gbk字符集共有多少个汉字_商品“锟斤拷";是个什么鬼?
Posted 幽反丶叛冥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了gbk字符集共有多少个汉字_商品“锟斤拷";是个什么鬼?相关的知识,希望对你有一定的参考价值。
文章转载至:https://blog.csdn.net/weixin_33958222/article/details/112101557
通过此链接 趣味数学 可以快速查找到字符对应编码
通过此链接 千千秀字 可以通过编码查找到对应字符

点击菜单栏“阅读打卡”
发现更多精彩和惊喜
周末女朋友出去逛街了,我自己一个人在家看综艺节目,突然,女朋友给我打来电话。




过了一会,女朋友回来了,她拿出手机,给我看了她在超市拍的照片:




字符编码和ASCII
我们经常看一些谍战剧,谍战剧里敌特、地下党员以及八路军各部间发送情报的时候,一般都是通过电报发送的,电报在传递的过程中,需要发报员用电键发出长短不一的电码,收报员就会听到电报机发出的滴滴滴答答答的声音。其实电报发出的声音都是"滴"和"答"的组合,"答"的声音是"滴"的三倍长。

发报员要先通过一种方式,将想要发送的情报转成电报的滴答声,收报员在听到滴答声之后,再将它们翻译成正常的文字。这个过程就是字符编码和字符解码。
谍战剧中将情报转成电报的"滴"和"答"声主要通过摩尔斯电码,这是一种通过不同的排列顺序来表达不同的英文字母、数字和标点符号的字符编码方式。莫尔斯电码由短的和长的电脉冲(称为点和划)所组成。点和划的时间长度都有规定,以一点为一个基本单位,一划等于三个点的长度。正好对应上电报的"滴"和"答"。

就像电报只能发出"滴"和"答"声一样,计算机只认识0和1两种字符,但是,人类的文字是多种多样的,如何把人类的文字转换成计算机认识的01字符呢,这个过程同样需要通过字符编码。
字符编码(Character encoding)是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。
和摩尔斯电码功能类似,上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定,这被称为 ASCII 码,一直沿用至今。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套计算机编码系统。它主要用于显示现代英语,其中共有128个字符,包含了所有的大写和小写字母,数字0到9、标点符号, 以及在美式英语中使用的特殊控制字符等。
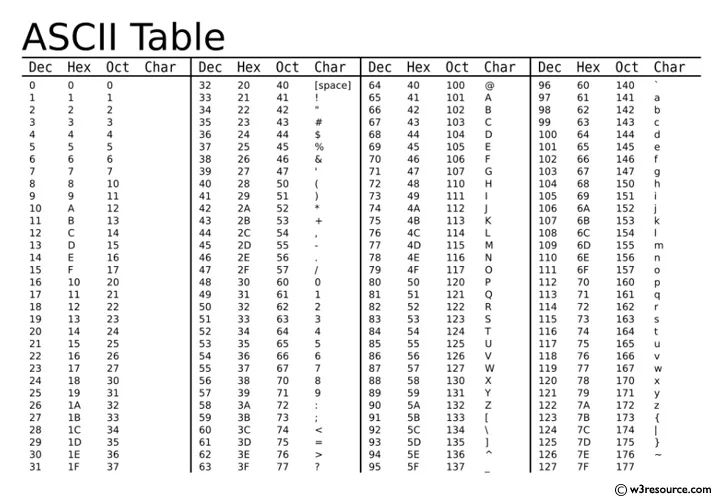



在介绍其他的字符编码之前,我们先来说一下一个计算机领域通用的字符集。
Unicode
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2019年5月公布的12.1,这一版本只新增了一个字符,即日本新年号令和的合字。

Unicode备受认可,并广泛地应用于计算机软件的国际化与本地化过程。有很多新科技,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
Unicode是一套通用的字符集,包含世界上的大部分文字,也就是说,Unicode是可以表示中文的。


UTF-8 UTF-16 UTF-32
Unicode虽然统一了全世界字符的编码,但没有规定如何存储。这么做是有考虑的:
如果Unicode统一规定,每个符号就要用三个或四个字节表示,因为字符太多,只能用这么多字节才能表示完全。
一旦这么规定,那么每个英文字母前都必然有二到三个字节是0,因为所有英文字母在ASCII中都有,都可以用一个字节表示,剩余字节位置就要补充0。
如果这样,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有:UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
UTF-8 使用一至四个字节为每个字符编码
UTF-16 使用二或四个字节为每个字符编码
UTF-32 使用四个字节为每个字符编码
所以我们可以说,UTF-8、UTF-16等都是 Unicode 的一种实现方式。
举个例子,Unicode规定了一个中文字符 "我"对应的unicode是"我",但是,在UTF-8和UTF-16等不同的实现方式下,这个二进制code的存储方式是不一样的。
UTF-8使用可变长度字节来储存 Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节。



GBK,GB2312,GB18030
因为UTF-8是Unicode的一种实现,所以他包含了世界上的所有文字的编码,他采用的是1-4字节进行编码。
对于那些排在前面优先纳入的文字,可能就优先使用1字节、2字节存储了,对于后纳入的文字,就要使用3字节或者4字节存储了。
正是因为他太全了,所以那些晚一些纳入的字符,在UTF-8中的存储所占的字节数可能就会多一些,那他的存储空间要求就会很大。
对于常用的汉字,在UTF-8中采用3字节进行编码,但是如果有一种只包含中文和ASCII的编码的话,就不需要使用3个字节,可能2个字节就够了。
对于大部分网站来说,基本都是只服务一个国家或者地区的,比如一个中国的网站,一般会出现简体字和繁体字以及一些英文字符,很少会出现日语或者韩文的。
也是出于这样的考虑,中国国家标准总局于1981年制定并实施了 GB 2312-80 编码,即中华人民共和国国家标准简体中文字符集。后来厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。
有了标准中文字符集,如果是一个纯中文网站,就可以可以采用这种编码方式,这样可以大大节省一些存储空间的。
常用的中文编码有GBK,GB2312,GB18030等,最常用的是GBK。
GB2312(1980年):16位字符集,收录有6763个简体汉字,682个符号,共7445个字符;
优点:适用于简体中文环境,属于中国国家标准,通行于大陆,新加坡等地也使用此编码;
缺点:不兼容繁体中文,其汉字集合过少。
GBK(1995年):16位字符集,收录有21003个汉字,883个符号,共21886个字符;
优点:适用于简繁中文共存的环境,为简体Windows所使用,向下完全兼容gb2312,向上支持 ISO-10646 国际标准 ;所有字符都可以一对一映射到unicode2.0上;
缺点:不属于官方标准,和big5之间需要转换;很多搜索引擎都不能很好地支持GBK汉字。
GB18030(2000年):32位字符集;收录了27484个汉字,同时收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
优点:可以收录所有你能想到的文字和符号,属于中国最新的国家标准;
缺点:目前支持它的软件较少。


乱码
我们还拿前面介绍过的发电报的例子来说,假设有以下场景:
发报员使用"美式摩尔斯电码"将情报转换成电报,收报员接收到电报之后,通过"现代国际摩尔斯电码"进行破译。那么得到的情报内容就可能完全看不懂,这就是乱码了。
就像在计算机领域,我们把一串中文字符通过UTF-8进行编码传输给别人,别人拿到这串文字之后,通过GBK进行解码,得到的内容就会是“锟届瀿锟斤拷雮傡锟斤拷直锟斤拷锟”,这就是乱码。
如以下代码:
public static void main(String[] args) throws UnsupportedEncodingException
String s = "漫话编程!";
byte[] bytes = s.getBytes(Charset.forName("GBK"));
System.out.println("GBK编码,GBK解码:" + new String(bytes, "GBK"));
System.out.println("GBK编码,GB18030解码:" + new String(bytes, "GB18030"));
System.out.println("GBK编码,UTF-8解码:" + new String(bytes, "UTF-8"));
输出结果:
GBK编码,GBK解码:漫话编程!GBK编码,GB18030解码:漫话编程!GBK编码,UTF-8解码:????????
可以看到,将中文字符,通过GBK编码,再使用UTF-8解码,得到的字符就是一串问号,这就是乱码了。



锟斤拷的前世今生
因为Unicode是一直在更新的,在这个过程中,肯定有一些比较新的字符他是无法表示的。或者即使Unicode发布了新版纳入了某个文字,但是很多软件系统并未升级也会有这样的问题。
就像生活中一些手机厂商新出的那些emoji表情,在自己的手机上可以正常显示,发到其他品牌的手机上可能就无法显示。这其实也是字符集不支持导致的。
发生以上情况时,无法显示的时候也需要有一个字符来表示的,在Unicode中,这个字符就是 � ,他也是Unicode中定义的一个特殊字符。也就是"0xFFFD REPLACEMENT CHARACTER",所有无法表示的字符都会通过这个字符来表示。
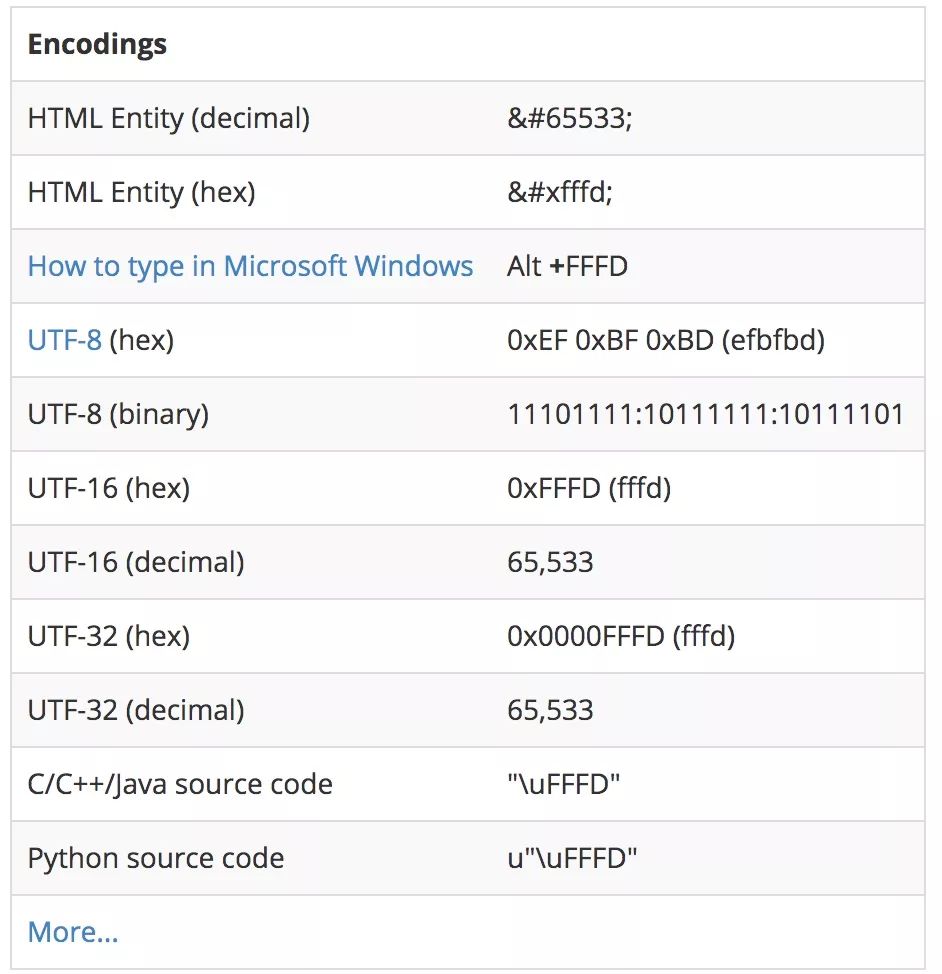
Unicode官方有关于这个符号的介绍,从上表中可以看到,他的10进制表示是65533,在UTF-8下,他的16进制形式是'0xEF 0xBF 0xBD'(三个字节)。
如果有两个连续的字符都无法显示,如"� �" ,那么在UTF-8编码下,16进制表示为:
0xEF 0xBF 0xBD 0xEF 0xBF 0xBD
以上这段编码,如果放到GBK中进行解码的话,因为GBK中一个汉字两个字节,那么结果就是:
0xEF 0xBF, 0xBD 0xEF, 0xBF 0xBD
即
0xEFBF0xBDEF0xBFBD
那么,如果展示出来,就是:锟(0xEFBF),斤(0xBDEF),拷(0xBFBD),所以,以后再见到锟斤拷,第一时间想到UTF-8和GBK的转换问题准没错。
除了锟斤拷以外,还有两组比较经典的乱码,分别是"烫烫烫"和"屯屯屯",这两个乱码产生自VC,这是debug模式下VC对内存的初始化操作。VC会把栈中新分配的内存初始化为0xcc,而把堆中新分配的内存初始化为0xcd。把0xcc和0xcd按照字符打印出来,就是烫和屯了。




作者:漫话编程 公众号:mhcoding
以上是关于gbk字符集共有多少个汉字_商品“锟斤拷";是个什么鬼?的主要内容,如果未能解决你的问题,请参考以下文章