记录一次生产环境Net Core应用内存暴涨导致OOM的排查过程
Posted 娃都会打酱油了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一次生产环境Net Core应用内存暴涨导致OOM的排查过程相关的知识,希望对你有一定的参考价值。
事情起源于某个周五,刚开始是突然发现生产服务不能访问,请求时居然直接提示服务器拒绝响应,然后连用于管理生产环境的Portainer虽然能打开,但登录右上角直接出红色告警信息无法接收服务器信息,进去后所有的node都不显示!生产环境跑了二年多了,还是第一次出现这种异常情况,既然一头雾水不知道啥情况,那IT维护的绝活重启大法必须得用起来啊,麻溜的sudo systemctl restart docker命令一出,整个docker重启完毕后,世界立刻恢复如常。
相安无事的度过了完美的周末,周一过来,屁股刚坐下,就又有反馈过来,应用又不能访问了!这奇了怪了,虽然这个应用只是数据汇总类应用,应用的访问频率不怎么高,但终究还是一个比较重要的应用,而且尝试访问时,包括请求Portainer时,服务器的响应结果都与之前那次一模一样,明显这不是偶发现象,需要分析究竟是什么原因导致该问题的,当然分析之前还是重启大法先用起来,但这次似乎有些不一样,重启过程中居然出现了异常提示
kernel:NMI watchdog: BUG: soft lockup - CPU#6 stuck for 22s! [kworker/u64:1:19446]
顿时让我这个半吊子Linux用户亚历山大,而且Git Bash中再输入指令,居然也卡死在那里没有任何输出响应,只能出更大的杀招,让IT帮忙把服务器重启!
IT反馈服务器已重启后,首先上去访问下应用是否可以正常访问,结果这次居然服务还是不能访问,再访问Portainer,结果居然连Portainer也不能访问!这又是啥幺蛾子?尝试在Git Bash再次登录服务器,这次能正常登陆,尝试df -h指令查看空间,服务器也能正常响应,看样子服务器的确重启过,再用docker ps查看下运行的容器情况,一眼看过去貌似也都正常,容器的启动时间也与服务器时间基本一致,都是在几分钟之内,所以问题究竟在哪呢?
仔细想想,我们的服务是通过nginx进行请求转发的,包括我们的Portainer也是,所以是不是该看看Nginx服务是否正常?docker ps -f name=nginx指令一查,啥情况?居然没有!难道有人把这个service给删了?生产搞这事情,这还了得!心急火燎的把docker stack指令准备好,在执行前习惯性的用docker stack services Service_Name指令查看stack下service的运行情况,结果奇迹出现了,nginx服务在的,只是REPLICAS显示为0/1,service启动不起来!(其实一开始就应该用docker ps -a -f name=nginx指令的,-a能同时显示已关闭的Container)既然不是有人要做删库跑路的事情,那就一切安好,docker logs --tail=1000 Container_ID指令直接查看最新的1000条容器日志,果然发现问题了,提示是host not found in upstream,内容如下图(图是事后通过Portainer查看的,当时没截图)
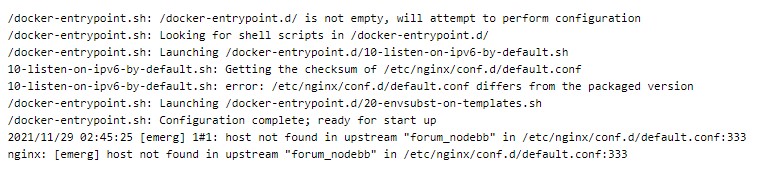
进入Nginx在服务的Volumn映射目录后,通过sudo cat default.conf查看配置,又有奇怪的事情了,居然没发现forum_nodebb这个upstream配置!仔细找了下,居然在反向代理部分发现了forum_nodebb,虽然不是很了解Nginx的机制,但理论上反向代理部分不应该会导致Nginx加载时解析失败啊?但不管怎样,跟相关同事确认了下这个forum_nodebb是否还在用,得到明确不在用的反馈后,直接sudo vim default.conf将相应部分全部注释并:wq保存后,docker service udpate Service_Name命令一出,根据命令结果确认Nginx服务已正确启动,浏览器中试下访问,服务正常响应。
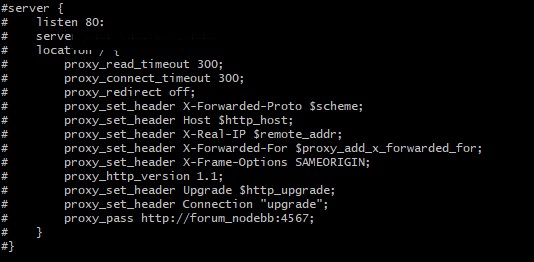
通过Portainer查看了下forum_nodebb这个service的状态,结果居然是少见的Dead状态,所以猜测是不是这个服务出了什么问题Container不断的重启,最终导致docker也出了问题?不管怎样,问题似乎解决了。
问题当然不可能解决,不然标题就不会是内存暴涨OOM了,是不是?第二天业务又反馈不能访问了,还是和之前一样,应用不能打开,Portainer提示无法接收服务器信息,都说事不过三,这究竟是啥问题呢?心有忐忑的用了下docker重启指令,还好没出现soft lockup,但看频率这事情每天都能发生一次,总不能每天都重启一次docker吧?而且也不知道服务器是什么时候崩溃的,崩溃到重启这段时间内的数据肯定也无法接收,这不就有可能导致数据丢失了吗,这怎么能行!
明知有问题,但又不知道究竟是什么原因导致的问题,这是最痛苦的!瞎折腾半天后,运维群内的一条告警信息引起了我的注意,这条信息是运维转发到该群的,而告警的服务器正是我们的生产服务器,告警内容是服务器内存使用率超过了90%,告警时间在我重启docker之前,虽然不确定该问题是否与我的问题有关联,但既然都是发生在同一台服务器上,总归是有一定的关联。通过top指令查看服务器内存和CPU的使用情况,居然Mongo服务占用内存有些高,但再高占用内存也就4G多点,按我们生产服务器64G内存的配置,会是Mongo的问题吗?
虽然有可能是Mongo的问题,但怎么确认呢?还是毫无头绪!突然想到既然每次都要重启docker才能解决问题,那我是不是可以去查看下docker本身的日志?通过sudo journalctl -u docker.service --since "2021-11-30 10:00:00" --until "2021-11-30 10:15:00",发现似乎有些错误信息

根据这个service.id,用docker service ls -f id=Container_ID查看下这是哪个服务

好巧不巧,居然也是Mongo,所以事情貌似都与这Mongo有关系,但怎么确定呢?通过查看Mongo的日志,似乎也没发现什么不正常的地方,哎,问题又回到了原点!
车到山前疑无路,柳暗花明又一村,无意中的一次docker ps,发现在没任何重启操作的情况下,居然有两个service是短时间内刚刚创建的,而且应该是docker swarm自动创建的

更关键的是这两个应用一个正好是Mongo,一个正好是主应用,docker swarm应该只有在容器异常退出时,才会自动创建新的容器,所以主应用是不是也有一定的问题?在Portainer中查看最后一份被关闭的容器日志,问题似乎有点发现
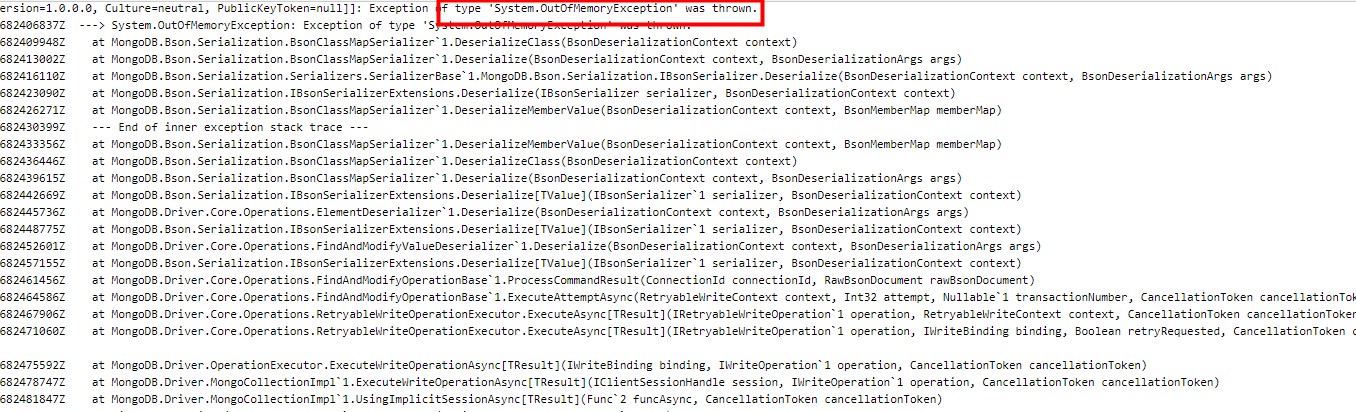
首先是发现在读取Mongo时,出现了OutOfMemoryException,但紧跟着发现还有好几个OutOfMemoryException
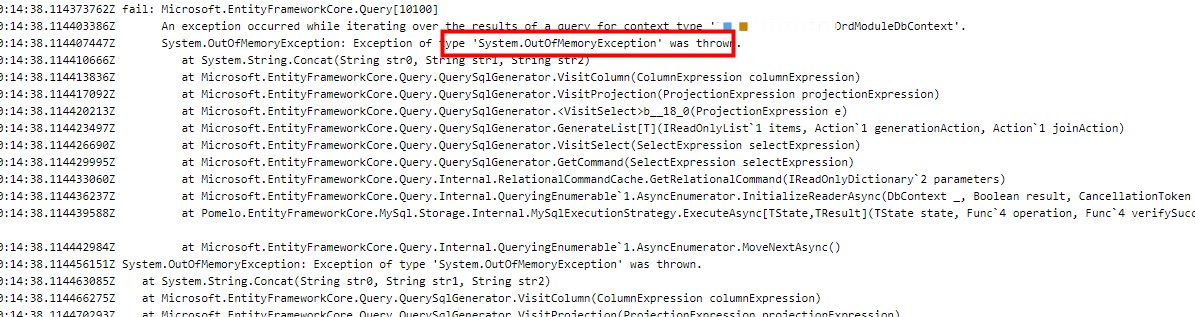
这次是跟EF有关了

这奇葩的居然jwt解析也OutOfMemoryException,明显是主应用的内存不够用了,导致大范围的OutOfMemoryException,最终导致容器OOM,也就是说主应用内存不够用,通过Portainer查看service的内存设置,发现只设置了3000MB,同样发现Mongo也被设置了5000MB的限制
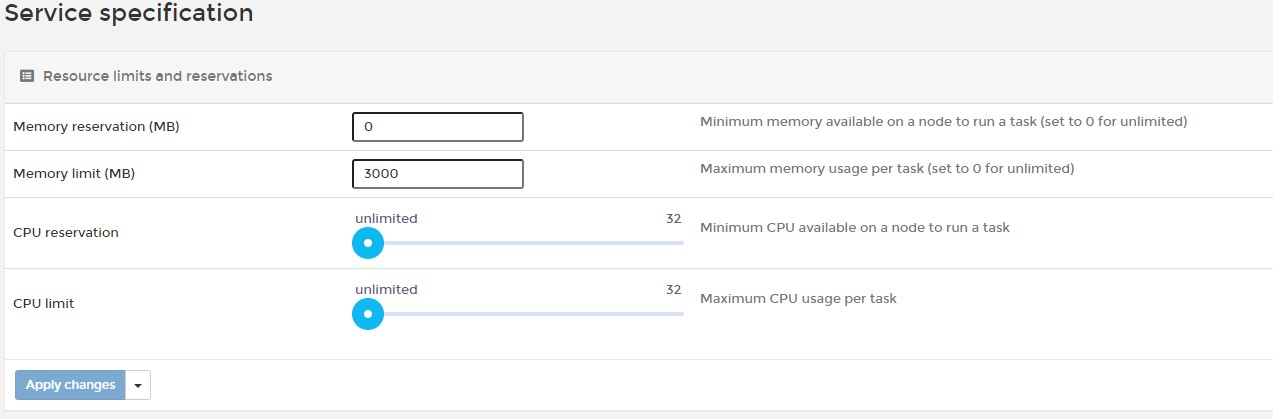
一般来说3G内存对.Net Core应用是足够使用了,而且这个设置应该也是很久以前就设置了的,为什么以前没出问题,最近才开始出问题呢?但不管怎样,首先肯定是将内存限制去掉,然后既然应用会因为OOM自动重启,而docker swarm反复创建新的容器可能会导致docker整个崩溃这也是之前曾经经历过的事情,所以现在需要监控下这两个应用的CPU和内存使用情况,通过Portainer的Containers菜单,在打开的界面中分别按service name进行搜索,并通过Quick actions的第三个图标打开监控界面
Mongo监控一段时间后的界面如下
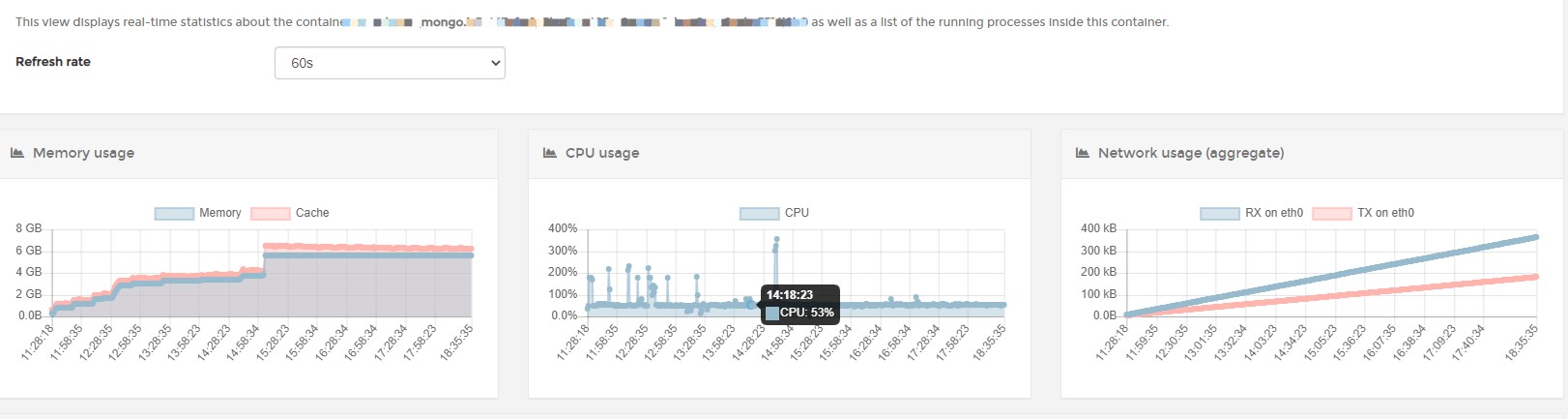
主应用监控一段时间之后的界面如下
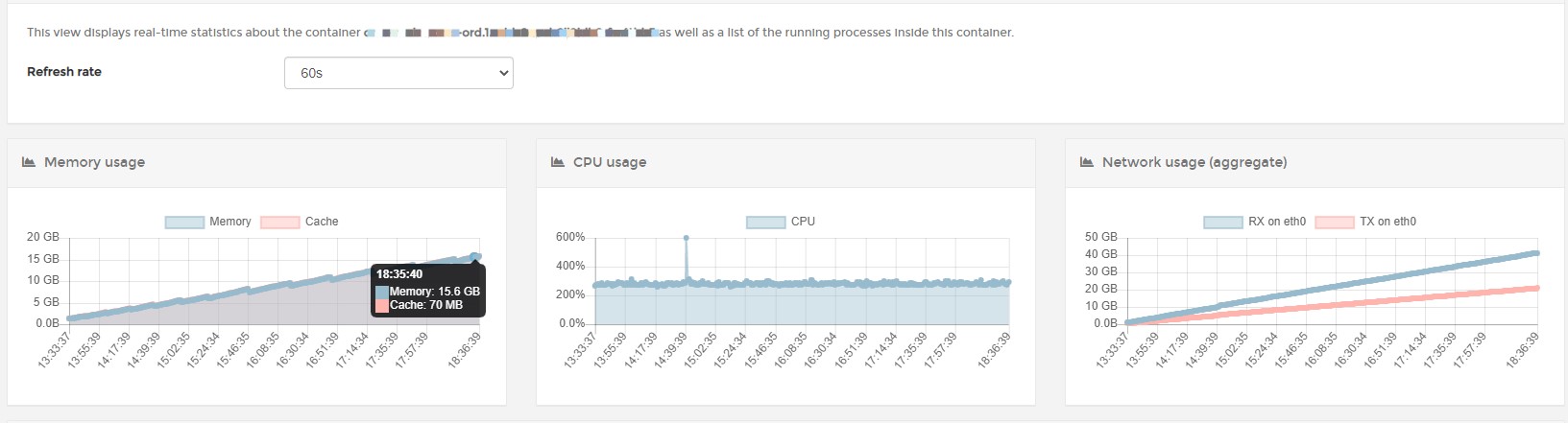
可以看到Mongo虽然内存会有增长,但增长到一定程度后就会稳定下来,反观主应用,在放开了内存限制之后,这增长真是一条直线稳定上涨,虽然目前我们应用不是WorkStation GC模式而是Server GC模式,但看内存的波动,应该也是有过GC行为,所以问题应该是有什么东西在不停的占用内存并且无法释放,一般来说这种问题抓dump进行分析才是正途,所以一开始我也是往这个方向上行动。
笑用网络上的流行语来总结:一顿操作猛如虎,一看输出0-10,资料查了一大堆
centeros 安装netcore sdk https://www.cnblogs.com/bob-zb/p/12761733.html
dotnet tool工具安装 https://www.cnblogs.com/chinasoft/p/14754778.html
docker容器文件复制到宿主机 https://blog.csdn.net/qq_31880107/article/details/86623307
lldb3.9.0 安装 https://www.cnblogs.com/calvinK/p/9263696.html
dump分析 https://www.cnblogs.com/panpanwelcome/p/14283807.html
结果生产环境docker版本不够,根本不具备抓dump的条件,要通过.Net Core自带的createdump抓取dump文件,需要给容器设置cap-add,而要执行docker service update --cap-add SYS_PTRACE Service_Name,则需要指定版本API 1.41+,好巧不巧我们生产环境的docker正好差了一个版本,而升级docker需要先卸载再安装,生产环境谁敢这么操作!不死心的我发现开发环境docker版本正好符合要求,于是又尝试在开发环境搞了一波,通过docker exec -it Container_ID /bin/sh进入容器,成功的把dump文件抓了下来,结果安装lldb时又失败了,yum install libunwind始终报Error: Unable to find a match: libunwind,无奈只能走人工分析一途。
按照.Net的GC机制,内存无法释放,要么是一直升代到gen2,要么是超大字符串超过85kb直接进gen2,根据git最近的代码更新记录反查代码,似乎没发现明显会导致内存占用无法释放的情况,所以问题改为全局搜索整个应用,根据GC标志的机制,要么是root也就是程序入口有引用,要么就是static变量在引用,要么就是Singleton注入服务有引用,还或者就是IDistributedCache用了MemoryCache,但排查下来,除了一个static变量可能有点问题,其它都没问题,而static变量改为非static发到生产后,内存一直上涨的情况还是存在!
虽然暂时没了方向,但问题产生的主要原因应该是已经明确了的。既然基本可以断定问题是出现在主应用上,那监控主应用的日志可能是个主意。通过日志,发现有大量Mongo的update操作日志,但这并不能说就是Mongo的问题。由于日志量刷新太快,于是考虑通过Nginx查看日志,通过关键字筛选,居然发现主应用上有大量请求在另一个地址上,Mongo更新的请求虽然也有,但与另一个请求比起来完全是小巫见大巫,那会不会是这个请求导致的问题呢?结果查看源码,发现这个API早就已经被删除,应该是其它调用程序没有同步删除该地址的调用,想来想去,反正也不知道问题究竟在哪,做减法得了,一个一个API进行排查总可以吧!在Nginx中先拦截了这个请求再说
location ~* ^/Request_URL
deny all;
在对应反向代理部分增加对该地址请求的deny后,想了想按业务时间来讲,Mongo的业务调用似乎也有点问题,因为这个时间不可能有人员在更新这部分数据,减法做到底,于是又把Mongo业务对应的请求地址也进行了deny,随后重启Nginx。为了更好的监控这次操作的效果,于是又把Mongo和主应用一起重启了下,随后重新开始监控。
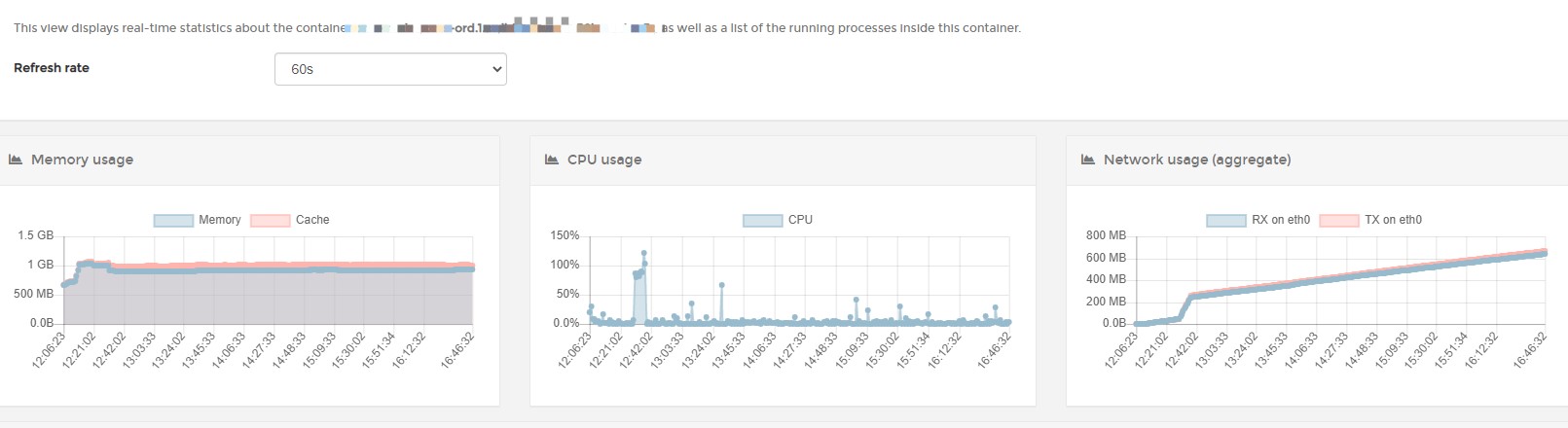
监控下来发现这次的deny效果居然不是一般的好,主应用CPU使用率居然直接降到了个位数,内存也一直稳定保持在1G左右,最神奇的是Network网络流量也降低了不是一点半点!考虑到非Mongo更新的请求是HttpGet请求,请求量大但也没达到DDos的程度,deny后应该不会对Network有这么大的影响,而且由于该请求地址实际已不存在,.Net core对于这种请求直接返回404,也不太可能对CPU能有这么大的影响,所以问题只可能是发生在Mongo更新的这个请求上!
注释掉对Mongo更新的deny,重启Nginx后,果然主应用的各种数据又开始异常增长!因为这次没有重启主应用,监控对比非常明显
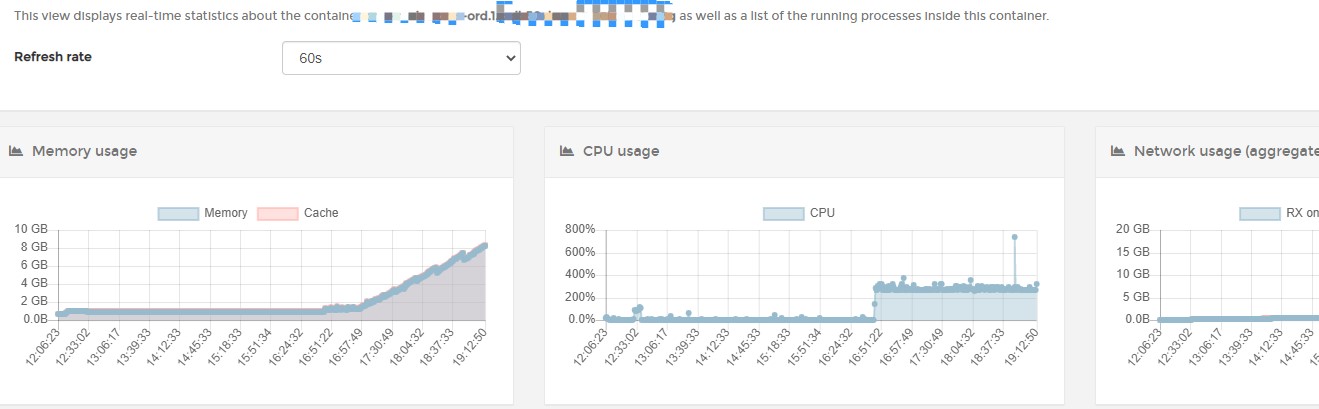
鉴于虽然Mongo的更新操作有日志,但日志不够精准,于是对相应的日志进行适当的调整优化,重新生成镜像发布到生产环境后(小公司有小公司的好啊,这种违规操作只有小公司才能做!),再通过关键字进行日志观察
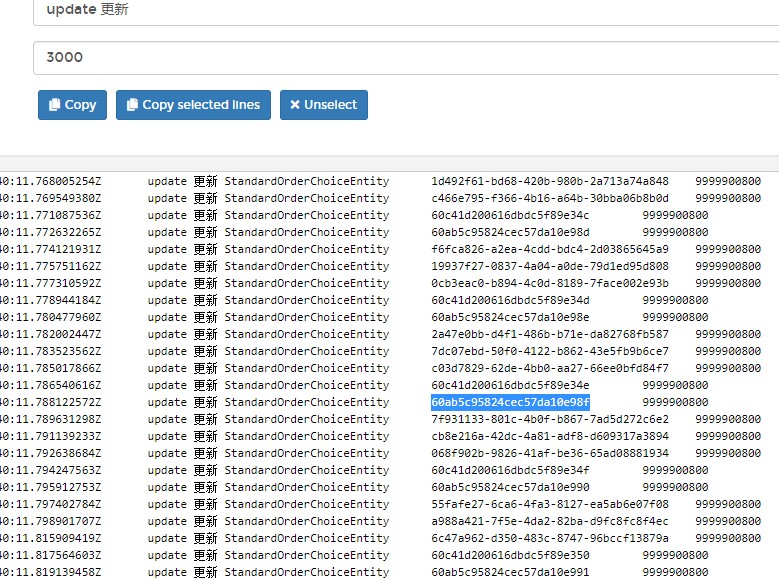
所有的更新居然都发生在毫秒级,这是什么鬼?百思不得其解,继续跟踪分析,发现所有的数据居然都来源于同一个请求端,再一阵监控,发现了更诡异的事情,日志似乎是重复的!于是以某条数据记录为锚点,进一步跟踪,发现的确是1分钟左右,该条记录的更新日志就会出现一次,再进一步去Mongo跟踪数据实体,发现两次更新的数据,除了更新时间,居然没有任何变化!?但为啥会这样呢,还是不知道,看样子需要跟调用方友好沟通下才行,在此之前还是继续deny该请求再说
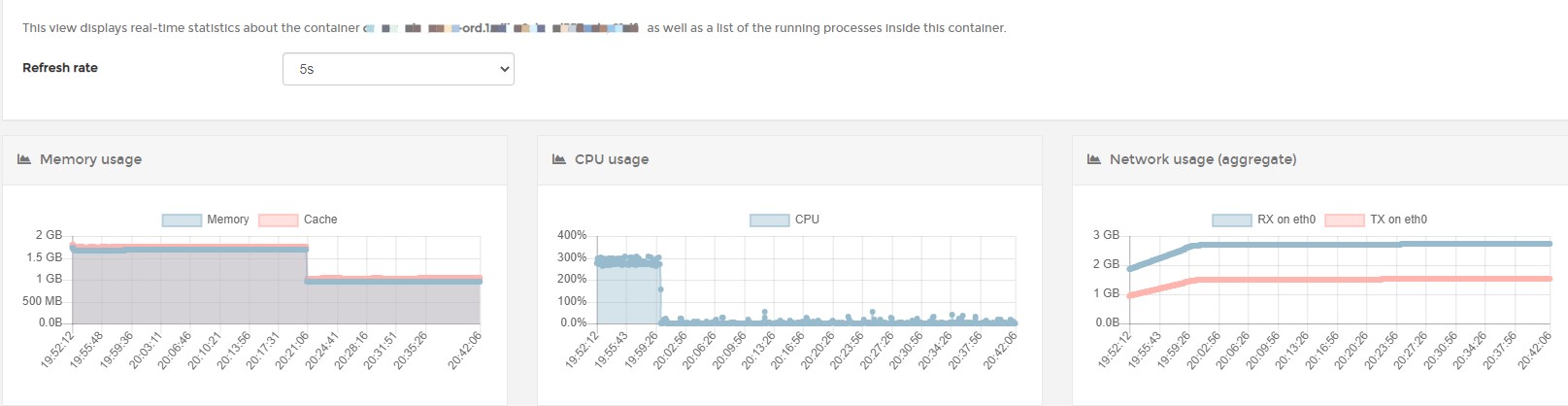
有点奇怪,Nginx在19:54重启deny,CPU居然没有立刻降下来,而是过了差不多到17:59才降下来,内存更是夸张到20:21才降了下来(前面有将应用改为了WorkStation GC模式)!查看日志,发现19:54之后,居然还有更新日志?明明已经没有请求了,为何还会有更新?
思前思后,结合前面日志观察到的毫秒级请求以及重复数据,突然灵光一闪,所有的问题一下子豁然开朗起来:应该是大量请求来不及处理,结合以前研究过Task的ThreadPoolTaskScheduler,所有的Task都会进入队列,来不及处理就会导致Task堆积,虽说Task堆积本身还不会导致这么大的问题,但好巧不巧,这些Task都是要执行更新操作,都顺带了一波请求数据,而这些数据因为Task的引用,GC是无法释放的,这就解释了为何内存会死命的增长!应该是Task堆积后,后续的API请求都timeout了,调用方的机制呢我也是有些了解,在请求失败后调用方为保证数据一定上传会定时重试,估计这重试频率呢就是1分钟,也就是说其实是同一批数据的更新请求,因为反复的调用,消费赶不上生产,服务器来不及处理导致Task一直堆积吃内存,最终导致OOM。再结合代码回查,因为这段代码没有使用CancellationToken,也就是说就算请求断开或者timeout了,服务器上也还是继续在处理堆积的Task,这样就解释了为何19:54已经没了请求,而服务器却直到19:59才降低了CPU使用率,因为这段时间服务器还在继续处理已经断开了的请求!
第二天与调用方沟通后,问题的原因就更明确了,因为该接口为批量更新接口,调用方每分钟调用一次批量更新500条数据,但超时时间设置的比较短,只有尴尬的5秒钟!实际5秒钟是绝对处理不完这500条数据的,在反复调整测试后,最终调整为批量每次更新100条记录,超时时间设置为40秒,同时服务端代码增加注入IHttpContextAccessor,通过判断RequestAborted来取消Task
if (httpContextAccessor.HttpContext.RequestAborted.IsCancellationRequested)
//记录取消日志
return;
最终监控到稳定更新完毕
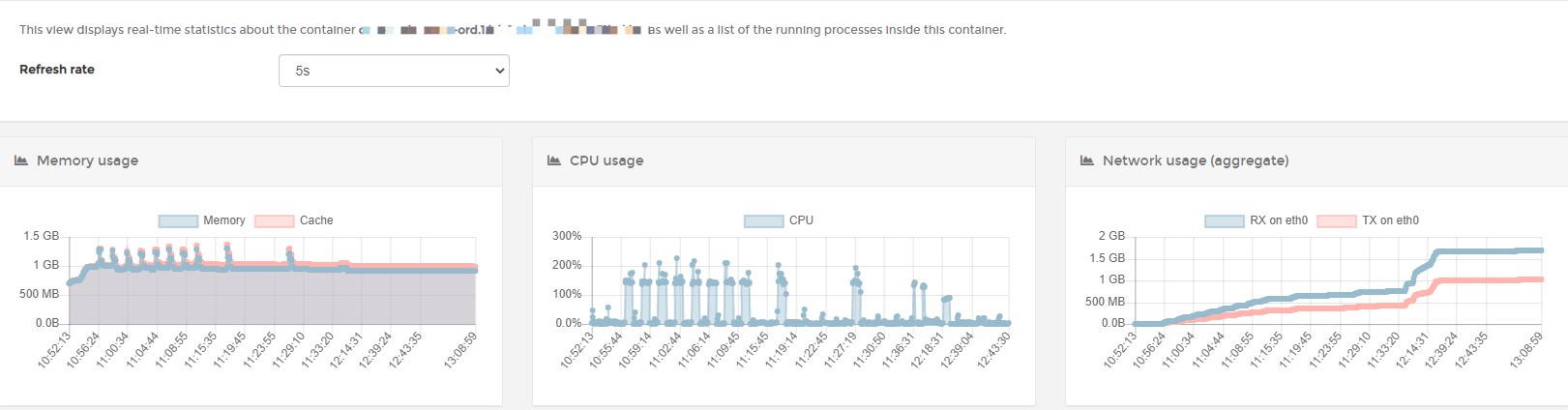
可以看到中间有几次波峰,根据调用方日志,前面几个波峰因为还在调整所以还是响应超时,但CancellationToken取消了后续的任务执行,所以内存也不会死命的上涨,此时再查看下日志,的确发现了取消日志,而最后两个波峰过后,数据已同步完毕,可以看到CPU使用率降低到个位数,Network网络流量也开始变成一条水平线。
以上是关于记录一次生产环境Net Core应用内存暴涨导致OOM的排查过程的主要内容,如果未能解决你的问题,请参考以下文章