每日一练(day02 手撕 KMP)
Posted 'or 1 or 不正经の泡泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一练(day02 手撕 KMP)相关的知识,希望对你有一定的参考价值。
前言
今天也就做了五题,本来是想要多做一点的,但是有个小bug调了半天,好烦(真就是想得行云流水,结果写的代码到处报错,没有仔细思考情况,太着急了)
题目
删除有序数组中的重复项
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for
(int i = 0; i < len; i++)
print(nums[i]); 示例 1:输入:nums = [1,1,2] 输出:2, nums = [1,2] 解释:函数应该返回新的长度 2 ,并且原数组 nums
的前两个元素被修改为 1, 2 。 不需要考虑数组中超出新长度后面的元素。 示例 2:输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度
5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。
这个题目比较简单,我们搞两个指针就好了,我们的目的是把没有重复的元素放到前面来。这里说几个需要被注意的点
如果数组长度为0或者1我们直接返回即可,可以从第二个元素开始判断,也就是数组下标1开始,并且快指针也是要比较前面的那个元素,所以也应该从1开始
class Solution
public int removeDuplicates(int[] nums)
int n = nums.length;
if (n == 0)
return 0;
int fast = 1, slow = 1;
while (fast < n)
if (nums[fast] != nums[fast - 1])
nums[slow] = nums[fast];
++slow;
++fast;
return slow;
原理的就这样,一个快指针负责扫描后面的数字有没有重复,另一个把前面的进行替换。
移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for
(int i = 0; i < len; i++)
print(nums[i]); 示例 1:输入:nums = [3,2,2,3], val = 3 输出:2, nums = [2,2] 解释:函数应该返回新的长度 2, 并且
nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums =
[2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。 示例 2:输入:nums = [0,1,2,2,3,0,4,2], val = 2 输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0
这个和上一题的思路基本上一样,反而更简单
class Solution
public int removeElement(int[] nums, int val)
int n = nums.length;
if (n == 0)
return 0;
int fast = 0, slow = 0;
while (fast < n)
if(nums[fast] != val)
nums[slow] = nums[fast];
slow++;
++fast;
return slow;
字符串匹配问题
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从
0 开始)。如果不存在,则返回 -1 。说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf()
定义相符。示例 1:
输入:haystack = “hello”, needle = “ll” 输出:2 示例 2:
输入:haystack = “aaaaa”, needle = “bba” 输出:-1 示例 3:
输入:haystack = “”, needle = “” 输出:0
这个就是我们数据结构学的时候最经典的那个串的问题嘛
同样这里有两个方法,一个是暴力匹配。还有一个是KMP算法。
第一种:
class Solution
public int strStr(String haystack, String needle)
//先来最简单的暴力算法
int length_world = haystack.length();
int length_needle = needle.length();
for(int i=0;i+length_needle<=length_world;i++)
boolean flag = true;
for(int j = 0;j<length_needle;j++)
if (haystack.charAt(i + j) != needle.charAt(j))
flag = false;
break;
if(flag)
return i;
return -1;
第二种:
这个第二种比较复杂的就是那个如何去生成 next 数组,只要有那个next数组,那么接下来就好办了,所以代码难度最大的不好理解的地方应该就是那个求 next 数组的问题,然后用这个next 数组去匹配。那我这里也简单说一下 KMP 算法的实现思路吧,接下来是考验我语文的时候了。
KMP 算法思路
next 数组求解(前缀表)
嗯,先假设哈,能够看到这里的小伙伴一定是,看了数据结构的KMP 算法,但是对于 具体的求解或者代码求解不熟悉的小伙伴,如果你会,那直接跳过,这个就只是我那个刷题目的记录,做个小总结嘛。如果你连KMP是啥都不知道,那确实不适合,我这个是属于实战总结,不是那种手把手教程(那个虚幻四的应该算是手把手教程)
下面是关于next 数组的定义,和概念。
前缀:包含首位字符但不包含末位字符的子串。
后缀:包含末位字符但不包含首位字符的子串。
next数组定义:当主串与模式串的某一位字符不匹配时,模式串要回退的位置。
但是这里面存放的内容可能不一样,有些是按照王道考研里面的内容存放的东西(包括我学校老师将的应该也是这种(暴露了我没听课))但是的还有个东西叫做前缀表,见下图,有说明。
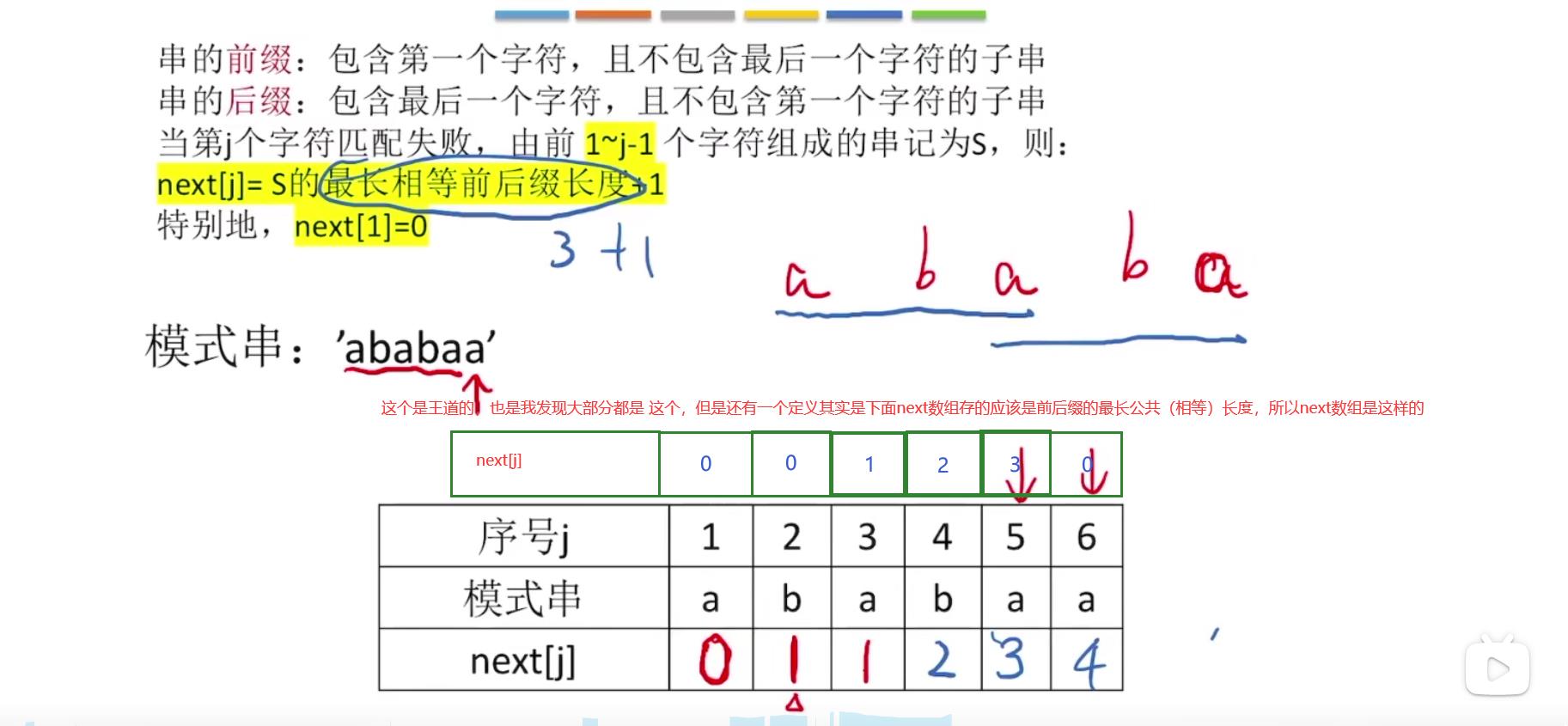
这个绿色部分的就是,而且我这边用的,这个叫做前缀表,那个next 数组里面放的其实是这个前缀表变换了的,具体为什么这样搞,其实应该是为了方便后面的比较。
首先我们明白一点,就是出了冲突我们是往前那一位对应的next的值所对应的在字符串当中的位置进行进行比较的。举个例子:
假设next 数组的值为 [0,1,2,1,3]
我假设下标是从1开始 1 2 3 4 5
现在第四个位置有冲突 next 对应的 值为 1 前一个对应的值为2
所以我们应该在字符串当中 找下标为 2 的字符去比较,然后看看有没有冲突,如果还有再重复
这个时候我们构造next 算法 其实和我们后面真正对比的代码的算法其实真的很像
如果没有冲突 那么就好办了,我们两个指针 j i (j 表示的是前缀的末尾的位置,由于特性,其实这个j 同时也是当前的那个元素(到i)的next 数组存放的前后缀最长公共部分的长度!!!,所以你看后面那个代码直接把next把next[i]=j,那么i表示的就是当前位置(也就是前缀位置))
所以重点有两个
第一:遇到冲突,也就是发现不匹配找到当前j 的前一个 next 数组的值并把j 移动到那个值对应的位置然后对比那个位置的字符和i所指向的有木有冲突
第二:j 表示的前缀的末尾位置(所以每一轮要++)同时也表示了当前(0 到 i)的前后缀的最长相同的长度
使用next 数组
这个使用就没啥好说的了,其实如果next数组搞定了,怎么用还不一样吗,只是我们把匹配冲突的对象变成了两个字符串,而不是一个。同时为了保证输出我们对下标进行换算也就是结果+1.
完整代码如下(如果没搞清楚的话,评论区留个言,我看看能不能直接做个新手教程):
class Solution
public int strStr(String haystack, String needle)
int n = haystack.length(), m = needle.length();
if (m == 0)
return 0;
int[] next = new int[m];
for (int i = 1, j = 0; i < m; i++)
while (j > 0 && needle.charAt(i) != needle.charAt(j))
j = next[j - 1]; // 有冲突回到前一位,然后对比那个所对应的下标为j的字符对不对得到
if (needle.charAt(i) == needle.charAt(j))
//对得到往前挪
j++;
next[i] = j;
for (int i = 0, j = 0; i < n; i++)
while (j > 0 && haystack.charAt(i) != needle.charAt(j))
j = next[j - 1];//有冲突
if (haystack.charAt(i) == needle.charAt(j))
j++;
if (j == m)
return i - m + 1;
return -1;
路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点
的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。叶子节点 是指没有子节点的节点。
示例 1:
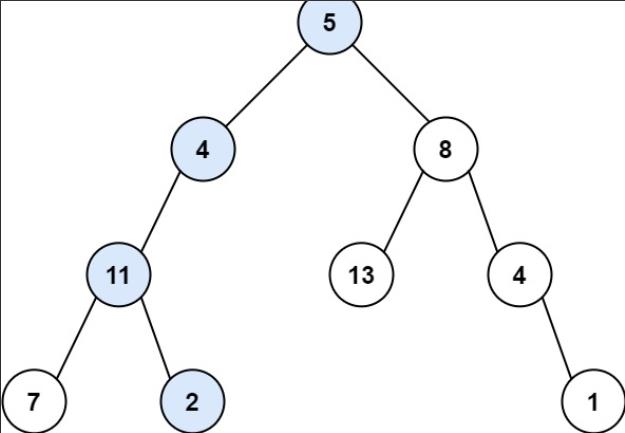
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true 解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:
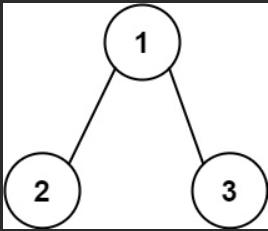
输入:root = [1,2,3], targetSum = 5 输出:false 解释:树中存在两条根节点到叶子节点的路径: (1 -->
2): 和为 3 (1 --> 3): 和为 4 不存在 sum = 5 的根节点到叶子节点的路径。
这个也没啥好说的,就那一套数的层次遍历嘛,搞个队列,是吧。
class Solution
public boolean hasPathSum(TreeNode root, int sum)
if (root == null)
return false;
Queue<TreeNode> queNode = new LinkedList<TreeNode>();
Queue<Integer> queVal = new LinkedList<Integer>();
queNode.offer(root);
queVal.offer(root.val);
while (!queNode.isEmpty())
TreeNode now = queNode.poll();
int temp = queVal.poll();
if (now.left == null && now.right == null)
if (temp == sum)
return true;
continue;
if (now.left != null)
queNode.offer(now.left);
queVal.offer(now.left.val + temp);
if (now.right != null)
queNode.offer(now.right);
queVal.offer(now.right.val + temp);
return false;
寻找两个中序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n)) 。
输入:nums1 = [0,0], nums2 = [0,0] 输出:0.00000
输入:nums1 = [], nums2 = [1] 输出:1.00000
输入:nums1 = [2], nums2 = [] 输出:2.00000
这个在那个力扣里面标的是困难题,但是,怎么说呢,简单方法能做,而且竟然好像还是效果最好的方式,内存消耗少,执行时间都是2ms
我看了看别写的,然后也试了试发现的。简单方法其实就是归并排序之后找中位数,只是带来了 O(m+n)的内存消耗,但是实际上我们可以搞个下标换算,也就是在两个数字里面分别排序,A数组第一元素是 归并后数组的第一个元素,B 的第一个 是归并后的 第二个,这样交错排序,那么我们实际上就不需要那个大数组放置元素,只需要换算我们的下标就可以了,但是我这里就偷个懒了。
这里要注意的就是那个合并后会剩下一些元素,这个要判断好
class Solution
public double findMedianSortedArrays(int[] nums1, int[] nums2)
int n = nums1.length;
int m = nums2.length;
int [] content = new int[n+m];
//先用双指针实现对 num1 和 num2的合并
int indexn = 0,indexm=0, content_index = 0;
double centnum = 0;
while (indexm<m && indexn<n)
if(nums1[indexn] < nums2[indexm])
content[content_index] = nums1[indexn];
content_index ++;
indexn ++;
else
content[content_index] = nums2[indexm];
content_index ++;
indexm ++;
if (indexn > indexm)
if(indexn < n)
setLast(content_index,m,n,indexn,content,nums1);
else
setLast(content_index,m,n,indexm,content,nums2);
else if(indexn == indexm)
if(n>m)
setLast(content_index,m,n,indexn,content,nums1);
else
setLast(content_index,m,n,indexm,content,nums2);
else
if(n<m)
if(indexm < m)
setLast(content_index,m,n,indexm,content,nums2);
else
setLast(content_index,m,n,indexn,content,nums1);
else
setLast(content_index,m,n,indexn,content,nums1);
if((m+n)%2 == 1)
centnum = content[(m+n)/2];
else
centnum = (content[((m+n)/2)] + content[((m+n)/2)-1])*1.0/2;
return centnum;
public void setLast(int content_index,int m,int n,int indexn,int[] content,int[] nums)
for (int i = content_index; i < m + n; i++)
content[i] = nums[indexn];
indexn++;
最后有啥问题,多交流(可惜以前没有好好刷letcode 报了蓝桥杯才开始,麻了,大一就得好好刷的)
以上是关于每日一练(day02 手撕 KMP)的主要内容,如果未能解决你的问题,请参考以下文章