大数据存储技术期末复习(自用)
Posted St Clair
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据存储技术期末复习(自用)相关的知识,希望对你有一定的参考价值。
一、题型
1. 判断题(20*2)
2. 简答题(3个*10)
3. 设计题(2个*15)
二、往年题目

三、知识点
(1)CAP理论
1、定义
一致性C:所有数据备份在同一时刻的值相同。读写请求是原子、串行的。
可用性A:部分节点故障,但整体仍然能响应读写请求。请求时间是有限、可终止的。
分区容忍性P:在一定通信时限内达成数据一致,否则发生分区,即部分节点无法和其他节点进行通信。分区是无法避免的。
2、分类
CA:关系型/单点数据库、LDAP、RDBMS,分区后子系统保持CA。
CP:传统数据库分布式事务/分布式数据库、分布式锁、MongoDB、HBase、Redis。
AP:DNS、Web缓存、NOSQL、Couch DB、Riak、Cassandra、Dynamo DB。分区节点失联导致数据不一致。
3、注意
没有一个软件系统同时满足CAP:这里的C 指的是强一致性。针对分布式系统而言,一定满足P,即存在网络分区(网络延时)。反证法,允许P-则Server丢包-则C不一致-CAP不成立。
弱一致性:最终一致性,DNS,Gossip (Cassandra的通信协议)
强一致性:同步,Paxos,Raft (multi-paxos),ZAB (multi-paxos)
(2)强一致性算法-paxos
1、共识算法
相同的初识状态+ 相同的输入 = 相同的结束状态。如mysql 的 binlog,paxos。
2、强一致性算法
强一致性算法=共识算法+client行为。强一致性算法强调多数派,读写需要大于N/2个节点,属于并发环境下的顺序问题。
3、强一致性算法-paxos:
角色:
Client:系统外部角色,请求发起者,比如民众
Proposer:接受client请求,向集群提出提案(propose)。并在冲突发生时,起到冲突调节的作用。像议员,替民众提出议案。
Acceptor(Voter):提议投票和接收者,只有在形成法定人数(Quorum,一般即为majority多数派)时,提议才会最终被接受。像国会。
Learner:提议接受者,backup,备份节点,对集群一致性没什么影响。
步骤阶段:

(3)强一致性算法-Raft
1、三个角色
领导者:0/1个,发送心跳消息,处理客户端读写请求,管理日志复制等。
候选人:领导者心跳超时,发起投票请求,当选领导者。
选民:处理日志消息,等待心跳消息,如果领导超时,就推举自己成为候选。
2、任期:
递增,逻辑时钟,选举投票以及日志复制的重要依据。
3、过程:
候选人向选民提出选举自己的请求,超过n/2同意,即可成为领导,进行日志复制等操作,宕机后超时时间最短的选民成为新的候选者,发起新一轮选举,重复以上步骤。
可以看出所有节点启动时都是follower状态;在一段时间内如果没有收到来自leader的心跳,从follower切换到candidate,发起选举;如果收到majority的赞成票(含自己的一票)则切换到leader状态;如果发现其他节点比自己更新,则主动切换到follower。总之,系统中最多只有一个leader,如果在一段时间里发现没有leader,则大家通过选举-投票选出leader。leader会不停的给follower发心跳消息,表明自己的存活状态。如果leader故障,那么follower会转换成candidate,重新选出leader。
4、三个问题:选举,日志复制,安全
日志:Raft 数据的载体,数据存储的最小单位。
日志结构:用户指令、任期、索引
日志复制:复制状态机-共识、日志、状态机。 mysql 的 HA 架构、redis 的集群架构。
日志同步:二阶段提交2PC。提交放到下一次请求,减少请求次数。
日志一致性:根据任期编号和索引值确定要不要复制
选举规则:自荐,少数服从多数,强者优先,每人一票先到先得,禁止造反,终身责任制。
强者优先:候选者任期编号大于自己,候选者日记完整性高于自己,才会投票。
(4)nginx的负载均衡策略

IP地址哈希:根据IP地址分配,同一个客户端请求转发给同一个服务器,保证session一致性,适合解决跨域问题。
(5)一致性Hash算法
Hash环:整个哈希值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。
Hash取模:Node A,B,C,D四台机器,利用其 IP 地址进行hash取模。体现了单调性--原有内容映射到原缓冲。将数据key使用相同的Hash函数计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”(步数编号),第一台遇到的服务器就是其应该定位到的服务器!
容错性/可扩展性:Node C 宕机,增加一台机器Node X,仅仅影响Node C到环空间的前一台服务器(逆时针第一台)之间的数据。因此,一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据(这之间的失效了),具有较好的容错性和可扩展性。
Hash环的数据倾斜问题、负载均衡:服务节点太少时,容易因为节点分布不均匀而造成数据倾斜。改进:引入虚节点,可以在服务器IP或主机名的后面增加编号,个数远大于当前节点数,均匀分布到一致性哈希值域环,提高缓冲空间利用率。
(6)全局ID生成算法
1、全局ID特点:
唯一-避免id冲突、在表合并迁移的时候,
有序,
可用-高并发正确,
自主-不依赖中心认证,
安全-不泄露信息。
2、UUID:当前日期时间+时钟序列+唯一硬件识别号。
优点:API简单易用。
缺点:内存大(超长字符串)、字符串不能加工、可读性差。
3、ID生成表模式:
机制:采用MySQL自增长ID机制,如: Mysql的auto_increment(自动 定量增长)。
优点:简单、天然有序,
缺点:并发性不好(只能一个写);数据库写压力大(就一个在写);数据库故障后不可使用(就一个增长列);存在泄露风险(就一个)。
改进:
a.水平拆分:每个数据库设置不同的初始值和相同的自增步长。
b.批量缓存自增ID,优点:可以避免固定步长带来的扩容问题(多条路,不必一直扩);缺点:服务器重启、单点故障会造成ID不连续(少了几个,就不连续了)。
4、Snowflake算法:
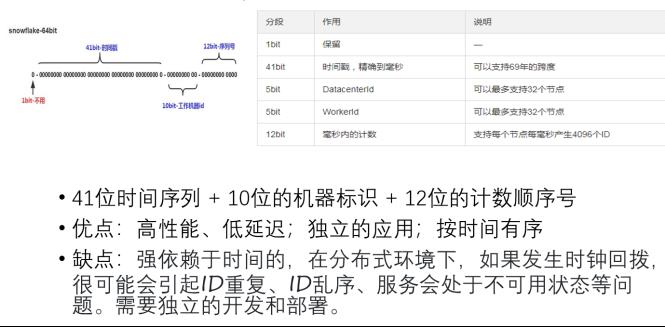
5、结合缓存方案:利用ID生成表模式成批获取ID放入本地缓存。
优点:高性能、低延迟、有序。
缺点:不连贯
6、Redis 生成ID:
定义:单线程操作,自增原子命令,保证ID 唯一有序。
优点:① 不依赖于数据库,灵活方便,且性能优于数据库。② 数字ID天然有序。
缺点:① 系统需要引入Redis的组件,增加系统复杂度。② 编码配置的工作量大。
优化方案:单节点性能瓶颈,因此使用Redis 集群来获取更高的吞吐量,并利用(①数据库水平拆分 ②批量缓存自增ID)来配置集群。
应用场景:生成每天从0开始的流水号。比如:“订单号=日期+当日自增长号”,则可以每天在Redis中生成一个Key,使用INCR进行累加。
7、Mongo的objectld算法:
定义:使用12字节(24bit)的BSON 类型字符串作为ID,并将所占的24bit 划分成多段。
ID:新版ObjectId中“机器标识码+进程号” 改为用随机数作为机器标识和进程号的值。
(7)设计一个缓存框架(参考课本java或者课件项目golang都可以)
通过JSR107规范,将缓存框架定义为客户端层、缓存提供层、缓存管理层、缓存存储层。其中缓存存储层又分为基本存储层、LRU存储层和Weak存储层。
缓存框架基本结构如下:
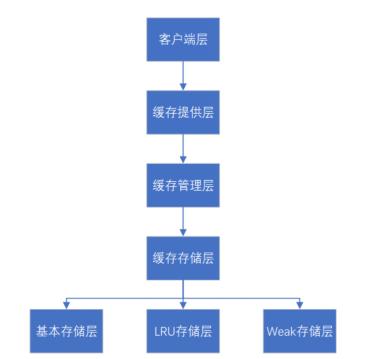
缓存框架的介绍说明:
客户端层:使用者直接通过该层与数据进行交互,从数据源(文件,数据库等)获取数据并添加到缓存中。要注意的是客户端层不应该支持多种数据源的配置,其一是因为数据源的种类太多,没办法实现;其二是扩展性不好。
缓存提供层:主要对缓存管理层的生命周期进行维护,负责缓存管理层的创建、保存、获取以及销毁。通过CachingProvider类创建缓存提供层对象。
缓存管理层:对应接口类CacheManager所对应的正是缓存管理层,在缓存框架中CacheManager的实现类,主要负责管理多个Cache实例,对Cache实例的生命周期进行维护,负责Cache实例的创建、保存、获取以及销毁。
Cache实例的创建和获取实际上主要是基于一个缓存池来实现的,在代码中使用的是一个ConcurrentHashMap类,可以根据多个不同的Cache名称创建多个缓存实例,从而可以并发的读取。
缓存存储层:主要负责缓存数据的存储和缓存的淘汰机制,基于DataStore接口实现,其中包含三个实现类:BaseDataStore、LRUDataStore、WeakDataStore。通过key值以及get、put、remove、replace方法可以获取、增加、删除、替换缓存数据。
基本存储层:是以普通的ConcurrentHashMap为存储核心,数据不淘汰。
LRU存储层:‘最近最少用’为原则,是一种相对平衡的一种淘汰算法。LRU 算法最核心的 2 个数据结构是:字典(map),存储键和值的映射关系;双向链表实现的队列,存放所有的值,便于访问,时间复杂度O(1)。LRUDataStore维护了一个LRUEntity数据表,执行put操作将最新数据封装放入链接头部。
Weak存储层:是以弱引用为原则的数据存储和缓存淘汰机制。实现类为WeakValueDataStore和WeakValueHolder。前者提供数据存储,后者提供基于弱引用的实际值存储逻辑。
(8)缓存击穿、穿透、雪崩现象及解决办法
1、缓存击穿(1):
描述:数据库里有数据,缓存里某一个key不存在,或者key过期失效,通常是热点数据,高并发情况下,造成瞬时DB请求量大、压力骤增,从而崩溃。
解决:
a.互斥锁方案(第一个请求加锁,其他等待,直到第一个拿到数据,其他跟着访问缓存即可,Redis的分布式锁和redisson框架 )。
b.设置热点数据永不过期。
2、缓存穿透(0):
描述:缓存里没有数据,数据库里也没有数据。查询一个不存在的数据,因为数据不存在,就不会被写入缓存,所以每次都请求DB,如果流量增大,就会造成缓存穿透。
解决:
a.缓存空值--查询结果返回空值,将其缓存,缓存时间最长不超过五分钟。
b.在缓存之前加一个Bloomfilter布隆过滤器,查询的时候先去Bf确认key是否存在,如果存在再去查询缓存和DB。
3、缓存雪崩(n):
描述:缓存里key对应的数据存在,但多个key过期,即在同一时刻失效,高并发情况下,造成瞬时DB请求量大、压力骤增,从而崩溃。通常由于服务器宕机、多个key设置了相同的过期时间引起。
解决:
a.构建多级缓存框架:Ngnix缓存+redis缓存+其他缓存(如Ehcache)。
b.设置不同的缓存失效时间:在原有的失效时间上增加随机值1-5min,重复率降低,集体失效概率降低。
c.互斥锁:同上,第一个请求加锁,其他等待,直到锁被释放,降低吞吐量,慎用。
(9)Ehcache的注解
开启注解:<cache:annotation-driven cache-manager=”cacheManager”/>
使用标记注解:通过对一个类进行注解修饰的方式在这个类中使用缓存注解。
@Cacheable:被修饰方法可以缓存、第一次缓存结果、后面t内返回结果即可(不执行代码段)
@CachePut:缓存结果且会执行代码段
@CacheEvict:删除(无效)缓存
Caching:使用同一个缓存注解多次修饰
CachingConfig:类的操作都是缓存操作 时,用来指定类,方便配置
(10)Memcached的内存管理机制
1、Slab内存分配机制:
page 分配给slab的空间,chunk,固定大小的数据区块--记录缓存内容,slab class,chunk组,动态创建的实际内存区。增长因子1.25,chunk大小依次累乘。
提前分配内存slab1MB(默认),再进行小对象填充chunk。Memcached根据数据大小,选择合适的slab,再根据slab内的空闲chunk表,选择合适的chunk,将数据缓存。
避免大量重复的初始化和清理,还有频繁的分配/释放内存,减轻内存负担,减少系统碎片。
但是分配内存长度固定,无法有效利用内存。
利用增长因子调优,控制slab之间的差异,控制chunksize的增长幅度差异,差距越小,利用率越高。
2、Item分配内存机制:
保存在chunk的实际数据,
键长nkey+值长nbytes+后缀长nsuffix+item结构大小,
根据这个快速定位slab classid(1MB,最小冗余slab class),
按照顺序(回收空间slot、slab空间page中、内存剩余memory、LRU)查找,
内存浪费,利用n参数调优,(重新规划slab=chunk*n,slab=chunk,chunk=item,整数倍)
利用增长因子调优,控制slab之间的差异,控制chunksize的增长幅度差异,差距越小,利用率越高。
3、缓存过期策略:
(1)Lazy Expiration(延迟/惰性 过期)
Memcached不会监控记录是否过期,而是当客户端来获取数据的时候,才会检查记录的时间戳,CPU不必耗费大量时间监控因此成为Lazy Expiration。
(2)LRU(Least Recently Used 最近最少使用)
当空间不足的时候,Memcached会优先使用已经过期的数据空间,如果还不够的话,就会使用LRU算法来分配空间,删除最近最少使用的key/value对,将其空间分配给新的key/value对。如果不希望使用LRU算法时,启动时加-M参数,这样memcached内存耗尽时会返回一个报错信息。要特别注意,Memcached的LRU不是全局的,而是针对slab的,可以说是区域性的。
(3)惰性删除机制
删除item对象时,不释放内存,作删除标记,指针放入slot回收插槽,下次分配的时候直接使用。
(11)关系型数据库和非关系型数据库的优缺点分析
关系型数据库:SQLite、MySQL、Oracle ,电信、银行等领域
优点:
1. 容易理解:一个关系型数据库就是由二维表及其之间的联系所组成的数据组织,这种结构贴近逻辑世界,相对网状、层次等模型更容易理解
2. 使用方便:通用的SQL语言使得操作关系型数据库非常方便
3. 易于维护:发展时间长,技术成熟
3. 数据完整性高:具有丰富的完整性(实体完整性、参照完整性和用户定义的完整性),大大降低了数据冗余和数据不一致的概率
4. 数据强一致性:关系型数据库的最大特点就是事务的一致性,严格遵循ACID模型
5. 标准化:支持统一查询语言SQL,可用于复杂的查询
7. 查询效率高:借助索引机制快速查询、高效的查询机制
缺点:
1. 读写性能不佳:为了维护一致性所付出的巨大代价就是其读写性能比较差,尤其是在海量的数据面前
2. 灵活性不高:固定的表结构导致灵活性差
3. 存在I/O瓶颈:对于高并发读写需求,传统关系型数据库的硬盘I/O是一个很大的瓶颈
4. 不支持海量数据:难以有效存储稀疏数据,存储记录数量有限
5. 可扩展性差:纵向扩展花费高,需要购买高额服务器,横向扩展性差
6. 数据库模式相对固定:严格遵循定义和约束,不够灵活
非关系型数据库:MongoDB、Redis、HBase 互联网企业、传统企业的非关键业务(比如数据分析)
优点:
1. 高并发、读写性能好:无需经过SQL层的解析,读写性能高,
2. 扩展性高:基于键值对,数据没有耦合性,容易扩展
3. 数据格式灵活:数据结构化存储方法的集合,非关系型数据库的存储格式是 格式、文档格式、图片格式等等,而关系型数据库只支持基础类型
4.支持海量数据:有效实现稀疏数据的存储管理、高可用。
5. 支持web2.0应用:分布式存储,使用键值对存储数据,与云计算结合紧密
6. 开源:NoSQL项目大都是开源的,允许用户根据自己需求对其进行修改以满足自己需求
缺点:
1. 不提供SQL支持,没有统一查询语言
2. 无事务处理机制
3. 数据结构相对复杂,复杂查询方面稍欠
4. 缺乏数学理论基础:NoSQL没有统一的理论基础
5. 数据完整性低:不支持ACID模型,而是支持BASE模型,很难实现数据完整性,只能达到数据最终一致性
6. 技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
(12)Redis的数据结构
Redis常用的value包含5种类型:string、list、set、hash、zset。

String:
最基本,
字符串、浮点数、整数,
任何类型数据(二进制、图片、json对象),
编码方式int raw动态字符串 embstr动态字符串
(32字节,SDS-字符数组-len alloc flags buf的 free区域),
基本操作:批量设置键值对、过期和SET 命令扩展、计数
场景:存储图片、统计微博粉丝数
List:
存储String序列,
按照插入顺序排序,可以重复,
可以添加一个元素到列表的头部或者尾部,插入和删除操作非常快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为 O(n)
底层是个链表结构,可以使用ziplist、linkedlist实现
利用迭代器可以从两个方向对链表进行迭代,
压缩列表(ziplist),zbyte字节、ztail偏移量、zlen数量、zlend结束点,prelen、encoding类型长度-根据不同数据改变-redis节省内存、data、复杂度O(1)、O(N)
场景:队列、消息排队、异步逻辑处理、文章列表、数据分页展示(有序的)
Quicklist,listpack-压缩列表
Hash:
string类型的field和value的域值映射表,key是哈希表名,ziplist、字典hashtable实现
适合用于存储对象。
链式hash,指向下一个hash,其中hash值相同的键值对链接,减少hash冲突,查询耗时增加,O(n),rehash扩展-两个Hash表-交替使用-迁移-量大阻塞-触发条件负载因子1 or 5和持久化,渐进式rehash-多次迁移-表2插入,查询表1表2,表1只减不增
场景:存储用户信息、分布式生成唯一ID(随机表)
Set:
String 类型的无序无重复集合,无序唯一键值对
内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL
整数集合intset、字典hashtable实现
Intset有序无重复,自动选择读,二分法查找,
场景:标签(文章分类)、去重(共同好友)、随机化展示
Zset:
String 类型的无序无重复集合,每个member关联一个score,
score可以重复,按照score排序,
Ziplist、skiplist跳表实现
skiplist跳表:范围查询-常数复杂度获取权重、哈希表实现,多层的有序链表,快读定位数据,O(logN)
场景:排行榜,IM最近会话列表
(13)Redis的持久化方式

区别:备份模式、间隔时间、数据格式、是否阻塞
全量模式:
描述:RDB(快照模式),dump.rdb ,Redis将内存中的所有数据全量写入到文件中,save 900 1, save RDB,不会fork,阻塞。bgsave #会fork一个新进程,系统自动触发也是使用的bgsave,非阻塞式。
优点:每隔一段时间进行所有数据的备份,灾备简单、远程传输,只需要fork一个子进程,不影响主进程。
缺点:故障丢失最后一次所有数据备份,数据备份时,导致内存膨胀两倍,多了负载内存CPU卡顿。突然中断无法保证数据强一致。
场景:适合于大规模的数据恢复,并且还原速度快,如果对数据的完整性不是特别敏感(可能存在最后一次丢失的情况)
增量模式:
描述:AOF(追加/日志模式),默认存储文件为appendonly.aof,存储 Redis 服务器已经执行过的的命令,并且只记录对内存有过修改的命令。以日志的形式来记录用户的请求写操作,以追加的形式进行记录到aof文件中,
写入机制:内容放到内存缓冲区,填满才落盘。越早地把命令写入到磁盘中,发生意外时丢失的数据就会越少。
优化:重写机制-长期运行-合并历史记录,aof文件会越变越长,BGREWRITEAOF,新的 aof 文件,体积会小,不会被阻塞。
自动触发AOF重写:当前文件的容量是之前的两倍,当前文件大于64mb。
(14)Redis集群的演进
主从集群:
主-可读写,从-可读。
主从同步/复制:SYNC--BGSave-发送快照-复制加载-缓存命令同步
优点:解决单机并发量大问题,分担主节点的读压力,读写分离,可用性和性能,哨兵的基础,异步方式-同步,仍然可以响应客户端。
缺点:数据不一致性,不能自动容错和恢复,主从切换-人为操作费用高。
哨兵集群:
主从复制+主节点故障转移
特点:哨兵)统一配置管理(主从地址、监控正常、通知问题、故障迁移-主从切换
核心:Raft算法
适合:分布式系统,系统容错,以及Leader选举
原理:哨兵定期向主从+其他哨兵发送ping命令,如果主服务器有效回复超时,标记为主观下线,所有哨兵以每秒一次的频率持续向主服务器确认,多数同意才能标记为客观下线,此时Info命令频率改变。如果数量不够就不能标记客观下线,直到返回有效回复,移出主观下线状态。
优点:
主从模式的升级,提高了系统的可用性和性能、稳定性
自动进行故障恢复
哨兵与哨兵之间、哨兵与master之间能够进行及时的监控,心跳检测
缺点:
一主多从的模式会遇到写的瓶颈,故障恢复的时间长,写的业务就会受到影响
增加了系统的复杂度,需要同时维护哨兵模式
Redis集群:
描述:redis数据分布式存储、分片、不同节点不同内容、收缩-故障恢复、扩容
目的:读写性能受限、扩容、单机存储
特点:至少3主3从,不同的配置文件。
主节点-读写-slot集合,从节点-备份、故障转移、读写分离。
每个节点负责部分hash槽,每个槽存放数据。
ClusterNode-元数据信息。
节点通信:meet/ping、pong
优点:去中心架构,故障转移-主从切换,可以实现读写分离,高速查询效率(哈希槽),不同节点存储不同内容--分片--避免单机缓存问题,扩容收缩--横向纵向扩展能力
缺点:数据一致性,冷备,架构复杂
(15)综合系统设计
1、set的使用:抽奖系统(数据结构、负载均衡、网关限流、分布式缓存等)

a.基本命令操作:
SADD增加元素
SREM 删除元素
SISMEMBER,查询某个 value 是否存在,相当于 contains
SRANDMEMBER,随机获取元素
SINTER/SUNION/SDIFF:交并差集
SCARD,获取长度/总个数
SINTER/SUNION/SDIFF+STORE:存储到某个key
b.需要考虑的情况:
静态资源放到cdn:抽奖活动的页面中,大部分内容都是静态的,只有抽奖按钮需要与服务端交互;对此可以通过客户端、CDN缓存等提升用户体验。
防用户误操作:客户端请求的时候判断时间是否在活动范围内,
防刷:营销活动是拿真金白银来推广,所以需要有效的机制能防止被人恶意攻击,将全部奖品刷走。防恶意注册用户、防恶意调用接口、防奖品被少部分人获取
高并发:当抽奖并发量大时,写DB的压力会很大。前端发送请求队列化处理,避免用户不停点击,造成大量请求,高并发的核心思路是逐级分流,通过缓存、队列、消息等手段将大流量逐步分散。缓存:不常变动、实时性要求不高、频繁变动不持久化、合适数据结构、缓存失效算法。以空间换时间,通过缓存来提升每个请求的处理速度,提升系统并发量。异步处理,分析并识别出可以异步处理的逻辑,将他们异步化。分层逐级拦截非法请求,仅让有效的请求到达底层系统;尽可能让每一次写操作都能成功。根据每个系统的服务能力,设定流量极限,流量超过极限值后进行限流。
具体采取哪种策略看具体的需求, 对数据的准确性实时性需求、性能需求等. 可以同时结合多种策略. 以及时间间隔也取决于产品需求和刷新耗时.
高可用:多实例部署;营销系统内部无状态,并可以通过水平扩展,提升系统性能。隔离技术的核心是防止压力、异常等相互传导,导致服务不稳定甚至不可用。限流技术,业务上主要通过计数器的方式进行防刷性限流
防止奖品超发:乐观锁、悲观锁、分布式锁。同步队列。缓存+异步。具体采取哪种策略看具体的需求, 对数据的准确性实时性需求、性能需求等. 可以同时结合多种策略. 以及时间间隔也取决于产品需求和刷新耗时.
电商秒杀:(类似)
超卖(分布式锁),请求-秒杀-访问/查询库存-下单-扣除/更新库存,消息队列限流
2、zset 的使用:排行榜 ,IM最近会话列表

a.基本命令操作:
ZSCORE,获取指定 value 的 score
ZRANK,确定某个值的排名
ZRANGEBYSCORE,根据分值区间遍历zset,分值区间内排名
ZREM,删除value
ZINCRBY key increment member,自增,数据和排行问题,描述:有序集合中对指定成员的分数加上增量 increment,比如你要给某个直播间做排行榜,key就是直播间相关的key,member就是邀请人的标识(一般就是userId),incrementScore就是这个人邀请的人数自增量,比如微博热搜排序,key就可以是小时榜/天榜/月榜,member是某一条热搜词条,incrementScore就是这个词条热度增量/权重增量),
ZREVRANGEBYSCORE key max min [WITHSCORES],根据分值区间遍历 zset,分值区间内排名。
b.需要考虑的情况:
为什么使用Zset:首先排行榜明显是一个热点数据, 访问频率大, 且计算复杂. 肯定不能直接从数据库中读取计算排名, 否则服务很容易挂掉。所以只能用缓存,而zset 是一个有序列表, 满足排序需求,redis 数据存在内存中, 存取效率高。其中zset 使用ziplist 或 skiplist+map实现. 直接查询用户积分时间复杂度低。
基本结构:对于整个排行榜, 我们用 zset 保存排行榜数据, key 为排行榜信息, member 为用户id, score 存储用户积分。用户信息(排行榜需要的头像昵称) 再用string或hash结构存储。
相同积分下的排序--score 设计:zset对于score相同的排序是按照key的map字典序排的,所以我们考虑在score里面加入时间信息,比如score = 积分 * 1E10 + 最大时间 - 当前时间,注意生成的score最大值不能越界.如果排行榜是临时的,超过某个时间就不存在或不保证数据的准确性, 那最大时间直接取排行榜的截止有效时间就可,这种方式时间信息占用的位数较少。如果排行榜一直存在就取固定值, 根据实际业务使用固定最大时间,满足实际业务场景。
缓存的定时刷新保证数据准确性:虽然我们将排行榜数据存入zset中, 但这个只是提高了我们的访问效率, 并不能完全保证数据的准确性和最终一致性. 可能会因为各种原因(高并发, 网络异常)导致缓存数据不准确, 因此需要定时刷新缓存数据.
缓存刷新策略:
全量刷新: 把所有缓存数据都重新计算一遍, 比如每天(一定时间内)刷一遍
增量刷新: 把一定时间内变化的缓存数据刷新, 每个小时刷一次
根据数据变化频率动态刷新: 类似redis持久化策略. 一定时间内变化的频率到达一个阈值就刷新.
具体采取哪种策略看具体的需求, 对数据的准确性实时性需求、性能需求等. 可以同时结合多种策略. 以及时间间隔也取决于产品需求和刷新耗时.
预防缓存击穿的必要性:如果缓存过期后用户访问排行榜, 这个时候就需要从数据库中查询相关数据, 重新计算排行榜前n位, 假如这个时候是大量用户并发访问, 然后查询排行榜缓存, 发现没有数据, 于是都去查询数据库重算. 这个时候数据库压力就会很大, 很容易挂掉. 即缓存击穿.
预防缓存击穿的解决方式:
a.不设置过期时间, 不过期就不会失效.
b.加锁, 重新加载缓存的时候加锁, 防止所有的请求都去数据库查询重算.
然后结合具体场景使用,具体采取哪种策略看具体的需求。
以上是关于大数据存储技术期末复习(自用)的主要内容,如果未能解决你的问题,请参考以下文章