3.基于Label studio的训练数据标注指南:文本分类任务
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.基于Label studio的训练数据标注指南:文本分类任务相关的知识,希望对你有一定的参考价值。
文本分类任务Label Studio使用指南

1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
3.基于Label studio的训练数据标注指南:文本分类任务
4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
目录
1. 安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.1
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2. 文本分类任务标注
2.1 项目创建
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后在Labeling Setup中选择Text Classification。
- 填写项目名称、描述

- 数据上传,从本地上传txt格式文件,选择
List of tasks,然后选择导入本项目

- 设置任务,添加标签


2.2 数据上传
项目创建后,可在Project/文本分类任务中点击Import继续导入数据,同样从本地上传txt格式文件,选择List of tasks,详见项目创建 。
2.3 标签构建
项目创建后,可在Setting/Labeling Interface中继续配置标签,详见项目创建
2.4 任务标注

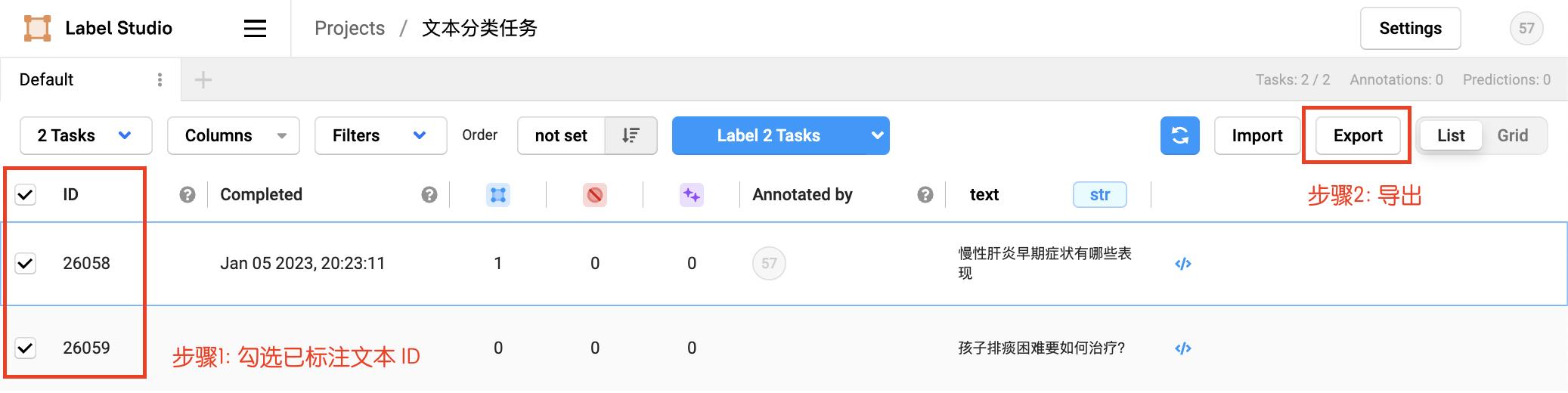
2.5 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:
2.6 数据转换
将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UTC的数据格式。
在数据转换阶段,还需要提供标签候选信息,放在./data/label.txt文件中,每个标签占一行。例如在医疗意图分类中,标签候选为["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"],也可通过options参数直接进行配置。
python label_studio.py \\
--label_studio_file ./data/label_studio.json \\
--save_dir ./data \\
--splits 0.8 0.1 0.1 \\
--options ./data/label.txt
2.7 更多配置
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。options: 指定分类任务的类别标签。若输入类型为文件,则文件中每行一个标签。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
References
以上是关于3.基于Label studio的训练数据标注指南:文本分类任务的主要内容,如果未能解决你的问题,请参考以下文章