龙蜥利器:系统运维工具 SysAK的云上应用性能诊断 | 龙蜥技术
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了龙蜥利器:系统运维工具 SysAK的云上应用性能诊断 | 龙蜥技术相关的知识,希望对你有一定的参考价值。
简介:本文从大量的性能诊断实践出发,来介绍 SysAK 在性能诊断上的方法论及相关工具。

文/张毅:系统运维SIG核心成员、SysAK 项目负责人;毛文安:系统运维 SIG 负责人。
系统运维既要业务稳定的运行,又要最大化的利用资源,因此对于应用性能的评估也是重要的一环,作为系统运维的利器,SysAK 自然少不了这方面的能力。但对于应用性能的诊断,有时比稳定性问题更难,非专业人员甚至有无从下手的感觉。本文从大量的性能诊断实践出发,来介绍 SysAK 在性能诊断上的方法论及相关工具。
SysAK 应用性能诊断方法
简而言之,SysAK 诊断应用性能的基本思路就是自顶向下并进行关联拓展。
自上向下即应用->OS->硬件,关联拓展则包括同级应用、系统影响、以及网络拓扑。说起来简单,但实施起来却是一个大工程。
1、应用画像
首先做的就是应用画像,要对应用的性能进行诊断,首先要对其进行画像,包括其业务吞吐、系统资源使用等,然后再根据画像中占比比较大的性能瓶颈进行逐一专项分析。具体来说,包括应用的并发数、运行和睡眠的统计。 并发数简单,统计业务任务数就行了,这个主要是为后面的资源使用作为参考。
1.1、运行统计
即对系统基础资源的利用进行分类统计,应用运行时基础资源占用就4类:
Cpu
通过 cpu 占用可知应用本身的吞吐是否高,并进一步通过 user/sys 的 cpu 占比可得知业务运行时更多的是在业务自身还是在内核资源的使用上。所以此处至少要包含运行时长、以及 user、sys 的各自比例。如果 sys 占比高,需要继续分析对应内核资源是否有异常情况,否则更多时候需要分析硬件资源上是否有瓶颈。
内存
通过内存的使用情况来判断内存的申请与访问是否是制约业务性能的因素。所以此处至少要包含内存分配总量、频率、缺页次数、跨 NUMA 节点访问次数和大小等的统计。
文件
通过文件访问的情况来判断文件 IO 是否是制约业务性能的因素。此处至少要包含文件读写频率、pagecache 命中率、平均 IO 时延等的统计。
网络
通过报文流量来判断网络是否是制约业务性能的因素,此处至少要包含流量统计、对端链接的网络拓扑等。
1.2、睡眠统计
如果应用运行周期内,睡眠时间占比很大,则很可能是影响业务性能的关键因素,此时就要分析睡眠的详细情况了。至少要包含三类行为的数据统计,包括具体行为的次数和时长:
主动睡眠:这类数据如果占比过高,则说明是应用自身行为。 用户临界资源竞争:这些数据如果占比过高,则需要优化应用。 内核资源等待:这类数据如果占比过高,则需要分析具体的系统内核资源瓶颈。 在有了应用画像以后,我们就对应用运行过程中的基本情况有了了解,如果发现瓶颈不在业务自身,那么就需要继续往下分析对应的系统资源或者硬件瓶颈了。
2、系统内核资源
系统内核资源制约应用性能的地方又可分为三大类:
2.1、干扰
一个服务器操作系统运行过程中,对应用运行的干扰源可能会很多,但干扰不一定会对业务造成影响,所以至少需要包含这些干扰源的频率和运行时间,来评估是否是关键因素。
至少需要包括以下干扰源的统计:
设备硬件中断
如果在业务运行过程中,某一类中断频率过高或者集中到某个 cpu,或者单次单次运行过过长,那么都都可能会影响到业务的性能,可以对中断进行打散绑定等操作观察效果。
系统定时中断
系统定时器过多,也可能会对业务的唤醒造成延迟,通常可以分析业务进程是否有大量的使用高精度定时器。
软中断
可能是网络流量是否有突发增加等。
内核线程
其他高优先级应用
2.2、瓶颈
系统内核资源种类繁多,应用模型不同,对内核资源的依赖也不同,所有瓶颈点无法完全覆盖,但至少需要包含几大类常见的内核资源的统计数据:
运行队列长度
这个可以表明是否业务进程/线程并发过多,或者是否绑核不合理等
fs/block 层时延
对于不同的文件系统或设备、IO 调度算法,可能会有不同的瓶颈点,通常需要进行分段统计时延来确定
内存分配延时
受内存水位、碎片的影响,内存分配的时延有时可能会很大
pagefault 时长与频率
内存缺页导致的内存请求、重映射、tlb flush 等对的开销是非常大的,如果频繁的进入到 pagefault 流程中,可以考虑从应用策略上进行优化,比如预分配内存池、使用大页等。
关键路径 kernel 锁的竞争
锁是不可避免的机制,kernel 态锁竞争通常会导致 sys 态的 cpu 升高,需要结合上下文进行具体分析。
2.3、策略
上述提到内核资源无法完全覆盖,但可以有另外一种方法去能观测一些数据,因为不同的内核策略可能有比较大的性能差异,所以可以尝试通过不同系统间的对比,找出配置的差异点。通常的系统配置采集如下:
内核启动参数
内核配置接口 sysctl/procfs/sysfs
内核模块差异
cgroup配置
3、虚拟化
当上述找不到瓶颈点时,或者我们想继续挖掘性能的剩余价值,通常就会到硬件这一侧,而目前业务部署在云上居多,所以在深入硬件层前,虚拟化层或者说主机侧也是绕不开的必要因素。对主机侧的性能分析,针对系统内核资源制约可以复用上述的方法,但对业务画像可以少做不少事,相对于应用业务,虚拟化这层的逻辑不会无限变化,我们可以从各个渠道了解到云厂商提供的虚拟化方案,目前主流的是 Linux kvm 方案。因此可以针对性的对 kvm 这个方案所所及到的技术点做特别分析。此处应该包含的统计包括:
qemu 线程的被抢占频率及时间、guest陷出频率及事件、qemu线程在host上运行的时间
通过这些来综合判断是否是由于虚拟化层带来的性能损失或者是否有改善的可能性。
4、硬件性能
最后,真正到了硬件层,到这里通常都是由于单纯从应用层或者系统层无法找到更多的优化空间了。其实又有两种思路,一种是看看硬件利用率的点,看能否反向调整应用,对硬件使用的热点减少依赖或者分散利用;另一种就是应用无法调整了,评估硬件的性能是否真正已到瓶颈。对于前者,又可以延伸出一套方法论来,比如 Ahmed Yasin 的TMAM,在 sysAK 中不做过多延伸,但仍然有必要的工作要做,除 cache、tlb miss、cpi 这些数据采集外,更关键的是怎么将这些数据结合应用进程的运行情况进行分析,比如同一 cpu 上的 cache 或带宽竞争多,是由于当前业务自身的程序设计,还是有其他进程存在争抢导致,对于争抢导致的可以通过绑核、rdt 等技术进行配合优化。
5、交互的应用环境
还没完,这里还少了一个拼图,现在绝大多数应用都不是单机的,交互的应用之间也会产生性能影响,因此在应用画像中,我们曾提到过网络连接的拓扑,就是用于此。我们可以将上述所有的性能诊断方法在和当前应用进行交互的对象上复制一遍。
总结
最后的最后,以一张大图来进行总结。
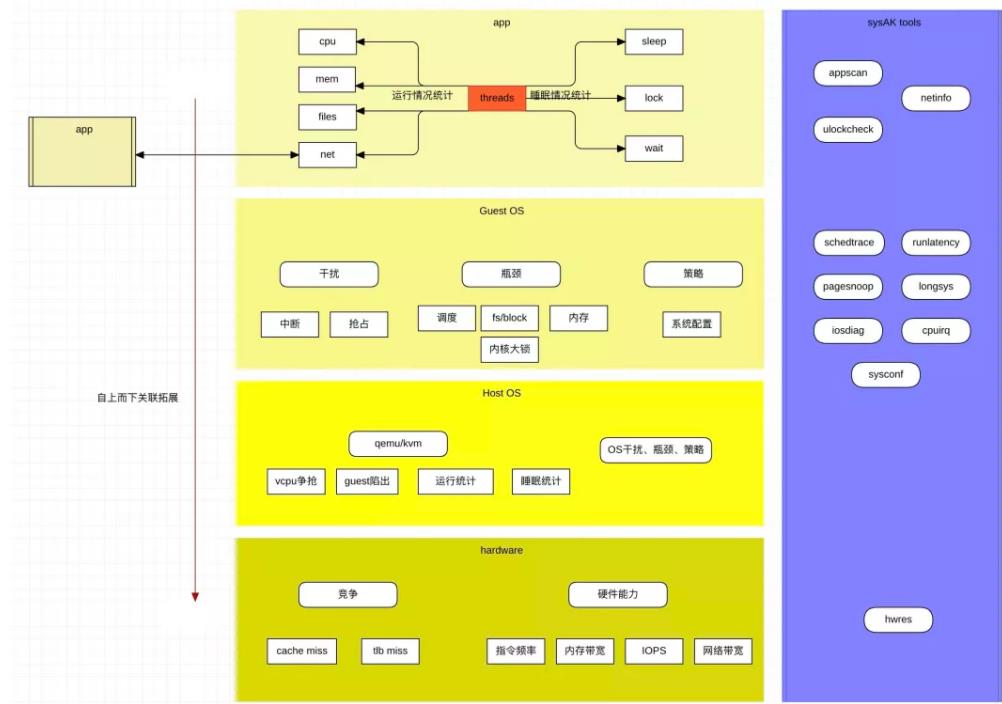
而图中涉及的工具将会在后续的实战篇中出现,敬请期待。
本文为阿里云原创内容,未经允许不得转载。
以上是关于龙蜥利器:系统运维工具 SysAK的云上应用性能诊断 | 龙蜥技术的主要内容,如果未能解决你的问题,请参考以下文章
SysAK 应用抖动诊断篇—— eBPF又立功了 | 龙蜥技术
直播回顾:如何对付臭名昭著的 IO 夯?诊断利器来了 | 龙蜥技术