Java集合与数据结构 Map 和 Set
Posted 头发都哪去了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合与数据结构 Map 和 Set相关的知识,希望对你有一定的参考价值。
Java集合与数据结构 Map和Set
搜索树
二叉搜索树又称二叉排序树,它或者是一棵空树**,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
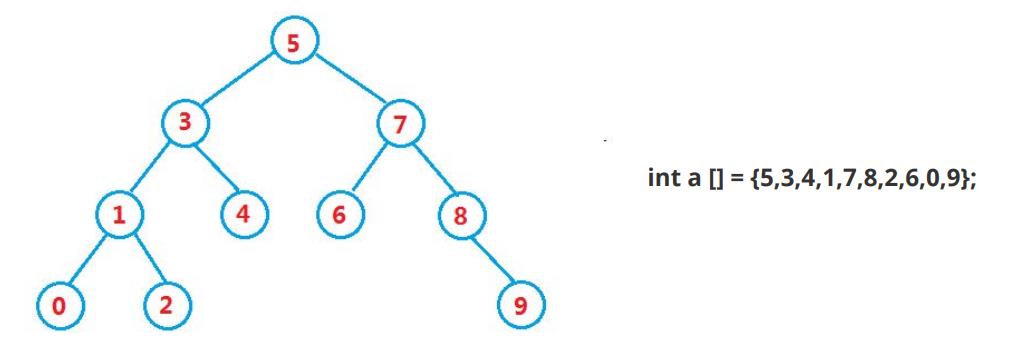
操作:查找、插入、删除
逻辑代码:
class BinarySearchTree
static class BSNode
public int val;
public BSNode left;
public BSNode right;
public BSNode(int val)
this.val = val;
public BSNode root = null;
/*
查找
*/
public BSNode search(int val)
if(root == null) return null;
BSNode cur = root;
while (cur != null)
if(cur.val == val)
return cur;
else if(cur.val < val)
cur = cur.right;
else
cur = cur.left;
return null;
/*
插入
*/
public boolean insert(int val)
BSNode bsNode = new BSNode(val);
if(root == null)
root = bsNode;
return true;
BSNode cur = root;
BSNode parent = null;
while (cur != null)
if(cur.val == val)
return false;
else if(cur.val < val)
parent = cur;
cur = cur.right;
else
parent = cur;
cur = cur.left;
if(parent.val < val)
parent.right = bsNode;
else
parent.left = bsNode;
return true;
/*
删除
*/
public void remove(int val)
if (root == null) return;
BSNode cur = root;
BSNode parent = null;
while (cur != null)
if (cur.val == val)
removeNode(parent,cur,val);
return;
else if (cur.val < val)
parent = cur;
cur = cur.right;
else
parent = cur;
cur = cur.left;
public void removeNode(BSNode parent, BSNode cur, int val)
if (cur.left == null)
if (root == cur)
root = cur.right;
else if (parent.left == cur)
parent.left = cur.right;
else
parent.right = cur.right;
else if (cur.right == null)
if (root == cur)
root = cur.left;
else if (parent.left == cur)
parent.left = cur.left;
else
parent.right = cur.left;
else
BSNode targetParent =cur;
BSNode target = cur.right;
while (target.left != null)
targetParent = target;
target = target.left;
cur.val = target.val;
if (target == targetParent.left)
targetParent.left = target.right;
else
targetParent.right = target.right;
查找逻辑:
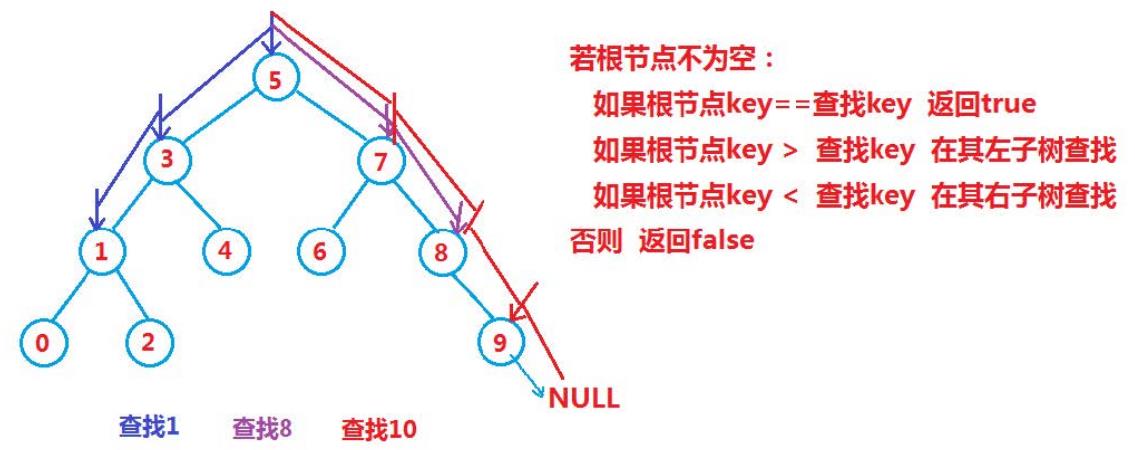
插入逻辑:

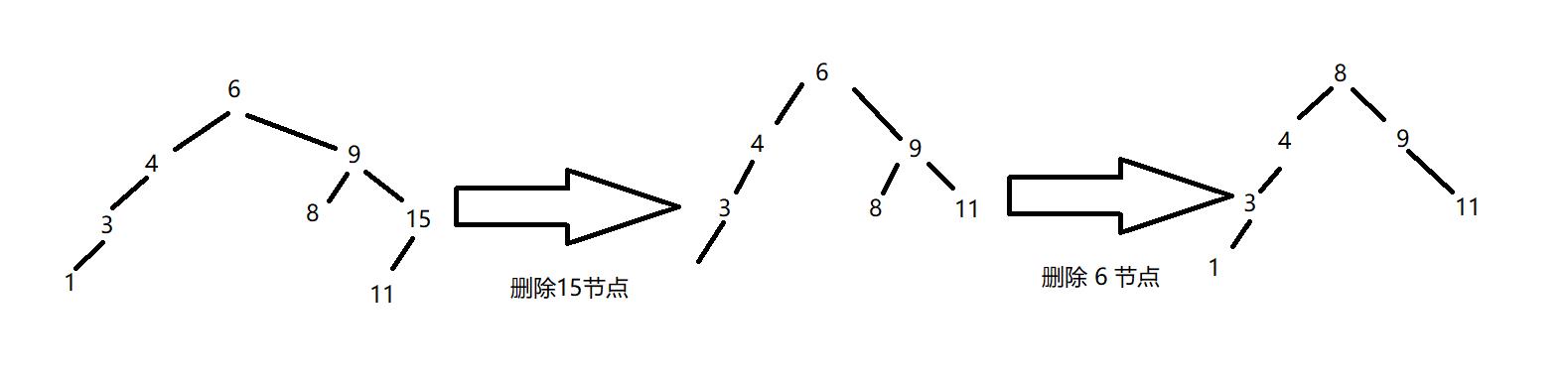
删除逻辑: 设待删除结点为 cur, 待删除结点的双亲结点为 parent
- cur.left == null 若 cur 是 root,则 root = cur.right 若 cur 不是 root,cur 是 parent.left,则 parent.left = cur.right 若 cur 不是 root,cur 是 parent.right,则 parent.right = cur.right
- cur.right == null 若 cur 是 root,则 root = cur.left 若 cur 不是 root,cur 是 parent.left,则 parent.left = cur.left 若 cur 不是 root,cur 是 parent.right,则 parent.right = cur.left
- cur.left != null && cur.right != null 需要使用替换法进行删除,即在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题。
测试代码:
public class TestDemo
public static void preOrder(BinarySearchTree.BSNode root)
if(root == null)
return;
System.out.print(root.val+" ");
preOrder(root.left);
preOrder(root.right);
public static void inOrder(BinarySearchTree.BSNode root)
if(root == null)
return;
inOrder(root.left);
System.out.print(root.val+" ");
inOrder(root.right);
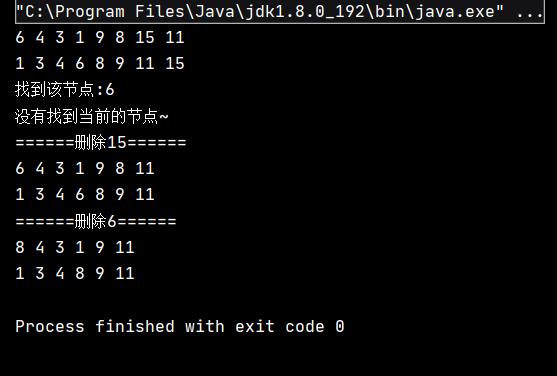
public static void main(String[] args)
BinarySearchTree binarySearchTree = new BinarySearchTree();
binarySearchTree.insert(6);
binarySearchTree.insert(4);
binarySearchTree.insert(3);
binarySearchTree.insert(1);
binarySearchTree.insert(9);
binarySearchTree.insert(15);
binarySearchTree.insert(8);
binarySearchTree.insert(11);
preOrder(binarySearchTree.root);
System.out.println();
inOrder(binarySearchTree.root);
System.out.println();
//查找节点5
try
BinarySearchTree.BSNode ret = binarySearchTree.search(6);
System.out.println("找到该节点:" + ret.val);
catch (NullPointerException e)
System.out.println("没有找到该节点~");
//查找节点14
try
BinarySearchTree.BSNode ret = binarySearchTree.search(14);
System.out.println(ret.val);
catch (NullPointerException e)
System.out.println("没有找到当前的节点~");
System.out.println("======删除15节点======");
binarySearchTree.remove(15);
preOrder(binarySearchTree.root);
System.out.println();
inOrder(binarySearchTree.root);
System.out.println();
System.out.println("======删除6节点======");
binarySearchTree.remove(6);
preOrder(binarySearchTree.root);
System.out.println();
inOrder(binarySearchTree.root);
System.out.println();
此代码的运行结果为:
性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:

最优情况下,二叉搜索树为完全二叉树,其时间复杂度:O(logN)
最差情况下,二叉搜索树退化为单支树,其时间复杂度: O(N)
搜索
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。
搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为O(logN) ,但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,Map和Set是一种适合动态查找的集合容器。
模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对
模型会有两种:
- 纯key 模型,比如:
- 有一个英文词典,快速查找一个单词是否在词典中 。
- 快速查找某个名字在不在通讯录中。
- Key-Value 模型,比如:
- 统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>。
- 梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号。
Map中存储的就是key-value的键值对,Set中只存储了Key。
Map 的使用
关于Map的说明
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
关于Map.Entry< K , V >的说明
Map.Entry<K, V> 是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
| 方法 | 解释 |
|---|---|
| K getKey() | 返回 entry 中的 key |
| V getValue() | 返回 entry 中的 value |
| V setValue(V value) | 将键值对中的value替换为指定value |
注意:Map.Entry<K,V>并没有提供设置Key的方法
Map 的常用方法说明
| 方法 | 解释 |
|---|---|
| V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
| V put(K key, V value) | 设置 key 对应的 value |
| V remove(Object key) | 删除 key 对应的映射关系 |
| Set< K> keySet() | 返回所有 key 的不重复集合 |
| Collection< V > values() | 返回所有 value 的可重复集合 |
| Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
注意:
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
- Map中存放键值对的Key是唯一的,value是可以重复的
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
TreeMap和HashMap的区别
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2N) | O(1) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
Set的使用
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
常见方法说明
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断 o 是否在集合中 |
| Iterator< E > iterator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection<? extends E> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
注意:
- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
TreeSet和HashSet的区别
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2N) | O(1) |
| 是否有序 | 关于Key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 先计算key哈希地址,然后进行插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
Map 和 Set 试题练习
只出现一次的数字
class Solution
public int singleNumber(int[] nums)
HashSet<Integer> set = new HashSet<>();
for(int i = 0;i < nums.length;i++)
if (set.contains(nums[i]))
set.remove(nums[i]);
else
set.add(nums[i]);
for(int i = 0;i < nums.length;i++)
if (set.contains(nums[i]))
return nums[i];
return -1;
使用Set方法解决本题。

复制带随机指针的链表
class Solution
public Node copyRandomList(Node head)
if (head == null) return null;
HashMap<Node,Node> map = new HashMap<>();
Node cur = head;
while (cur != null)
Node node = new Node(cur.val);
map.put(cur,node);
cur = cur.next;
cur = head;
while (cur != null)
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
return map.get(head);
该代码通过测试。

宝石与石头
class Solution
public int numJewelsInStones(String jewels, String stones)
HashSet<Character> set = new HashSet<>();
int count = 0;
for(char ch:jewels.toCharArray())
set.add(ch);
for(char ch:stones.toCharArray())
if(set.contains(ch))
count++;
return count;
该代码通过测试。
坏键盘打字
import java.util.*;
public class Main
public static void function(String strExc,String strAct)
HashSet<Character> setAct = new HashSet<>();
for (char ch:strAct.toUpperCase().toCharArray())
setAct.add(ch);
HashSet<Character> setBroken = new HashSet<>();
for (char ch:strExc.toUpperCase().toCharArray())
if (!setAct.contains(ch) && !setBroken.contains(ch))
setBroken.add(ch);
System.out.print(ch);
public static void main(String