回顾IDEA 开发 SparkSQL 基础编程
Posted 骑着蜗牛ひ追导弹'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了回顾IDEA 开发 SparkSQL 基础编程相关的知识,希望对你有一定的参考价值。
文章目录
1、添加依赖
当前热门的开发编辑器当属 IDEA 了,接下来介绍一下在该款开发工具中的使用。
首先我们需要为Spark-SQL模块导入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
在原有的pom.xml的基础上更新一下即可!(完整配置连接如下,永久有效哦)😎😎😎
提取连接: https://pan.baidu.com/s/1o1px2DBN5AEWDtouxlUhRw
提取码:eirr
2、代码实现
2.1 构建环境
不同于spark-core,在其基础之上,spark-sql内置封装了新的入口SparkSession。起初,SparkSQL创建了两个入口:SQLContext、HiveContext。之后为了解决入口不统一的问题,创建了一个新的入口节点 — SparkSession,作为整个Spark生态工具的统一入口节点,包括了SQLContext、HiveContext、SparkContext等组建的功能。
注意:
- SparkSession的创建需要借助伴生类的
Builder()进行创建,因为原始的SparkSession是私有封装,外部无法直接访问。

object Spark01_sql_test
def main(args: Array[String]): Unit =
// TODO: 创建sparkSession的运行环境
val conf = new SparkConf().setMaster("local[*]").setAppName("test")
val spark = new SparkSession.Builder().config(conf).getOrCreate()
// TODO:逻辑操作
......
// TODO:关闭资源
spark.stop()
2.2 DataFrame的创建
1、构建json数据文件
"username":"张三","age": 25,"sex":"男"
"username":"李四","age": 23,"sex":"男"
"username":"王五","age": 24,"sex":"女"
"username":"赵六","age": 22,"sex":"男"
2、获取数据
- 通过
spark.read从文件中获取的数据集会被自动保存为DataFrame类型的数据。
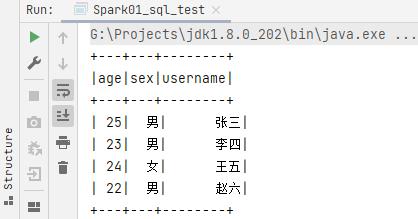
val df: DataFrame = spark.read.json("data/user.json")
df.show()
3、SQL语法
- 在
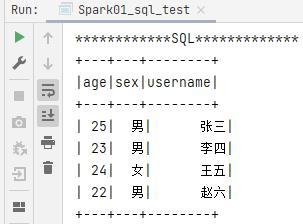
创建好数据的视图表之后,直接使用spark.sql执行sql语句
println("************SQL*************")
// SQL
df.createOrReplaceGlobalTempView("user")
spark.sql("select * from global_temp.user").show()
4、DSL语法
- 使用spark封装的
sql 语法API进行具体操作 - 注意要导入隐式转换:
import spark.implicits._
println("************DSL*************")
// DSL
import spark.implicits._ // 隐式转换
df.select('username,$"age",'sex).show()

2.3 DataSet的创建
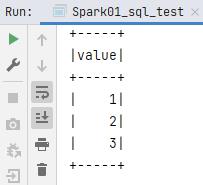
// TODO:DataSet
val seq = Seq(1,2,3)
val ds = seq.toDS()
ds.show()
查看底层可以知道:type DataFrame = Dataset[Row],也就是DataFrame是DataSet指定类型的一种数据对象,所以DataFrame适用的方法DataSet也均适用。
2.4 RDD & DataFrame
// TODO:RDD <=> DataFrame
// 创建rdd
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(
List(
(1,"zhangsan",30),(2,"lisi",25),(3,"wangwu",40)
)
)
// toDF 转为 DataFrame
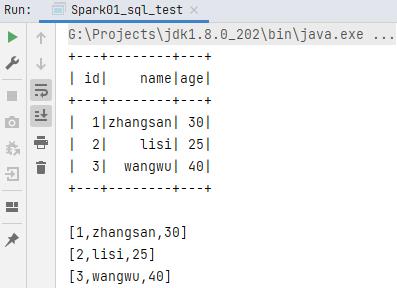
val df: DataFrame = rdd.toDF("id","name","age")
df.show()
// df.rdd 转为 rdd:RDD[Row]
val backRDD: RDD[Row] = df.rdd
backRDD.collect().foreach(println)
2.5 RDD & DataSet
// TODO:RDD <=> DataSet
// 创建RDD
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(
List(
(1, "zhangsan", 30), (2, "lisi", 25), (3, "wangwu", 40)
)
)
// 转换RDD的数据类型
val mapRDD: RDD[user] = rdd.map
case (id, name, age) =>
user(id, name, age)
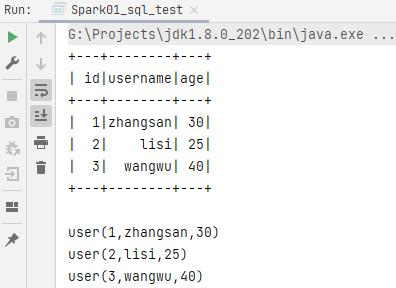
// toDS 转为 DataSet
val toDS: Dataset[user] = mapRDD.toDS()
toDS.show()
// ds.rdd 转为 rdd
val backRDD = toDS.rdd
backRDD.collect().foreach(println)
2.5 DataFrame & DataSet
- DataFrame 转换为 DataSet 需要给出明确的数据结构类型信息,这里我们创建user样例类作为DataFrame的数据结构类型补充。
// 样例类
case class user(id:Int,username:String,age:Int)
// TODO:DataFrame <=> DataSet
val ds: Dataset[user] = df.as[user]
val backDF: DataFrame = ds.toDF()
以上是关于回顾IDEA 开发 SparkSQL 基础编程的主要内容,如果未能解决你的问题,请参考以下文章