Mybatis 一连串提问,被面试官吊打了!
Posted Java知音_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis 一连串提问,被面试官吊打了!相关的知识,希望对你有一定的参考价值。
点击关注公众号,实用技术文章及时了解
最近出去面试,在简历中写了些关于Mybatis的技术点,于是面试官就开始对我不断询问,本文特意记录下面试中遇到的一些问题。
说说什么是Mybatis
Mybatis是一款对于Sql进行了一定封装的持久化sql框架,将常用的crud接口进行了一定的封装,减轻了开发人员对于SQL操作的繁琐性。
在工作中为什么会选择使用这款框架?
简化了sql的相关操作复杂度
自动处理好了链接的创建,释放,sql的参数组装
可以引入一些第三方缓存的插件
提供了对于Spring容器的集成功能
学习成本低,市面上也有比较多的资料信息
说一下正常的JDBC执行规范?
首先需要通过DriverManager建立链接,然后获取到Statement对象。
public class JdbcApplication
static String driverName = "com.mysql.jdbc.Driver";
static String username = "root";
static String password = "test";
static String url = "jdbc:mysql://cloud.db.com:3306/db_user";
public static void main(String[] args) throws SQLException
Connection connection = DriverManager.getConnection(url,username,password);
String sql = "select * from t_user";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
ResultSet resultSet = preparedStatement.executeQuery();
while(resultSet.next())
int id = resultSet.getInt("id");
System.out.println(id);
resultSet.close();
preparedStatement.close();
connection.close();
建立一个数据源的大致步骤:
构建数据源
创建数据库链接,一般是可以通过
DriverManager.getConnection()来获取创建sql并且执行,例如调用Statement接口执行,JDBC的api中定义的
executeQuery()方法执行查询操作,executeUpdate()方法执行更新操作结果集的处理,一般都是对resultSet进行getint,getString之类的操作。
链接的释放,例如说.close相关操作。
你说自己看过MyBatis的源码,列举些内部比较核心的类说说?
Configuration
管理 mysql-config.xml 全局配置关系类
SqlSessionFactory
SqlSession 管理工厂接口
SqlSession
是一个面向用户(程序员)的接口。SqlSession 中提 供了很多操作数据库的方法
Executor
执行器是一个接口(基本执行器、缓存执行器)
作用:SqlSession 内部通过执行器操作数据库
MappedStatement
底层封装对象 作用:对操作数据库存储封装,包括 sql 语句、输入输出参数
StatementHandler
具体操作数据库相关的 handler 接口
ResultSetHandler
具体操作数据库返回结果的 handler 接口
SQL对象
mybatis内部拼接sql语句信息的封装对象
ScriptRunner
mybatis内部一个能接收链接参数信息的脚本运行器。
SqlRunner
使用SqlRunner可以简化我们的jdbc执行操作,代码如下:
public static void main(String[] args) throws SQLException
Connection connection = DriverManager.getConnection(url,username,password);
SqlRunner sqlRunner = new SqlRunner(connection);
String querySql = new SQL()
SELECT("*");
FROM("t_user");
WHERE("1=1");
.toString();
List<Map<String,Object>> resultMap = sqlRunner.selectAll(querySql);
for (Map<String, Object> stringObjectMap : resultMap)
System.out.println(stringObjectMap.toString());
MetaObject
一个比较常用的反射工具类,在mybatis源码里面经常会看到。
MetaClass
这里面包含了一个org.apache.ibatis.reflection.Reflector 对象,这个对象内部似乎包含了比较多的关于反射获取的属性值,例如说方法信息,字段属性等。
ObjectFactory
这是一个创建对象的工厂设计,在创建某些对象之前会先又一层包装的warrper,可以适当地调整入参信息。
ObjectFactory objectFactory = new DefaultObjectFactory();
List<Object> strs = new ArrayList<Object>();
List<Class<?>> classList = new ArrayList<>();
String str = objectFactory.create(String.class,classList,strs);ProxyFactory
是一个代理工厂,主要适配了mybatis里面的几种代理机制。ProxyFactory接口有两个不同的实现,分别为CglibProxyFactory和JavassistProxyFactory
如果不使用Spring框架,Mybatis框架该如何使用?
原生mybatis1的执行流程:
public static void main(String[] args) throws IOException
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//核心点在这
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> userList = mapper.selectAll();
System.out.println(userList.toString());
首先通过sqlsessionfactory结合配置文件的数据(可以是io流信息),创建出一个sqlsession,然后根据sqlsession获取到通过MapperProxy创建的jdk代理,当执行对应的sql语句的时候会调用invocationhandler里面的invoke语句。接下来就是一系列的crud封装的handler处理。
聊聊MyBatis内部的缓存设计
每当我们使用 MyBatis 开启一次和数据库的会话,MyBatis 会创建出一个 SqlSession 对象表 示一次数据库会话。在对数据库的一次会话中,我们有可能会反复地执行完全相同的查询语句,如果不采取一些措施的话,每一次查询都会查询一次数据库,而我们在极短的时间内 做了完全相同的查询,那么它们的结果极有可能完全相同,由于查询一次数据库的代价很大,这有可能造成很大的资源浪费。
为了解决这一问题,减少资源的浪费,MyBatis 会在表示会话的 SqlSession 对象中建立一个 简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候,如果判断先前有个完 全一样的查询,会直接从缓存中直接将结果取出,返回给用户,不需要再进行一次数据库查询了。
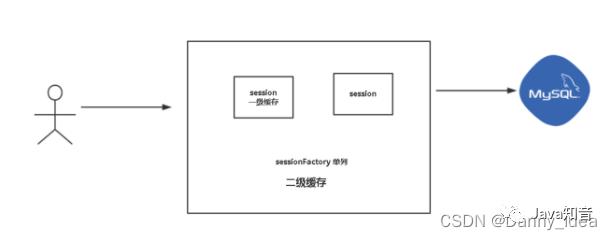
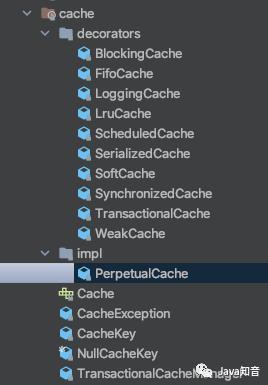
mybatis的内部的cache目录下包含有多种缓存的设计,全部都存放在了一个包内部,主要是对cache接口进行了多实现。
一级缓存
一级缓存是和sqlsession做绑定关联的一种存储设计,当首次查询出来的数据会被存储到一个hashmap中,而对应的cacheKey这块可以在源代码org.apache.ibatis.executor.BaseExecutor#createCacheKey里看到。
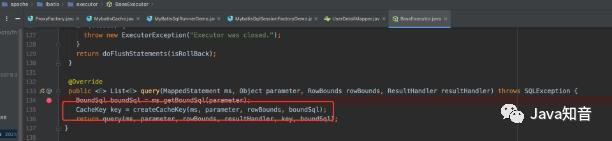
如果需要查看缓存的更多细节部分,可以debug模式切换到org.apache.ibatis.cache.impl.PerpetualCache里面进行查看。
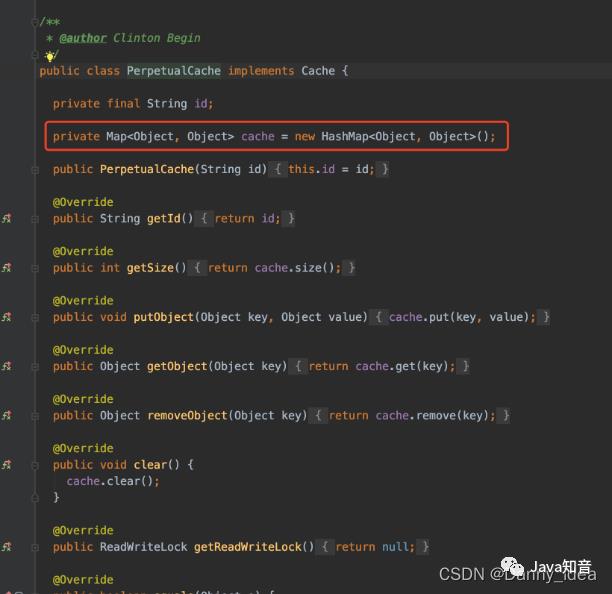
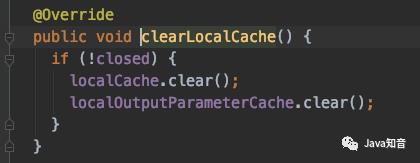
内部包含了一个HashMap集合用于存储缓存数据。而所谓的清除缓存就是将这个hashmap执行clear操作。
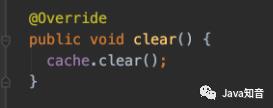
缓存如何实现唯一值?
通过类的函数id+包名实现唯一值图片:
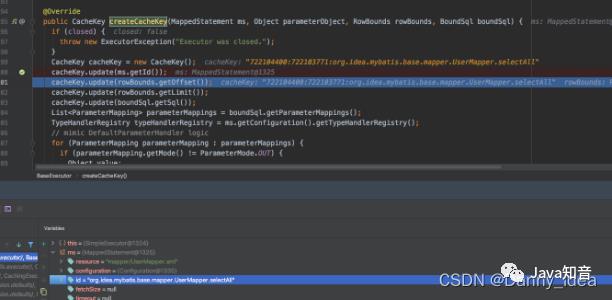
内部对于缓存还会区分环境类型:
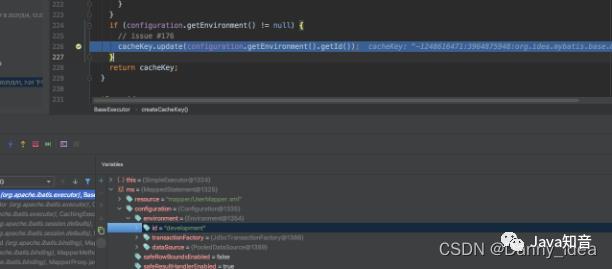
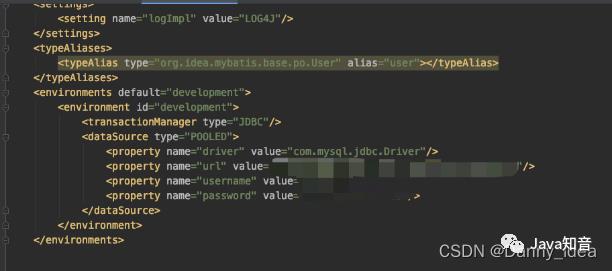
这里的环境id正好对应了配置文件中所填写的id:
为什么一级缓存也叫查询缓存
因为查询出来的数据会放到一个map中,一旦出现写操作,缓存就会失效。
什么时候一级缓存会失效?
一旦涉及到对应的update操作,就会清理缓存。
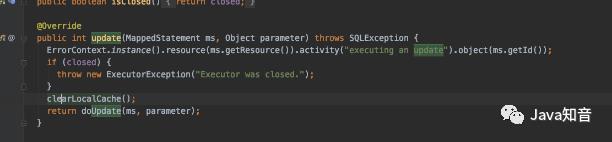
源代码如下所示:
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed)
throw new ExecutorException("Executor was closed.");
clearLocalCache();
return doUpdate(ms, parameter);
框架内部是如何识别该清理哪些缓存?
由于按照包名+类名+id的方式构建cache的key,所以没法识别出该清理哪个缓存,因此一旦进行更新操作的时候是直接将整个map进行清理。
一级缓存和sqlsession之间的关系
一个sqlsession会有一个自己专属的map用作一级缓存,不同sqlsession之间的缓存不会共享。
多数据源的情况下会连接不同的sqlsessionfactory,不同的sqlsessionfactory则对应不同的sqlsession,所以一级缓存不同,因此查询和更新的时候不会互相影响。
可以手动清理缓存吗?
可以通过sqlSession.clearCache();操作实现
如何判断两次查询是同一个查询:
按照cachekey的构建机制判断:
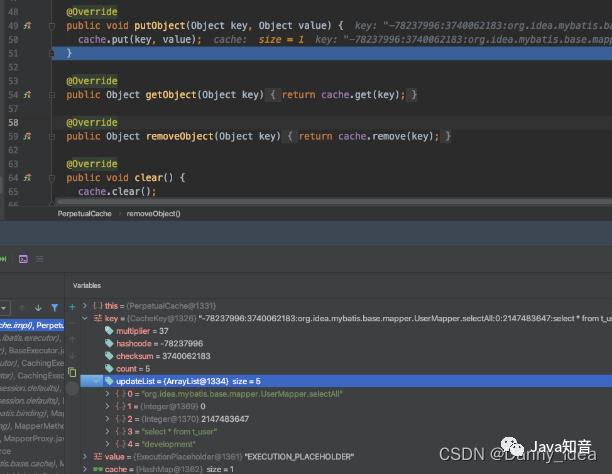
缓存的key是由好几个参数构建出来的:
hashcode
查询的条数范围:如果是selectall系列,就是0-2147483647(21亿左右)
sql语句
enviorment的配置id
二级缓存
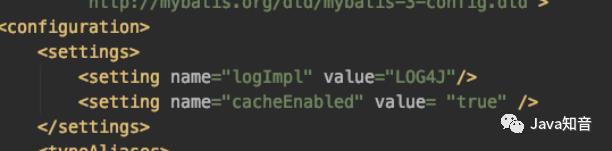
框架的内部默认是没有开启二级缓存的,需要开发人员手动开启。二级缓存是根据sqlsession进行识别的,同一个mapper在不同的sqlsession中会共享缓存。
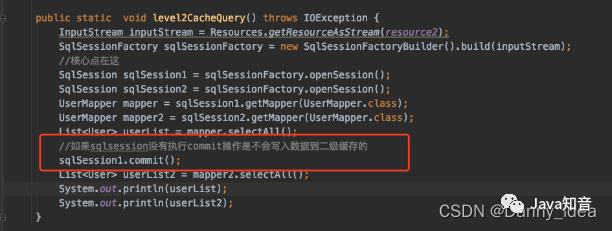
代码案例:
需要执行commit操作才会写入到二级缓存中
同时在xml配置里需要额外配置:
对应到mapper文件中配置:
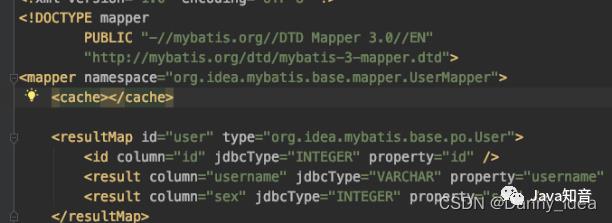
mybatis中还可以配置userCache和flushCache等配置项,userCache是用来设置是否禁用二级缓存的,在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
推荐

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
以上是关于Mybatis 一连串提问,被面试官吊打了!的主要内容,如果未能解决你的问题,请参考以下文章
一面字节跳动,被面试官吊打!幸得华为内推,三面拿到offer
被面试官吊打系列之JUC之 可重入读写锁ReentrantReadWriteLock 之 源码详尽分析
软件测试字节跳动一面,被面试官吊打!幸得华为内推,三面拿到offer