深度学习入门笔记(二十):经典神经网络(LeNet-5AlexNet和VGGNet)
Posted 我是管小亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习入门笔记(二十):经典神经网络(LeNet-5AlexNet和VGGNet)相关的知识,希望对你有一定的参考价值。
欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
1、为什么要进行实例探究?
最快最直观地熟悉这些网络结构(比如卷积层、池化层以及全连接层这些组件)的方法就是看看一些卷积神经网络的实例分析,就像很多人通过看别人的代码来学习编程一样,通过研究别人构建有效组件的案例是个不错的办法,实际上在计算机视觉任务中表现良好的神经网络框架往往也适用于其它任务,比如,有人已经训练或者计算出擅长识别猫、狗、人的神经网络或者神经网络框架,那么对于计算机视觉识别任务的自动驾驶汽车,是完全可以借鉴的。
按照进度,你应该可以读一些计算机视觉方面的研究论文了,比如这几个经典的网络:

- LeNet-5 网络,初代手写数字识别网络,我记得应该是1980年代的;
- 经常被引用的 AlexNet,开启新一轮深度学习热潮;
- 还有 VGG 网络,发现了深度对网络效果提升的巨大影响;
- 然后是 ResNet,又称残差网络;
- 还会讲谷歌 Inception 神经网络的实例分析。
了解了这些神经网络,相信你会对如何构建有效的卷积神经网络更有感觉!!还有期中使用的各种网络组件,即使计算机视觉并不是你的主要方向,你也会从 ResNet 和 Inception 网络这样的实例中找到一些不错的想法。
2、经典网络
这次笔记来学习几个经典的神经网络结构,分别是:
- LeNet-5
- AlexNet
- VGGNet
开始吧。
1)LeNet-5
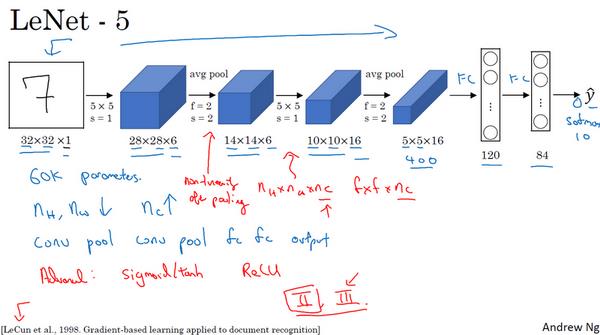
首先看看 LeNet-5 的网络结构。
论文地址:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
假设有一张32×32×1的图片,LeNet-5 可以识别图中的手写数字,比如7,因为 LeNet-5 是针对灰度图片训练的,所以图片的大小只有32×32×1,因为 LeNet-5 的结构使用6个5×5的过滤器,步幅为1,padding 为0,所以输出结果为28×28×6,然后进行池化操作,在这篇论文写成的那个年代,人们更喜欢使用平均池化,而现在我们可能用最大池化更多一些!不管怎样,过滤器的宽度为2,步幅为2,图像的尺寸,高度和宽度都缩小了2倍,输出结果是一个14×14×6的图像。
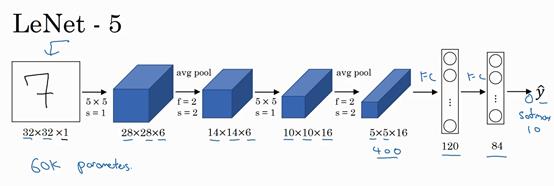
接下来是卷积层,用一组16个5×5的过滤器,所以新的输出结果有16个通道,而 LeNet-5 的论文是在1998年撰写的,当时人们并不使用 padding,或者总是使用 valid 卷积,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小,所以图像从14到14缩小到了10×10,然后又是池化层,高度和宽度再缩小一半,输出一个5×5×16的图像。将所有数字相乘,乘积是400。
然后下一层是全连接层,有400个节点,每个节点有120个神经元,这里已经有了一个全连接层,但有时还会从这400个节点中抽取一部分节点84个,去构建另一个全连接层,就像这样,有2个全连接层。
最后一步就是利用这84个特征得到最后的输出,所以在这里再加一个节点用来预测 y ^ \\haty y^ 的值, y ^ \\haty y^ 有10个可能的值,对应识别0-9这10个数字。在现在的版本中则使用 softmax 函数输出结果,而在当时,LeNet-5 网络在输出层使用了另外一种现在已经很少用到的分类器。
LeNet-5 的神经网络会小一些,只有约6万个参数,而现在,经常看到含有一千万到一亿个参数的神经网络,比这大1000倍的神经网络也不在少数。不管怎样,如果从左往右看,随着网络越来越深,图像的高度和宽度在缩小,从最初的32×32缩小到28×28,再到14×14、10×10,最后只有5×5,与此同时,随着网络层次的加深,通道数量一直在增加,从1增加到6个,再到16个。
对于那些想尝试阅读论文的同学,再补充几点:
- 接下来的部分主要针对那些打算阅读经典论文的同学,所以会更加深入。
- 这些内容如果你看过了,完全可以跳过。
- 当然也可以再看一下,算是对神经网络历史的一种回顾吧。
- 最后,听不懂也不要紧,慢慢来。
如果认真读到这篇经典论文 LeNet-5 时,你会发现,过去人们使用 sigmod 函数和 tanh 函数,而不是 ReLu 函数,这种网络结构的特别之处还在于,各网络层之间是有关联的,这在今天看来显得很有趣。比如说,在当时计算机的运行速度非常慢,为了减少计算量和参数,经典的 LeNet-5 网络使用了非常复杂的计算方式,论文中提到的这些复杂细节,现在一般都不用了。
2)AlexNet
第二种经典神经网络是 AlexNet,是以论文的第一作者 Alex Krizhevsky 的名字命名的,另外两位合著者是 ilya Sutskever 和 Geoffery Hinton,努力也许以后会有你自己的名字命名的网络结构也未可知。
论文地址:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
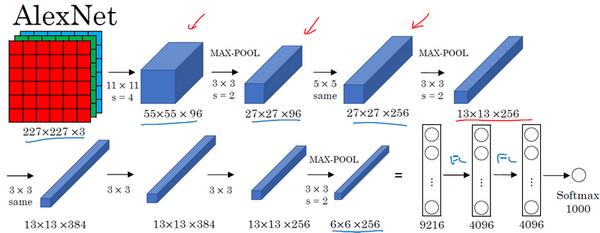
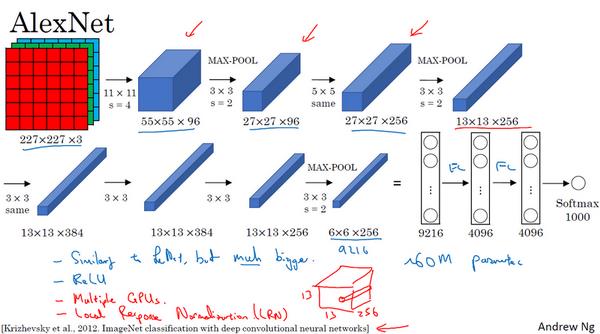
首先用一张227×227×3的图片作为输入,实际上原文中使用的图像是224×224×3,但是如果你尝试去推导一下,会发现227×227这个尺寸更好一些。
第一层使用96个11×11的过滤器,步幅为4,因此尺寸缩小到55×55,缩小了4倍左右。然后用一个3×3的过滤器构建最大池化层, f = 3 f=3 f=3,步幅 s s s 为2,卷积层尺寸缩小为27×27×96。
接着再执行一个5×5的卷积,padding 之后,输出是27×27×276。然后再次进行最大池化,尺寸缩小到13×13。
再执行一次 same 卷积,相同的 padding,得到的结果是13×13×384,384个过滤器。
再做一次 same 卷积,就像这样。再做一次同样的操作,最后再进行一次最大池化,尺寸缩小到6×6×256。
6×6×256等于9216,将其展开为9216个单元,然后是一些全连接层。
最后使用 softmax 函数输出识别的结果,看它究竟是1000个可能的对象中的哪一个。
实际上,你应该可以看出,这个神经网络与 LeNet 有很多相似之处,不过 AlexNet 要大得多,正如前面讲到的 LeNet 或 LeNet-5 大约有6万个参数,而 AlexNet 包含约6000万个参数。当用于训练图像和数据集时,AlexNet 能够处理非常相似的基本构造模块,这些模块往往包含着大量的隐藏单元或数据,这一点 AlexNet 表现出色。
AlexNet 比 LeNet 表现更为出色的另一个原因是它使用了 ReLu 激活函数。
同样的,还会讲一些比较深奥的内容,如果你并不打算阅读论文,不听也没有关系。
第一点,在写这篇论文的时候,GPU 的处理速度还比较慢,所以 AlexNet 采用了非常复杂的方法在两个 GPU 上进行训练,大致原理是,这些层分别拆分到两个不同的 GPU 上,同时还专门有一个方法用于两个 GPU 进行交流。
论文还提到,经典的 AlexNet 结构还有另一种类型的层,叫作 局部响应归一化层(Local Response Normalization),即 LRN 层,这类层应用得并不多,甚至现在已经没人用了,,,所以没有专门讲。局部响应归一层的基本思路是,假如这是网络的一块,比如是13×13×256,LRN 要做的就是选取一个位置,从这个位置穿过整个通道,能得到256个数字,并进行归一化。
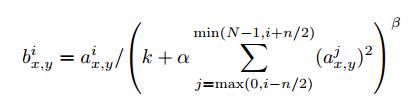
你可能会问,为什么要进行局部响应归一化?
对于这张13×13的图像中的每个位置来说,可能并不需要太多的高激活神经元,但是后来,很多研究者发现 LRN 起不到太大作用,这也是它被划掉的内容之一,现在并不用 LRN 来训练网络。
3)VGGNet
这次笔记要讲的第三个,也是最后一个范例是 VGG,也叫作 VGG-16 网络(VGG 有16和19,不过一般说的是16)。
论文地址:https://arxiv.org/pdf/1409.1556.pdf
值得注意的一点是,VGG-16 其实是一个很深的网络,但是它的一大优点是简化了神经网络结构,所以并没有那么多超参数,是一种只需要专注于构建卷积层的简单网络。。
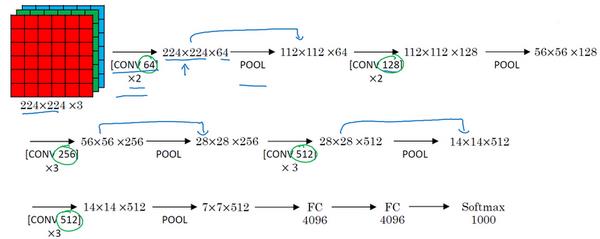
输入图像尺寸是224×224×3,进行第一个卷积之后得到224×224×64的特征图,接着还有一层224×224×64,得到这样2个厚度为64的卷积层,意味着进行了两次卷积,这里采用的大小都为3×3,步幅为1,并且都是 same 卷积。
接下来创建一个池化层,池化层将输入图像进行压缩,从224×224×64缩小到多少呢?没错,减少到112×112×64。
然后又是若干个卷积层,使用128个过滤器,以及一些 same 卷积,输出112×112×128。
然后进行池化,可以推导出池化后的结果是56×56×128。
接着再用256个相同的过滤器进行三次卷积操作,然后再池化,然后再卷积三次,再池化,如此进行几轮操作后,将最后得到的7×7×512的特征图进行全连接操作,得到4096个单元,然后进行 softmax 激活,输出从1000个对象中识别的结果。
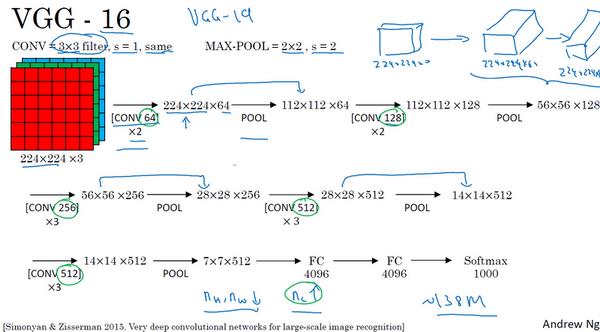
顺便说一下,VGG-16 的这个数字16,就是指在这个网络中包含16个层(卷积层和全连接层),所以确实是个很大的网络,总共包含约1.38亿个参数,即便以现在的标准来看,都算是非常大的网络,但 VGG-16 的结构并不复杂,这点是非常吸引人的,而且网络结构很规整,都是几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。
同时,卷积层的过滤器数量变化存在一定的规律,由64翻倍变成128,再到256和512,作者可能认为512已经足够大了,所以后面的层就不再翻倍了。无论如何,每一步都进行翻倍,或者说在每一组卷积层进行过滤器翻倍操作,正是设计此种网络结构的另一个简单原则。这种相对一致的网络结构对研究者很有吸引力,而它的主要缺点是需要训练的特征数量非常巨大。
有些文章还介绍了 VGG-19 网络,它甚至比 VGG-16 还要大,但是由于 VGG-16 的表现几乎和 VGG-19 不分高下,所以很多人还是会使用 VGG-16。另外一点,我最喜欢它的一点是,文中揭示了,随着网络的加深,图像的高度和宽度都在以一定的规律不断缩小,每次池化后刚好缩小一半,而通道数量在不断增加,而且刚好也是在每组卷积操作后增加一倍,也就是说,图像缩小的比例和通道数增加的比例是有规律的,就是一个非常完美的对称结构,从这个角度来看,这篇论文真的很吸引人。
3、总结
以上就是三种经典的网络结构,如果你对这些论文感兴趣,建议的顺序是从介绍 AlexNet 的论文开始,然后就是 VGG 的论文,最后有空了再看 LeNet 的论文,虽然有些晦涩难懂,但对于了解这些网络结构很有帮助。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
- 深度学习入门笔记(十九):卷积神经网络(二)
- 深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程
以上是关于深度学习入门笔记(二十):经典神经网络(LeNet-5AlexNet和VGGNet)的主要内容,如果未能解决你的问题,请参考以下文章