Lookalike算法调研
Posted dulingtingzi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lookalike算法调研相关的知识,希望对你有一定的参考价值。
参考了很多优秀博主的文章,这属于一个汇总吧
参考文章:(还有很多,在后面的连接里)
1、什么是lookalike
lookalike算法是计算广告中的术语,不是单指某一种算法,而是一类方法的统称。其目的是基于目标人群,从海量的人群中找出和目标人群相似的其他人群,实现人群包扩充。
比如:广告主需要对100w人投放,但是,从选取的基础数据包中,只有30w,那么如何满足100w的投放需求,这时,就需要通过lookalike的方式进行扩充,既要保证人群数量,又要确保人群的相似。
如果只是简单的从公共池中选取70w,完成100w的匹配,很有可能出现无效用户。例如:高级消费品,尽可能的投放给中高级消费,且具有该品类偏好的人群。
2、如何进行lookalike
lookalike使用什么算法呢,估计没几个人能说得出来的,即使现在Lookalike成了DMP、DSP、广告投放平台的标配,也就只有少数的公司会提交论文、公布具体的实现算法,大部分是不公开的,只是说基于种子人群扩散效应,将lookalike作为一种提升逼格的利器,给人一副忌讳莫深的感觉。没人知道它具体的算法,更不用说怎么评估它的效果。
Lookalike可以分为显示定位和隐式定位。
第一种,显式定位,广告主根据标签进行人群选择。
这种方式,最为简单,高效。广告主通过用户画像标签,筛选性别,年龄,品类偏好等。可以直接快速达到人群包提取目的。这是最简单、高效、粗暴的一种方式。这种适合收集有大量用户数据能构建完整用户画像的公司做。这种方式试错成本高,手动调优难,投放效率低,所以往智能定向的方向发展,如协同过滤,序列推荐,图神经网络等,但很多平台仍然会提供这种传统的显示定向方式的。
这种方法,具有一定局限性,未必男性就不关心女性用品,也未必食品偏好的人群,就不关心护肤用品。标签的产出,本身基于用户行为,但单纯标签筛选,并不能把潜在相关用户提取出来。
计算广告中的lookalike是如何实现的?
因此,就需要采用第二种方法。
第二种,隐式定位,通过机器学习的方法,对种子用户进行建模。
隐式定位是通过机器学习、深度学习的方法,对种子用户进行建模,然后用模型去识别。参考《A Sub-linear, Massive-scale Look-alike Audience Extension System》里面的分类规则做如下划分:
基于相似度模型
主要是基于User-User之间的某种距离大小来衡量用户之间的相似度,主流的相似度计算方法包括:针对连续值的余弦相似度(Cosine similarity)以及针对离散值的(Jaccard similarity)
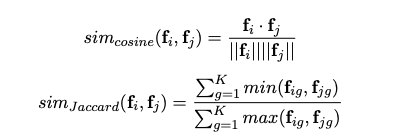
计算完个体之间的距离后,如何计算个体和样本整体之间的距离有三种方法:
- 最大值Max:利用u1与seeds中相似度最大值作为u1与seeds的相似度 sim(u1,seeds)=Max(sim(uj,seeds))
- 平均值Mean:利用u1与seeds中每个用户的相似度去均值作为整体相似度 sim(u1,seeds)=Mean(sim(uj,seeds))
- 基于概率:该方法要求用户之间的相似度在[0,1]之间。通过不相似度反向得到相似度。
这方法计算简单,适用于小范围的计算,因为每个用户都去计算和种子用户的距离,数据量大的时候,计算量呈现指数级上升,通常会采用LSH(Locality Sensitive Hashing ,局部敏喊哈希)的方式去加速计算,如领英的《Audience Expansion for Online Social Network Advertising》。
除此之外还有皮尔森相关系数(Pearson Correlation Coefficient)、Jaccard相似系数(Jaccard Coefficient)、Tanimoto系数(广义Jaccard相似系数)。
基于标签/用户协同过滤
在标签扩散的基础上,采用基于用户的协同过滤算法,找到与种子人群相似的机会人群。协同过滤推荐算法分为两类:基于用户的协同过滤推荐算法和基于项目的协同过滤推荐算法。
- 基于用户的协同过滤推荐算法根据用户对项目的评分矩阵,计算用户之间的相似度,找出目标用户的最邻近邻居集合,最后,对最近邻居集合进行加权,从而产生目标用户的推荐集。
- 基于项目的协同过滤推荐算法根据对用户已评分项目相似项目的评分进行预测,从某种程度上减少了评分矩阵稀疏性和冷启动问题对推荐质量的影响。
这里采用的第一种算法,基于用户的协同过滤推荐算法的核心想法是通过寻找相似的用户,然后根据相似用户的关系进行推荐。例如,用户A喜欢电影a和c,用户B喜欢电影b,用户C喜欢电影a、c和d,通过数据可以发现用户A和用户C是是比较接近的人群,就是喜欢相同的,同时c还喜欢d,那么我们可以A也喜欢d电影,向A推荐d电影。如果将用户和电影(这里指特征)看做一个点建立起了联系,关系网就形成一张图。
- 第一阶段是从种子用户找到与用户相似的用户集,基于相似度去计算(有些会从种子用户计算推荐集)
- 第二阶段根据候选集产生推荐集,先得到最后推荐集,再通过Top-N排序算法得到用户
基于分类模型
将look-alike看成是分类问题,很多的分类算法都可能适用。
LR算法
将种子用户作为正例,将随机用户进行降采样后作为负例,为每个种子训练一个LR模型。用这个模型在全部用户上预测,后去判断其他的用户是否为目标人群,模型如下:
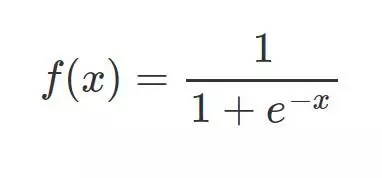
x是个向量,可以将所有的特征都输入:
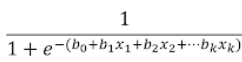
这个函数的图形是:
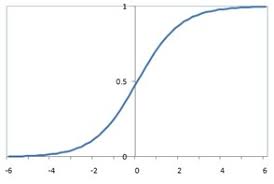
值的范围在0到1之间,通过阈值就可以判断是否符合目标用户,如0.6,大于0.6是目标用户,小于0.6是非目标用户
这种方法的优势在于种子用户的所有特征都使用到,易于解释。缺点是是它是线性的,相对还是简答;随着广告的增加,索引存储、离线训练和预测的机器会难以支撑。
- 腾讯的广点通在2015年到2017年就是用这种.
- 360DMP在2016年左右也是用这种。
- TalkingData在2015年左右也使用这种
- 爱奇艺DMP使用这种算法
RF模型
根据阿里巴巴的文章,对随机森林模型的实验效果并不理想,在相同的样本和特征上Precision和AUC指标均比LR低,且特征重要性结果只能到特征粒度不能到特征值粒度,因此不再使用。
PS-SMART算法
根据阿里巴巴的文章,PS架构的GBDT算法模型,决策树弱分类器加上GBM算法,具有较强的非线性拟合能力,在应用中相比其它两种算法模型效果更好。因此选择PS-SMART作为最终的算法模型,并对损失函数、树的个数深度、正则系数进行调优。
- 阿里巴巴的品牌目标人群优选使用PS-SMART算法
……
基于聚类
根据用户标签,采用层次聚类算法(如BIRCH或CURE算法)对人群进行聚类,再从中找出与种子人群相似的机会人群,再通过Top-N排序算法得到用户。
基于社交关系
以具有相似社交关系的人也有相似的兴趣爱好/价值观为前提假设,利用社交网络关系进行人群扩散。
基于图模型
基于图模型的代表就是Yahoo提出《A Sub-linear, Massive-scale Look-alike Audience Extension System》,文章在Abstract就直接写是基于图模型,由于选择特征的时候可以用LR,所以有些文章会将其划分到基于回归模型:

图模型可以分为两个阶段:
- 粗排序(Global Graph Construction):通过构造全局图找相似的用户,而构造全局图使用的是Jaccard similarity,会带来计算量的问题,所以利用LSH(Locality Sensitive Hashing ,局部敏喊哈希)来加速相似度的计算并构造全局图,有两种计算方法方法MiniHash+LSH。
- 精排序(Campaign Specific Modeling):根据广告特征权重对粗排序做排序,而对特征的选择可以选择IV(information value)或LR(logistic regression)方法。
注意:由于在最后一步使用LR,有些分类将这种方法放到了基于回归类型。
基于Attention深度模型
RALM算法:全名Real-time Attention based Look-alike Model,这是腾讯最近提出的一个基于深度学习的Look-alike系统,已经微信上的看一看应用。它通过 user representation learning 表达用户的兴趣状态,通过 Look-alike learning 学习种子用户群体信息以及目标用户与种子用户群的相似性,从而实现实时且高效的受众用户扩展和内容触达。
- 微信看一看使用RALM算法
使用情况
从公开资料可以知道一些公司使用的具体算法,由于时效性问题,有些公司的实际使用的可能已经更新了,下面信息仅做了解:
- Adobe的用的是TraitWeight algorithm,
- 百度用深度神经网络相似排序模型
由于性能的因素,部分厂家会使用两级模型,就是第一级别是基于标签的,因为基于标签的方式简单,能够做初步筛选,其实就是做粗排,第二级别的是基于算法的,做精选。
举个例子:
以30w人群,扩展100w为例。我们需要将30w用户的共有特征提取出来,内容包含性别,学历,年龄,职业,常住地,购买力,RFM分值,最近浏览加购信息等。该人群特征提取完成之后,成为种子包,标记为正样本。
接下来,我们需要有一个基础用户包,用于70w的人群扩展,可以是全量数据,可以是近三个月,近一个月的活跃用户,也可以是品类偏好用户,数据内容取决于具体业务。数据规模,取决于扩展人群数量。需要扩展70w,基础包数量,可以是300w,500w,或者更多。当然了,不是越多越好,数量越多,意味着后期模型转换耗时会更长。
假设基础包用户500w,我们需要从500w中随机抽取30w用户,标记为负样本。
接下来,就是一串的特征处理,StringIndexer,VectorAssembler,OneHotEncoder,QuantileDiscretizer。总是,就是将离散型字符变量整数化,离散型整数变量编码,以减少不同类别之间的距离差,把连续性变量进行分箱,调整为离散型变量,以减少距离差。离散化、归一化、等分位,都是常用的特征处理手段,spark ML中提供了一堆。。。
特征处理完成后,进行模型训练,这里的分类算法,可以是LR,SVM或是其它,不同厂的做法都不相同。效果好就行。
模型训练完成后,重要环节,需要对500w的基础包进行transform,模型会对500w数据中的每条数据进行分类,并预测概率值。从500w数据中,抽取正样本,并按照概率从高到低排序,取出top 70w即可。
最后,将30w人群与70w人群进行合并,标记100w的扩展人群包,用于线上投放。
3、计算广告中的lookalike是如何实现的?
可能有读者已经意识到,直接把基础包中,随机抽取30w标记为负样本,也许不妥,有可能存在与种子包人群高相似用户。解决这个问题,只有一个办法,就是多跑几次。先以第一次的模型,对30w基础包用户进行分类,产出top,重新修正标记,再从公共池中,抽取等量用户补充,不断迭代,最终会训练一个理想模型出来。
在机器学习中,模型的好坏,极大程度上取决于特征的选取及处理。算法上,可以采用一般的分类算法,亦可采用深度学习中的多层神经网络相关算法。总之,方法很简单,需要的是,对模型进行不断的优化。
4、lookalike应用tips:
- 结合聚类算法一起使用
有时候客户提供过来的种子人群成分是非常复杂的,往往是参杂了大量子类人群的总和,如果直接拿这些种子人群进行lookaLike,则相当于把人群的特征进行了弱化,最终找出来的相似人群特征会变得不明显。例如某奢侈品牌,他们的一方种子人群中包含2类,一类是真正有钱的人群,平时开豪车住别墅的,另外一类是普通的城市小白领,他们往往攒好几个月的工资进行一次消费。这2种人群必须先通过聚类算法区分出来,然后再输入lookaLike算法去扩大。 - 在什么媒体上用
LookaLike算法选出的人群最终是在媒体的流量人群中实现触达,因此媒体自身流量对最终lookaLike算法落地的效果影响非常大,例如我们做过的某次营销案例,选取某DSP做为精准营销的落地媒体,在整个4周的营销过程中,最终选取的精准人群只有2%曝光成功。(一方面由于该DSP媒体流量均为长尾流量,而我们选取的目标人群为金融类目标人群,该DSP对目标人群覆盖率低,另外由于低价策略,竞价成功率低也导致了最终触达的精准人群规模比较小。)最终我们分析了这2%成功曝光的人群,发现他们也是Lookalike算法相似度相对较低的,也就是说最相似的那部分目标人群在该媒体上并没有出现和竞得。
因此为了保证lookaLike算法落地的效果,选取与广告主自身产品相对匹配的目标媒体以及合适的出价都非常重要。 - 根据效果数据优化lookaLike算法
一旦精准营销活动开始后,就可以回收消费者对营销的反馈数据做为正样本来对lookaLike算法进行优化。通过TalkingData对大量历史投放数据的分析,动态优化lookaike算法可以极大的提升算法的转化效果:在同样选取相似度TOP100w样本进行精准投放的情况下,每日优化样本库组相比较不优化组在一周的投放周期内,可提升激活率180%以上。样本库优化的周期可以根据效果数据回收的量级、媒体的技术支持能力、以及DMP平台自身的数据更新周期综合决定,建议每1-2日更新目标用户群。
个人理解及总结:
lookalike其实是一种框架,就是基于已有的目标或者标签用户群,来进行相似目标人群寻找或者目标人群扩充,说白了就是要找到和已有的目标标签人群相似的人群,以便进行产品营销,这样的话,方法其实就很多了,也很灵活,可以基于模型,也可以基于规则,可以有监督,也可基于无监督聚类,可以并行用不同的方法取并集或者交集,也可串行,用级联的方法去得到更精准的目标人群,所以,其实这个概念就是个术语,他把解决寻找相似目标人群的方法都叫lookalike,无论你的方法是什么,只要你能找准目标人群即可。我猜测之所以找到这个术语指代,可能就是细分场景很多,各家公司数据也各不相同,不会也不能有一种通用的方式去解决问题。所以把找目标人群的这些五花八门的解决方法统一叫做lookalike,具体使用什么方法,还是得依据你有什么数据,具体问题具体分析,没有万能公式
比较不错的案例:
Lookalike 在爱奇艺广告投放中的应用 - 开发者头条
案例 | 基于 Youmi DSP, Look-alike技术究竟能带来什么?
知乎上的答案:
论文解读|微信看一看实时Look-alike推荐算法
深度学习在推荐领域的应用:Lookalike 算法
深度学习在推荐领域的应用:Lookalike 算法 - 博文视点
Lookalike 技术调研(这里面的例子非常好,我们也可以采用这种多角度分析特征拼接和建模的方式,最后计算相似度来进行受众人群扩展)
深度学习在推荐领域的应用(这个文章里有几篇参考的论文可以直接下载)
深度学习在推荐领域的应用_huangyimo的专栏-CSDN博客
【论文笔记】Audience Expansion for Online Social Network Advertising【用户扩展】【lookalike】
【论文笔记】Audience Expansion for Online Social Network Advertising【用户扩展】【lookalike】 - 知乎
有些用户相似度扩展是用LSH算法做的,可以了解一下这个算法
以上是关于Lookalike算法调研的主要内容,如果未能解决你的问题,请参考以下文章