Hadoop集群搭建(一主二从)
Posted 人生短短几个秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群搭建(一主二从)相关的知识,希望对你有一定的参考价值。
Hadoop集群搭建(一主二从)
Hadoop集群搭建
前言
Hadoop集群的搭建,分布式文件系统HDFS提供了基础存储支持,需要存储的数据被HDFS切割成块分布到集群环境当中进行存储,具有高容错、高可靠性、高可扩展性、高获得性、高吞吐率。
基于HDFS搭建的Hadoop集群环境,对于硬件的要求不高,普通的商用机器就能支持,在集群中(尤其是大的集群),节点失败率是比较高的HDFS的目标是确保集群在节点失败的时候不会让用户感觉到明显的中断。
本文主要为搭建一个主节点,两个从节点
一、VMware安装,以及jdk,Hadoop安装包
- VMware 安装步骤,见:VMware安装.
- jdk安装包: jdk-8u171-linux-x64.tar.gz
- hadoop安装包: hadoop-2.7.7.tar.gz
链接:jdk+hadoop
提取码:ayi9
二、在VMware中安装CentOS 7
下载CentOS 7阿里云的镜像:http://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/
选择镜像:CentOS-7-x86_64-Minimal-2009.iso
接下来的工作就是在虚拟机上进行了!
首先创建一个新的虚拟机。

我们这里选择自定义,然后点击下一步
下一步

设置CentOS-7 镜像,镜像我放到了E盘,点击下一步

设置虚拟机位置(G盘)

使用推荐内存
一直点击下一步了,直到
开启虚拟机,鼠标选中Install CentOS 7,选中后别怀疑,直接回车;
加载完成后,进入安装界面,选中简体中文,点击继续。
设置安装位置,选择磁盘
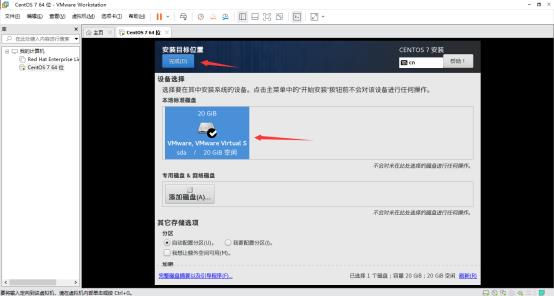
设置网络和主机名
 打开以太网开关
打开以太网开关
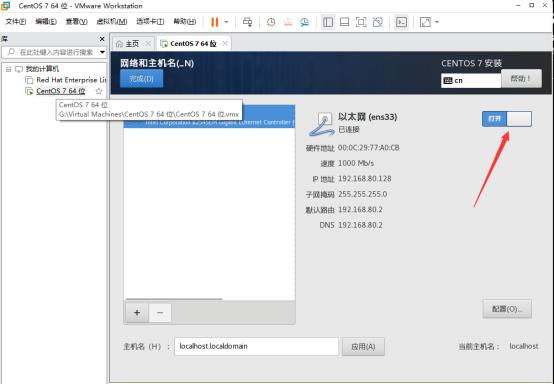
点击配置
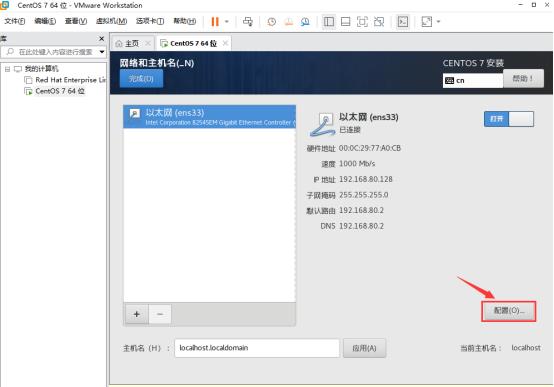
编辑ipv4,根据如下进行编辑
方法改为手动,记住IP地址,子网掩码,以及网关。DNS服务器选用阿里的DNS:223.5.5.5,223.6.6.6,勾选“需要IPv4地址完成这个连接”。
最后保存。

随后,更改主机名,我这里将它设置为localhost。
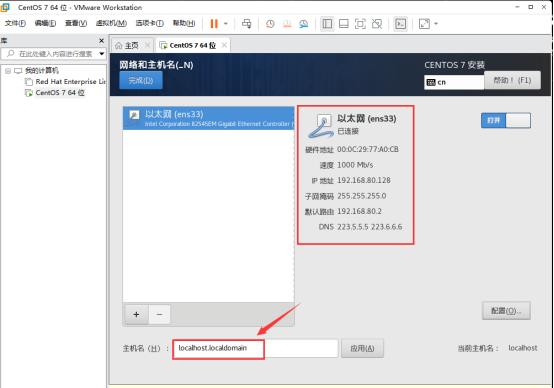
主机名修改后,点击完成
显示“ens33已连接”

点击开始安装,
配置root 密码,我这里密码简单设置为123456
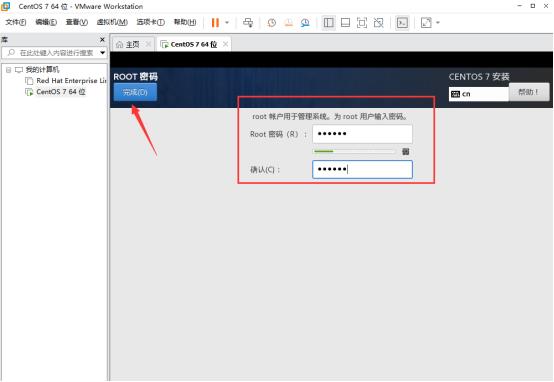
等待等待等待,一直等待

安装完成后,点击重启

在localhost login处输入root,密码为123456;回车
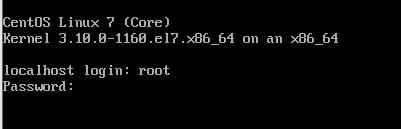
如图则表示安装成功

输入测试命令:ping www.baidu.com,如图,则连接成功(使用ctrl+c结束命令)此时,CentOS 7安装成功

三、XSHELL和XFTP下载与安装
官网地址: https://www.netsarang.com/zh/free-for-home-school/
填写下姓名,邮箱,下载链接将发送至邮箱
这个安装的话就很简单了,直接下一步就好。

更新一下yum源,运行命令yum -y update。当看到Complete!表示更新完成。
将系统的防火墙关闭。输入下面两个命令。
systemctl stop firewalld.service //临时关闭防火墙
systemctl disable firewalld.service //永久关闭防火墙

输入vi /etc/selinux/config,关闭Linux系统内核SELinux
找到SELINUX,将其改成SELINUX=disabled。
然后按下键盘的esc键,输入**:wq**进行保存并退出。w 指令表示写入文件,q 表示退出。
**切记:**下面的输入一定要正确输入,一定正确保存!!!虽然我也不知道为什么保存后,最后又没了,我只能反反复复检查,重新写入。


之后输入reboot命令回车重启系统,使命令生效。重启之后输入:/usr/sbin/sestatus -v 查看SELinux是否被禁用
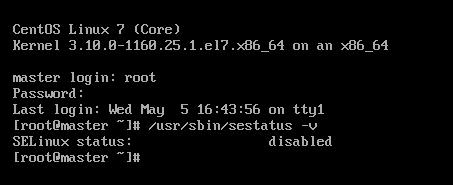
然后输入yum install vim -y 安装vim编辑器
输入:vim /etc/hosts
编辑hosts文件,后面配置虚拟机将IP先添加到hosts当中。

localhost 的IP地址为安装虚拟机时的IP地址,即:192.168.80.128
a1的IP地址为上面128+1,即192.168.80.129
a2的IP地址为上面128+2,即192.168.80.130
输入完成后,保存退出。
方法同上,即按下键盘的esc键,输入**:wq**,后面不在赘述。
紧接着,在root下创建Hadooptools文件夹。依次输入如下命令(mkdir命令用于创建目录):
cd /root
mkdir Hadooptools
cd Hadooptools
接下来,打开XFTP,新建会话。
主机:192.168.80.128
用户名:root
密码:123456

将Hadoop安装包里jdk-8u171-linux-x64.tar.gz和hadoop-2.7.7.tar.gz拖拽至/root/HAdooptools文件夹下

上传结束后,检查是否上传成功。在虚拟机中使用命令:cd /root/Hadooptools,进入Hadooptools文件夹中,输入:ls

分别解压两个安装包
tar -zxvf hadoop-2.7.7.tar.gz
tar -zxvf jdk-8u171-linux-x64.tar.gz
解压完成后,进行jdk的安装和配置
依次输入:
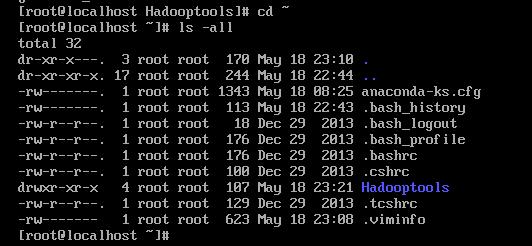
cd ~
ls -all
如下图
继续输入:vim .bash_profile
修改文件:
export JAVA_HOME=/root/Hadooptool/jdk1.8.0_171
export PATH=$JAVA_HOME/bin: $PATH
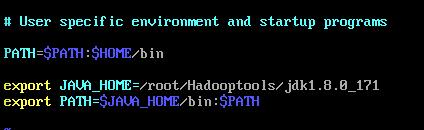
保存退出后,输入命令:source .bash_profile 使输入生效
最后检查jdk是否配置成功。输入:java -version

如图所示,则配置成功,输入:shutdown now 关闭虚拟机
五、克隆虚拟机,配置主机,搭建集群
修改目前的虚拟机名字为localhost
注意:虚拟机须在关闭状态才可以克隆。如图:
克隆虚拟机:右键—>快照—>快照管理器

点击“当前位置” ,克隆
 创建完整克隆
创建完整克隆

将虚拟机名称命名为:a1


重复克隆操作:克隆名为a2 的虚拟机


如图所示:克隆完成

依次启动3个虚拟机,修改其IP地址。
进入a1虚拟机,输入命令:vim /etc/sysconfig/network-scripts/ifcfg-ens33
将IPADDR修改为192.168.80.129
保存退出,输入: service network restart 使配置生效

类似地,配置a2的IP地址,将其修改为192.168.80.130,同样保存退出,输入:service network restart
随后,修改主机名,分别在a1, a2中输入:
hostnamectl set-hostname a1
hostnamectl set-hostname a2
输入logout,登出。
再次登录,即如图所示:

然后在localhost中分别输入以下命令:
ping localhost
ping a1
ping a2
如图:
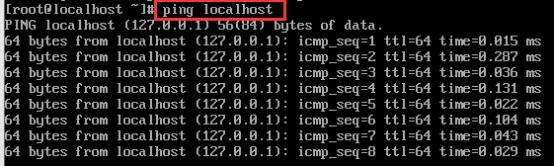
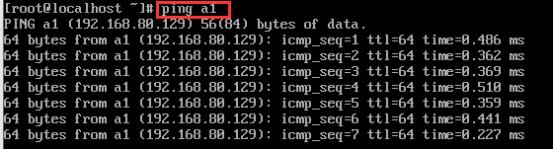

成功!
六、使用Xshell连接虚拟机
打开Xshell, 点击新建会话,设置如下:
名称:localhost
协议:SSH
主机(IP地址):192.168.80.128
点击确定
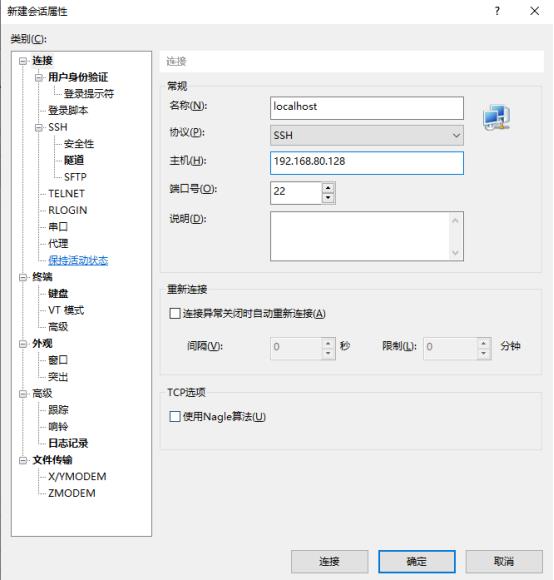
用户身份验证,用户名为:root 密码:123456
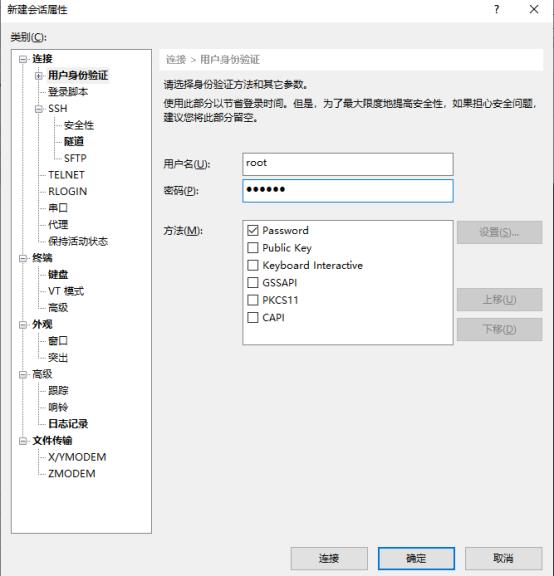
点击隧道,X11取消勾选,如图所示:

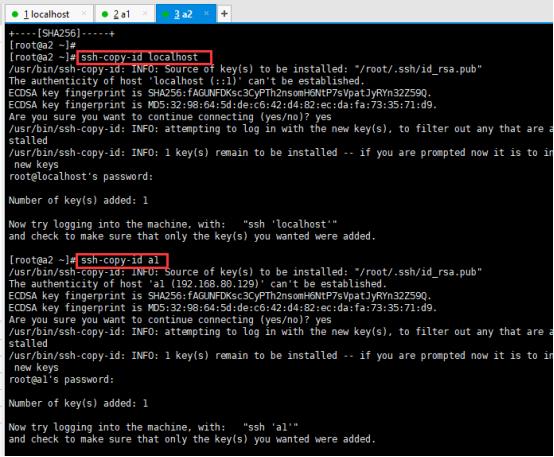
连接三个会话,在xshell中制作免密码登陆,在localhost中输入以下命令:ssh-keygen -t rsa 然后一直回车直到命令结束。
相同的操作分别在a1,a2中进行完成。

在localhost中依次输入下面命令:
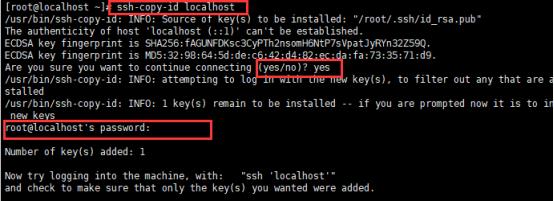
ssh-copy-id localhost
ssh-copy-id a1
ssh-copy-id a2
然后根据提示输入localhost,a1,a2的密码,从而实现对登陆的免密操作。
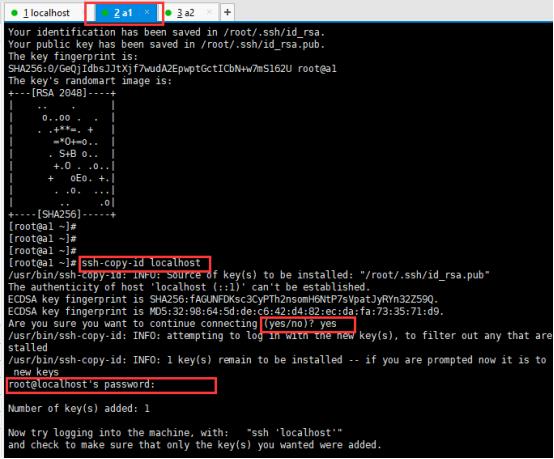
在a1中输入下面命令
ssh-copy-id localhost
ssh-copy-id a2
在a2中依次输入以下命令:
ssh-copy-id localhost
ssh-copy-id a1
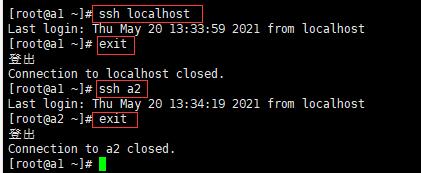
通过ssh命令测试看是否设置免密登陆成功,如下图操作:

a1中
a2中
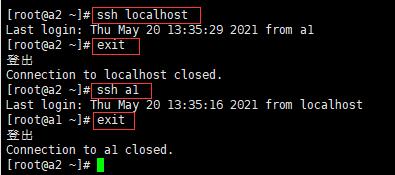
localhost,a1,a2配置时间同步:
在localhost,输入:crontab -e
输入:0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org,保存并退出
输入clock检查时间是否正确。

a1,a2同上。
七、配置Hadoop
下面的操作均在localhost上进行,只需将localhost操作里的修改命令复制粘贴到a1,a2即可。
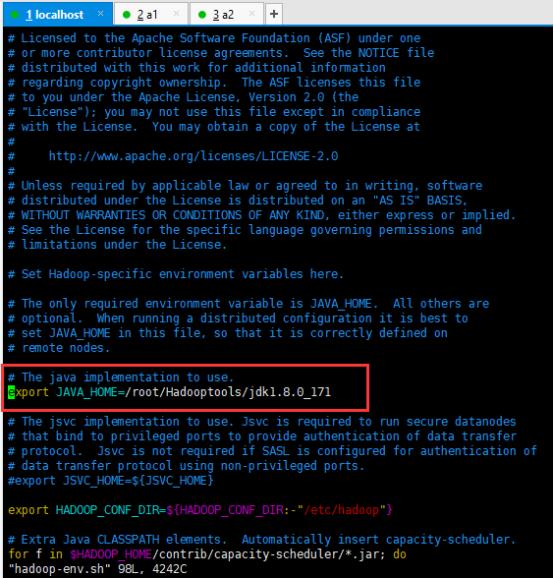
1、 修改:hadoop-env.sh
进入hadoop-2.7.7文件:cd /root/Hadooptools/hadoop-2.7.7/etc/hadoop/
修改hadoop-env.sh:vim hadoop-env.sh
将export JAVA_HOME修改为下面的值,然后保存并退出。
# The java implementation to use.
export JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
2、修改yarn-env.sh
输入:vim yarn-env.sh
修改JAVA_HOME,然后保存退出。
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/root/Hadooptools/jdk1.8.0_171
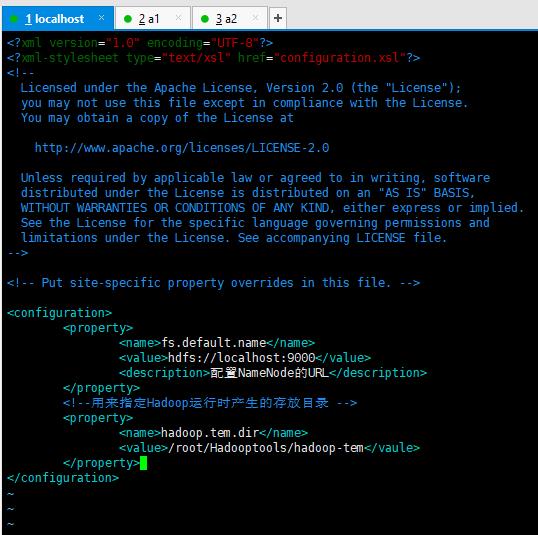
3、修改core-site.xml
输入:vim core-site.xml
将下面内容复制粘贴到文件中,然后保存退出。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
<description>配置NameNode的URL</description>
</property>
<!--用来指定hadoop运行时产生的存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/Hadooptools/hadoop-tmp</value>
</property>
</configuration>
如图:
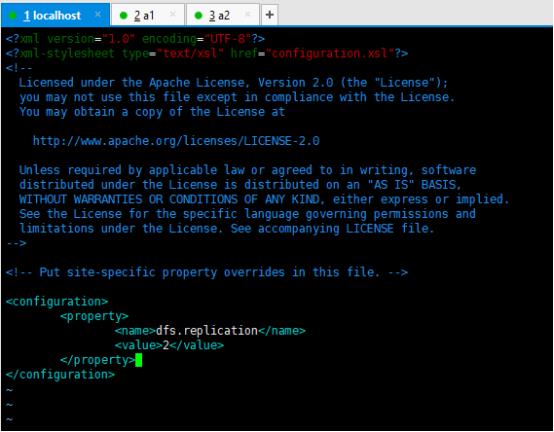
4、修改hdfs-site.xml
输入:vim hdfs-site.xml
将下面内容粘贴到文件中,再保存退出。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
如图:
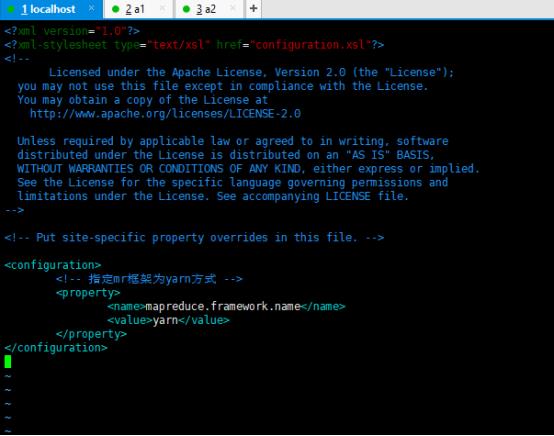
5、修改mapred-site.xml
输入:vim mapred-site.xml
将下面内容粘贴到文件中,保存退出。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
如图:
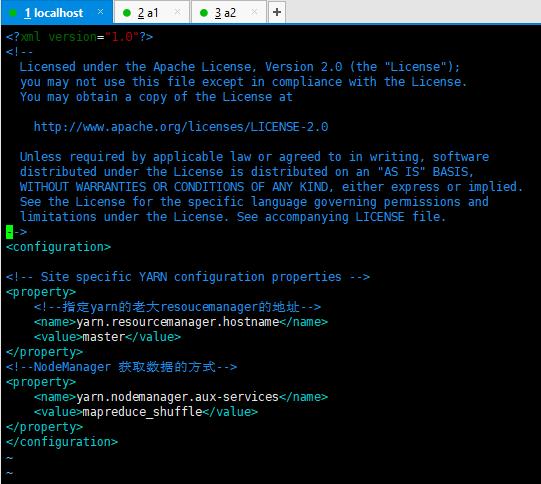
6、修改yarn-site.xml
输入:vim yarn-site.xml
将下面内容粘贴到文件中:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--指定yarn的老大resoucemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--NodeManager 获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
如图:
7、 修改slaves
输入:vim slaves
粘贴以下内容到文件:
localhost
a1
a2
建立hadoop-tmp文件夹
进入到Hadooptools文件夹下,新建文件夹(依次输入):
cd /root/Hadooptools/
mkdir hadoop-tmp
删除a1,a2上的Hadooptools文件夹
依次再a1,a2,上执行,输入下面命令:
rm -rf /root/Hadooptools/
将 localhost上的 Hadooptools文件夹复制到a1,a2上,输入下面命令:
scp -r /root/Hadooptools root@a1:/root/
scp -r /root/Hadooptools root@a2:/root/
配置系统环境变量
输入下面命令:vim /root/.bash_profile
将下面内容添加到文件中:
export HADOOP_HOME=/root/Hadooptools/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
然后执行source /root/.bash_profile,使其生效。
a1,a2虚拟机配置同上。
建议配置完,最后再次检查一遍,我的问题是配置完后再次查看完全被清空,我也不知道原因
最后,格式化hadoop文件系统。
注:该命令只能执行一次不可执行多次。要确保准确无误。
输入:hdfs namenode -format
当看到successful信息时,表明格式化成功。
八、启动Hadoop集群
输入:start-all.sh

根据提示,输入yes。
用主浏览器访问 http://192.168.168.128:50070 查看启动是否成功

显示节点为3,则配置成功。
登陆yarn的WebUI http://192.168.80.128:8088/

测试spark运行是否正常
运行以下命令:
cd /root
./Hadooptools/spark/bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 /root/Hadooptools/spark/examples//jars/spark-examples_2.12-3.1.1.jar 100
打开spark的WebUI查看运行情况
http://192.168.80.128:8080

结束!!!
好复杂!!!
历时好久!!!
本文借鉴链接: 南风未闻.的博客,感谢大佬
以上是关于Hadoop集群搭建(一主二从)的主要内容,如果未能解决你的问题,请参考以下文章
centos7案例实战——redis一主二从三哨兵高可用服务搭建
docker compose搭建redis7.0.4高可用一主二从三哨兵集群并整合SpringBoot图文完整版