python 代码跳动之美
Posted 我只会一点点代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 代码跳动之美相关的知识,希望对你有一定的参考价值。
python 代码跳动之美
1、先上效果
python 【篮球教学】代码正在模仿中
python 【篮球教学】代码正在模仿中
2、运行环境
Python版本:Python3.7(Python3.5+应该都没有问题),推荐使用jupyter运行
2.1、依赖库:
- ①opencv-python(4.5.1.48)
- ②Pillow (7.0.0)
- ③moviepy(1.0.3)
2.2、安装方法
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python Pillow moviepy
2.3、导入环境
import shutil
import cv2
import os
from PIL import Image # PIL 是一个 Python 图像处理库
import PIL
import PIL.Image
import PIL.ImageFont
import PIL.ImageOps
import PIL.ImageDraw
import numpy as np
import glob
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.MAX_IMAGE_PIXELS = None
from moviepy.editor import *
3、目录结构图
- D盘
- video 目录
- tmp 目录 — 存放一开始分解成帧的图片
- txt 目录 — 存放由tmp目录转化得到的txt文件
- tmp_final目录 — 存放由txt目录转化所得到的图片并进行规格化处理
- first.mp4 — 这是需要处理的原视频
- middle.mp4 — 这是处理后自动生成的中间视频
- final.mp4 — 将原视频与中间视频按左右的位置拼接在一起
- final_with_voice.mp4 — 加入原声,得到最终的视频
- video 目录
4、处理步骤详情图

5、代码实现
5.1、创建临时目录
第一步:事先创建好临时目录,方便存放文件。
- D:\\videos\\tmp\\(一开始视频按照帧率分解的图片存放的目录)
- D:\\videos\\txt\\(然后每一帧图片转化为txt存放的目录)
- D:\\videos\\tmp_final(将txt转化为需要的图片存放的目录)
def create_path_before_start(path1,path2,path3):
# 检查存放每一帧的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path1):
os.makedirs(path1)
# 检查每一帧对应的txt所在的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path2):
os.makedirs(path2)
# 检查每一个处理后的txt对应的每一帧图片的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path3):
os.makedirs(path3)
例如:
create_path_before_start('D:\\\\videos\\\\tmp\\\\','D:\\\\videos\\\\txt\\\\','D:\\\\videos\\\\tmp_final\\\\')
执行成功后可以看到目录已经提前创建好了。

5.2、将目标视频分解为若干图片
执行代码之前,先把目标视频放到D盘的video目录:

第二步:将目标视频first.mp4分解为若干图片,并存到tmp目录中。在这里我没有重新自定义帧率,都是按照默认的30来处理。
def deal_with_video_to_frame(path1,path2):
cap = cv2.VideoCapture(path1) # 目标视频位置
# 原视频的帧率
fps = int(cap.get(5))
# 原视频的总帧数
frame_count = int(cap.get(7))
c=0
while(1):
success, frame = cap.read()
if success:
img = cv2.imwrite(path2+str(c) + '.png',frame) # 拆解后每一帧图片存放的位置,这里我以编号0,1,2.....为命名
c=c+1
else:
break
cap.release()
return fps,frame_count
fps,frame_count = deal_with_video_to_frame('D:\\\\videos\\\\first.mp4', 'D:\\\\videos\\\\tmp\\\\')
执行成功后,输出fps,frame_count看看:
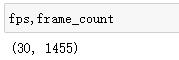
可以看到视频已经按照帧率30分解为1455张图片了。

5.3、将图片转化字符集形式的txt
第三步:把tmp目录中的1455张图片合成txt,每一张图片都有一个对应的txt文件
def deal_with_frame_to_txt(path1,path2,num):
# 是我们的字符画所使用的字符集,一共有 72 个字符,字符的种类与数量可以自己根据字符画的效果反复调试的
#ascii_char = list("01")
ascii_char = list("01B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\\|()1[]?-_+~<>i!lI;:oa+>!:+. ")
WH = Image.open(path1+"0.png")#返回一个Image对象
WIDTH = int(WH.size[0]/10) # 字符画的宽,txt占多少列
HEIGHT = int(WH.size[1]/10) # 字符画的高,txt占多少行
WH.close()
def get_char(r, g, b, alpha=256): # alpha透明度
if alpha == 0:
return ' '
length = len(ascii_char)
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b) # 计算灰度
unit = (256.0 + 1) / length
return ascii_char[int(gray / unit)] # 不同的灰度对应着不同的字符
# 通过灰度来区分色块
# 将256灰度映射到2个字符上,也就是RGB值转字符的函数:
def get_char_photo(path3,path4):
im = Image.open(path3)
im = im.resize((WIDTH, HEIGHT), Image.NEAREST)
txt = ""
for i in range(HEIGHT):
for j in range(WIDTH):
txt += get_char(*im.getpixel((j, i))) + ' ' # 获得相应的字符
txt += '\\n'
#print(txt) # 打印出字符画
# 将字符画 写入文件中
with open(path4, 'w') as f:
f.write(txt)
for i in range(num):
get_char_photo(path1+'.png'.format(i), path2+'.txt'.format(i))
deal_with_frame_to_txt('D:\\\\videos\\\\tmp\\\\', 'D:\\\\videos\\\\txt\\\\',frame_count)
执行成功后,可以看到,txt目录中生成了1455个txt,每一个都对应着tmp目录中的图片:

5.4、txt转字符编码式图片
第四步:将txt目录中的1455个txt文件转化为1455张图片。
def deal_with_txt_to_frame(path1,path2,num):
PIXEL_ON = 0 # PIL color to use for "on"
PIXEL_OFF = 255 # PIL color to use for "off"
def text_image(text_path, font_path=None):
"""Convert text file to a grayscale image with black characters on a white background.
arguments:
text_path - the content of this file will be converted to an image
font_path - path to a font file (for example impact.ttf)
"""
grayscale = 'L'
# parse the file into lines
with open(text_path) as text_file: # can throw FileNotFoundError
lines = tuple(l.rstrip() for l in text_file.readlines())
# choose a font (you can see more detail in my library on github)
large_font = 20 # get better resolution with larger size
font_path = font_path or 'cour.ttf' # Courier New. works in windows. linux may need more explicit path
try:
font = PIL.ImageFont.truetype(font_path, size=large_font)
except IOError:
font = PIL.ImageFont.load_default()
#print('Could not use chosen font. Using default.')
# make the background image based on the combination of font and lines
pt2px = lambda pt: int(round(pt * 96.0 / 72)) # convert points to pixels
max_width_line = max(lines, key=lambda s: font.getsize(s)[0])
# max height is adjusted down because it's too large visually for spacing
test_string = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
max_height = pt2px(font.getsize(test_string)[1])
max_width = pt2px(font.getsize(max_width_line)[0])
height = max_height * len(lines) # perfect or a little oversized
width = int(round(max_width + 40)) # a little oversized
image = PIL.Image.new(grayscale, (width, height), color=PIXEL_OFF)
draw = PIL.ImageDraw.Draw(image)
# draw each line of text
vertical_position = 5
horizontal_position = 5
line_spacing = int(round(max_height * 0.8)) # reduced spacing seems better
for line in lines:
draw.text((horizontal_position, vertical_position),
line, fill=PIXEL_ON, font=font)
vertical_position += line_spacing
# crop the text
c_box = PIL.ImageOps.invert(image).getbbox()
image = image.crop(c_box)
return image
for i in range(num):
image = text_image(path1+'.txt'.format(i))
#image.show()
image.save(path2+'.png'.format(i))
deal_with_txt_to_frame('D:\\\\videos\\\\txt\\\\', 'D:\\\\videos\\\\tmp_final\\\\',frame_count)
执行成功后,可以看到tmp_final目录中生成了1455张字符编码式的图片了。
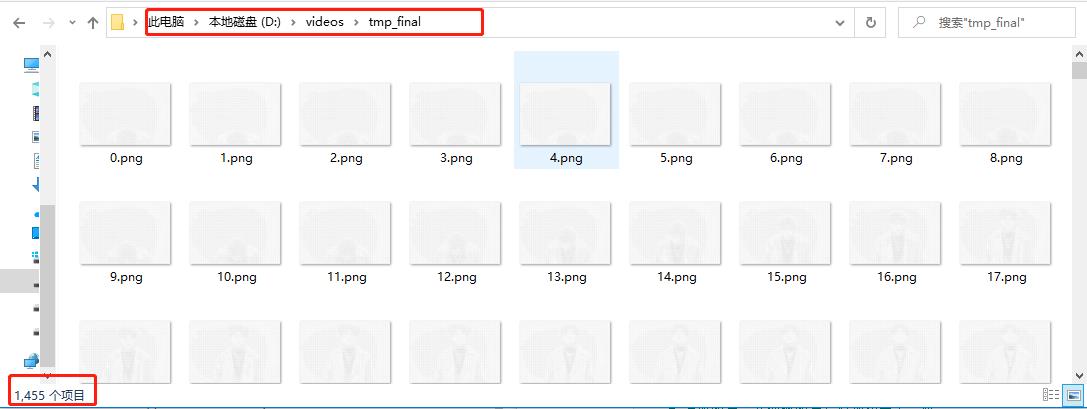
5.5、字符编码式图片按规格化处理
第五步:将字符编码式图片按规格化处理。因为在moviepy模块中,将视频按照图片的方式导出mp4格式,是需要每一张图片的分辨率都是一致的。因为我在5.3的时候图片转txt的过程加了空行,所以在5.4的时候txt重新转回图片的分辨率会大于原视频。而且我们在后面因为需要和原视频拼接在一起,所以就按照原视频的分辨率压缩为一致了。
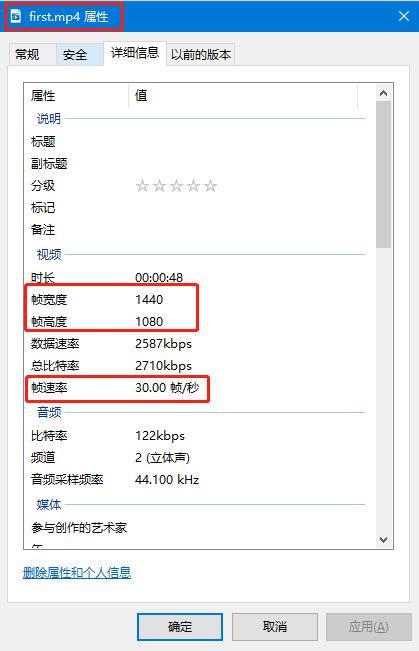
举个例子,现在tmp_final的图片分辨率为3442×2363,5.5的代码就是为了将其等比例压缩为原视频的分辨率1440×1080。

def deal_with_the_same_size(path1,path2,num):
# 获取原视频的分辨率
cap = cv2.VideoCapture(path1) # 目标视频位置
WIDTH = int(cap.get(3))
HEIGHT = int(cap.get(4))
if WIDTH%2==1:
WIDTH = WIDTH-1
if HEIGHT%2==1:
HEIGHT = HEIGHT -1
cap.release()
# 读取图片,并调整图片与原视频大小一致
for i in range(num):
img = cv2.imread(path2+".png".format(i))
final_img = cv2.resize(img,(WIDTH,HEIGHT))
cv2.imwrite(path2+".png".format(i), final_img)
cv2.destroyAllWindows()
def deal_with_the_same_size(path1,path2,num):
# 获取原视频的分辨率
cap = cv2.VideoCapture(path1) # 目标视频位置
WIDTH = int(cap.get(3))
HEIGHT = int(cap.get(4))
if WIDTH%2==1:
WIDTH = WIDTH-1
if HEIGHT%2==1:
HEIGHT = HEIGHT -1
cap.release()
# 读取图片,并调整图片与原视频大小一致
for i in range(num):
img = cv2.imread(path2+".png".format(i))
final_img = cv2.resize(img,(WIDTH,HEIGHT))
cv2.imwrite(path2+".png".format(i), final_img)
cv2.destroyAllWindows()
deal_with_the_same_size('D:\\\\videos\\\\first.mp4', 'D:\\\\videos\\\\tmp_final\\\\',frame_count)
运行成功后,可以看到,tmp_final的所有图片的分辨率都已经压缩为1440×1080了。

5.6、合成视频并与原视频拼接
第六步,将tmp_final中的图片按照原视频的帧率30重新合成为视频,然后与原视频进行拼接。
def generate_video(path1,file1,file2,file3,frame):
#读取一张图片的长宽
WH = Image.open(path1+"0.png")#返回一个Image对象
WIDTH = WH.size[0] # 字符画的宽,txt占多少列
HEIGHT = WH.size[1] # 字符画的高,txt占多少行
WH.close()
size = (WIDTH, HEIGHT)
# 获取有多少张图片
list_file_name = glob.glob(os.path.join(path1,"*.png"))
num = len(list_file_name)
#完成写入对象的创建,第一个参数是合成之后的视频的名称,第二个参数是可以使用的编码器,第三个参数是帧率即每秒钟展示多少张图片,第四个参数是图片大小信息
videowrite = cv2.VideoWriter(file1,-1,frame,size)
#img_array=[]
for filename in [path1+'.png'.format(i) for i in range(num)]:
img = cv2.imread(filename)
if img is None:
print(filename + " is error!")
continue
videowrite.write(img)
videowrite.release()
clip1 = VideoFileClip(file2)
clip2 = VideoFileClip(file1)
final_clip = clips_array([[clip1,clip2]])
final_clip.write_videofile(file3)
generate_video('D:\\\\videos\\\\tmp_final\\\\','D:\\\\videos\\\\target.mp4','D:\\\\videos\\\\first.mp4','D:\\\\videos\\\\final.mp4',fps)
执行成功后,可以看到,字符编码式的中间视频target.mp4以及拼接后的视频final.mp4已经生成了,只是现在还没有声音。

5.7、给拼接的视频导入声音
第七步:给拼接好的视频导入原声。
def get_voice_and_load(file1,file2,file3):
# 获取原视频的声音
video = VideoFileClip(file1)
audio = video.audio
# 将原声导入处理后的视频
video = VideoFileClip(file2)
final_video = video.set_audio(audio)
final_video.write_videofile(file3,fps=video.fps,codec='libx264')
video.close()
get_voice_and_load('D:\\\\videos\\\\first.mp4','D:\\\\videos\\\\final.mp4','D:\\\\videos\\\\final_with_voice.mp4')
运行成功后,就可以得到最终我们想要的视频final_with_voice.mp4了。

5.8、删除临时目录与中间文件
最后一步:把tmp,txt和tmp_final这三个临时目录及其产生的中间文件删除。
def delete_cache_dir(path1,path2,path3):
# 检查存放每一帧的存放目录是否存在,存在则递归删除
if os.path.exists(path1):
shutil.rmtree(path1)
# 检查每一帧对应的txt所在的存放目录是否存在,存在则递归删除
if os.path.exists(path2):
shutil.rmtree(path2)
# 检查每一个处理后的txt对应的每一帧图片的存放目录是否存在,存在则递归删除
if os.path.exists(path3):
shutil.rmtree(path3)
delete_cache_dir('D:\\\\videos\\\\tmp\\\\', 'D:\\\\videos\\\\txt\\\\', 'D:\\\\videos\\\\tmp_final\\\\')
运行成功之后,可以看到这三个目录及其文件全删了:
6、全部代码(供参考)
import shutil
import cv2
import os
from PIL import Image # PIL 是一个 Python 图像处理库
import PIL
import PIL.Image
import PIL.ImageFont
import PIL.ImageOps
import PIL.ImageDraw
import numpy as np
import glob
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
Image.MAX_IMAGE_PIXELS = None
from moviepy.editor import *
def create_path_before_start(path1,path2,path3):
# 检查存放每一帧的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path1):
os.makedirs(path1)
# 检查每一帧对应的txt所在的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path2):
os.makedirs(path2)
# 检查每一个处理后的txt对应的每一帧图片的存放目录是否存在,不存在则提前创建好
if not os.path.exists(path3):
os.makedirs(path3)
def deal_with_video_to_frame(path1,path2):
cap = cv2.VideoCapture(path1) # 目标视频位置
# 原视频的帧率
fps = int(cap.get(5))
# 原视频的总帧数
frame_count = int(cap.get(7))
c=0
while(1):
success, frame = cap.read()
if success:
img = cv2.imwrite(path2+str(c) + '.png',frame) # 拆解后每一帧图片存放的位置,这里我以编号0,1,2.....为命名
c=c+1
else:
break
cap.release()
return fps,frame_count
def deal_with_frame_to_txt(path1,path2,num):
# 是我们的字符画所使用的字符集,一共有 72 个字符,字符的种类与数量可以自己根据字符画的效果反复调试的
#ascii_char = list("01")
ascii_char = list("01B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\\|()1[]?-_+~<>i!lI;:oa+>!:+. ")
WH = Image.open(path1+"0.png")#返回一个Image对象
WIDTH = int(WH.size[0]/10) # 字符画的宽,txt占多少列
HEIGHT = int(WH.size[1]/10) # 字符画的高,txt占多少行
WH.close()
def get_char(r, g, b, alpha=256): # alpha透明度
if alpha == 0:
return ' '
length = len(ascii_char)
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b) # 计算灰度
unit = (256.0 + 1) / length
return ascii_char[int(gray / unit)] # 不同的灰度对应着不同的字符
# 通过灰度来区分色块
# 将256灰度映射到2个字符上,也就是RGB值转字符的函数:
def get_char_photo(path3,path4):
im = Image.open(path3)
im = im.resize((WIDTH, HEIGHT), Image.NEAREST)
txt = ""
for i in range(HEIGHT):
for j in range(WIDTH):
txt += get_char(*im.getpixel((j, i))) + ' ' # 获得相应的字符
txt += '\\n'
#print(txt) # 打印出字符画
# 将字符画 写入文件中
with open(path4, 'w') as f:
f.write(txt)
for i in range(num):
get_char_photo(path1+'.png'.format(i), path2+'.txt'.format(i))
def deal_with_txt_to_frame(path1,path2,num):
PIXEL_ON = 0 # PIL color to use for "on"
PIXEL_OFF = 255 # PIL color to use for "off"
def text_image(text_path, font_path=None):
"""Convert text file to a grayscale image with black characters on a white background.
arguments:
text_path - the content of this file will be converted to an image
font_path - path to a font file (for example impact.ttf)
"""
grayscale = 'L'
# parse the file into lines
with open(text_path) as text_file: # can throw FileNotFoundError
lines = tuple(l.rstrip() for l in text_file.readlines())
# choose a font (you can see more detail in my library on github)
large_font = 20 # get better resolution with larger size
font_path = font_path or 'cour.ttf' # Courier New. works in windows. linux may need more explicit path
try:
font = PIL.ImageFont.truetype(font_path, size=large_font)
except IOError:
font = PIL.ImageFont.load_default()
#print('Could not use chosen font. Using default.')
# make the background image based on the combination of font and lines
pt2px = lambda pt: int(round(pt * 96.0 / 72)) # convert points to pixels
max_width_line = max(lines, key=lambda s: font.getsize(s)[0])
# max height is adjusted down because it's too large visually for spacing
test_string = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
max_height = pt2px(font.getsize(test_string)[1])
max_width = pt2px(font.getsize(max_width_line)[0])
height = max_height * len(lines) # perfect or a little oversized
width = int(round(max_width + 40)) # a little oversized
image = PIL.Image.new(grayscale, (width, height), color=PIXEL_OFF)
draw = PIL.ImageDraw.Draw(image)
# draw each line of text
vertical_position = 5
horizontal_position = 5
line_spacing = int(round(max_height * 0.8)) # reduced spacing seems better
for line in lines:
draw.text((horizontal_position, vertical_position),
line, fill=PIXEL_ON, font=font)
vertical_position += line_spacing
# crop the text
c_box = PIL.ImageOps.invert(image).getbbox()
image = image.crop(c_box)
return image
for i in range(num):
image = text_image(path1+'.txt'.format(i))
#image.show()
image.save(path2+'.png'.format(i))
def deal_with_the_same_size(path1,path2,num):
# 获取原视频的分辨率
cap = cv2.VideoCapture(path1) # 目标视频位置
WIDTH = int(cap.get(3))
HEIGHT = int(cap.get(4))
if WIDTH%2==1:
WIDTH = WIDTH-1
if HEIGHT%2==1:
HEIGHT = HEIGHT -1
cap.release()
# 读取图片,并调整图片与原视频大小一致
for i in range(num):
img = cv2.imread(path2+".png".format(i))
final_img = cv2.resize(img,(WIDTH,HEIGHT))
cv2.imwrite(path2+".png".format(i), final_img)
cv2.destroyAllWindows()
def generate_video(path1,file1,file2,file3,frame):
#读取一张图片的长宽
WH = Image.open(path1+"0.png")#返回一个Image对象
WIDTH = WH.size[0] # 字符画的宽,txt占多少列
HEIGHT = WH.size[1] # 字符画的高,txt占多少行
WH.close()
size = (WIDTH, HEIGHT)
# 获取有多少张图片
list_file_name = glob.glob(os.path.join(path1,"*.png"))
num = len(list_file_name)
#完成写入对象的创建,第一个参数是合成之后的视频的名称,第二个参数是可以使用的编码器,第三个参数是帧率即每秒钟展示多少张图片,第四个参数是图片大小信息
videowrite = cv2.VideoWriter(file1,-1,frame,size)
#img_array=[]
for filename in [path1+'.png'.format(i) for i in range(num)]:
img = cv2.imread(filename)
if img is None:
print(filename + " is error!")
continue
videowrite.write(img)
videowrite.release()
clip1 = VideoFileClip(file2)
clip2 = VideoFileClip(file1)
final_clip = clips_array([[clip1,clip2]])
final_clip.write_videofile(file3)
def get_voice_and_load(file1,file2,file3):
# 获取原视频的声音
video1 = VideoFileClip(file1)
audio = video1.audio
# 将原声导入处理后的视频
video2 = VideoFileClip(file2)
final_video = video2.set_audio(audio)
final_video.write_videofile(file3,fps=video2.fps,codec='libx264')
video1.close()
video2.close()
def delete_cache_dir(path1,path2,path3):
# 检查存放每一帧的存放目录是否存在,存在则递归删除
if os.path.exists(path1):
shutil.rmtree(path1)
# 检查每一帧对应的txt所在的存放目录是否存在,存在则递归删除
if os.path.exists(path2):
shutil.rmtree(path2)
# 检查每一个处理后的txt对应的每一帧图片的存放目录是否存在,存在则递归删除
if os.path.exists(path3):
shutil.rmtree(path3)
if __name__ == '__main__':
# 一开始视频按照帧率分解的图片存放的目录
fisrt_frame_save_path = 'D:\\\\videos\\\\tmp\\\\'
# 然后每一帧图片转化为txt存放的目录
txt_save_path = 'D:\\\\videos\\\\txt\\\\'
# 将txt转化为需要的图片存放的目录
after_process_save_path = 'D:\\\\videos\\\\tmp_final\\\\'
# 原视频的绝对路径,这个路径为你需要转化的原视频
video_path = "D:\\\\videos\\\\first.mp4"
# 合成后的视频的绝对路径,由自己自由定义
target_video = 'D:\\\\videos\\\\target.mp4'
# 导入声音后的最终视频
final_video = 'D:\\\\videos\\\\final.mp4'
final_video_with_voice = 'D:\\\\videos\\\\final_with_voice.mp4'
# 第一步:提前把需要的目录创建好
create_path_before_start(fisrt_frame_save_path,txt_save_path,after_process_save_path)
# 第二步:导出视频的每一帧
fps,frame_count = deal_with_video_to_frame(video_path,fisrt_frame_save_path)
# 第三步:将每一帧的图片转化为一个个的txt文件
deal_with_frame_to_txt(fisrt_frame_save_path,txt_save_path,frame_count)
# 第四步:将txt文件转化为字符编码式的图片
deal_with_txt_to_frame(txt_save_path,after_process_save_path,frame_count)
# 第五步:将字符编码式的图片剪切为统一尺寸的图片
deal_with_the_same_size(video_path,after_process_save_path,frame_count)
# 第六步:将每一帧处理后的图片重新合成为视频
generate_video(after_process_save_path,target_video,video_path,final_video,fps)
# 第七步:给视频导入原声
get_voice_and_load(video_path,final_video,final_video_with_voice)
# 第八步:将产生的中间文件删除
delete_cache_dir(fisrt_frame_save_path,txt_save_path,after_process_save_path)
在运行整体代码之前,需要在D:\\videos\\目录先放置自己的目标视频,例如本文中的first.mp4。或者在main函数中自定义目录和文件的绝对路径。其他函数都已经写好了,可以直接调用。建议拿个几秒的视频测试,理解一下流程。一分钟以上的视频,跑一遍一般要半个小时。当然,只是对于我的电脑而言。

PS 好了,今天的分享就到此为止。
分享不易,运行成功的兄弟记得回来点个赞,评论区扣个1打卡再走。

以上是关于python 代码跳动之美的主要内容,如果未能解决你的问题,请参考以下文章