《Effective STL》阅读笔记
Posted grayondream
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Effective STL》阅读笔记相关的知识,希望对你有一定的参考价值。
一 容器
1 慎重选择容器
STL提供了多种容器,不同容器的应用场景不同,需要充分理解容器的使用场景,并针对性的选择合适的容器。C++中的容器类型包括:
- 标准STL序列容器:vector、string、deque、list;
- 标准STL关联容器:set、multiset、map、multimap;
- 非标准序列容器:slist、rope;
- 非标准关联容器:unordered_set、unordered_multiset、unordered_map、unordered_multimap;
- 标准的非STL容器:array、bitset、valarray、stack、queue、priority_queue。
上面提到的多种容器一般分类为连续内存容器(vector、string和dequeue)和基于节点的容器(set、list等)。在进行容器选择时可以按照下面的准则进行判断:
- 若需要在容器的任意位置插入新元素,选择序列容器;关联容器是不行的;
- 若关心容器中的元素是排序的,如果不关心,则散列容器是一个可行的选择;否则要避免散列容器;
- 若选择的容器必须是标准C++的一部分,就排除了散列容器、slist和rope;
- 若需要随机访问迭代器,则对容器的选择就被限定为vector、deque和string,也可以考虑rope;若需要双向迭代器,那么必须避免slist以及散列容器的一个常见实现;
- 发生元素的插入或删除操作时,若需要避免移动容器中原来的元素,则要避免连续内存的容器;
- 若容器中数据的布局需要和C兼容,则只能选择vector;
- 若元素的查找速度是关键的考虑因素,则要考虑散列容器、排序的vector和标准关联容器;
- 若介意容器内部使用了引用计数技术(reference counting),则要避免使用string和rope。当然,若需要某种表示字符串的方法,这是可以考虑vector;
- 对于插入和删除操作,若需要事务语义(transactional semantics)即在插入和删除操作失败时,若需要回滚的能力,则使用基于节点的容器;
- 若需要使迭代器、指针和引用变为无效的次数最少,则要使用基于节点的容器,因为对这类容器的插入和删除操作从来不会使迭代器、指针和引用变为无效(除非它们指向了一个你正在删除的元素),而针对连续内存容器的插入和删除操作一般会使指向该容器的迭代器、指针和引用变为无效;
- 当插入操作仅在容器末尾发生时,deque的迭代器有可能会变为无效。deque是唯一的、迭代器可能会变为无效而指针和引用不会变为无效的STL标准容器。
2 不要试图编写独立于容器类型的代码
由于不同类型的容器的具体实现差距过大,即便是相同操作往往也可能有不同的执行结果。比如map默认是有序的,vector默认是无序的,对二者进行insert或者erase操作对容器的结构影响不同,且迭代器、指针和引用等失效的策略不同。因此尝试写独立于容器的代码往往得不偿失。
但是有时为了隐藏实现,不可避免希望将容器独立于实现代码中可以使用typedef将具体的容器类型封装隐藏,或者将容器隐藏在一个类中将对容器的操作进行抽象,即创建一个适配器满足当前的应用场景。但是这么做的时候也需要仔细考虑,有没有可能过度设计,过度封装。
//使用typedef封装隐藏实现
typedef vector<Object> objVector;
typedef objVector::iterator objVecIterator;
//将容器隐藏在类中
class ObjVector
private:
typedef vector<Object> objVector;
typedef objVector::iterator objVecIterator;
public:
objVecIterator insert(Object obj);
;
3 确保容器中的对象拷贝正确且高效
STL虽然针对传入的对象类型进行了左右值得优化,但是有些情况下依然可能调用对象的拷贝构造函数。因此在使用STL插入对象时需要明白对象的拷贝的开销,如果开销过大可尝试使用指针进行管理。
4 使用empty而不是size() == 0
虽然size() == 0和empty()语义结果相同,但是二者的语义不同。STL容器基本能够保证empty()的耗时是常数,但是有些容器size()无法保证常数的实现,因此为了保证性能应该 只使用empty()判空。
5 区间成员函数优先于对应的氮元素成员函数
区间成员函数是指使用迭代器的区间操作容器,而不是使用循环多次调用针对某单个元素的插入或者删除工作。使用区间成员函数能够触发某些优化,比如对于内置类型STL可能直接使用memmove移动内存,防止在插入或者删除时不断改变元素的位置。同时使用区间成员函数代码的可维护性和可读性相比比较好。
一般设计的区间操作包含:区间创建,区间插入,区间删除,区间赋值。
6 当心C++编译期烦人的分析机制。
C++编译器在分析声明时尽量将语句解析为函数声明,如果无法解析为函数声明再尝试其他解析方式。如果某一个变量的声明符合函数声明的语法则会被解释为函数声明,导致期望外的语义,比如:
list<char> data(istream_iterator<char>(is), istream_iterator<char>());
C++中允许省略参数名和在参数名中添加括号,因此上面的声明会被解析为返回值为list<char>,第一个参数为is,第二个参数省略参数名的函数声明。为了避免该种情况可显示声明istream_iteraor<char>两个对象而不是在函数调用中创建,或者将istream_iterator<char>(is)使用括号包含。
list<char> data((istream_iterator<char>(is)), istream_iterator<char>());
istream_iterator<char> is, dataFile;
list<char> data(is, dataFile);
7 如果容器中包含了使用new创建的指针,需要在容器析构前释放其中的内存
容器只负责维护插入的对象,对象的销毁工作需要用户自己负责。对于栈上的对象因为时自动析构的,用户不用在意,但是对于堆上的对象容器只会销毁对应的指针对象,而指针对象指向的内存容器是不会管理的。因此如果容器中插入了堆指针,则需要在容器销毁前释放对应的内存。
8切勿包含auto_ptr容器对象
auto_ptr已经被开除智能指针的行列了,目前应该不存在这个问题。
9 慎重选择删除对象的方法
虽然直接调用对应的函数能够直接删除容器中的对象,但是如果使用更加合理的操作函数能够提高效率。
- 删除容器中特定值的所有对象:
- 如果为
vector``````string或者deque,则使用erase(remove)方法; - 如果是
list,使用remove; - 如果是标准关联容器使用
erase;
- 如果为
- 删除容器中满足某个判别式的所有对象:
- 如果为
vector``````string或者deque,则使用erase(remove_if)方法; - 如果是
list,使用remove_if; - 如果是标准关联容器使用
remove_copy_if或者```swap,或者自己写一个循环;
- 如果为
- 要在循环内部做某些外的操作:
- 如果为标准序列容器,则在遍历时进行操作,记得更新迭代器;
- 如果为标准关联容器,则在遍历时进行操作,更新迭代器后记得自增。
10 了解allocator的约定和限制
allocator存在一些问题:
allocate得到的内存虽然类型为T*但是并不是真正的对象的内存,因为对象还未构造;- 为了保证
allocator相同类型的等价性,allocator不能包含非静态数据成员,因为该成员会破坏对象的状态; - 对于基于节点管理的容器
allocator并不真正的负责节点的内存申请,STL实现中而是使用一个other负责节点内存构造。
template<class _Other>
struct _CXX17_DEPRECATE_OLD_ALLOCATOR_MEMBERS rebind
// convert this type to allocator<_Other>
using other = allocator<_Other>;
;
如果希望编写自定义的分配子,需要记住以下内容:
- 分配子是一个模板,模板参数T代表为它分配内存的对象的类型。
- 提供类型定义pointer和reference,但是始终让pointer为T*,reference为T&。
- 千万别让分配子拥有随对象而不同的状态(per-object state)。通常,分配子不应该有非静态的数据成员。
- 传给分配子的allocate成员函数的是那些要求内存的对象的个数,而不是所需的字节数。同时要记住,那些函数返回T*指针(通过pointer类型定义),即使尚未有T对象被构造出来。
- 一定要提供嵌套的rebind模板,因为标准容器依赖该模板。
11 理解自定义分配子的合理方法
针对不同的场景需要不同的使用方式。
12 切勿对STL容器的线程安全性有不切实际的依赖
STL不能完全保证线程安全性,因此在实现线程安全地代码时需要自行针对代码的线程安全性进行自我检查,如果无法保证代码的可重入性则使用锁保证。
二 vector和string
13 vector和string优先于动态分配的数组
当决定用new来动态分配内存时,这意味着将承担以下责任:
- 必须确保以后用delete来删除所分配的内存,否则会导致资源泄漏
- 必须确保使用了正确的
delete形式,如果分配了单个对象,则必须使用"delete";如果分配了数组,则需要使用"delete[]"。如果使用了不正确的delete形式,那么结果将是不确定的。在有些平台上,程序会在运行时崩溃;在其他平台上,它会妨碍进一步运行,有时会泄漏资源和破坏内存。 - 必须确保只
delete了一次。如果一次分配被多次delete,结果同样是不确定的。
如果正在动态地分配数组,那么可能要做更多的工作。为了减轻自己的负担,使用vector或string。另外有些时候string是以引用计数实现的,多线程环境下引用计数带来的性能损耗可能远超过你对所占用内存的容忍度,那么需要尝试改变string,禁用引用计数或者自己实现一个,或者使用vector<char>。
14 使用reverse避免不必要的内存分配
如果场景中需要频繁插入数据,可能预先使用reverse分配对应大小的内存能够减小可能发生的不断申请销毁内存的消耗。
STL容器中如果内存不足会申请新的内存,将对象拷贝到新内存,然后销毁就内存。
15 注意string的多样性
- string的值可能会被引用计数,也可能不会。很多实现在默认情况下会使用引用计数,但它们通常提供了关闭默认选择的方法,往往是通过预处理宏来做到这一点。
- string对象大小的范围可以是一个char*指针大小的1倍到7倍。
- 创建一个新的字符串值可能需要零次、一次或两次动态分配内存。
- string对象可能共享,也可能不共享其大小和容量信息。
- string可能支持,也可能不支持针对单个对象的分配子。
- 不同的实现对字符内存的最小分配单位有不同的策略。
16 了解如何把vector和string数据传给旧的API
在使用容器时可能需要将容器数据传递给某些C接口,对于vector可直接将首个元素的地址传递给需要兼容的接口即可,但是需要注意可能容器中没有元素获取第一个元素的地址是非法的。虽然对于某些内置类型迭代器就是指针,但是不建议获取地带器的指针作为数据地址的起始位置,如果需要使用可以使用&*vec.begin()。
vector<int> vec;
if(!vec.empty())
doSomething(&vec[0]);
对于stinrg内部实现不一定是连续内存,因此不能使用和vector同样的方式获取地址,可以使用STL提供的APIc_str(),该函数返回一个const char*。
另外需要注意的是,在使用vector时如果获取了对应数据的地址,如果以后需要继续使用对应的vector就不应该修改其中元素的数量,修改元素的值是可以的。
同时,如果希望通过C API初始化容器可以先将对应的数据拷贝到vector中,然后根据vector构建对应的容器总是可行的。
17 使用swap除去多余的容量
使用swap可以完成一些特定的任务:
- 原本容器尺寸比较大,现在希望缩减容器的尺寸,
vec.swap(ret),该操作并不保证总能去除所有多余的空间,但是总是能够保证缩减尺寸; - 清空容器并将容器缩小为最小容量,
string().swap(str)。
18 避免使用vector<bool>
由于vector<bool>的实现是利用bit紧促实现的,导致我们无法像正常操作vector那样获取单个元素的地址(因为bit不能取地址),因此在使用vector<bool>时需要注意这些。如果希望像使用普通容器那样使用vector<bool>可以使用deque<bool>或者使用bitset。
三 关联容器
19 理解等价和相等的区别
STL中有两种判断两个元素的值是否相等的方法:
- 基于相等(以``find
算法为代表)。它是以operator==```为基础; - 基于等价(以
set::insert),默认以operator<为基础(!(w1<w2) && !(w2<w1))。
!c.key_comp()(x, y) && !c.key_comp()(y, x)
20 为包含指针的关联容器指定比较类型
不提供的话,容器会使用默认的比较函数比较指针的地址值,导致关联容器中元素的存储顺序是按照地址大小存储的。
21 总是让比较函数在相等的情况下返回false
由于关联容器中比较元素是看元素是否等价,而等价是基于<的,如果比较函数在相等的情况下返回true,就会导致表达式!(w1 < w2) && !(w2 < w1)变成!(w1 <= w2) && !(w2 <= w1),原本相等的元素变成不相等。比如下面的代码会导致set的size是2(vs环境下会直接abort)。
set<int, less_equal<int>> s;
s.insert(1);
s.insert(1);
printf("size = %d\\n", s.size());
因此在自定义比较函数时,记住比较函数的返回值表明按照比较函数给定的顺序,一个元素是否在另一个元素之前。对于相等的情况总是返回false不会出问题。
22 切勿修改set或者multiset中的键值
map和multimap的key是const的因此如果修改是无法通过编译的,但是对于set和multiset标准委员会并未要求其key是const,因此对于不同的STL实现是有可能修改set的key的。如果你需要修改你应该明白,修改会导致代码不具备可移植性的同时破坏容器的结构。(我自己测试发现vs和gcc的set stl实现的迭代器返回的都是const)。
由于C++提供了const_cast也就意味着你可以强制修改,如果需要修改,需要正确的修改(如下示例)。
auto it = s.find(i);
if(it != s.end())
const_cast<Object&>(*it)->changeValue(1);
下面的代码在vs下回abort,而gcc能能够正常编译运行。
class object
public:
int val;
void setValue(int v)
val = v;
bool operator==(const object &ob)
return val == ob.val;
bool operator<(const object &ob)
return val < ob.val;
;
int main()
set<object> s;
object ob;
ob.setValue(1);
const_cast<object&>(*s.begin()).setValue(2);
printf("size = %d\\n", s.begin()->val);
//system("pause");
23 考虑使用排序的vector替代关联容器
- 场景中在查找元素的中途还要插入元素,则使用关联容器比较高效;
- 场景中容器一旦配置完成很少修改,只需要查找时使用排序的
vector更加高效。
对于关联容器由于其实现是RBTree就导致容器存储的节点包含多个额外的指针,当元素比较多是这些额外的指针就导致比存储同样数据的vector占用更大的内存,占用更大的内存可能导致数据跨页存储,导致缺页错误。
vector总是能够保证数据的连续性,但是关联容器的节点并不总是能够保证,导致数据存储可能不集中更加容易触发缺页错误。
24 当效率至关重要时,请在map::operator[]与map::insert之间谨慎做出选择
向关联容器中插入或者更新元素时,可以使用insert或者[],它们都会检查容器中是否包含对应的元素如果包含则更新元素,如果不包含则插入。
对于插入容器中不存在的值,使用[]等价于,首先创建一个对象,返回对象的引用,然后更新对象的值。而直接调用insert会直接根据值构造对应的对象。
m[1] = 1;
//等价于
typedef map<int, object> objectmap;
pair<objectmap::iterator, bool> ret = m.insert(objectmap::value_type(1, object()));
ret.first->second = 1;
//insert
m.insert(objectmap::value_type(1, 1));
对于更新容器中的值,[]操作直接更新,而insert需要构造一个pair和对应的对象,并包含临时对象的析构和pair的析构。
m[k]=v;
m.insert(objectmap::value_type(k, v));
因此对于插入容器中不存在的元素使用insert更加高效;更新容器中存在的元素使用[]更加高效。
25 熟悉非标准的散列容器
了解并使用hash_set,hash_multiset,hash_map和hash_multimap。
四 迭代器
26 iterator优先于const_iterator、reverse_iterator以及const_reverse_iterator
从下面的图中能够看出iterator总是能够通过一些方式转换成const_iteator、reverse_iterator或者const_reverse_iterator,而反之不一定。
在使用迭代器时尽量使用iterator能够避免一些因为STL不良实现而导致的潜在问题。最直接解决问题的方式是避免混用不同类型的迭代器。
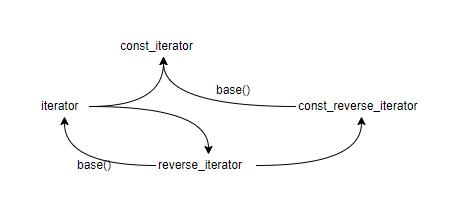
27 使用distance和advance将容器的const_iterator转换成iterator
条款26中提到尽量避免混用迭代器,但是有些场景中可能无法避免,此时可以使用distance或者advance将const_iterator转换成iterator,用法是advance(i, distance(i, ci))。该方式的效率取决于使用的迭代器,如果是随机访问迭代器,则是O(1),如果是双向迭代器则是O(n)的时间复杂度。
28 正确理解由reverse_iterator的base()成员函数所产生的的iterator的用法
对于以下代码,base()返回的迭代器并不是像我们期望的那样,而是指向了下一个元素,因此在使用base()获取迭代器是需要记得改特性。
vector<int> vec = 1,2,3,4,5 ;
auto it = find(vec.rbegin(), vec.rend(), 3);
printf("rvalue = %d, value = %d\\n", *it, *it.base()); //rvalue = 3, value = 4
29 对于逐个字符输入考虑istreambuf_iterator
istreambuf_iterator相比于istream_iterator能够处理所有字符(不忽略空字符),并且效率要高一些。
五 算法
30 确保目标区间足够大
如果在操作容器时能够预知操作的大小,使用reverse()对容器扩容能够减少内存分配带来的性能损耗。
31 了解各种与排序相关的选择
- 如果需要对
vector、string、deque或者数组中的元素执行一次完全排序,那么可以使用sort或者stable_sort。 - 如果有一个
vector、string、deque或数组,并且只需要对等价性最前面的n个元素进行排序,可以使用partial_sort。 - 如果有一个
vector、string、deque或数组,并且需要找到第n个位置上的元素,或者,需要找到等价性最前面的n个元素但又不必对着n个元素进行排序,那么可以使用nth_element。 - 如果需要将一个标准序列容器中的元素按照是否满足某个特定的条件区分开来,那么可以使用
partition和stable_partition。 - 如果数据在一个
list中,那么仍然可以调用partition和stable_partition算法;可以利用list::sort来替代sort和stable_sort算法。
除此之外,也可以通过标准的关联容器来保证容器中的元素时钟保持特定的顺序。
32 如果确实需要删除元素,则需要在remove这一类算法之后调用erase
remove只是将不需要删除的元素前移,也就是元素虽然删除了但是并不会对容器缩容,因此如果要删除需要使用erase真正删除。类似效果的还有remove_if和unique。
vector<int> vec = 1,4,3,4,5 ;
for (auto &&val : vec)
printf("%d\\t", val);
printf("\\n");
//1 4 3 4 5
//1 3 5 4 5
remove(vec.begin(), vec.end(), 4);
for (auto &&val : vec)
printf("%d\\t", val);
printf("\\n");
33 对包含指针的容器使用remove这一类算法时要特别小心
remove并不会析构对象,而是使用赋值替换对象,如果有指针,可能会出现指针丢失造成内存泄漏。一个可行的方案是使用智能指针。
34 了解哪些算法要求使用排序的区间作为参数
STL中那些要求排序区间的STL算法:
binary_search;lower_bound;upper_bound;equal_range;set_union;set_intersection;set_difference;set_symmetric_difference;merge;inplace_merge;includes;
binary_search、lower_bound、upper_bound和equal_range这些算法并不都能够保证log(n)的时间复杂度,只有在接受随机访问迭代器时才能保证。
set_union、set_intersection、set_difference和set_symmetric_difference这4个算法提供了线性时间效率的集合操作。
merge和inplace_merge实际上实现了合并和排序的联合操作:它们读入了两个排序的区间,然后合并成一个新的排序区间。线性时间。
includes用来判断一个区间中的所有对象是否都在另一个区间中。
unique和unique_if与上述讨论过的算法有所不同,它们即使对于未排序的区间也有很好的行为。
35 通过mismatch或lexicographical_compare实现简单的忽略大小写的字符串比较
// 忽略大小写地比较字符c1和c2,如果c1<c2,返回-1;如果c1>c2,返回1;如果c1==c2,返回0
int ciCharCompare(char c1, char c2)
int lc1 = std::tolower(static_cast<unsigned char>(c1));
int lc2 = std::tolower(static_cast<unsigned char>(c2));
if (lc1 < lc2) return -1;
if (lc1 > lc2) return 1;
return 0;
int ciStringCompareImpl(const std::string& s1, const std::string& s2)
typedef std::pair<std::string::const_iterator, std::string::const_iterator> PSCI;
PSCI p = std::mismatch(s1.begin(), s1.end(), s2.begin(), std::not2(std::ptr_fun(ciCharCompare)));
if (p.first == s1.end()) // 如果为true,要么s1和s2相等,或者s1比s2短
if (p.second == s2.end()) return 0;
else return -1;
return ciCharCompare(*p.first, *p.second); // 字符串之间的关系和这两个不匹配的字符之间的关系相同
int ciStringCompare(const std::string& s1, const std::string& s2)
// 把短的字符串作为第一个区间传入
if (s1.size() <= s2.size()) return ciStringCompareImpl(s1, s2);
else return -ciStringCompareImpl(s2, s1);
// 返回在忽略大小写的情况下,c1是否在c2之前
bool ciCharLess(char c1, char c2)
return std::tolower(static_cast<unsigned char>(c1)) <
std::tolower(static_cast<unsigned char>(c2));
bool ciStringCompare2(const std::string& s1, const std::string& s2)
return std::lexicographical_compare(s1.begin(), s1.end(), s2.begin(), s2.end(), ciCharLess);
bool ciStringCompare3(const std::string& s1, const std::string& s2)
// 前提:不考虑国际化支持,也确定字符串中不会包含内嵌的空字符
return strcmp(s1.c_str(), s2.c_str());
int test_item_35()
std::string str1 "xxz" , str2 "xxx" ;
fprintf(stdout, "str1:str2: %d\\n", ciStringCompare(str1, str2));
fprintf(stdout, "str1:str2: %d\\n", ciStringCompare2(str1, str2));
fprintf(stdout, "str1:str2: %d\\n", ciStringCompare3(str1, str2));
return 0;
36 理解copy_if算法的正确实现
c++11已经支持copy_if。
37 使用accumulate或者for_each进行区间统计
传给accumulate尽量不要带有副作用,即不要带状态。
class printer
public:
void operator()(const int val)const
printf("%d\\t", val);
;
int main()
vector<int> vec = 1,4,3,4,5 ;
auto ret = accumulate(vec.begin(), vec.end(), 0);
for_each(vec.begin(), vec.end(), printer