Elasticsearch:如何正确处理 Elasticsearch 摄取管道故障
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何正确处理 Elasticsearch 摄取管道故障相关的知识,希望对你有一定的参考价值。
在我之前的文章 “Elastic:开发者上手指南” 中的 “Ingest pipeline” 章节中个,我有很多文章是关于 ingest pipeline 的。在今天的文章中,我将重点介绍如何处理在摄取管道中的错误。在我之前的文章 “Elasticsearch:如何处理 ingest pipeline 中的异常” 也有详细描述。在今天的文章中,我将使用一个实际的例子来展示如何实现一个死信索引(dead letter index - DLI)
创建摄取管道的能力是 Elastic Stack 提供的最强大的工具之一,用于在 Elasticsearch 中为数据编制索引之前处理和转换数据。
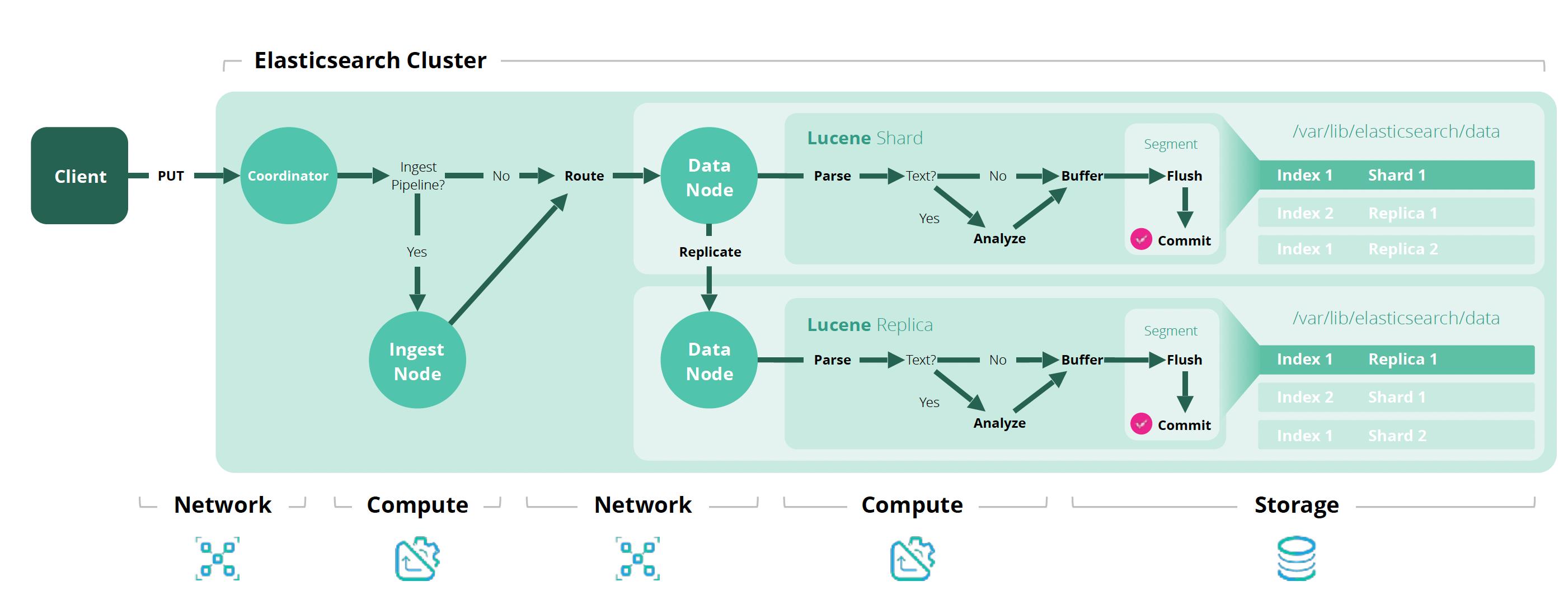
自从它们出现在 Elasticsearch 的第 5 版中以来已经过去了很长时间:
- 添加了许多处理器(用于处理传入的文档)
- 你现在可以直接在 Kibana 中创建和编辑管道
很多人习惯于依赖 Logstash 来执行数据处理,这很好:这个工具证明了自己非常高效、强大和通用,无论你是否想使用 Elasticsearch,都可以发现、操作和导出数据。 但是,它是有代价的:你必须在服务器(物理、VM 或 IAAS)上安装和管理 Logstash。 如果你决定购买 Elastic Cloud 集群,这甚至会很烦人:Logstash 不在报价范围内。
如果你想使用 Logstash 实现高可用性,这取决于你:创建多个节点(不同服务器上的 Logstash 实例)并将它们放在消息代理后面以在这些节点之间分配负载。
另一方面,摄取管道允许实现高水平的数据处理,并与 Elasticsearch 完全集成:一旦你的集群启动并准备就绪,你就可以创建、测试和运行摄取管道。
在数据韧性和故障处理方面,Logstash 原生提供的一项功能称为死信队列 (dead letter queue - DLQ)。 它允许设置 Logstash 将每个不成功的事件存储在一个特殊的地方而不是丢弃它们。 然后可以使用死信队列 Logstash 输入插件来尝试将事件再次呈现给处理管道。
等一下! 死信队列不是 ingest pipeline 的特性,如何正确处理处理失败?
让我们看看如何利用 Elasticsearch 及其摄取管道的强大功能来:
- 处理故障
- 存储不成功的事件
- 重放它们
在今天的展示中,我将使用最新的 Elastic Stack 8.6.1 来进行展示。
Elasticsearch:如何正确处理 Elasticsearch 摄取管道故障
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考我之前的文章 “Elasticsearch:如何在 Docker 上运行 Elasticsearch 8.x 进行本地开发”。出于方便,我在今天的展示中不安装带有安全设置的 Elasticsearch,以便我更容易使用 Python 来写入数据。
准备数据
我们今天使用的数据可以在 Kaggle 网站上下载:Netflix Movies and TV Shows | Kaggle。这个是 2019 年 Netflix shows 的真实数据。这个数据是一个 CSV 格式的数据。在我的博客里有非常多的方法展示了如何把数据写入到 Elasticsearch 中。在今天的展示中,我将使用 Python 应用来写入这些 CSV 数据。
在下载的 CSV 文件中,有一个 header,每行文本代表一个 Netflix 节目。 在其他字段中,你可以找到它的 ID (show_id)、type、title、发布年份等。
show_id,type,title,director,cast,country,date_added,release_year,rating,duration,listed_in,description在数据集中,有些字段缺失,有些需要处理,我们稍后会看到。从下载的数据中,我们可以看到它一共含有 8810 个条目。
让我们写入数据吧 :)
创建索引映射
我们建议创建一个名为 netflix_titles 的 Elasticsearch 索引:
PUT netflix_titles
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
,
"mappings":
"properties":
"cast":
"type": "keyword"
,
"categories":
"type": "keyword"
,
"country":
"type": "keyword"
,
"date_added":
"type": "date"
,
"description":
"type": "text"
,
"director":
"type": "keyword"
,
"duration":
"type": "keyword"
,
"rating":
"type": "keyword"
,
"release_year":
"type": "long"
,
"show_id":
"type": "keyword"
,
"title":
"type": "text"
,
"type":
"type": "keyword"
我们在 Kibana 中运行上面的命令。
创建 ingest pipeline
现在让我们认真起来! 在真正把数据写入到 Elasticsearch 之前,我们需要解析消息、提取字段、管理错误等。 目标是创建适合我们上面设计的 netflix_titles 索引的文档。
我们在 Kibana 中创建如下的 netflix-titles-pipeline 摄取管道:
PUT _ingest/pipeline/netflix-titles-pipeline
"processors": [
"csv":
"description": "Parse the incoming message",
"field": "message",
"target_fields": [
"show_id",
"type",
"title",
"director",
"cast",
"country",
"date_added",
"release_year",
"rating",
"duration",
"listed_in",
"description"
],
"trim": true,
"tag": "csv-parse-message"
,
"split":
"description": "Split the cast property into cast members",
"field": "cast",
"separator": ",\\\\s*",
"ignore_missing": true,
"tag": "split-cast"
,
"split":
"description": "Split the listed_in property into categories",
"field": "listed_in",
"separator": ",\\\\s*",
"ignore_missing": true,
"tag": "split-listed_in"
,
"rename":
"description": "Rename the listed_in property in categories",
"field": "listed_in",
"target_field": "categories",
"ignore_missing": true,
"tag": "rename-listed_in"
,
"trim":
"description": "Trim date_added field",
"field": "date_added",
"ignore_missing": true,
"tag": "trim-date_added"
,
"date":
"description": "Convert date_added field to a date field",
"field": "date_added",
"formats": [ "MMMM d, yyyy"],
"target_field": "date_added",
"tag": "date-date_added"
,
"convert":
"description": "Convert release_year to a number",
"field": "release_year",
"type": "integer",
"tag": "convert-release_year"
,
"remove":
"description": "Finally remove the message field",
"field": "message",
"tag": "remove-message"
]
针对上面的 pipeline,我做如下的一些说明:
首先,我们可以看到一个摄取管道由几个处理器组成,从上到下应用。 每个人都在将传入消息传递给下一个消息之前对其进行修改。
第一个处理器是 csv :它允许我们将字段 message 的内容(这是 python 脚本构建的唯一字段)分解为包含独立数据的单个字段。
然后我们找到其他处理器:
- split 包含几个值的字段,用分隔符分隔成一个字段,就是这些值的数组(split)
- rename 字段,重新命名一个字段
- 将字符串形式的 date_added 字段转换为真正的日期格式字段 (date)
- 将 release_year 转换为整数 ( convert )
最后一个处理器是 remove,顾名思义,它允许从最终事件中删除 message 字段(不需要保留它:我们已经从中提取了所有值)。 这里的关键是将这个处理器放在最后的位置,因为只有当我们确定在前面的处理器执行期间一切都很好时,我们才想删除原始消息(我们可以合理地假设删除处理器不会抛出任何错误...)
问题:现在,如果其中一个处理器出现故障会发生什么?
编写 Python 脚本将数据集注入 Elasticsearch
任何语言或工具都可以用来解析 CSV 文件并将数据发送到 Elasticsearch,你可以在我的文章 “Elastic:开发者上手指南” 找到各种语言写入数据的方法。在本文章中,我们选择 Python 语言来作为数据写入的方法。有关如何使用 Python l连接到 Elasticsearch,请详细参阅文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
你可以在地址 GitHub - liu-xiao-guo/es-indexer: Utility command line program to index lines of a file in an Elasticsearch cluster 查看 Python 脚本。我们将使用这个脚本来写入数据。
这里重要的是这个小程序实际上非常愚蠢:它只是读取输入文件,挑选每一行,创建一个简单的 JSON 消息,它有一个名为 message 的唯一字段包含该行,并使用一个批量索引和要使用的入口管道的名称。
这些原始数据的解析将由 Elasticsearch 端的专用摄取管道负责。
作为示例,请看我们如何使用此脚本启动数据摄取:
$ pip install -r requirements.txt
$ pwd
/Users/liuxg/python/es-indexer
$ python es-indexer.py -e localhost:9200 -s ./netflix_titles.csv netflix_titles在不使用 pipeline 的情况下,我们可以看到如下的输出结果:
$ python es-indexer.py -e http://localhost:9200 -s ./netflix_titles.csv netflix_titles
es_host: http://localhost:9200
args.files: ./netflix_titles.csv
args.index: netflix_titles
args.pipeline: None
arg.skip_first_line: True
-- elasticsearch host set to : http://localhost:9200
success: 8809$ python es-indexer.py -e http://localhost:9200 -s ./netflix_titles.csv netflix_titles
es_host: http://localhost:9200
args.files: ./netflix_titles.csv
args.index: netflix_titles
args.pipeline: None
arg.skip_first_line: True
-- elasticsearch host set to : http://localhost:9200
success: 8809我们的原始文档共有 8810 个条目,除去一个 header 部分,我们成功地摄入了 8809 个文档。说明我们的摄入是成功的。我们也可以在 Kibana 中做如下的查看:
GET netflix_titles/_count
"count": 8809,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
但是在上面,我们并没有使用 pipeline。我们接下来使用 pipeline 来进行摄入文档。
首先,我们在 Kibana 中做如下的操作:
DELETE netflix_titles
PUT netflix_titles
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
,
"mappings":
"properties":
"cast":
"type": "keyword"
,
"categories":
"type": "keyword"
,
"country":
"type": "keyword"
,
"date_added":
"type": "date"
,
"description":
"type": "text"
,
"director":
"type": "keyword"
,
"duration":
"type": "keyword"
,
"rating":
"type": "keyword"
,
"release_year":
"type": "long"
,
"show_id":
"type": "keyword"
,
"title":
"type": "text"
,
"type":
"type": "keyword"
在上面,我删除了 netflix_titles,并重新创建了 netflix_titles 索引。接着我们使用如下的命令:
python es-indexer.py -e http://localhost:9200 -p netflix-titles-pipeline -s ./netflix_titles.csv netflix_titles$ python es-indexer.py -e http://localhost:9200 -p netflix-titles-pipeline -s ./netflix_titles.csv netflix_titles
es_host: http://localhost:9200
args.files: ./netflix_titles.csv
args.index: netflix_titles
args.pipeline: netflix-titles-pipeline
arg.skip_first_line: True
-- elasticsearch host set to : http://localhost:9200
Traceback (most recent call last):
File "/Users/liuxg/python/es-indexer/es-indexer.py", line 58, in <module>
main()
File "/Users/liuxg/python/es-indexer/es-indexer.py", line 51, in main
for ok, _ in streaming_bulk(client=es, actions= generate_bulk_actions(args.file, args.index, args.pipeline or '',
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/helpers/actions.py", line 438, in streaming_bulk
for data, (ok, info) in zip(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/helpers/actions.py", line 355, in _process_bulk_chunk
yield from gen
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/helpers/actions.py", line 274, in _process_bulk_chunk_success
raise BulkIndexError(f"len(errors) document(s) failed to index.", errors)
elasticsearch.helpers.BulkIndexError: 2 document(s) failed to index.很显然,我们的摄入失败了。这个显然是由于我们引入 pipeline 而导致的。我们通过如下的命令来检查已经摄入的文档:
GET netflix_titles/_count
"count": 6498,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
很显然,我们在第 6498 这个文档的地方被卡住了。由于 pipeline 的失败导致我们的摄入终止。我们仔细查找第 6499 这个文档(header 占一行):
s6498,Movie,Click,Frank Coraci,"Adam Sandler, Kate Beckinsale, Christopher Walken, David Hasselhoff, Henry Winkler, Julie Kavner, Sean Astin, Joseph Castanon, Jonah Hill, Jake Hoffman, Jennifer Coolidge",United States,"January 1, 2020",2006,PG-13,108 min,"Comedies, Sci-Fi & Fantasy",Overworked Michael Newman stumbles on a universal remote control that gives him the power to pause or fast-forward through scenes in his life.
很显然,它和其它正常的文档相比较:
s6480,Movie,Christmas in the Smokies,Gary Wheeler,"Sarah Lancaster, Barry Corbin, Alan Powell, Jill Wagner, Danny Vinson, Gregory Alan Williams, Rebecca Koon, Brett Rice",United States,"March 1, 2019",2015,TV-G,88 min,"Children & Family Movies, Dramas, Romantic Movies","In the Smoky Mountains, an ambitious woman works to save her family's historic berry farm as her ex, a country music star, returns to town."
我们发现在那个文档的后面,它少了一个引号。我们一种方法就是添加一个引号来解决这个问题。
从上面的代码中我们可以看出来,由于 pipeline 所抛出的异常而导致我们的客户端不能完成所有数据的写入。
处理错误
如果上述摄取管道失败,则意味着其中一个处理器出现故障。 这也意味着收到的数据并不像我们认为的那样(因为嘿,我们已经对潜在问题进行了很多预期)。
如果 netflix-titles-pipeline 保持原样,任何解析错误都会导致索引错误,但我们会丢失原始消息,因此我们必须做一些聪明的事情来处理错误并将失败的消息存储在此处的某个位置我们可以找到它,修复它并重播它:死信索引(Dead Letter Index)! 🎉
创建一个模板
从 Elastic 7.8 开始,索引模板是可组合的。 我们将使用这种创建模板的新方法来告诉 Elasticsearch 在我们创建名称以 dead-letter- 开头的索引时应用指定的映射。
首先我们创建映射组件模板:
PUT _component_template/dead-letter-mapping-template
"template":
"mappings":
"properties":
"message":
"type": "keyword"
,
"event":
"properties":
"index":
"type": "keyword"
,
"created":
"type": "date"
,
"error":
"properties":
"message":
"type": "text"
,
"processor_type":
"type": "keyword"
,
"processor_tag":
"type": "keyword"
然后使用此组件模板的索引模板:
PUT _index_template/dead-letter-index-template
"index_patterns": "dead-letter-*",
"template":
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
,
"composed_of": [
"dead-letter-mapping-template"
]
让我们分析一下我们刚刚创建的映射。存储在使用此映射创建的索引中的每个文档将包含:
- message:最初收到的消息(失败)
- event.index:我们首先要在其中添加该文档的索引的名称
- event.created:在死信目标中创建文档的日期
- event.error:对象错误,包含错误消息、失败处理器的类型和标记
这显然只是一个示例,你可以随意向此映射添加你可能需要的任何字段。
创建一个摄取管道以将文档添加到死信索引
如果在处理先前的摄取管道期间出现故障,将使用如下定义的摄取管道。 它将以失败时的状态接收失败的文档,这就是为什么必须将原始消息字段的删除设置在处理器列表的最后位置:我们需要将其保留到最后一刻。
当通过死信摄取管道接收到失败的文档时,它将具有 message 字段(包含原始数据)以及摄取管道到目前为止创建的一些新字段:我们将不得不清理接收到的文档以仅保留 message 字段。 然后我们将不得不填写死信文档的其他字段,因为它已由我们之前构建的映射定义。
这是死信摄入管道的定义:
PUT _ingest/pipeline/dead-letter-pipeline
"description": "Index documents in a dead letter index",
"processors": [
"script":
"description": "Clean up document",
"source": """
def keys = ctx.keySet().stream()
.collect(Collectors.toList());
for (def field: keys)
if (!field.startsWith('_') && field != 'message')
ctx.remove(field);
"""
,
"set":
"field": "event.index",
"value": " _index "
,
"set":
"field": "event.created",
"value": " _ingest.timestamp "
,
"set":
"field": "event.error.message",
"value": " _ingest.on_failure_message "
,
"set":
"field": "event.error.processor_type",
"value": " _ingest.on_failure_processor_type "
,
"set":
"field": "event.error.processor_tag",
"value": " _ingest.on_failure_processor_tag "
,
"set":
"description": "Route document to dead-letter-<index>",
"field": "_index",
"value": "dead-letter- _index "
]
让我们解释一下这个摄取管道。请再次记住,摄取管道中的处理器是自上而下执行的。
第一个处理器也是最复杂的:它是一个脚本处理器 —— 运行 Painless 代码——它的功能是清理在前一个摄取阶段失败的文档。 正如我们上面所说,可能发生故障的处理器不一定是第一个处理器,我们的文档已经可以包含比我们只想保留的 message 更多的字段。 此脚本通过删除除以 _ 开头的字段和 message 字段之外的所有字段来清理文档。
然后我们将 event.index 字段设置为失败文档的 _index 字段的值:它包含我们最初尝试存储文档的索引的名称。
我们还设置了通过此管道提取失败文档的日期,以及与错误相关的所有信息。
最后,我们将 _index 字段设置为我们要存储该文档的索引的名称:dead-letter- _index ,这意味着如果原始文档将要存储在索引 foo 之前摄取错误,它现在将存储在 dead-letter-foo 索引中。
更新摄取管道以处理错误
现在我们的死信摄取管道已准备就绪,我们必须更新 Netflix 影片摄取管道以在出现错误时使用它。
我们所要做的就是在管道定义的末尾添加一个 on_failure 语句来捕获所有错误并将失败的文档重定向到我们的新管道 dead-letter-pipeline :
PUT _ingest/pipeline/netflix-titles-pipeline
"processors": [
"csv":
"description": "Parse the incoming message",
"field": "message",
"target_fields": [
"show_id",
"type",
"title",
"director",
"cast",
"country",
"date_added",
"release_year",
"rating",
"duration",
"listed_in",
"description"
],
"trim": true,
"tag": "csv-parse-message"
,
"split":
"description": "Split the cast property into cast members",
"field": "cast",
"separator": """,\\s*""",
"ignore_missing": true,
"tag": "split-cast"
,
"split":
"description": "Split the listed_in property into categories",
"field": "listed_in",
"separator": """,\\s*""",
"ignore_missing": true,
"tag": "split-listed_in"
,
"rename":
"description": "Rename the listed_in property in categories",
"field": "listed_in",
"target_field": "categories",
"ignore_missing": true,
"tag": "rename-listed_in"
,
"trim":
"description": "Trim date_added field",
"field": "date_added",
"ignore_missing": true,
"tag": "trim-date_added"
,
"date":
"description": "Convert date_added field to a date field",
"field": "date_added",
"formats": [
"MMMM d, yyyy"
],
"target_field": "date_added",
"tag": "date-date_added"
,
"convert":
"description": "Convert release_year to a number",
"field": "release_year",
"type": "integer",
"tag": "convert-release_year"
,
"remove":
"description": "Finally remove the message field",
"field": "message",
"tag": "remove-message"
],
"on_failure": [
"pipeline":
"description": "Handle errors through the dedicated pipeline",
"name": "dead-letter-pipeline"
]
测试时间 :)
好的,回到我们的 Netflix 影片数据。
正如我们之前看到的,该文件是一个 CSV 文件,其中每一行代表一个 Netflix 标题。 某些字段丢失或需要清理,这就是我们在摄取管道的某些处理器中添加“ignore_missing”: true 语句的原因。 我们还在 csv 处理器中使用 "trimming": true 选项来删除多余的空格。 使用 Netflix 标题 CSV 文件运行这个摄取管道几乎没问题:每一行都被正确处理,并且相应的文档被添加到目标索引中,除了没有 date_added 字段的行会引发索引错误。
再输入一些错误
为了能够测试我们的错误处理,我们将调整 CSV 文件以添加错误,而不是缺少 date_added 字段。
对于 id 为 s2 的节目,我们删除了 cast 属性的第一个双引号(专用处理器将无法解析)。
s2,TV Show,Blood & Water,,Ama Qamata, Khosi Ngema, Gail Mabalane, Thabang Molaba, Dillon Windvogel, Natasha Thahane, Arno Greeff, Xolile Tshabalala, Getmore Sithole, Cindy Mahlangu, Ryle De Morny, Greteli Fincham, Sello Maake Ka-Ncube, Odwa Gwanya, Mekaila Mathys, Sandi Schultz, Duane Williams, Shamilla Miller, Patrick Mofokeng",South Africa,"September 24, 2021",2021,TV-MA,2 Seasons,"International TV Shows, TV Dramas, TV Mysteries","After crossing paths at a party, a Cape Town teen sets out to
请注意在上面的 Ama 前面,我删除了引号。
对于 id 为 s4 的节目,我把 date_added 字段里的 September 修改为 Septem:
s4,TV Show,Jailbirds New Orleans,,,,"Septem 24, 2021",2021,TV-MA,1 Season,"Docuseries, Reality TV","Feuds, flirtations and toilet talk go down among the incarcerated women at the Orleans Justice Center in New Orleans on this gritty reality series."
对于 id 为 s6 的节目,我们将发行年份 2021 替换为 202T 。
s6,TV Show,Midnight Mass,Mike Flanagan,"Kate Siegel, Zach Gilford, Hamish Linklater, Henry Thomas, Kristin Lehman, Samantha Sloyan, Igby Rigney, Rahul Kohli, Annarah Cymone, Annabeth Gish, Alex Essoe, Rahul Abburi, Matt Biedel, Michael Trucco, Crystal Balint, Louis Oliver",,"September 24, 2021",202T,TV-MA,1 Season,"TV Dramas, TV Horror, TV Mysteries","The arrival of a charismatic young priest brings glorious miracles, ominous mysteries and renewed religious fervor to a dying town desperate to believe."
准备测试
首先,我们删除并重新创建 netflix_titles 索引:
DELETE netflix_titles
PUT netflix_titles
"settings":
"number_of_shards": 1,
"number_of_replicas": 0
,
"mappings":
"properties":
"cast":
"type": "keyword"
,
"categories":
"type": "keyword"
,
"country":
"type": "keyword"
,
"date_added":
"type": "date"
,
"description":
"type": "text"
,
"director":
"type": "keyword"
,
"duration":
"type": "keyword"
,
"rating":
"type": "keyword"
,
"release_year":
"type": "long"
,
"show_id":
"type": "keyword"
,
"title":
"type": "text"
,
"type":
"type": "keyword"
接下来,我们可以通过如下的两个命令来删除之前已经创建好的 ingest pipelines,然后再创建它们:
DELETE _ingest/pipeline/netflix-titles-pipeline
PUT _ingest/pipeline/netflix-titles-pipeline
...
DELETE _ingest/pipeline/dead-letter-pipeline
PUT _ingest/pipeline/dead-letter-pipeline
... 我们此时查看 netflix_titles 索引里应该没有任何的文档。我们可以通过如下的命令来查看当前节点小的 ingest pipelines:
GET _nodes/stats/ingest?filter_path=nodes.*.ingest我们应该看到像如下的 pipelines:
"nodes":
"tZLy82KRTaiCdpsbkEYnuA":
"ingest":
"total":
"count": 58502,
"time_in_millis": 821,
"current": 0,
"failed": 18
,
"pipelines":
"netflix-titles-pipeline":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0,
"processors": [
"csv:csv-parse-message":
"type": "csv",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"split:split-cast":
"type": "split",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"split:split-listed_in":
"type": "split",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"rename:rename-listed_in":
"type": "rename",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"trim:trim-date_added":
"type": "trim",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"date:date-date_added":
"type": "date",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"convert:convert-release_year":
"type": "convert",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"remove:remove-message":
"type": "remove",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
]
,
"dead-letter-pipeline":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0,
"processors": [
"script":
"type": "script",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
,
"set":
"type": "set",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
]
,
"extract_csv":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0,
"processors": [
"csv":
"type": "csv",
"stats":
"count": 0,
"time_in_millis": 0,
"current": 0,
"failed": 0
]
这里重要的是对两个管道 (0) 的调用次数。
摄取有错误的数据
我们还是按照之前的方法来摄取数据。在我们的命令行中打入如下的命令:
python es-indexer.py -e http://localhost:9200 -p netflix-titles-pipeline -s ./netflix_titles.csv netflix_titles$ python es-indexer.py -e http://localhost:9200 -p netflix-titles-pipeline -s ./netflix_titles.csv netflix_titles
es_host: http://localhost:9200
args.files: ./netflix_titles.csv
args.index: netflix_titles
args.pipeline: netflix-titles-pipeline
arg.skip_first_line: True
-- elasticsearch host set to : http://localhost:9200
Total success: 8809很显然,我们这次的调用是成功的。它没有任何的错误信息。Python 代码也没有发生异常。共有 8809 个文档被处理。
这次再让我们来检查一下 ingest pipeline 的统计情况:
GET _nodes/stats/ingest?filter_path=nodes.*.ingest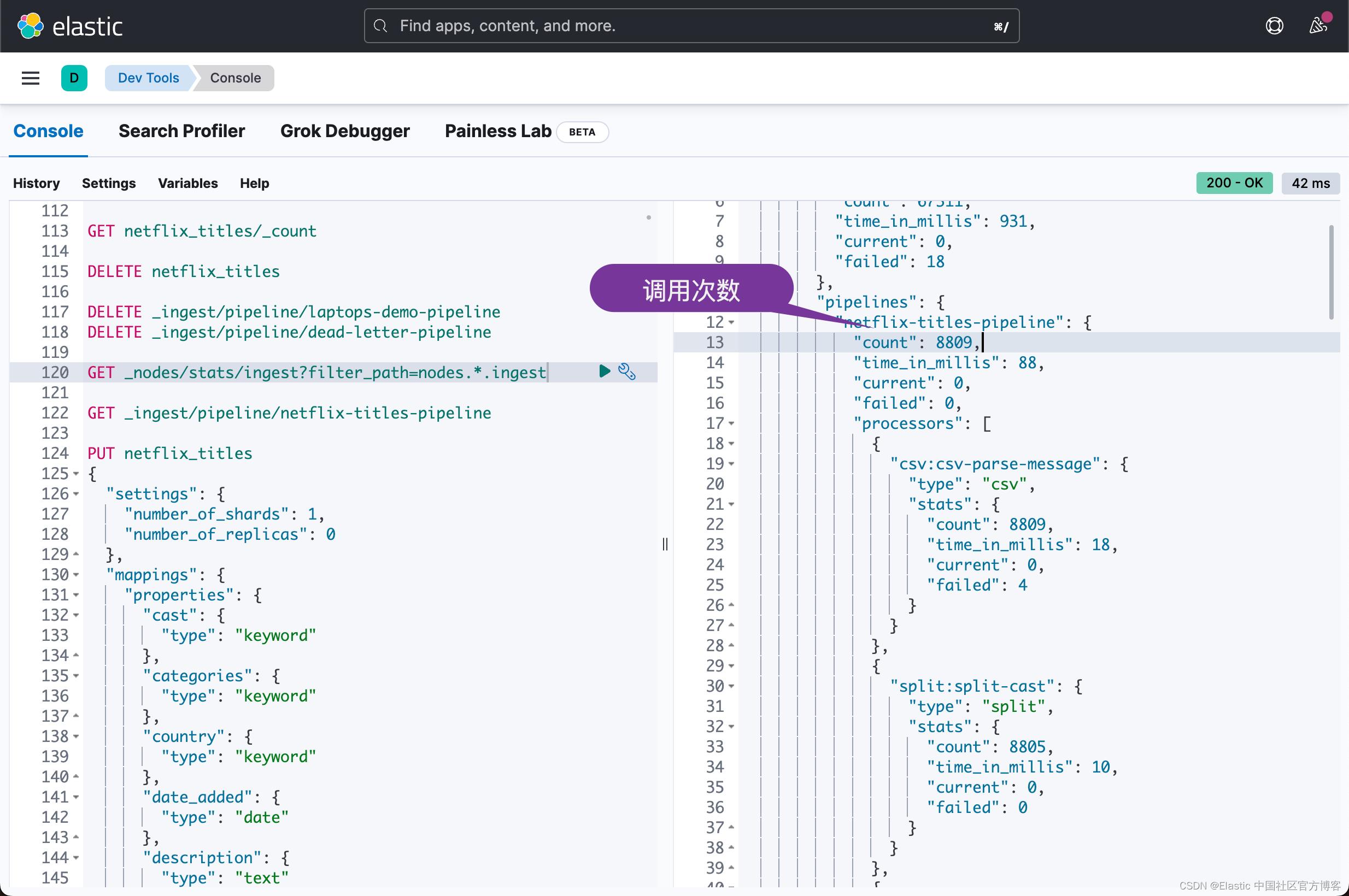
我们可以看到 netflix-title-pipeline 被调用了 8809 次。

我们可以看懂 dead-letter-pipeline 被调用 17 次。
我们可以通过如下的命令来查看 netflix_titles 的文档数:
GET netflix_titles/_count
"count": 8792,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
现在,如果我们检查应该创建的 dead-letter-netflix_titles 索引的内容,我们会发现它包含 17 个文档。 让我们来分析一下这些文件。
GET dead-letter-netflix_titles/_search第一个文档就是:

Hurray! 我们在 message 字段中获取原始消息,并在其他字段中获取错误的详细信息(csv 处理器因缺少引号而失败)。 我们可以看到最初的目标索引是 netflix_titles 并且我们在死信索引中也有该文档的创建日期。我们可以进一步查看其他文档的问题。
修正所有的问题
工作的第一部分现在完成了:当一个文档被发送到 Elasticsearch 时,如果在摄取管道处理过程中没有错误,它就被正确地索引,否则它与我们所收集的所有信息一起被索引到一个死信索引中。需要解决问题。
从那里开始,下一步显然是能够修复和重放文档摄取,希望它能通过。
我们可以创建一个仅包含更正行的 CSV 文件,然后尝试使用 python 脚本再次索引,但我们也可以直接使用死信索引来修复错误并重新索引文档。 这样我们就留在了 Elasticsearch 生态系统中。
更新失败文档
第一步是找到失败的原因:event.error.message 给了我们一个很好的指示,应该允许我们修复消息的内容。
从那里,我们可以直接在死信索引中更新文档。
让我们处理 s2 节目 —— 由于缺少引号而失败的节目 —— 并更新 message 字段以再次添加双引号。
POST dead-letter-netflix_titles/_update/O2UVm4YBRPmzDW_iFSrO
"doc":
"message": "s2,TV Show,Blood & Water,,\\"Ama Qamata, Khosi Ngema, Gail Mabalane, Thabang Molaba, Dillon Windvogel, Natasha Thahane, Arno Greeff, Xolile Tshabalala, Getmore Sithole, Cindy Mahlangu, Ryle De Morny, Greteli Fincham, Sello Maake Ka-Ncube, Odwa Gwanya, Mekaila Mathys, Sandi Schultz, Duane Williams, Shamilla Miller, Patrick Mofokeng\\",South Africa,\\"September 24, 2021\\",2021,TV-MA,2 Seasons,\\"International TV Shows, TV Dramas, TV Mysteries\\",\\"After crossing paths at a party, a Cape Town teen sets out to prove whether a private-school swimming star is her sister who was abducted at birth.\\"",
"event":
"fix_iteration": 1
此命令允许我们更新 message 字段,但也可以将 fix_iteration 字段添加到文档中,以后可能会有用:如果存在 fix_iteration 字段,则意味着有人尝试修复文档,并且 fix_iteration 的值指示有多少已经进行了尝试。
再试一次
现在重试固定文档的索引就像使用 _reindex API 一样简单:
POST _reindex
"source":
"index": "dead-letter-netflix_titles",
"query":
"term":
"event.fix_iteration":
"value": 1
,
"_source": [ "message" ]
,
"dest":
"index": "netflix_titles",
"pipeline": "netflix-titles-pipeline"
我们可以在这里看到,我们使用源过滤来仅索引死信索引中存在的文档的 message 字段。
在死信索引中将文档标记为已修复或什至将其删除以指示没有更多错误需要处理,这可能很有用。
结论
好吧,这篇文章很长,但我认为这个主题是值得的,感谢你阅读到这里。 😍
摄取管道是非常强大的工具,我们一起看到了如何通过处理错误以安全的方式使用它们。
不过有一点免责声明:我在本文中提出的解决方案并不是您想要使用 Elasticsearch 及其摄取管道处理错误时可以想到的唯一解决方案 —— 这是一个功能强大的工具的一个特点,可以提供多种方法来达到相同的目的目标 — ,但是我希望它能帮助您掌握本主题中涉及的各种概念和机制。
以上是关于Elasticsearch:如何正确处理 Elasticsearch 摄取管道故障的主要内容,如果未能解决你的问题,请参考以下文章