Spark追妻系列(默认分区规则)
Posted 数仓白菜白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark追妻系列(默认分区规则)相关的知识,希望对你有一定的参考价值。
年前的最后一个天,最后一篇博文
小谈
今天是除夕夜,写完这篇博客就去下载LOL玩云顶之奕去了,今天晚上放松放松,明天是大年初一,大年初一可能会更文。
困惑
刚开始学习Spark,对于一些代码不理解,为什么要写SparkConf和SrakContext才能运行,当习惯敲这个之后,对于setMaster又不理解,只知道跟着人家的视频写上Local.
跟着视频按部就班的学着,能听懂一二剩下的八九分都不理解,跟着人家的视频走,视频里面的老师说啥自己听啥,使得自己空知道怎么做,而不知道为什么是这样做。
问题发生在这一次的手误
val wordCount = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)将上面的*删掉了
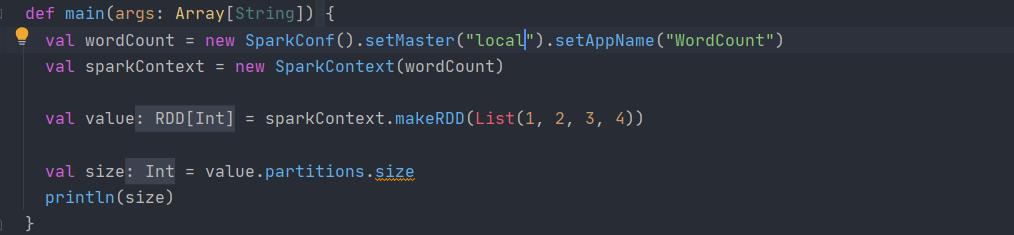
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)就这样,到最后输出的时候SaveAsTextFile
按理来说,会出现12个文件,但是只出现了1个,(关于为什么是十二,自己只知道是本地的cpu核数),为什么只出现了一个,当场就愣住了。这就是所谓的治标不治本吗?
- 在Local[*]的时候,本地会有12个分区
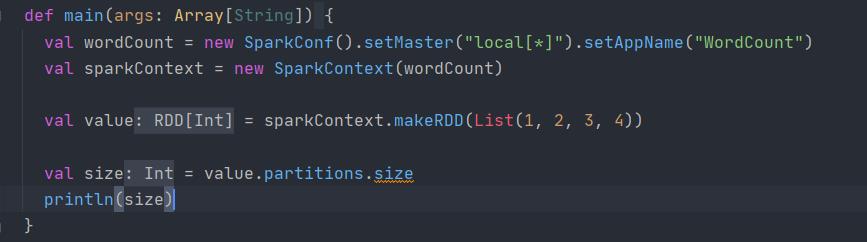
2.在Local的时候,本地只会有一个分区
终究,还是将手伸向了源码
分析
问题的根源就是这三句

为什么Local 和 Local[*]的结果是不一样的?同样是将结果保存在文件夹里面,最后显示的分区数目是不一样的
一步一步来,看源码
1.进入makeRdd源码,发现makeRdd的底层就是parallelize方法
在创建RDD的时候可以makeRDD也可以parallelize
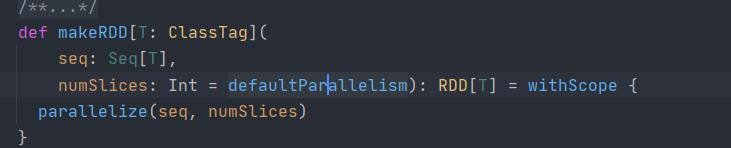
2.点击defaultParallelism,继续深入
3.在子类中找到defaultParallelism实现方法

4.重点来了

def getInt(key: String, defaultValue: Int): Int =
catchIllegalValue(key)
getOption(key).map(_.toInt).getOrElse(defaultValue)
//如果指定了并行度,那么就用指定的并行度
//如果没有指定并行度,就用defaultValue 默认的并行度上面这段代码就是重点了。
这段告诉我们的就是如果我们创建RDD的时候,指定了并行度,那么就采取指定的并行度,如果不指定并行度,那么就采用默认的并行度。
既然已经知道了为什么在最后输出文件的时候会有不同的文件数,不妨继续往下面走一走,看看默认的并行度是多少
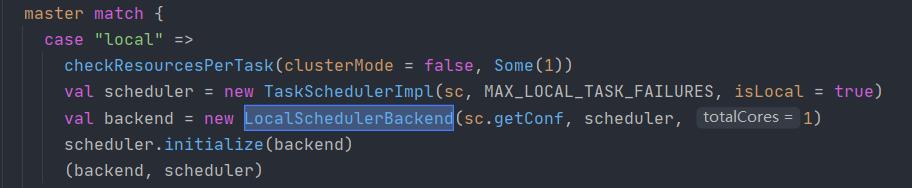
上面就是master也就是刚开始的SetMaster。
1.如果是local
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")正如上面的截图,当使用local的时候,系统定义的本地并行度就是1
totalCores = 1 本地的分区个数就是1
2.如果是local[*]
val wordCount = new SparkConf().setMaster("local[*]").setAppName("WordCount")
刚开始会进行正则匹配
val LOCAL_N_REGEX = """local\\[([0-9]+|\\*)\\]""".r匹配到的就是local[*] 或者 local[0-9]
如果是local[*] 那么就用本地电脑的核数,如果不是*,那么就用自己定义的0-9的数组作为核数。
TotalCores在这里就是本地电脑的核数,也就是
上面的图中,也就是我的电脑核数是12,那么我最后生成文件的个数就是12,
上面所讲的就是Spark本地环境中的默认分区规则,在默认分区规则之外,还有数据在分区存储的规则没有讲,碍于时间关系。将会在年后进行讲解。
总结:
临近除夕,这篇博客简短的写了一个,就是讲一下Local[*]和Local的区别,下次将会讲数据在分区文件里面的存储规则以及自定义分区
多读源码,尽管看的不是特别懂,但是慢慢来,一定可以比现在熟练
以上是关于Spark追妻系列(默认分区规则)的主要内容,如果未能解决你的问题,请参考以下文章