Elasticsearch:图片相似度搜索的 5 个技术组成部分
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:图片相似度搜索的 5 个技术组成部分相关的知识,希望对你有一定的参考价值。
作者:Radovan Ondas,Bernhard Suhm

在本系列博文的第一部分中,我们介绍了图像相似度搜索,并回顾了一种可以降低复杂性并便于实施的高级架构。 此博客解释了实现图像相似性搜索应用程序所需的每个组件的基本概念和技术注意事项。 学习更多关于:
- 嵌入模型:机器学习模型生成应用向量搜索所需数据的数值表示
- 推理端点:用于将嵌入模型应用于 Elastic 中的数据的 API
- 矢量搜索:相似性搜索如何与最近邻搜索一起工作
- 生成图像嵌入:将数字表示的生成扩展到大型数据集
- 应用逻辑:交互前端如何与后端矢量搜索引擎通信
深入研究这五个组件,你可以了解如何在 Elastic 中应用矢量搜索来实现更直观的搜索体验。

1. 嵌入模型
要将相似性搜索应用于自然语言或图像数据,你需要机器学习模型将数据转换为其数值表示,也称为矢量嵌入。 在这个例子中:
- NLP “transformer” 模型将自然语言转化为矢量。
- OpenAI CLIP(对比语言 - 图像预训练)模型对图像进行矢量化。
Transformer 模型是经过训练以各种方式处理自然语言数据的机器学习模型,例如语言翻译、文本分类或命名实体识别。 他们接受了极大的带注释文本数据集的训练,以学习人类语言的模式和结构。
图像相似性应用程序根据文本、自然语言描述找到匹配的图像。 要实现这种相似性搜索,你需要一个在文本和图像上都经过训练并且可以将文本查询转换为矢量的模型。 然后可以使用它来查找相似图像。
详细了解如何在 Elasticsearch 中上传和使用 NLP 模型 >>
CLIP 是 OpenAI 开发的一种可以处理文本和图像的大规模语言模型。给定一小段文本作为输入,该模型被训练来预测图像的文本表示。 这涉及学习以允许模型做出准确预测的方式对齐图像的视觉和文本表示。
CLIP 的另一个重要方面是它是一个 “零样本” 模型,允许它执行没有经过专门训练的任务。 例如,它可以在训练期间从未见过的语言之间进行翻译,或者将图像分类到以前从未见过的类别中。 这使得 CLIP 成为一个非常灵活和通用的模型。
你将使用 CLIP 模型对你的图像进行矢量化处理,使用 Elastic 中的推理端点(如下所述)并对大量图像执行推理(如下文第 3 节所述)。
2. 推理端点
一旦将 NLP 模型加载到 Elasticsearch 中,你就可以处理实际的用户查询。 首先,你需要使用 Elasticsearch _infer 端点将查询文本转换为矢量。 该端点提供了一种在 Elastic 中原生使用 NLP 模型的内置方法,不需要查询外部服务,从而显着简化了实施。
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
"docs" : [
"text_field": "A mountain covered in snow"
]
3. 向量(相似度)搜索
在使用矢量嵌入对查询和文档进行索引后,相似文档是嵌入空间中查询的最近邻居。 实现该目标的一种流行算法是 k 最近邻 (kNN),它找到与查询向量最近的 k 个向量。 但是,对于你通常在图像搜索应用程序中处理的大型数据集,kNN 需要非常高的计算资源,并可能导致执行时间过长。 作为一种解决方案,近似最近邻 (ANN) 搜索牺牲了完美的准确性,以换取在高维嵌入空间中大规模高效执行。
在 Elastic 中,_search 端点支持精确和近似最近邻搜索。 使用下面的代码进行 kNN 搜索。 它假定 your-image-index 中所有图像的嵌入都在 image_embedding 字段中可用。 下一节将讨论如何创建嵌入。
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
"fields": [...],
"knn":
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
要了解有关 Elastic 中 kNN 的更多信息,请参阅我们的文档:k-nearest neighbor (kNN) search | Elasticsearch Guide [8.6] | Elastic.
4. 生成图像嵌入
上面提到的图像嵌入对于图像相似性搜索的良好性能至关重要。 它们应该存储在一个单独的索引中,该索引包含图像嵌入,在上面的代码中称为 your-image-index。 该索引由每个图像的文档以及上下文字段和图像的密集矢量(图像嵌入)解释组成。 图像嵌入表示低维空间中的图像。 相似的图像被映射到这个空间中的附近点。 原始图像可能有几 MB 大,具体取决于其分辨率。
如何生成这些嵌入的具体细节可能会有所不同。 一般来说,这个过程涉及从图像中提取特征,然后使用数学函数将它们映射到低维空间。 该函数通常在大量图像数据集上进行训练,以学习在低维空间中表示特征的最佳方式。 生成嵌入是一项一次性任务。
在此博客中,我们将为此目的使用 CLIP 模型。 它由 OpenAI 分发,提供了一个很好的起点。 你可能需要为专门的用例训练自定义嵌入模型以实现所需的性能,具体取决于你要分类的图像类型在用于训练 CLIP 模型的公开可用数据中的表现程度。
Elastic 中的嵌入生成需要在摄取时发生,因此在搜索外部的过程中发生,步骤如下:
- 加载 CLIP 模型。
- 对于每个图像:
- 加载图像。
- 使用模型评估图像。
- 将生成的嵌入保存到文档中。
- 将文档保存到数据存储/Elasticsearch 中。
如下的伪代码使这些步骤更加具体,你可以在示例存储库中访问完整代码。
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc =
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...或者参考下图作为说明:
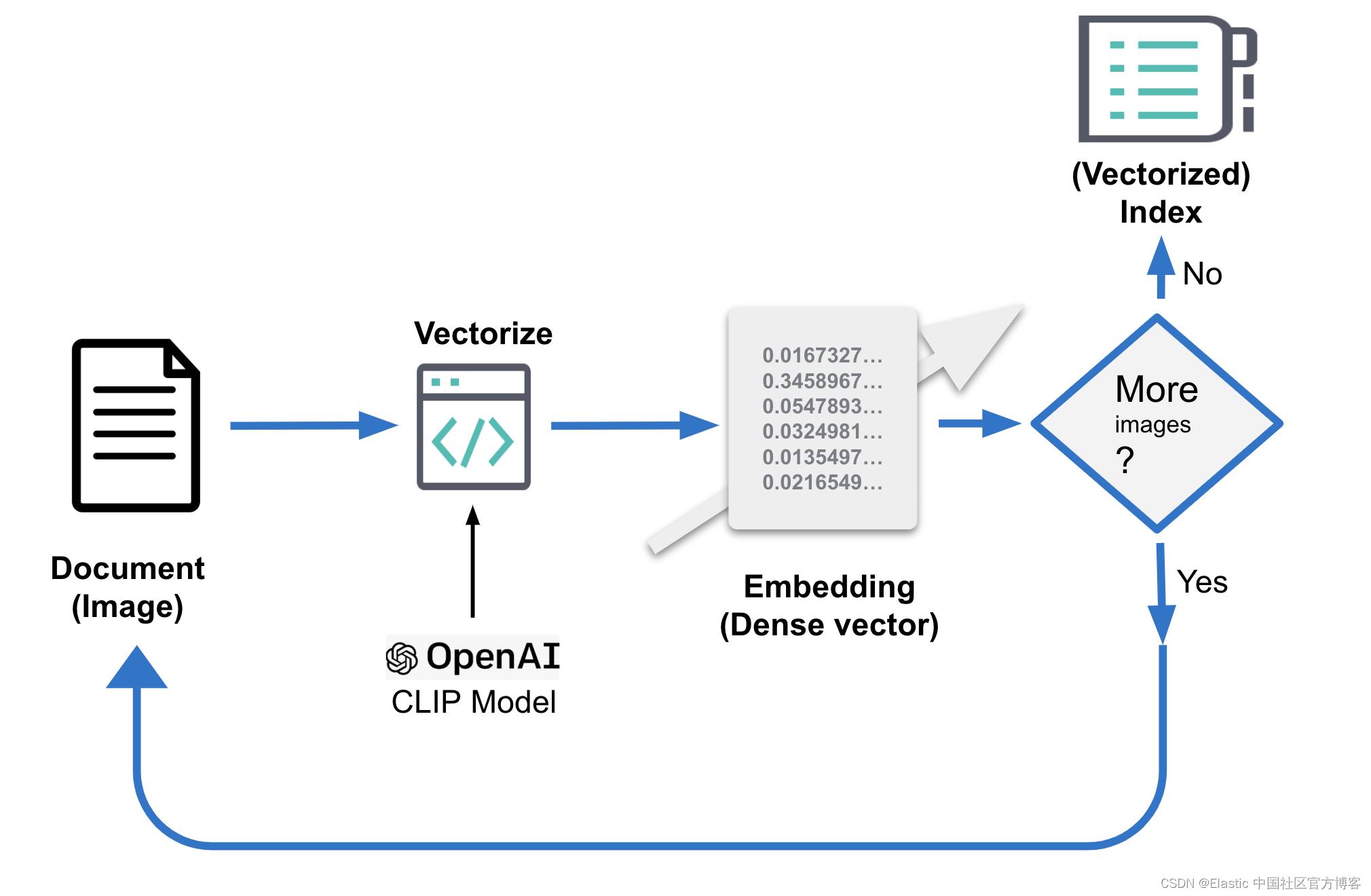
处理后的文档可能如下所示。 关键部分是存储密集向量表示的字段 image_embedding。
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source":
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
5. 应用逻辑
在这些基本组件的基础上,你最终可以将所有部分组合在一起并通过逻辑来实现交互式图像相似性搜索。 让我们从概念上开始,了解当你想要以交互方式检索与给定描述匹配的图像时需要发生的事情。
对于文本查询,输入可以简单到像 "roses" 这样的单个词,也可以是更广泛的描述,如 “a mountain covered in snow”。 或者你也可以提供一张图片并要求提供与你拥有的图片相似的图片。
尽管你使用不同的模式来制定查询,但两者都是在底层矢量搜索中使用相同的步骤序列执行的,即对由其嵌入(作为 “dense” 矢量)表示的文档使用查询 (kNN)。 我们在前面的部分中描述了使 Elasticsearch 能够对大型图像数据集执行非常快速和可扩展的矢量搜索的机制。 请参阅此文档以了解有关在 Elastic 中调整 kNN 搜索以提高效率的更多信息。
- 那么如何实现上述逻辑呢? 在下面的流程图中,你可以看到信息是如何流动的:用户发出的查询,作为文本或图像,由嵌入模型矢量化 —— 取决于输入类型:NLP 模型用于文本描述,而 CLIP 模型用于图像。
- 两者都将输入查询转换为它们的数字表示,并将结果存储为 Elasticsearch 中的密集矢量类型([number, number, number...])。
- 然后在 kNN 搜索中使用向量表示来查找相似的向量(图像),这些向量作为结果返回。
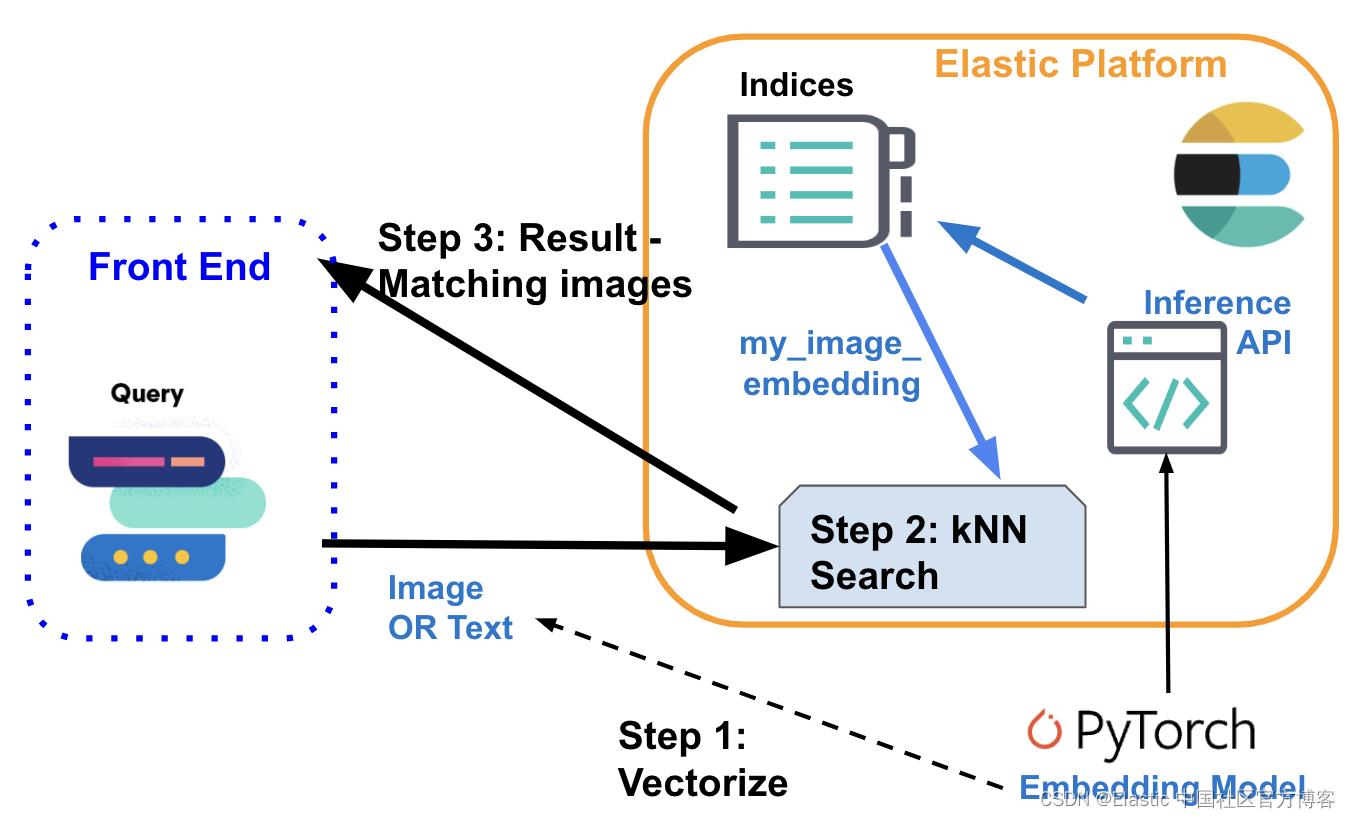
推理:矢量化用户查询
后台的应用程序会向 Elasticsearch 中的推理 API 发送请求。 对于文本输入,是这样的:
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
"docs" : [
"text_field": "A mountain covered in snow"
]
对于图像,你可以使用以下简化代码使用 CLIP 模型处理单个图像,你需要提前将其加载到 Elastic 机器学习节点中:
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)你将得到一个 512 长的 Float32 值数组,如下所示:
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
搜索:寻找相似的图片
对于两种类型的输入,搜索工作相同。 将带有 kNN 搜索定义的查询发送到带有图像嵌入 my-image-embeddings 的索引。 放入先前查询的密集向量 ("query_vector": [ ... ]) 并执行搜索。
GET my-image-embeddings/_search
"knn":
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
,
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
Elasticsearch 的响应将根据我们的 kNN 搜索查询为你提供存储在 Elasticsearch 中最匹配的图像。
下面的流程图总结了交互式应用程序在处理用户查询时所经历的步骤:
- 加载交互式应用程序,它的前端。
- 用户选择他们感兴趣的图像。
- 你的应用程序通过应用 CLIP 模型将图像矢量化,并将生成的嵌入存储为密集矢量。
- 应用程序在 Elasticsearch 中启动 kNN 查询,它获取嵌入并返回其最近的邻居。
- 你的应用程序处理响应并呈现一个(或多个)匹配图像。

现在你已经了解了实现交互式图像相似性搜索所需的主要组件和信息流,你可以浏览本系列的最后一部分,了解如何实现它。 你将获得有关如何设置应用程序环境、导入 NLP 模型以及最终完成图像嵌入生成的分步指南。 然后,你将能够使用自然语言搜索图像 —— 无需关键字。
以上是关于Elasticsearch:图片相似度搜索的 5 个技术组成部分的主要内容,如果未能解决你的问题,请参考以下文章