对于七段数码数字模型进行改进:一个关键的数字1的问题
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对于七段数码数字模型进行改进:一个关键的数字1的问题相关的知识,希望对你有一定的参考价值。
简 介: 对于训练集合进行扩增,需要根据图片本身在应用中可能遇到的变化进行。对于图片中的数码管数字识别,一个最重要的问题是字符的平移,特别是对于字符1来说,遇到的可能性最大。比如在一些三位半,四位半的数字表中,最前面的数字可能只有1,0两个数字,所以分割过程中,1的位置有可能位于图片的最左。针对这种情况,对于训练数据集合进行平移扩充,通过测试结果可以看出,模型的精度得到了提高。
关键词: 数码管,LENET,CNN,数据增强
§01 数字1的问题
1.1 问题来源
在 一个中等规模的七段数码数据库以及利用它训练的识别网络 中,利用了近200张网络数码图片训练出LeNet网络,可以达到了很好的数字(LCD,LED七段数字)识别的效果,网络的适应性比较强。但是在 测试LCDNet对于万用表读数识别效果 测试中,对于如下的图片识别的结果出现了问题:
下面的图片被识别成“07729”

▲ 图1.1 图片内容被识别成07729
问题出现在对于字符分割的问题上,明显,对于最左侧的“1”,实际上它的左侧部分被切割出去了。因此,将上述图片按照5等分,所获得到的图片如下。如果注视到这个分割结果,对于第一个字符应该说,还是分割的不错的。主要原因是“1”所在的位置偏向中心。

▲ 图1.1.2 图片分为5等分对应的图片
为了验证这个问题,对原来图片左侧进行填补背景颜色,对应的图片如下。

▲ 图1.1.3 对原来图片左侧进行填补背景之后的图片
然后再进行五等分,对应的图片为:

▲ 图1.1.4 补充分割之后的图片
在这种情况下,所获得的识别结果就正确了。
这说明在原来训练模型中,对于“1”这个字符,更多的样本对应“1”它是在图片的左侧,而不是在中间或者右边。
1.2 如何解决?
上面的这种情况对于数字“1”比较特殊,一种简单的解决方案,就是直接对于样本中所有的“1”的样本,都进行左右平移的扩充,使得模型对于“1”的左右位置不敏感。

▲ 图1.2.1 将1图片左右平移
plt.figure(figsize=(10, 5))
n = inp[0][0]
x = list(range(0, 24, 4))
print(type(n), shape(n), x)
for id,xx in enumerate(x):
mm = roll(n, xx)
plt.subplot(1, len(x), id+1)
plt.imshow(mm)
§02 重新训练
2.1 准备数据集合
2.1.1 数据集合进行合并
现在已经有了四个7段数字图片集合,将它们合并在一起。
- 输入数字目录:7seg, testlcd, testled, testseg7
- 输出数字目录:seg7all
最终获得数字图片:303个
from headm import * # =
import shutil
inputdir = ['7Seg', 'testlcd', 'testled', 'testseg7']
outdir = '/home/aistudio/work/7seg/seg7all'
count = 0
for d in inputdir:
dstr = '/home/aistudio/work/7seg/' + d
fdir = os.listdir(dstr)
for f in fdir:
ext = f.split('.')[-1].upper()
if ext.find('JPG') < 0 and ext.find('BMP') < 0: continue
numstr = f.split('.')[0].split('-')[-1]
outfn = '%03d-%s.%s'%(count, numstr, ext)
outfn = os.path.join(outdir, outfn)
count += 1
shutil.copyfile(os.path.join(dstr, f), outfn)
printt(count)
2.1.2 分解图片中的数字
对前面准备好的数字图片分割相应的数字。
(1)分割代码
from headm import * # =
import cv2
from tqdm import tqdm
picdir = '/home/aistudio/work/7seg/seg7all'
filedim = [s for s in os.listdir(picdir) if s.upper().find('BMP') > 0 or s.upper().find('JPG') > 0]
filedim = sorted(filedim)
outdir = '/home/aistudio/work/7seg/pic48'
totalpic = 0
OUT_SIZE = 48
for f in tqdm(filedim):
fn = os.path.join(picdir, f)
img = cv2.imread(fn)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgwidth = gray.shape[1]
imgheight = gray.shape[0]
numstr = f.split('.')[0].split('-')[1]
numnum = len(numstr)
for i in range(numnum):
left = imgwidth * i // numnum
right = imgwidth * (i + 1) // numnum
data = gray[0:imgheight, left:right]
dataout = cv2.resize(data, (OUT_SIZE, OUT_SIZE))
outfn = os.path.join(outdir, '%04d_%s.BMP'%(totalpic, numstr[i]))
totalpic += 1
cv2.imwrite(outfn, dataout)
newheight = int(imgheight * 0.85)
newwidth = int((right-left)*0.85)
deltaheight = (imgheight- newheight)//2
deltawidth = (right-left-newwidth)//2
data = gray[deltaheight:imgheight-deltaheight, left:right]
dataout = cv2.resize(data, (OUT_SIZE, OUT_SIZE))
outfn = os.path.join(outdir, '%04d_%s.BMP'%(totalpic, numstr[i]))
totalpic += 1
cv2.imwrite(outfn, dataout)
data = gray[0:imgheight, left+deltawidth:right-deltawidth]
dataout = cv2.resize(data, (OUT_SIZE, OUT_SIZE))
outfn = os.path.join(outdir, '%04d_%s.BMP'%(totalpic, numstr[i]))
totalpic += 1
cv2.imwrite(outfn, dataout)
data = gray[deltaheight:imgheight-deltaheight, left+deltawidth:right-deltawidth]
dataout = cv2.resize(data, (OUT_SIZE, OUT_SIZE))
outfn = os.path.join(outdir, '%04d_%s.BMP'%(totalpic, numstr[i]))
totalpic += 1
cv2.imwrite(outfn, dataout)
printt(totalpic:)
分割完毕之后,每个数字对应四个数字,分别是原来数字,上下左右膨胀1.17倍的图片。图片总数为: 5340。
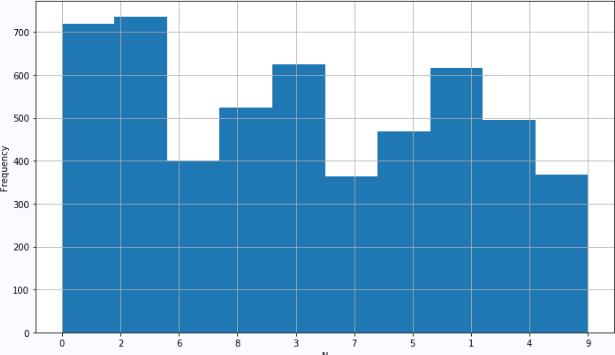
▲ 图2.1.1 十个数字的不同频次分布
2.1.3 数字清洗与1平移
下面对于分割出的数字进行清洗,其中包含有“N”背景颜色的数字。另外,对于所有为“1”的数字往右平移倍增。
if num == 1:
img = cv2.imread(infn)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray1 = roll(gray, -12)
gray2 = roll(gray, -24)
gray3 = roll(gray, -36)以上是关于对于七段数码数字模型进行改进:一个关键的数字1的问题的主要内容,如果未能解决你的问题,请参考以下文章