将偏差技巧可视化,请考虑图9.3(左),在图9.3中,我们将权重矩阵和偏差分开。到目前为止,这个图描述的是我们如何看待我们的评分函数。但是,我们可以将W和b组合在一起,只要我们在每个xi中插入一个新列,其中每个条目都是1(图9.3,右)。使用偏差技巧可以让我们只学习一个权重矩阵,因此我们倾向于使用这种方法来实现。对于本书以后的所有例子,当我提到W时,假设偏差向量b也隐含在权重矩阵中。
9.1.5 梯度下降的伪代码

This pseudocode is what all variations of gradient descent are built off of. We start off on Line
1 by looping until some condition is met, typically either:
- 已经经过了指定数量的epoch(这意味着我们的学习算法已经“看过”每个训练数据点N次)。
- 我们的损失已经变得足够低或训练精度满足高。
- 在随后的M时代,损失并没有得到改善。
然后,第2行调用一个名为evaluate_gradient的函数。这个函数需要三个参数:
- loss:一个函数,用来计算当前参数W和输入数据的损失。
- data:我们的训练数据,其中每个训练样本由一个图像(或特征向量)表示。
- W:我们正在优化的实际权重矩阵。我们的目标是应用梯度下降来找到一个产生最小损失的W。
evaluate_gradient函数返回一个K维的向量,其中K是图像/特征向量的维数。Wgradient变量是实际的梯度,每个维度都有一个梯度入口。
然后在直线3上应用梯度下降法。我们用Wgradient乘以α,这是我们的学习速率。学习速率控制着我们的步长。
在实践中,您将花费大量的时间来寻找α的最优值——它是您的模型中最重要的参数。如果α太大,你将花费所有的时间在损失的地形周围跳跃,永远不会真正“下降”到盆地的底部(除非你的随机弹跳纯粹是运气)。相反地,如果α太小,那么它将需要很多次迭代(可能非常多)才能到达盆地的底部。寻找α的最优值会让您非常头疼——您将花费大量的时间为您的模型和数据集的这个变量寻找最优值。
9.1.6使用Python实现基本梯度下降
现在我们已经了解了梯度下降的基本知识,让我们用Python实现它,并使用它对一些数据进行分类。打开一个新文件,命名为gradient_descent.py,并插入以下代码:

第2-7行导入所需的Python包。我们以前见过所有这些导入,除了make_blobs,它是一个用于创建正态分布数据点的“blobs”的函数——在从头开始测试或实现我们自己的模型时,这是一个方便的函数。
然后在第9行定义sigmoid_activation函数。当绘制时,这个函数将类似于“S”形曲线(图9.4)。我们称它为激活函数,因为该函数将根据输入x“激活”并触发“ON”(输出值> 0.5)或“OFF”(输出值<= 0.5)。
我们可以通过以下预测方法来定义这种关系:
13 def predict(X, W):
14 # take the dot product between our features and weight matrix
15 preds = sigmoid_activation(X.dot(W))
16
17 # apply a step function to threshold the outputs to binary
18 # class labels
19 preds[preds <= 0.5] = 0
20 preds[preds > 0] = 1
21
22 # return the predictions
23 return preds
给定一组输入数据点X和权重W,我们对它们调用sigmoid_activation函数来获得一组预测(第15行)。然后我们对预测进行阈值设置:任何值<= 0.5的预测被设置为0,而任何值> 0.5的预测被设置为1(第19和20行)。然后将预测返回给第23行上的调用函数。
虽然还有其他(更好的)替代s形激活函数的方法,但它为我们讨论神经网络、深度学习和基于梯度的优化提供了一个很好的起点。我将在Starter Bundle的第10章和实践者Bundle的第7章中讨论其他激活函数,但目前,只需记住,sigmoid是一个非线性激活函数,我们可以使用它来限制我们的预测。
接下来,让我们解析命令行参数:
25 # construct the argument parse and parse the arguments
26 ap = argparse.ArgumentParser()
27 ap.add_argument("-e", "--epochs", type=float, default=100,
28 help="# of epochs")
29 ap.add_argument("-a", "--alpha", type=float, default=0.01,
30 help="learning rate")
31 args = vars(ap.parse_args())
我们可以为脚本提供两个(可选的)命令行参数:
——epoch:我们使用梯度下降训练分类器时将使用的epoch的数量。
——alpha:梯度下降的学习速率。我们通常看到0.1、0.01和0.001作为初始学习率值,但这也是一个超参数,您需要根据自己的分类问题进行调整。
33 # generate a 2-class classification problem with 1,000 data points,
34 # where each data point is a 2D feature vector
35 (X, y) = make_blobs(n_samples=1000, n_features=2, centers=2,
36 cluster_std=1.5, random_state=1)
37 y = y.reshape((y.shape[0], 1))
38
39 # insert a column of 1’s as the last entry in the feature
40 # matrix -- this little trick allows us to treat the bias
41 # as a trainable parameter within the weight matrix
42 X = np.c_[X, np.ones((X.shape[0]))]
43
44 # partition the data into training and testing splits using 50% of
45 # the data for training and the remaining 50% for testing
46 (trainX, testX, trainY, testY) = train_test_split(X, y,
47 test_size=0.5, random_state=42)
在第35行,我们调用了make_blobs,它生成了分成两个类的1000个数据点。这些数据点是2D的,这意味着“特征向量”的长度是2。这些数据点的标签不是0就是1。我们的目标是训练一个能够正确预测每个数据点的类标签的分类器。
第42行应用了“偏差技巧”(上面详述了),它允许我们明确地跳过跟踪偏差向量b,通过在我们的设计矩阵x中插入一个全新的列1作为最后一个条目,在所有特征向量中添加一个包含恒定值的列,可以让我们将偏差视为权重矩阵W中的一个可训练参数,而不是一个完全独立的变量。
一旦我们插入了1列,我们就在第46行和第47行将数据划分为训练和测试分区,使用50%的数据用于训练,50%的数据用于测试。
我们的下一个代码块处理随机初始化我们的权重矩阵使用均匀分布,这样它有相同的维数作为我们的输入特征(包括偏差):
49 # initialize our weight matrix and list of losses
50 print("[INFO] training...")
51 W = np.random.randn(X.shape[1], 1)
52 losses = []
你也可能看到两个0和1重量初始化,但正如我们将在这本书的后面发现,良好的初始化是训练一个神经网络的关键在合理的时间内,所以随机初始化以及简单的启发式胜出在绝大多数情况下[84]。
第52行初始化一个列表,记录每个epoch之后的损失。在Python脚本的最后,我们将绘制损失(理想情况下,这种损失应该随着时间的推移而减少)。
请注意,零类在100%的情况下是如何正确分类的,而一个类在99%的情况下是如何正确分类的。这种差异的原因是香草梯度下降只对每个epoch执行一次权值更新——在这个例子中,我们训练我们的模型为100个epoch,所以只有100个更新发生。根据权重矩阵的初始化和学习率的大小,我们可能无法学习一个可以分离点的模型(即使它们是线性可分的)。
对于简单的梯度下降,你最好以更小的学习速率训练更多的epoch来帮助克服这个问题。然而,正如我们将在下一节中看到的,梯度下降的一个变体,称为随机梯度下降,对每批训练数据执行一个权值更新,这意味着每个epoch有多个权值更新。这种方法导致更快、更稳定的收敛。
9.2随机梯度下降法(SGD)
相反,我们应该应用随机梯度下降(SGD),这是对标准梯度下降算法的一个简单修改,该算法计算梯度,并在小批量的训练数据上更新权值矩阵W,而不是在整个训练集上。虽然这种修改导致了“更多噪声”的更新,但它也允许我们沿着梯度采取更多的步骤(每批处理一步,而不是每个epoch一步),最终导致更快的收敛,对损失和分类精度没有负面影响。
9.2.1 Mini-batch SGD
回顾普通的梯度下降算法,应该(多少)很明显,该方法在大型数据集上运行非常缓慢。之所以这么慢,是因为梯度下降的每次迭代都要求我们在更新权值矩阵之前,对训练数据中的每个训练点进行预测。对于像ImageNet这样的图像数据集,我们有超过120万的训练图像,这个计算可能需要很长时间。
结果还表明,在沿着我们的权重矩阵迈出一步之前,计算每个训练点的预测是一种计算浪费,并且对我们的模型覆盖几乎没有帮助。
while True:
2 batch = next_training_batch(data, 256)
3 Wgradient = evaluate_gradient(loss, batch, W)
4 W += -alpha * Wgradient
香草梯度下降和SGD之间的唯一区别是添加了next_training_batch函数。我们不是在整个数据集上计算梯度,而是对数据进行采样,产生一批数据。我们在批处理上评估梯度,并更新我们的权值矩阵w。从实现的角度来看,我们也尝试在应用SGD之前随机化我们的训练样本,因为算法对批处理很敏感。
看完SGD的伪代码后,您会立即注意到引入了一个新参数:批处理大小。在SGD的“纯粹”实现中,您的小批量大小将是1,这意味着我们将从训练集中随机抽样一个数据点,计算梯度,并更新我们的参数。然而,我们经常使用> 1的小批量。典型的批量大小包括32、64、128和256。
那么,为什么要使用批量> 1呢?首先,批量大小> 1有助于减少参数更新(http://pyimg.co/pd5w0)中的方差,从而实现更稳定的收敛。其次,2的幂通常是可取的批量大小,因为他们允许内部线性代数优化库更有效。
一般来说,迷你批处理大小不是一个超参数,您不应该太担心[57]。如果你使用GPU来训练你的神经网络,你要确定有多少训练例子适合你的GPU,然后使用2的最接近的幂作为批处理的大小,这样批处理将适合GPU。对于CPU
以上是关于)的主要内容,如果未能解决你的问题,请参考以下文章