Java JDBC的优雅设计
Posted 蘑菇君520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java JDBC的优雅设计相关的知识,希望对你有一定的参考价值。
JDBC是什么?
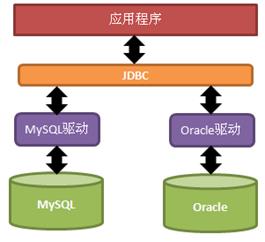
JDBC全称是:Java DataBase Connectivity, 即Java数据库连接,它是Java平台下的技术规范。定义了在Java语言中,该如何去访问数据库,执行SQL语句,开启事务等一系列与数据库相关的操作。
JDBC是一种规范,规范嘛,就是定义一些抽象,告诉你咱们这可以干啥。那具体该怎么干呢,那就是具体的数据库厂商去考虑的了。不同的数据库厂商会提供相应的JDBC规范的实现,即驱动,供我们在Java代码中操作他们的数据库。
为什么需要JDBC?
假如Java平台没有这个数据库访问的规范,我们还能正常用数据库么?
自然是可以的,只要mysql, Oracle依然给我们提供访问支持。
举个栗子,假如MySQL给我们提供mysql-connector.jar, 里面有个MySQLManager类可以访问MySQL数据库:
public class MySQLManager
public MySqlConnection getConnection()
// 建立MySQL的连接
public void executeStatement(MySqlStatement statement)
// 执行sql语句
Oracle提供oracle-connector.jar, 里面有个OracleManager类可以访问Oracle数据库:
public class OracleManager
public OracleConnection getConnection()
// 建立Oracle的连接
public void executeStatement(OracleStatement statement)
// 执行sql语句
好,我有一个朋友,叫小毛(不是我… o(╥﹏╥)o),假如他公司之前用Oracle数据库,所以他在Java程序里引入了oracle-connector.jar,将Oracle数据库用的是风生水起,一切都很正常。直到一个冬天,他们公司穷困潦倒。CTO说,Oracle虽然好用,但是收费太高,我们还是换成免费的MySQL吧。小毛只好引入mysql-connector.jar,然后加班加点将代码里所有OracleXXX相关的类换成了MySQLXXX。
看到这里,大佬们应该都知道为什么需要JDBC了。天下数据库千千万,如果所有数据库都提供不同的操作方式,那么开发人员在操作不同数据库的时候得累死。而Java这种大平台,就站出来了:爸爸给你们提供一套统一的接口,你们怎么做我不管,但是要符合我定的规范,实现规范里的功能即可。
你会如何定义JDBC规范
接下来我们该去看看JDBC规范里定义了哪些接口。
那在看接口之前,我们自己来脑补一下,访问数据库需要哪些接口?
我们操作数据库,最简单的流程:
1. 建立数据库连接 (小老弟来登门拜访,联络感情)
2. 执行SQL语句 (最近手头有点紧,大兄弟借个钱呗)
2.1 执行成功,返回结果 (谢谢大佬救命之恩)
2.2 执行失败,抛出异常 (从未见过如此小气之人)
3. 关闭连接 (有空再联系,拜了个拜~)
看上面这个流程,不难想到:
- 我们得有个接口
Connection来描述一个连接吧,毕竟数据库的所有操作都建立在连接的基础上 - 在一个连接中,我们能执行SQL语句,那么语句也是一个接口
Statement - 执行语句后,比如查询语句,还得获取返回结果吧。这返回的结果也是一个接口
ResultSet - 建立连接,执行语句的过程中会遇到各种错误,那我们得搞个异常类来表示吧
SQLException - 谁来建立和关闭连接呢?所以还需要一个驱动类
Driver,来表示某个数据库的驱动,从驱动中获取连接,以及驱动的基本信息。
当当当,上面就是蘑菇君想到的最简化的一个JDBC规范了。好,MySQL,Oracle,SQL Server你们这些小老弟们,按照爸爸的要求,去给我实现一下,Thanks♪(・ω・)ノ。(啪,我死了)

正经JDBC的规范
现在咱们看看代码,求证一下JDBC规范里定义了哪些重要接口,跟蘑菇君 yy 的是不是差不多。
以下的代码的版本基于JDK 8, JDBC 4.2。
JDBC相关的类和接口在java.sql和javax.sql包下面。

我们上面猜想的接口都出现在了java.sql包里。除此之外呢,我们来看看还有哪些额外的东东:
数据类型
既然JDBC要一统数据库的访问接口,那么肯定要定义一些数据类型的接口,声明自己支持哪些数据类型。而数据库厂商就得向JDBC里定义的数据类型靠齐,提供支持。
JDBC中有个SQLType接口,来表示通用的SQL数据类型:
public interface SQLType
/**
* @return The name of this @code SQLType.
*/
String getName();
/**
* @return The name of the vendor for this data type
*/
String getVendor();
/**
* @return An Integer representing the vendor specific data type
*/
Integer getVendorTypeNumber();
同时,JDBC中有个枚举类JDBCType, 里面定义了JDBC支持的数据类型:
public enum JDBCType implements SQLType
/**
* Identifies the generic SQL type @code DECIMAL.
*/
DECIMAL(Types.DECIMAL),
/**
* Identifies the generic SQL type @code CHAR.
*/
CHAR(Types.CHAR),
/**
* Identifies the generic SQL type @code VARCHAR.
*/
VARCHAR(Types.VARCHAR),
/**
* Identifies the generic SQL type @code BLOB.
*/
BLOB(Types.BLOB),
/**
* Identifies the generic SQL type @code DATE.
*/
DATE(Types.DATE),
/**
* Identifies the generic SQL type @code TIMESTAMP.
*/
TIMESTAMP(Types.TIMESTAMP),
// 省略...
同时,JDBC也提供了这些数据类型的实现类或者接口,比如java.sql.Date, java.sql.Timestamp, java.sql.Blob (看着很眼熟吧~)。
从开发者的角度看,我们从数据库查询或者发送数据时,就会用到这些数据结构来标识数据库里的字段类型了。
从数据库厂商的角度看,他们就需要将自己支持的类型,与JDBC中的类型匹配起来。以MySQL为例,其驱动jar包里有个MysqlType枚举类就实现了SQLType接口,提供MYSQL支持的所有数据类型,并与JDBC中的数据类型,以及实现类映射起来。
public enum MysqlType implements SQLType
// varchar类型,与String类关联
VARCHAR("VARCHAR", Types.VARCHAR, String.class, 0, MysqlType.IS_NOT_DECIMAL, 65535L, "(M) [CHARACTER SET charset_name] [COLLATE collation_name]"),
// timestamp类型,与Timestamp类关联起来
TIMESTAMP("TIMESTAMP", Types.TIMESTAMP, Timestamp.class, 0, MysqlType.IS_NOT_DECIMAL, 26L, "[(fsp)]"),
// 省略。。。
public int getJdbcType()
return this.jdbcType;
// 将JDBCType转成MysqlType
public static MysqlType getByJdbcType(int jdbcType)
switch (jdbcType)
case Types.BIGINT:
return BIGINT;
case Types.LONGVARBINARY:
case Types.BLOB: // TODO check that it's correct
case Types.JAVA_OBJECT: // TODO check that it's correct
return BLOB;
case Types.TIME_WITH_TIMEZONE:
throw new FeatureNotAvailableException("TIME_WITH_TIMEZONE type is not supported");
...
上面这个MysqlType类就实现了JDBC与MySQL的类型互转。
语句
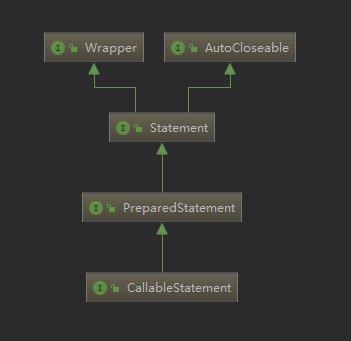
JDBC中定义了三种语句用于执行SQL:
-
Statement:静态SQL语句 -
PreparedStatement:预编译的SQL语句 -
CallableStatement:SQL存储过程语句
接口层次如下:
Statement
创建Statement执行语句,方式如下:
Statement s = connection.createStatement();
// 拼接sql语句
String sql = "insert into t_courses values(1,"+ i + " 数学)";
s.execute(sql);
Statement的用法,咱们直接查API文档即可,就不多说了。
要注意的是,使用Statement执行sql语句,参数拼接容易出错,并且有sql注入的风险。
PreparedStatement
创建PreparedStatement执行语句,方式如下:
public void addCourse(String courseName)
String sql = "insert into t_course(course_name) values(?)";
//该语句为每个参数保留一个问号(“?”)作为占位符
Connection conn = null; //和数据库取得连接
PreparedStatement pstmt = null; //创建statement
try
conn = DbUtil.getConnection();
pstmt = (PreparedStatement) conn.prepareStatement(sql);
pstmt.setString(1, courseName); //给占位符赋值, 占位符索引从1开始
pstmt.executeUpdate(); //执行
catch(SQLException e)
e.printStackTrace();
finally
DbUtil.close(pstmt);
DbUtil.close(conn); //必须关闭
我们能看到,PreparedStatement能够通过设置参数,指定相应的值, 可读性和维护性比较高。这种给参数赋值的方式,可以有效的避免sql注入。
同时,相比Statement,如果我们正确的使用PreparedStatement,是可以大幅度提高性能的。其中缘由呢,可以参考下面的文章,值得一看~
https://www.cnblogs.com/meronzhang/archive/2012/09/28/2707374.html
异常
蘑菇君在上面瞎 yy 的时候提到过,我们需要一些规范来定义,访问数据库过程中遇到的各种异常。
但是问题来了,数据库毕竟是个很复杂的软件,错误类型也是繁杂无比。所以有关部门在制定SQL标准时,制定了SQL状态类型。这个SQL状态类型就跟HTTP的状态码一样,表示一类通用的错误。比如,42000代表语法错误,但是具体怎么错法,还得各数据库厂商去定义。
所以对一个SQL状态类型而言,不同数据库的错误码一般都不一样。比如,重复主键错误码:
MySQL -> 1062
PostgreSQL -> 23505
Oracle -> 1
JDBC定义了一个通用的异常类SQLException:
public class SQLException extends java.lang.Exception
implements Iterable<Throwable>
// SQL状态类型,这是SQL标准中定义的
private String SQLState;
// 错误码,这是厂商定义的
private int vendorCode;
public SQLException(String reason, String SQLState, int vendorCode)
super(reason);
this.SQLState = SQLState;
this.vendorCode = vendorCode;
同时也定义了一些常用的子异常:
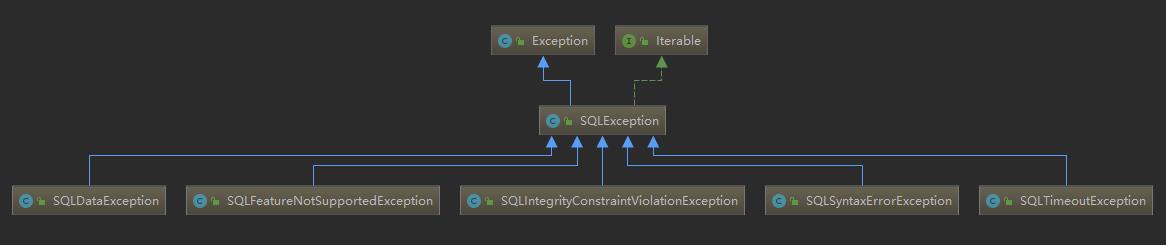
这里要注意的是,这些子异常也都是表示通用的错误类型,比如SQLSyntaxErrorException。如果我们想精确的处理某一具体的错误,比如:
我想针对主键重复异常做一些特殊处理,但是不同数据库的错误码又不同,JDBC也没有定义DuplicateKeyCodesException啊。我们该如何优雅的处理呢?
Spring JDBC中,对这种情况做了灰常优雅的处理。想知道嘛,且听下回分解~
DriverManager
驱动管理器类,顾名思义,负责管理所有的Driver。上面提到过,Driver负责创建应用程序与数据库之间的连接。我们的应用程序可以跟多个数据库勾搭,所以这里是一对多的关系。DriverManager就是用来维护这些关系的。
好,又到了蘑菇君的 yy 时间,DriverManager既然是维护Driver信息的,那么这个类要是我,我该怎么设计呢?
这个类的属性嘛,得需要一个集合来存所有Driver吧,而且要方便获取到某个驱动,那么我选择用Map结构。
// DriverManager是个工具类,所以里面的属性和方法应该是static的
private static Map<String, Driver> driverMap = new HashMap<>();
方法,无外乎是对Driver简单的增删改查:
public static void addDriver(Driver driver)
driverMap.put(driver.getName(), driver);
public static void removeDriver(Driver driver)
return driverMap.remove(driver);
public static Driver getDriver(String driverName)
return driverMap.get(driverName);
来,又到了见证翻车的时刻,看看正版DriverManager是怎么写的:
public class DriverManager
// (1) 线程安全的driver list
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
static
// (2) 初始化drivers
loadInitialDrivers();
println("JDBC DriverManager initialized");
// (3) 获取连接
public static Connection getConnection(String url) throws SQLException
// (4) 获取driver
public static Driver getDriver(String url) throws SQLException
// (5) 注册driver
public static synchronized void registerDriver(java.sql.Driver driver)
// (6) 反注册driver
public static synchronized void deregisterDriver(Driver driver)
emmmm… 跟预料之中几乎差不多嘛,啊哈哈哈哈哈哈…(尴尬又不失礼貌的微笑)
(1) 用的是线程安全的CopyOnWriteArrayList来保存Drivers,因为有多线程并发操作Driver的情况。这里为啥不像我猜测的那样用一个Map来保存呢?是因为Driver接口是没有name属性的,所以不好通过一个key去标识一个Driver
(2) 初始化drivers,这代码放在静态代码块里,也就是在用到DriverManager的时候,就会通过Java的SPI机制去扫描Classpath,找到所有jar包里的META-INF/services/java.sql.Driver文件,并加载其中的Driver类。(SPI是什么?Java重要知识点,要考的哦)
以MySQL为例,就会加载下图中的MySQL的驱动类:
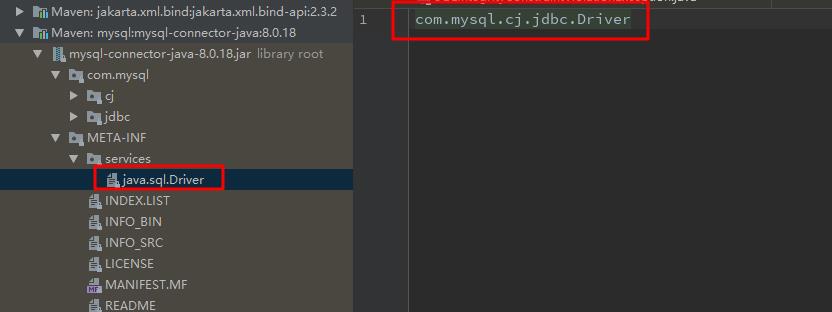
(3) 获取连接。getConnection(String url),这个方法我们应该挺熟的,通过数据库的连接url去建立一个连接。这是一个快捷方式,其实里面还是调用了Driver.connect(url)方法去获取Connection
(4) 通过url去获取一个driver,这个是比较合理的,url里就有数据库的地址。
扩展规范
在javax.sql扩展包里,对JDBC规范提供了许多额外的补充。比如:
- RowSet
- 数据源
- 分布式事务支持
RowSet
RowSet 扩展了ResultSet, 并以一种更灵活,更易于使用的方式保存table数据。更多用法可见:
https://www.docs4dev.com/docs/zh/java/java8/tutorials/jdbc-basics-rowset.html
数据源
使用JDBC数据源可以访问JNDI、连接池、分布式事务等等。我们的应用程序在访问数据库时,多数都用到了数据库连接池。业界也有很多有名的数据库连接池,比如c3p0, Druid, Hikari等等,都实现了DataSource接口。
数据库连接池的实现那是相当讲究了,可扩展和可考虑的点灰常之多。以后会写系列学习文章来分析。
分布式事务支持
这也是个很大的话题了,占个坑,以后再聊~
总结
曾经有个智者,布吉岛式水朔德斯基,说过一句话:
软件开发中遇到的所有问题,都可以通过增加一层抽象而得以解决
JDBC也是一层抽象,将不同数据库的访问逻辑抽象出来,提供统一的数据访问形式。
通过对JDBC规范的学习,可以了解规范背后的设计理念和方式,也能间接的提高自己的认知。同时,在学习的过程中,也能发现更多的知识点,比如Java的SPI机制,线程上下文加载器,错误码异常统一处理,连接池等等(可以等后续蘑菇君的相关文章( ̄︶ ̄))。
参考资料
JDBC API 官方文档:https://docs.oracle.com/javase/8/docs/technotes/guides/jdbc/
SQL状态类别码:https://www.ibm.com/support/knowledgecenter/SSEPEK_10.0.0/codes/src/tpc/db2z_sqlstatevalues.html#db2z_sqlstatevalues__code23
题外话
我是蘑菇君,我为自己撒盐 (っ•̀ω•́)っ✎⁾⁾
以上是关于Java JDBC的优雅设计的主要内容,如果未能解决你的问题,请参考以下文章