Docker容器里进程的 pid 是如何申请出来的?
Posted 热爱编程的大忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker容器里进程的 pid 是如何申请出来的?相关的知识,希望对你有一定的参考价值。
Docker容器里进程的 pid 是如何申请出来的?
引言
如果大家有过在容器中执行 ps 命令的经验,都会知道在容器中的进程的 pid 一般是比较小的。例如下面我的这个例子。
# ps -ef
PID USER TIME COMMAND
1 root 0:00 ./demo-ie
13 root 0:00 /bin/bash
21 root 0:00 ps -ef
不知道大家是否和我一样好奇容器进程中的 pid 是如何申请出来的?和宿主机中申请 pid 有什么不同?内核又是如何显示容器中的进程号的?
前面我们在《Linux进程是如何创建出来的?》中介绍了进程的创建过程。事实上进程的 pid 命名空间、pid 也都是在这个过程中申请的。我今天就来带大家深入理解一下 docker 核心之一 pid 命名空间的工作原理。
一、Linux 的默认 pid 命名空间
前面的文章《Linux进程是如何创建出来的?》中我们提到了进程的命名空间成员 nsproxy。
//file:include/linux/sched.h
struct task_struct
...
/* namespaces */
struct nsproxy *nsproxy;
Linux 在启动的时候会有一套默认的命名空间,定义在 kernel/nsproxy.c 文件下。
//file:kernel/nsproxy.c
struct nsproxy init_nsproxy =
.count = ATOMIC_INIT(1),
.uts_ns = &init_uts_ns,
.ipc_ns = &init_ipc_ns,
.mnt_ns = NULL,
.pid_ns = &init_pid_ns,
.net_ns = &init_net,
;
其中默认的 pid 命名空间是 init_pid_ns,它定义在 kernel/pid.c 下。
//file:kernel/pid.c
struct pid_namespace init_pid_ns =
.kref =
.refcount = ATOMIC_INIT(2),
,
.pidmap =
[ 0 ... PIDMAP_ENTRIES-1] = ATOMIC_INIT(BITS_PER_PAGE), NULL
,
.last_pid = 0,
.level = 0,
.child_reaper = &init_task,
.user_ns = &init_user_ns,
.proc_inum = PROC_PID_INIT_INO,
;
在 pid 命名空间里我觉得最需要关注的是两个字段。一个是 level 表示当前 pid 命名空间的层级。另一个是 pidmap,这是一个 bitmap,一个 bit 如果为 1,就表示当前序号的 pid 已经分配出去了。
另外默认命名空间的 level 初始化是 0。这是一个表示树的层次结构的节点。如果有多个命名空间创建出来,它们之间会组成一棵树。level 表示树在第几层。根节点的 level 是 0。
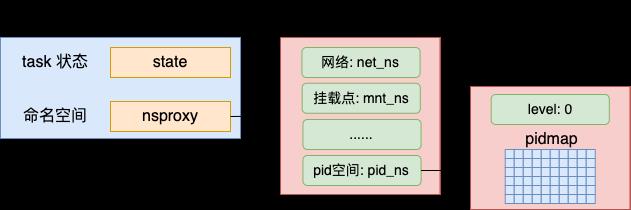
INIT_TASK 0号进程,也叫 idle 进程,它固定使用这个默认的 init_nsproxy。
//file:include/linux/init_task.h
#define INIT_TASK(tsk) \\
.state = 0, \\
.stack = &init_thread_info, \\
.usage = ATOMIC_INIT(2), \\
.flags = PF_KTHREAD, \\
.prio = MAX_PRIO-20, \\
.static_prio = MAX_PRIO-20, \\
.normal_prio = MAX_PRIO-20, \\
...
.nsproxy = &init_nsproxy, \\
......
所有进程都是一个派生一个的方式生成出来的。如果不指定命名空间,所有进程使用的都是使用缺省的命名空间。
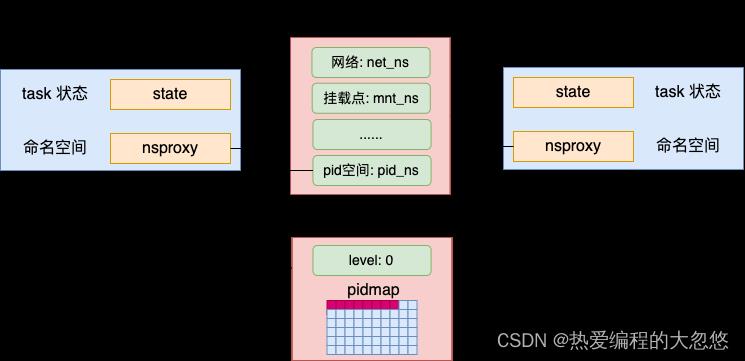
二、Linux 新 pid 命名空间创建
在这里,我们假设我们创建进程时指定了 CLONE_NEWPID 要创建一个独立的 pid 命名空间出来(Docker 容器就是这么干的)。
在 《Linux进程是如何创建出来的?》一文中我们已经了解了进程的创建过程。整个创建过程的核心是在于 copy_process 函数。
在这个函数中会申请和拷贝进程的地址空间、打开文件列表、文件目录等关键信息,另外就是pid 命名空间的创建也是在这里完成的。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
...
//2.1 拷贝进程的命名空间 nsproxy
retval = copy_namespaces(clone_flags, p);
//2.2 申请 pid
pid = alloc_pid(p->nsproxy->pid_ns);
//2.3 记录 pid
p->pid = pid_nr(pid);
p->tgid = p->pid;
attach_pid(p, PIDTYPE_PID, pid);
...
2.1 创建进程时构造新命名空间
在上面的 copy_process 代码中我们看到对 copy_namespaces 函数的调用。命名空间就是在这个函数中操作的。
//file:kernel/nsproxy.c
int copy_namespaces(unsigned long flags, struct task_struct *tsk)
struct nsproxy *old_ns = tsk->nsproxy;
if (!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |
CLONE_NEWPID | CLONE_NEWNET)))
return 0;
new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);
tsk->nsproxy = new_ns;
...
如果在创建进程时候没有传入 CLONE_NEWNS 等几个 flag,还是会复用之前的默认命名空间。这几个 flag 的含义如下。
- CLONE_NEWPID: 是否创建新的进程编号命名空间,以便与宿主机的进程 PID 进行隔离
- CLONE_NEWNS: 是否创建新的挂载点(文件系统)命名空间,以便隔离文件系统和挂载点
- CLONE_NEWNET: 是否创建新的网络命名空间,以便隔离网卡、IP、端口、路由表等网络资源
- CLONE_NEWUTS: 是否创建新的主机名与域名命名空间,以便在网络中独立标识自己
- CLONE_NEWIPC: 是否创建新的 IPC 命名空间,以便隔离信号量、消息队列和共享内存
- CLONE_NEWUSER: 用来隔离用户和用户组的。
因为我们本节开头假设传入了 CLONE_NEWPID 标记。所以会进入到 create_new_namespaces 中来申请新的命名空间。
//file:kernel/nsproxy.c
static struct nsproxy *create_new_namespaces(unsigned long flags,
struct task_struct *tsk, struct user_namespace *user_ns,
struct fs_struct *new_fs)
//申请新的 nsproxy
struct nsproxy *new_nsp;
new_nsp = create_nsproxy();
......
//拷贝或创建 PID 命名空间
new_nsp->pid_ns = copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns);
create_new_namespaces 中会调用 copy_pid_ns 来完成实际的创建,真正的创建过程是在 create_pid_namespace 中完成的。
//file:kernel/pid_namespace.c
static struct pid_namespace *create_pid_namespace(...)
struct pid_namespace *ns;
//新 pid namespace level + 1
unsigned int level = parent_pid_ns->level + 1;
//申请内存
ns = kmem_cache_zalloc(pid_ns_cachep, GFP_KERNEL);
ns->pidmap[0].page = kzalloc(PAGE_SIZE, GFP_KERNEL);
ns->pid_cachep = create_pid_cachep(level + 1);
//设置新命名空间 level
ns->level = level;
//新命名空间和旧命名空间组成一棵树
ns->parent = get_pid_ns(parent_pid_ns);
//初始化 pidmap
set_bit(0, ns->pidmap[0].page);
atomic_set(&ns->pidmap[0].nr_free, BITS_PER_PAGE - 1);
for (i = 1; i < PIDMAP_ENTRIES; i++)
atomic_set(&ns->pidmap[i].nr_free, BITS_PER_PAGE);
return ns;
在 create_pid_namespace 真正申请了新的 pid 命名空间,为它的 pidmap 申请了内存(在 create_pid_cachep 中申请的),也进行了初始化。
另外还有一点比较重要的是新命名空间和旧命名空间通过 parent、level 等字段组成了一棵树。其中 parent 指向了上一级命名空间,自己的 level 用来表示层次,设置成了上一级 level + 1。
其最终的效果就是新进程拥有了新的 pid namespace,并且这个新 pid namespace 和父 pidnamespace 串联了起来,效果如下图。
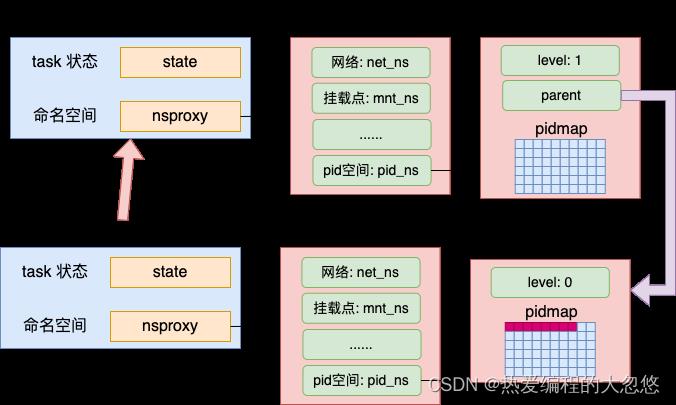
如果 pid 有多层的话,会组成更直观的树形结构。
2.2 申请进程id
创建完命名空间后,在 copy_process 中接下来接着就是调用 alloc_pid 来分配 pid。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
...
//2.1 拷贝进程的命名空间 nsproxy
retval = copy_namespaces(clone_flags, p);
...
//2.2 申请 pid
pid = alloc_pid(p->nsproxy->pid_ns);
...
注意传入的参数是 p->nsproxy->pid_ns。前面进程创建了新的 pid namespace,这个时候该命名空间就是 level 为 1 的新 pid_ns。我们继续来看 alloc_pid 具体 pid 的过程。
//file:kernel/pid.c
struct pid *alloc_pid(struct pid_namespace *ns)
//申请 pid 内核对象
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
//调用到alloc_pidmap来分配一个空闲的pid
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--)
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
...
return pid;
在上面的代码中要注意两个细节。
- 我们平时说的 pid 在内核中并不是一个简单的整数类型,而是一个小结构体来表示的(struct pid)。
- 申请 pid 并不是申请了一个,而是使用了一个 for 循环申请多个出来
之所以要申请多个,是因为对于容器里的进程来说,并不是在自己当前的命名空间申请就完事了,还要到其父命名空间中也申请一个。我们把 for 循环的工作工程用下图表示一下。
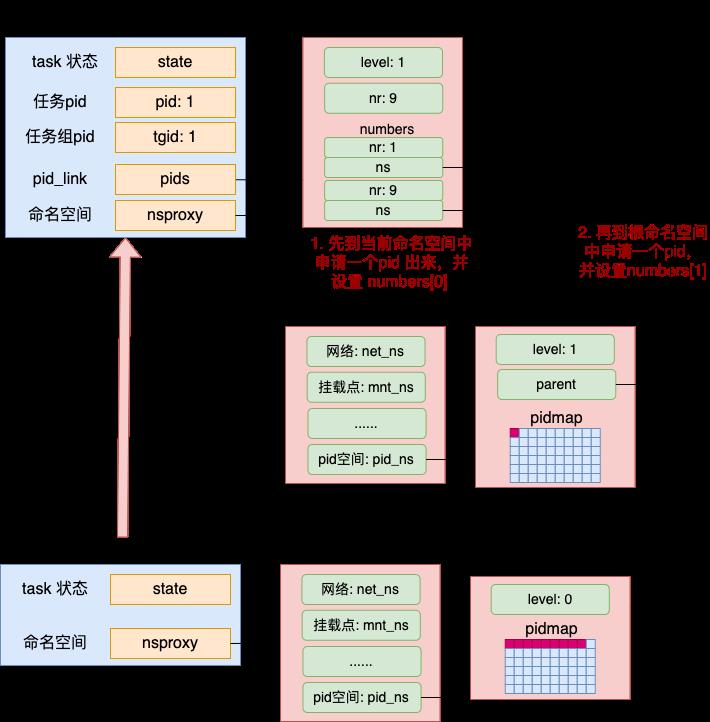
首先到当前层次的命名空间申请一个 pid 出来,然后顺着命名空间的父节点,每一层也都要申请一个,并都记录到 pid->numbers 数组中。
这里多说一下,如果 pid 申请失败的话,会报 -ENOMEM 错误,在用户层看起来就是“fork:无法分配内存”,实际是由 pid 不足引起的。这个问题我在《明明还有大量内存,为啥报错“无法分配内存”?》 提到过。
2.3 设置整数格式 pid
当申请并构造完 pid 后,将其设置在 task_struct 上,记录起来。
//file:kernel/fork.c
static struct task_struct *copy_process(...)
...
//2.2 申请 pid
pid = alloc_pid(p->nsproxy->pid_ns);
//2.3 记录 pid
p->pid = pid_nr(pid);
p->tgid = p->pid;
attach_pid(p, PIDTYPE_PID, pid);
...
其中 pid_nr 是获取的根 pid 命名空间下的 pid 编号,参见 pid_nr 源码。
//file:include/linux/pid.h
static inline pid_t pid_nr(struct pid *pid)
pid_t nr = 0;
if (pid)
nr = pid->numbers[0].nr;
return nr;
然后再调用 attach_pid 是把申请到的 pid 结构挂到自己的 pids[PIDTYPE_PID] 链表里了。
//file:kernel/pid.c
void attach_pid(struct task_struct *task, enum pid_type type,
struct pid *pid)
...
link = &task->pids[type];
link->pid = pid;
hlist_add_head_rcu(&link->node, &pid->tasks[type]);
task->pids 是一组链表。
三、容器进程 pid 查看
pid 已经申请好了,那在容器中是如何查看当前层次的进程号的呢?比如我们在容器中看到的 demo-ie 进程的 id 就是 1。
# ps -ef
PID USER TIME COMMAND
1 root 0:00 ./demo-ie
...
内核提供了个函数用来查看进程在当前某个命名空间的命名号。
//file:kernel/pid.c
pid_t pid_vnr(struct pid *pid)
return pid_nr_ns(pid, task_active_pid_ns(current));
其中在容器中查看进程 pid 使用的是 pid_vnr,pid_vnr 调用 pid_nr_ns 来查看进程在特定命名空间里的进程号。
函数 pid_nr_ns 接收连个参数
- 第一个参数是进程里记录的 pid 对象(保存有在各个层次申请到的 pid 号)
- 第二个参数是指定的 pid 命名空间(通过 task_active_pid_ns(current)获取)。
当具备这两个参数后,就可以根据 pid 命名空间里记录的层次 level 取得容器进程的当前 pid 了
//file:kernel/pid.c
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)
struct upid *upid;
pid_t nr = 0;
if (pid && ns->level <= pid->level)
upid = &pid->numbers[ns->level];
if (upid->ns == ns)
nr = upid->nr;
return nr;
在 pid_nr_ns 中通过判断 level 就把容器 pid 整数值查出来了。
四、总结
最后,举个例子,假如有一个进程在 level 0 级别的 pid 命名空间里申请到的进程号是 1256,在 level 1 容器 pid 命名空间里申请到的进程号是 5。那么这个进程以及其 pid 在内存中的形式是下图这个样子的。

那么容器在查看进程的 pid 号的时候,传入容器的 pid 命名空间,就可以将该进程在容器中的 pid 号 5 给打印出来了!!
转载
以上是关于Docker容器里进程的 pid 是如何申请出来的?的主要内容,如果未能解决你的问题,请参考以下文章