hash--
Posted 蚍蜉撼树谈何易
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hash--相关的知识,希望对你有一定的参考价值。
哈希概念
哈希是C++11的产物,是为了提高查找效率所提出的一种关联式容器。
底层结构:链表+(指针)数组
哈希是一种高效用来搜索的数据结构,与传统的查找方式进行比较,发现传统的方式都需要进行元素的比较,性能高低取决于元素的比较次数。让元素在查找时不进行比较,或者减少比较次数。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(log2 N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一对一映射的关系,那么在查找时通过该函数可以很快找到该元素。
实现机制
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)

哈希冲突
什么是哈希冲突?

解决哈希冲突方法
- 直接定制法–(常用)
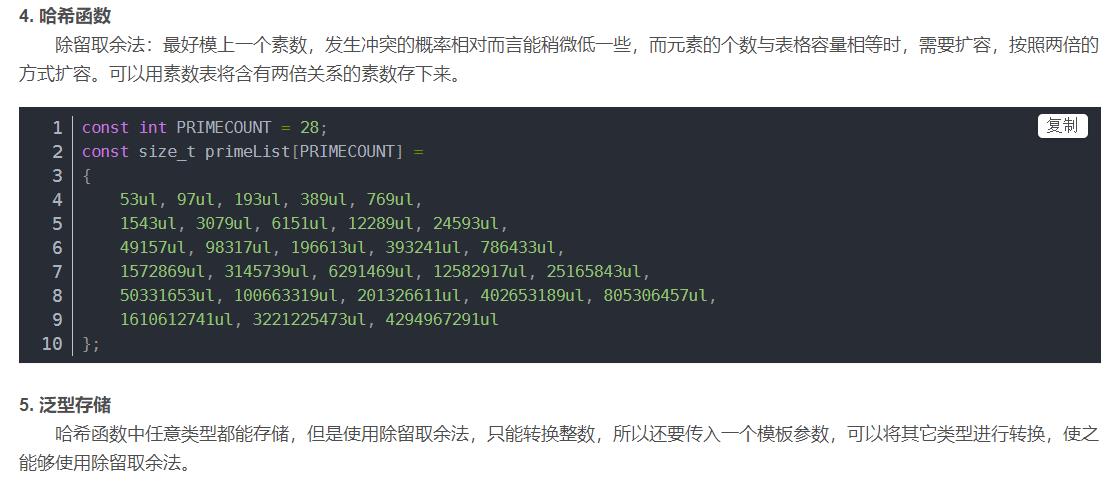
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B 优点:简单、均匀 缺点:需要事先知道关键字的分布情况 使用场景:适合查找比较小且连续的情况 面试题:字符串中第一个只出现一次字符 - 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址 - 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址 平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况
比特科技4. 折叠法–(了解)
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况 - 随机数法–(了解)
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。通常应用于关键字长度不等时采用此法 - 数学分析法–(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
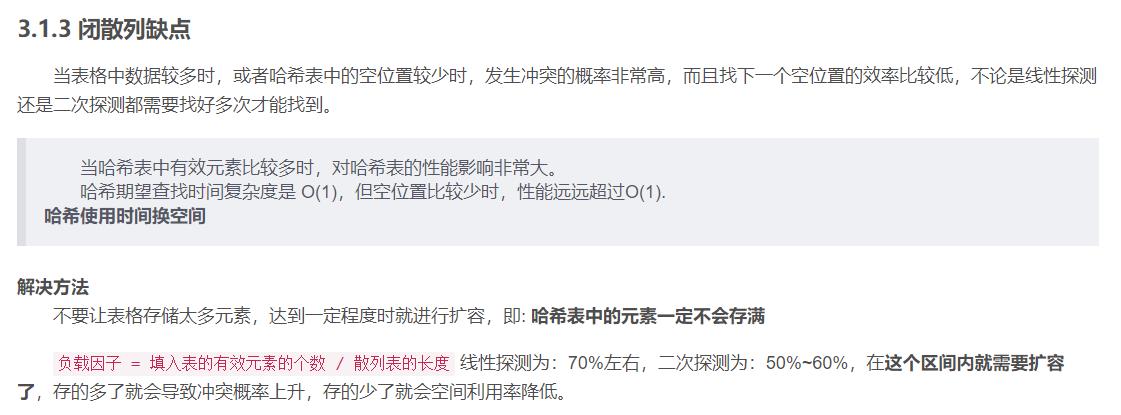
闭散列与开散列
闭散列
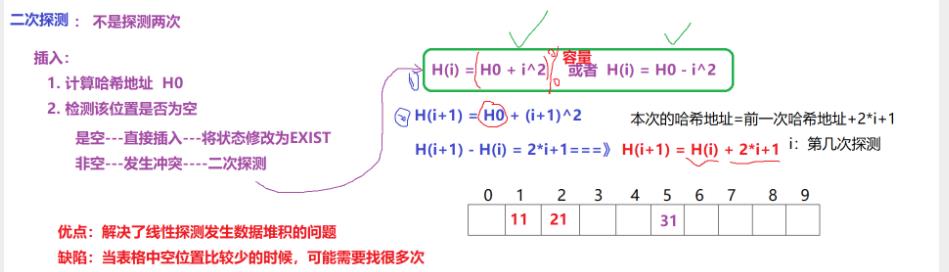
线性探测:

二次探测:
开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
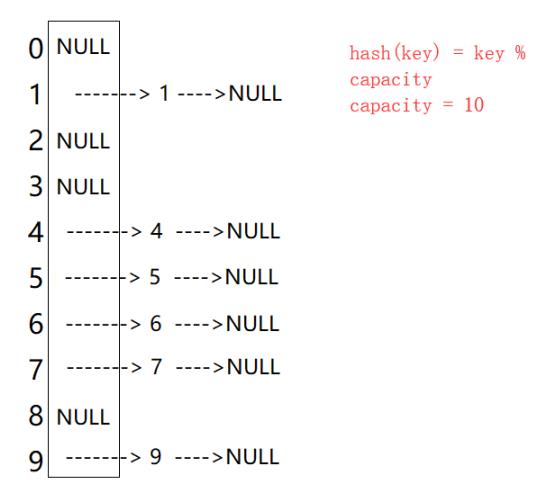
开散列中每个桶中放的都是发生哈希冲突的元素。
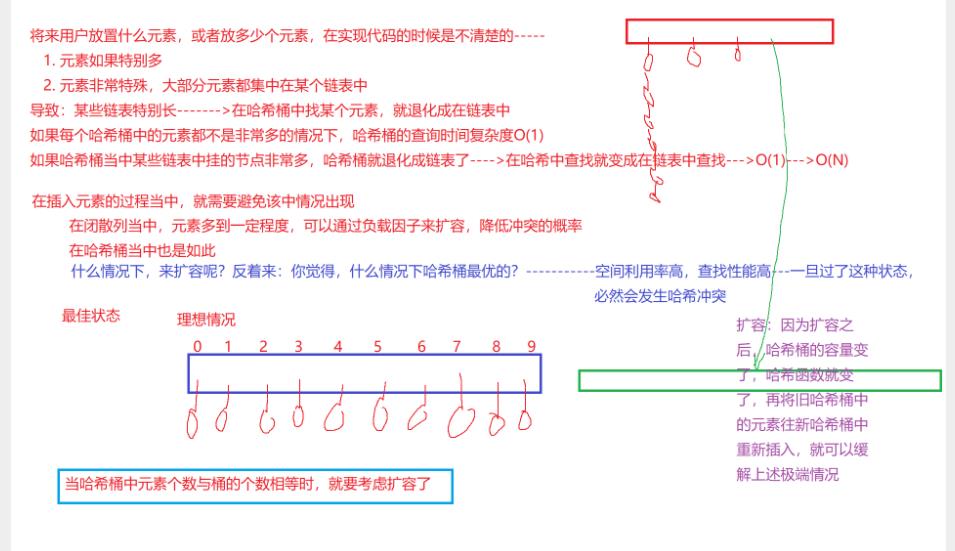
开散列的增容问题
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,那该条件怎么确认呢?开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
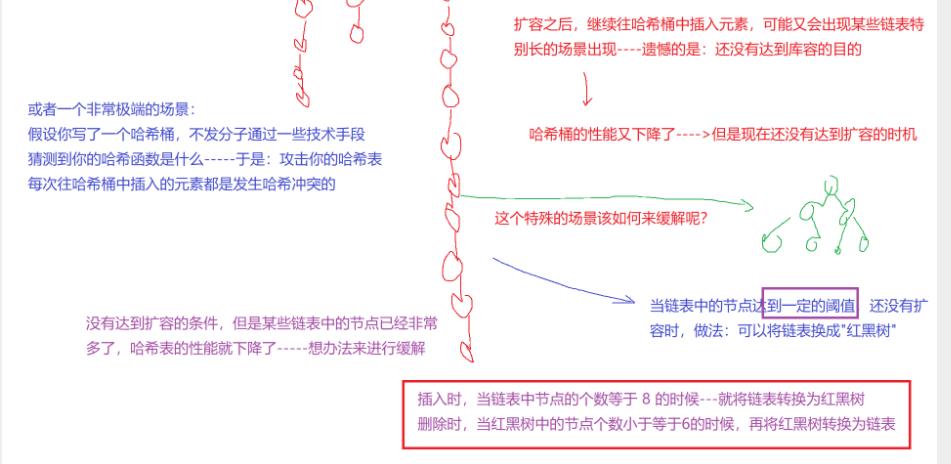

对比
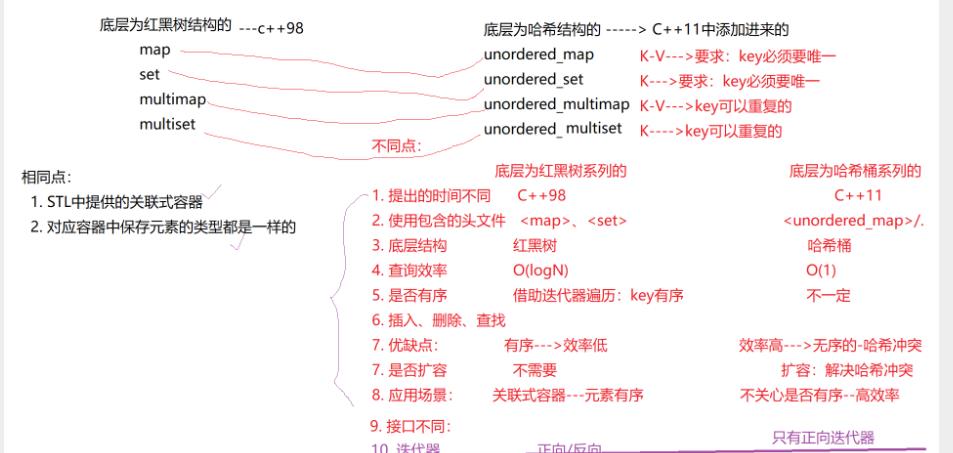
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上: 由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <= 0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
测试代码
#include<iostream>
#include<unordered_map>
using namespace std;
void test_constructor()
unordered_map<string, int> ret;//空构造
//花括号构造2
unordered_map<string, int >ret1 "hello",1,"world",2;
//ret1.insert(make_pair("hello", 2));
//拷贝构造
unordered_map<string, int >ret2(ret1);
//范围构造
unordered_map<string, int> ret3(ret2.begin(), ret2.end());
auto it = ret3.begin();
/*while (it != nullptr)
cout << it->first << "->" << it->second << endl;
++it;
*/
for (auto& it : ret3)
cout << it.first << "->" << it.second << endl;
unordered_map<string, int > ret4 = ret3;
for (auto& it : ret4)
cout << it.first << "->" << it.second << endl;
cout << ret3["helloo"] << endl;
void test_size()
unordered_map<string, int >ret1 "hello",1,"world",2 ;
//有效元素个数(有效键值对)
cout << ret1.size() << endl;
if (ret1.empty())
cout << "empty" << endl;
else
cout << "not empty" << endl;
void test_iterator()
unordered_map<string, int >ret1 "hello",1,"world",2 ;
//正向
auto it = ret1.begin();
while (it!=ret1.end())
cout << it->first << "->" << it->second << endl;
++it;
//返回指向unordered_map容器 (1) 或其中一个桶 (2) 中的第一个元素的const_iterator。 一个常量性是一个迭代器
//,它指向常量内容。这个迭代器可以增减(除非它本身也是const),就像unordered_map::begin返回的迭代器一样,但不能用来修改它指向的内容。
unordered_map< string, int >ret2 "hello",1,"world",2 ;
auto it1 = ret2.cbegin();
while (it1 != ret2.cend())
cout << it1->first << "->" << it1->second << endl;
++it1;
//it = ret1.cbegin();
//测试[]及at
void test_se()
unordered_map<string, int >ret1 "hello",1,"world",2 ;
ret1["q"] = 100;
cout << ret1["hello"] << endl;
auto it = ret1.cbegin();
while (it != ret1.cend())
cout << it->first << "->" << it->second << endl;
++it;
void test_rectify()
unordered_map<string, int >ret "hello",1,"world",2 ;
//单个元素插入
ret.insert(make_pair("qqq", 30));
ret.insert(make_pair("www", 30));
ret.insert(make_pair("eee", 30));
auto it = ret.begin();
while (it != ret.end())
cout << it->first << "->" << it->second << endl;
++it;
cout << endl;
//键值唯一
ret.insert(make_pair("eee", 30));
it = ret.begin();
while (it != ret.end())
cout << it->first << "->" << it->second << endl;
++it;
//区间插入,利用迭代器
unordered_map<string, int >ret2 "helloqqq",1,"worldqqq",2 ;
ret.insert(ret2.begin(), ret2.end());
cout << endl;
it = ret.begin();
while (it != ret.end())
cout << it->first << "->" << it->second << endl;
++it;
cout << endl;
//测试删除
ret.erase("helloqqq");
ret.erase("worldqqq");
it = ret.begin();
while (it != ret.end())
cout << it->first << "->" << it->second << endl;
++it;
cout << endl;
//测试swap
ret.swap(ret2);
it = ret.begin();
while (it != ret.end())
cout << it->first << "->" << it->second << endl;
++it;
//测试清空
ret.clear();
if (ret.empty())
cout << "empty" << endl;
else
cout << "not empty" << endl;
//测试桶操作
void test_bukket()
unordered_map<string, int >ret "hello",1,"world",2 ;
//测试桶个数
cout << ret.bucket_count() << endl;
//测试键值位于哪个桶中
cout << ret.bucket("hello") << endl;
//返回桶中有效元素个数
cout << ret.bucket_size(3) << endl;
void test_find()
unordered_map<string, int >ret "hello",1,"world",2 ;
auto it = ret.find("is");
if (it == ret.end())
cout << "is not in this" << endl;
int main()
//test_constructor();
//test_size();
//test_iterator();
//test_se();
//test_rectify();
//test_bukket();
test_find();
return 0;
以上是关于hash--的主要内容,如果未能解决你的问题,请参考以下文章