在校大学生用 Python 当爬虫一个月能赚3000吗?
Posted 码农成神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在校大学生用 Python 当爬虫一个月能赚3000吗?相关的知识,希望对你有一定的参考价值。
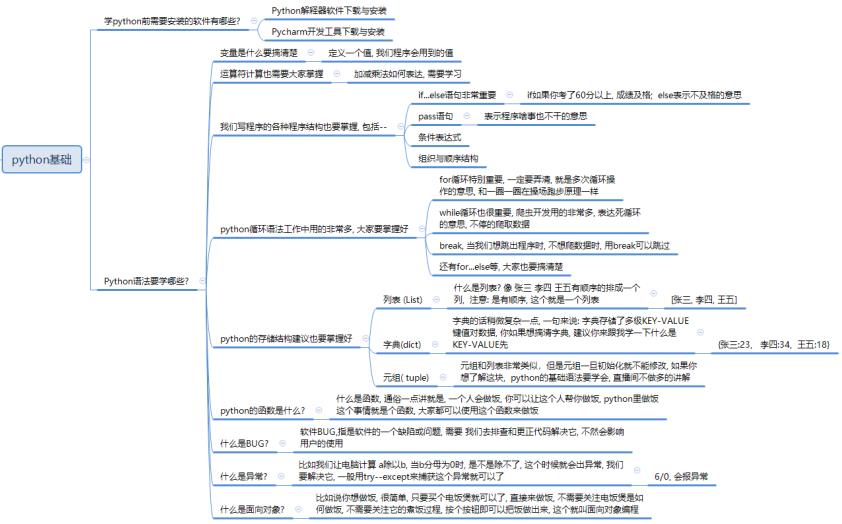
有人问:在校大学生用 python 当爬虫一个月能赚3000吗?如果能每天要工作多长时间?自学的话要多长时间可以达到这个水平?
我还未毕业的时候,曾经用 scrapy 抓了很多数据,卖给过不少公司。基本上后面3年主要就是靠卖数据生存,那会儿收入一度比工资多。
近两年爬虫门槛降低很厉害,很多公司已经有了专职的IT爬虫人员,以及很多公司研发出专门的爬虫工具来做一些基础爬虫的工作售卖给需求方,低端爬虫的工作薪酬也逐渐走低,同时市面上一些外包的需求也大大降低。
但像月收入 3000 这种还是不成问题的,但你要具备相对成熟一些的业务能力,比如市面上主流的爬虫技术,理解需求的能力,跟客户沟通的能力等等,那可能这些东西你还没有接触过,这些能力分别如何培养呢?
1. 在校大学生: 最好是数学或计算机相关专业,编程能力还可以的话,稍微看一下爬虫知识,主要涉及一门语言的爬虫库、html解析、内容存储等;由于在校学生的工程经验比较少,建议只接一些少量数据抓取的项目,而不要去接一些监控类的项目、或大规模抓取的项目。慢慢来,步子不要迈太。
2. 在职人员: 如果你本身就是爬虫工程师,接私活很简单。如果你不是,也不要紧。只要是做IT的,稍微学习一下爬虫应该不难。在职人员的优势是熟悉项目开发流程,工程经验丰富,能对一个任务的难度、时间、花费进行合理评估。可以尝试去接一些大规模抓取任务、监控任务、移动端模拟登录并抓取任务等,收益想对可观一些。
从 0 开始的话,大体上可分为三个阶段去实现:
- 第一阶段 入门,掌握必备基础知识,比如Python基础、网络请求的基本原理等;
-
第二阶段 模仿,跟着别人的爬虫代码学,弄懂每一行代码,熟悉主流的爬虫工具;
-
第三阶段 自己动手,到了这个阶段你开始有自己的解题思路了,可以独立设计爬虫系统。
爬虫涉及的技术包括但不限于熟练一门编程语言(这里以 Python爬虫为例) HTML 知识、HTTP 协议的基本知识、正则表达式、数据库知识,常用抓包工具的使用、爬虫框架的使用、涉及到大规模爬虫,还需要了解分布式的概念、消息队列、常用的数据结构和算法、缓存,甚至还包括机器学习的应用,大规模的系统背后都是靠很多技术来支撑的。
数据分析、挖掘、甚至是机器学习都离不开数据,而数据很多时候需要通过爬虫来获取,因此,即使把爬虫作为一门专业来学也是有很大前途的。
这里分享一些我自学爬虫的时候看过的书籍吧,这里面的有的可以速读,有的需要精读,还有项目实战部分,是需要操作的:
《Python 爬虫开发与项目实战》
本书籍分为基础篇、中级篇、深入篇,由浅及深地讲解了爬虫开发中所需的知识和技能。本书是一本适合初学者的书籍,既有对基础知识点的讲解,也涉及关键问题和难点的分析和解决。
基础篇
第1章 回顾 Python 编程
- 安装 Python
- 搭建开发环境
- IO编程
- 进程和线程
- 网络编程
第2章 Web前端基础
- W3C标准
- HTTP标准
- 小结
第3章 初识网络爬虫
- 网络爬虫概述
- HTTP 请求的Python 实现
- 小结

第4章 HTML 解析大法
- 初识Firebug
- 正则表达式
- 强大的 BeautifulSoup
- 小结
第5章 数据存储(无数据库版)
- HTML 正文抽取
- 多媒体文件抽取
- Email 提醒
- 小结
第6章 实战项目:基础爬虫
- 基础爬虫架构及运行流程
- URL 管理器
- HTML 下载器
- HTML 解析器
- 数据存储器
- 爬虫调度器
- 小结

第7章 实战项目:简单分布式爬虫
- 简单分布式爬虫结构
- 控制节点
- 爬虫节点
- 小结
中级篇
第8章 数据存储 (数据库版)
- SQLite
- mysql
- 更适合爬虫的MongoDB
- …

第9章 动态网站抓取
- Ajax 和动态 HTML
- 动态爬虫1:爬取影评信息
- PhantomJS
- Selenium
- 动态爬虫1:爬取去哪网
- …
第10章 Web 端协议分析
- 网页登录 POST 分析
- 验证码问题
- www>m>wap
- …
第11章 终端协议分析
- PC客户端抓包分析
- APP抓包分析
- API爬虫:爬取mp3 资源
第12章 初窥 Scrapy 爬虫框架
- Scrapy 爬虫架构
- 安装 Scrapy
- 创建 cnblogs 项目
- 创建爬虫模块
- 选择器
- 命令行工具
- 定义 Item
- 翻页功能
- 构建 Item Pipeline
- 内置数据存储
- 内置图片和文件下载方式
- 启动爬虫
- 强化爬虫
- …

第13章 深入 Scrapy 爬虫框架
- 再看 Spider
- Item Loader
- 再看 Item Pipeline
- 请求与响应
- 下载器中间件
- Spider 中间件
- 扩展
- 突破反爬虫
- …
第14章 实战项目:Scrapy 爬虫
- 创建知乎爬虫
- 定义 Item
- 创建爬虫模块
- Pipeline
- 优化措施
- 部署爬虫
- …
深入篇
第15章 增量式爬虫
- 去重方案
- BloomFilter 算法
- Scrapy 与 BloomFilter
- …

第16章 分布式爬虫与Scrapy
- Redis 基础
- Python 和 Redis
- MongoDB 集群
- …
第17章 项目实战:Scrapy 分布式
- 创建云起书院爬虫
- 定义 Item
- 编写爬虫模块
- Pipeline
- 应对反爬虫机制
- 去重优化
- …

第18章 人性化 PySpider 爬虫框架
- PySpider 与 Scrapy
- 安装 PySpider
- 创建豆瓣爬虫
- 选择器
- Ajax 和 HTTP 请求
- PySpider 和 PhantomJS
- 数据存储
- PySpider 爬虫架构
- …
更多 Python 资料:
注意:学习资料在于精,不在于多,多反而不是好事,作为一名程序员,大家的学习时间都太宝贵了,我们要把80%时间投入在最有价值20%的学习内容上。
以上 Python 资料免费分享,需要的朋友可以微信扫描下方 CSDN 官方认证二维码,免费领取Python资料!

以上是关于在校大学生用 Python 当爬虫一个月能赚3000吗?的主要内容,如果未能解决你的问题,请参考以下文章