ACL学习
Posted 龚喜发财+1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ACL学习相关的知识,希望对你有一定的参考价值。
文章目录
DPDK提供了三种classify算法:最长匹配LPM、精确匹配(Exact Match)和通配符匹配(ACL)
一.Access control list
DPDK 提供了一个访问控制库,可以根据一组分类规则对输入数据包进行分类。
ACL 库用于对具有多个类别的一组规则执行 N 元组搜索,并为每个类别找到最佳匹配(最高优先级)。库 API 提供以下基本操作:
- 创建新的访问控制 (AC) 上下文。
- 将规则添加到上下文中。
- 对于上下文中的所有规则,构建执行数据包分类所需的运行时结构。
- 执行输入数据包分类。
- 销毁 AC 上下文及其运行时结构并释放相关内存。
1.规则定义
1.1定义匹配区域 rte_acl_field_def
当前的实现允许用户为每个 AC 上下文指定其自己的规则(字段集),将在其上执行数据包分类。尽管规则字段布局几乎没有限制:
规则定义中的第一个字段必须是一个字节长。所有后续字段都必须分组为 4 个连续字节的集合。这样做主要是出于性能原因 - 搜索函数将第一个输入字节作为流设置的一部分进行处理,然后展开搜索函数的内部循环以一次处理四个输入字节。
ACL规则主要面向的是IP流量中的五元组信息,即IP/PORT/PROTO(源ip,目标ip,源端口,目标端口,传输层协议),算法在这个基础上进行了抽象,提供了三种类型的匹配区域:
RTE_ACL_FIELD_TYPE_BITMASK:单字节区域如ip头部一个字节的proto字段;
RTE_ACL_FIELD_TYPE_MASK:采用MASK方式描述,一般对应4字节的源/目的地址;
RTE_ACL_FIELD_TYPE_RANGE:一般对应TCP或UDP头部2字节的PORT区域。
熟悉这三种类型的使用后,完全可以用它们去匹配网络报文的其它区域,甚至将其应用到其它场景中。
要定义 AC 规则内的每个字段,使用以下结构:
struct rte_acl_field_def
uint8_t type; /*< type - ACL_FIELD_TYPE. */
uint8_t size; /*< size of field 1,2,4, or 8. */
uint8_t field_index; /*< index of field inside the rule. */
uint8_t input_index; /*< 0-N input index. */
uint32_t offset; /*< offset to start of field. */
;
- type 字段类型是以下三种选择之一:
_MASK - 用于具有定义相关位数的值和掩码的 IP 地址等字段。
_RANGE - 用于字段,例如具有该字段的下限值和上限值的端口。
_BITMASK - 用于具有值和位掩码的协议标识符等字段。 - size size 参数以字节为单位定义字段的长度。允许的值为 1、2、4 或 8 个字节。请注意,由于输入字节的分组,必须将 1 或 2 字节字段定义为组成 4 个连续输入字节的连续字段。此外,最好将 8 字节或更多字节的字段定义为 4 字节字段,以便构建过程可以消除所有字段。
- field_index 一个从零开始的值,表示该字段在规则内的位置;N 个字段的 0 到 N-1。
- input_index 如上所述,所有输入字段,除了第一个,必须以 4 个连续字节为一组。输入索引指定该字段属于哪个输入组。
- offset offset 字段定义了字段的偏移量。这是从用于搜索的缓冲区参数开始的偏移量。
struct rte_acl_field_def ipv4_defs[5] =
/* first input field - always one byte long. */
.type = RTE_ACL_FIELD_TYPE_BITMASK,
.size = sizeof (uint8_t),
.field_index = 0,
.input_index = 0,
.offset = offsetof (struct ipv4_5tuple, proto),
,
/* next input field (IPv4 source address) - 4 consecutive bytes. */
.type = RTE_ACL_FIELD_TYPE_MASK,
.size = sizeof (uint32_t),
.field_index = 1,
.input_index = 1,
.offset = offsetof (struct ipv4_5tuple, ip_src),
,
/* next input field (IPv4 destination address) - 4 consecutive bytes. */
.type = RTE_ACL_FIELD_TYPE_MASK,
.size = sizeof (uint32_t),
.field_index = 2,
.input_index = 2,
.offset = offsetof (struct ipv4_5tuple, ip_dst),
,
/*
* Next 2 fields (src & dst ports) form 4 consecutive bytes.
* They share the same input index.
*/
.type = RTE_ACL_FIELD_TYPE_RANGE,
.size = sizeof (uint16_t),
.field_index = 3,
.input_index = 3,
.offset = offsetof (struct ipv4_5tuple, port_src),
,
.type = RTE_ACL_FIELD_TYPE_RANGE,
.size = sizeof (uint16_t),
.field_index = 4,
.input_index = 3,
.offset = offsetof (struct ipv4_5tuple, port_dst),
,
;
此类 IPv4 5 元组规则的典型示例如下:
source addr/mask destination addr/mask source ports dest ports protocol/mask
192.168.1.0/24 192.168.2.31/32 0:65535 1234:1234 17/0xff
任何具有协议 ID 17 (UDP)、源地址 192.168.1.[0-255]、目的地址 192.168.2.31、源端口 [0-65535] 和目的端口 1234 的 IPv4 数据包都符合上述规则。
1.2定义具体规则 acl_ipv4_rule
a)对于每一个field给出明确的定义
比如定义了5个field,那么请给出每一个的具体定义:
.field[0] = .value.u8 = 0, .mask_range.u8 = 0x0,,
.field[1] = .value.u32 = IPv4(0, 0, 0, 0), .mask_range.u32 = 0,,
.field[2] = .value.u32 = IPv4(192, 168, 2, 4), .mask_range.u32 = 32,,
.field[3] = .value.u16 = 0, .mask_range.u16 = 0xffff,,
.field[4] = .value.u16 = 1024, .mask_range.u16 = 0xffff,,
像field[1]中IP和mask都为0,表示匹配所有的IP地址;field[3]中range由0到65535,表示匹配所有。类似这样的全匹配一定要显示的定义出来,因为如果不明确定义,这些字段的值取决于编译器的,最后编译的ACL规则很可能与原有设想存在偏差。
b)field的全匹配方式
如果在规则中,对于某个field不进行限制,对于不同type的field,规则书写时有一定差异:
对于BITMASK和MASK类型,全0代表匹配所有,如上例中的field[0]、field[1];
对于RANGE,则按照上述field[3]中的形式定义。
2.trie树的构造
规则定义好后,会转换为trie树并最终合并到一起。
实际处理过程中,build_trie函数会自底向上的将rule中的每个field转换为node,然后将这些node合并生成这条rule的trie,最后将这个trie与已有的trie进行merge,最终生成整个rule set的trie。
2.1 node数据结构
tire由node组成,其主要数据成员如下:
struct rte_acl_node
struct rte_acl_bitset values;
uint32_t num_ptrs; /* number of ptr_set in use */
struct rte_acl_ptr_set *ptrs; /* transitions array for this node */
int32_t match_flag;
struct rte_acl_match_results *mrt; /* only valid when match_flag != 0 */
uint64_t node_index; /* index for this node */
int32_t match_index; /* index to match data */
uint32_t node_type;
int32_t fanout;
union
char transitions[RTE_ACL_QUAD_SIZE];
/* boundaries for ranged node */
uint8_t dfa_gr64[RTE_ACL_DFA_GR64_NUM];
;
;
node中values成员用于记录匹配信息,ptrs则用于描述node的出边,用于指向转换后的node。
values采用bitmap进行压缩,其数据结构为struct rte_acl_bitset values; 一个byte取值范围是[0,255],可通过256个bit位来进行对应,并实现byte值的快速查找:即通过第x位的bit值是否为1来判断是否包含数值x(0 <= x < 256)。
bitmap参考:https://www.cnblogs.com/cjsblog/p/11613708.html
num_ptrs用于描述出边数目,ptrs即为实际的出边,它记录了其匹配值values和匹配后的节点指针。
match_flag和mrt则用于记录匹配结果,trie树中叶子节点一定是记录匹配结果的节点。
trie树其详细结构比较复杂,这里将其结构进行简化,如下所示:
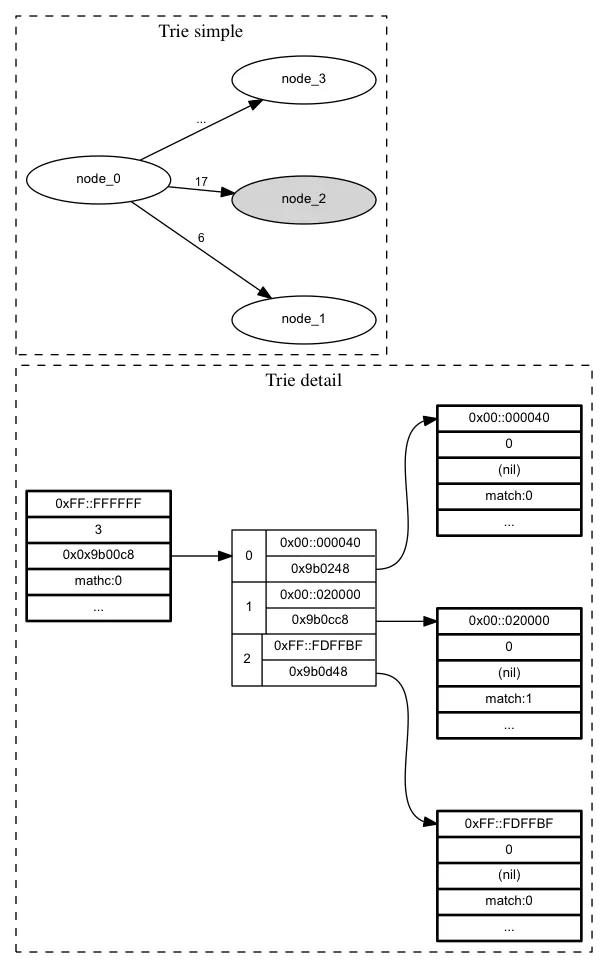
上图的trie树有4个node,通过ptrs进行指向,values字段为匹配值的bitmap表示,为了表述的简洁,后续会采用simple的方式进行描述。
在trie simple中,实心节点表示匹配节点,边上的数字代表匹配值(为便于阅读,采用实际值而不再是bitmap形式),…代表其它匹配值。
2.2 由field到node
不同type的field,转换为node的方式会有所不同。
目前提供的3种类型:BITMASK描述一个byte的匹配,支持mask模式;MASK用于描述4个byte的匹配,支持mask模式;RANGE描述2个byte的匹配,此时mask表示上限。
field到node的转换,见build_trie中的for循环,具体转换函数则参考:
acl_gen_mask_trie和acl_gen_range_trie
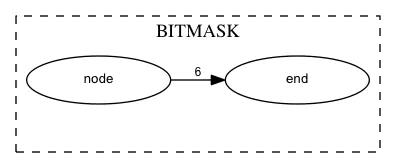
对于BITMASK,如.value.u8 = 6, .mask_range.u8 = 0xff,,它最后的转换形式如下:
对于MASK,如.value.u32 = IPv4(192, 168, 2, 4), .mask_range.u32 = 32,,它会转换为如下形式:

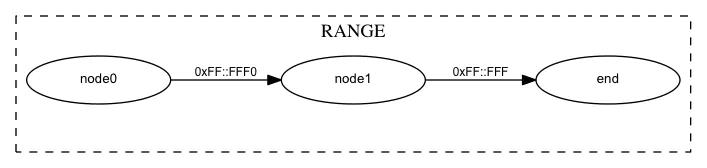
对于RANGE,如.value.u16 = 1024, .mask_range.u16 = 0xffff,,它会转换为如下形式:
2.3由field到rule trie
构造field的node时,总会在结尾添加一个空的end节点,最后一个field除外(它是match node)。在for循环中每完成了一个field的解析后,会将其合并到root中,从而生成这个rule的trie。
合并前,也会先构造一个空的end node(见build_trie函数中,while循环下的root创建),让它与field构成的node头合并,因为不相交,所以merge时会将匹配信息合并到end node并释放原有的头,并将field链的end节点返回(保存到end_prev中),下次合并时,就用此end节点与新的node头合并。
循环遍历完所有的field后,这些node就串联起来了,构成这个rule的trie。
root = acl_alloc_node(context, 0);
root->ref_count = 1;
end = root;
for (n = 0; n < rule->config->num_fields; n++)
field_index = rule->config->defs[n].field_index;
fld = rule->f->field + field_index;
end_prev = end;
...
/* merge this field on to the end of the rule */
if (acl_merge_trie(context, end_prev, merge, 0,
NULL) != 0)
return NULL;
参考:https://www.jianshu.com/p/0f71f814d73e
以上是关于ACL学习的主要内容,如果未能解决你的问题,请参考以下文章