本周推荐 | 电商3D购物新体验:AR量脚和AR试戴背后的算法技术
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了本周推荐 | 电商3D购物新体验:AR量脚和AR试戴背后的算法技术相关的知识,希望对你有一定的参考价值。

推荐语:本文结合了工业实际应用,介绍了工程上精心设计量脚交互流程,算法上融合2d检测、3d重建来实现较为精准的量脚流程,并在一系列算法流程计算上,充分考虑到了算法效率,保证了用户体验,具有很实用的价值。
——大淘宝技术算法工程师 尘漠

引言
随着智能手机算力的提升,AR/VR应用的不断涌现,普通消费者对好玩有趣的AR应用接受度和期待越来越高,而3D沉浸式购物,包括各类AR试戴、AR量脚、AR试鞋等,因其广阔的应用前景而获得巨大关注。
例如,基于图像算法的AR量脚可以解决用户网购鞋子时尺码不合脚的问题。用户可以直接通过手机的摄像头、Lidar等传感器拍摄自己的脚并立刻获知脚长,再选购合适尺码的鞋子。该算法可以大大减少退换货的问题出现,提升了用户网购体验。
另一方面,手部商品的AR试戴作为3D沉浸式购物重要的组成部分,有着广阔的应用前景,例如,手表、手机作为重要的电商品类,具有客单价高、销量高的特点,如果能提高这些品类的AR试戴体验,必然能够提高用户的购买意愿。
为了解决AR量脚和AR试戴的实际问题,我们在PixelAI移动端视觉算法库中实现了对应的AR算法,结合2022年双十一,在淘宝App和天猫App中进行了算法到实际产品的落地。具体来说,在AR量脚算法中,我们将目标检测、直线检测、图像分割、三维点云重建等多种算法进行融合,并精心设计了量脚界面和教程,保证用户良好体验的同时,让脚长测量误差处于3mm以内。而基于AR手部算法,我们在天猫App 3D空间中上线了AR手表试戴,AR手机体验和数字戒指商品的AR试戴。本文将着重介绍来自PixelAI移动端视觉算法库的AR试戴、AR量脚两项技术。

AR量脚
▐ 算法线上效果
AR量脚手淘入口
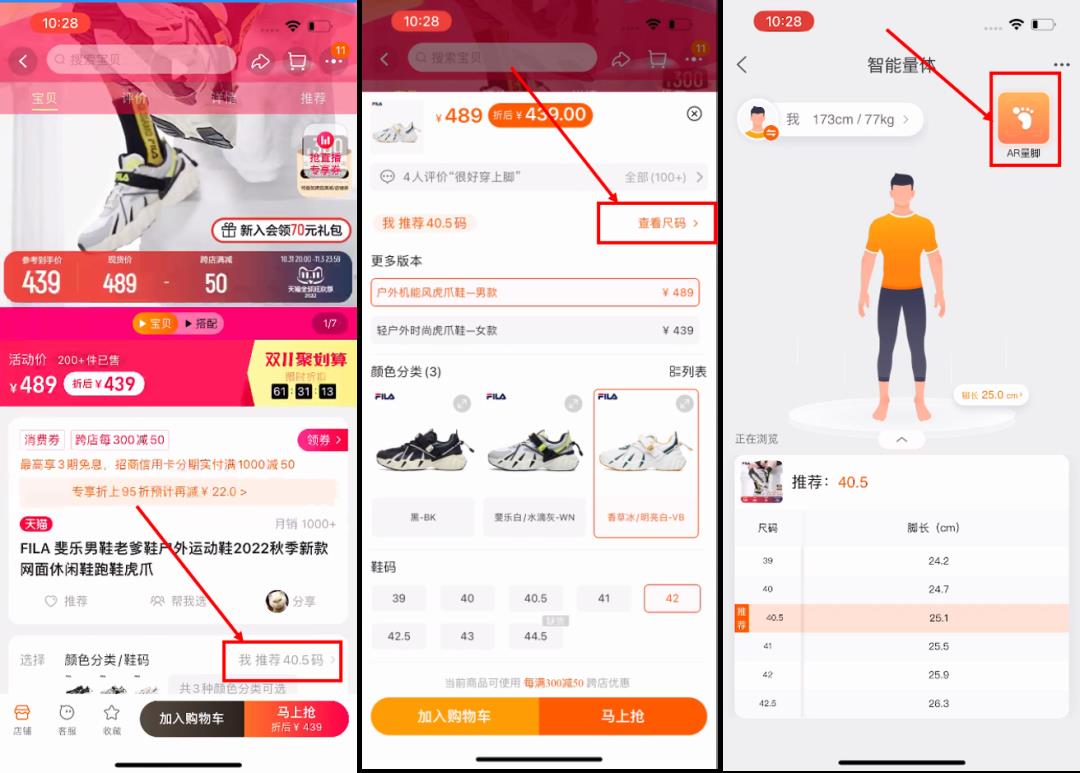
AR量脚线上效果
▐ 界面和教程设计
通过对大量用户的试用调研、收集用户体验痛点后,我们将拍摄脚部的界面设计为一个U型区域,U型的底部和屏幕参考线相切,突出强调脚后跟的U型需要和界面U型重合以及让地面参考线和屏幕参考线重合,减少用户的误操作。同时,我们用橙色U型区域表示脚部放置状态不满足量脚的前提条件,用绿色U型区域表示脚部放置状态满足量脚的前提条件。量脚教程则被浓缩为3个gif动图,更生动简洁,达到“一图胜千言”的效果,大大提高用户的量脚体验。教程gif动图如下所示。



▐ 算法实现
概述
在AR量脚算法中,我们首先使用脚部实时检测算法确保用户的脚满足AR量脚的前提条件。然后我们充分利用相机拍摄的RGB图片、Lidar传感器获取的深度图以及相机内外参数,在同一个三维空间分别对地面和脚部进行三维点云重建。为了区分地面和脚,我们通过分割算法对手机拍摄的图片进行脚部分割,获得脚部的像素区域。同时,为了实现地面脚后跟参考线和屏幕参考线的自动重合,我们加入了直线检测算法,防止用户拍摄过程中因手抖而无法重合两根参考线的问题出现。在得到地面和脚部的点云后,我们再通过脚部点云在地面所处平面的投影区域,计算脚部投影的bbox和脚的长宽。流程如下图所示。

算法模块介绍
脚部检测
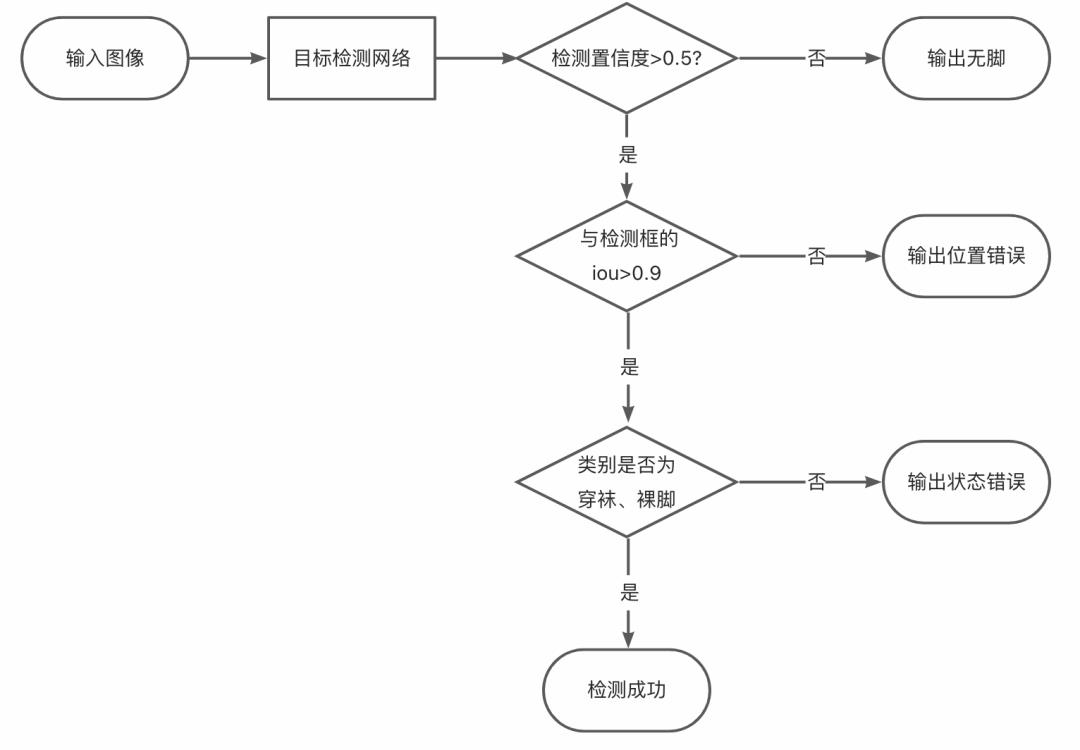
在AR量脚算法中,我们首先通过实时脚部检测算法对相机拍摄的每一帧画面进行检测,判断脚是否存在、是否脱鞋以及是否放在正确的屏幕区域内。只有满足脚存在于画面、脱鞋且位于正确的屏幕区域,用户才可以获得点击测量按钮的权限(按钮从灰色变为彩色,屏幕U型区域由橙色变绿色)。这样的算法约束可以大大减少用户随意拍摄或误操作从而导致测量不准的问题出现。
在检测算法选型与设计上,我们综合对比了NanoDet[1]、yolov5n[2]、yolox-nano[3]等业界常用的实时目标检测算法,最终选用了移动端推理友好、且在低参数量下精度优势明显的NanoDet-Plus模型[1]。为了提高脚部区域的定位能力并不增加额外数据的标注负担,模型首先在一个较大规模的AR试鞋目标检测数据集上进行了充分训练,然后基于该预训练参数在小规模的AR量脚数据集上进行参数调优。在实践中,单纯的目标检测模型容易混淆部分穿鞋和穿袜的图片,因此我们在模型的backbone之后接了一个分类器,并使用focal loss作为监督来提高细粒度困难样本的挖掘能力。检测网络结构和检测结果判断逻辑如下图所示。

脚部检测视频效果:
地面检测
当用户按下测量按钮后,量脚算法正式开始运行。首先是通过Lidar传感器采集的深度图和相机外参对地面进行三维点云重建,此时脚部点云可以被视为噪点。通过RANSAC算法获得地面所在的最优平面方程Ax+By+Cz+D=0。具体步骤如下所述。
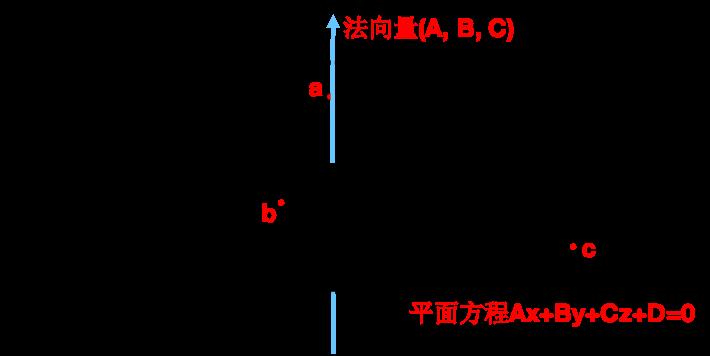
step1:随机选取点云中的3个点a、b、c,构建一个平面,计算得到平面的法向量和平面方程。
step2:计算所有点距离该平面的距离,量化该平面的拟合程度。
step3:多次重复step1和step2,获得拟合度最佳的平面方程。
直线检测
针对用户在量脚拍摄过程中由于手抖无法准确重合地面脚后跟参考线和屏幕参考线的痛点,我们加入了直线检测的功能,让用户即使由于手抖而没有让屏幕参考线和地面参考线准确重合,依然可以通过自动检测地面参考线的算法实现自动重合。
通过对直线检测MLSD[4]、TP-LSD[5]等相关算法的调研,我们针对量脚的业务场景定制了一个直线检测算法。首先针对量脚的业务场景,我们自制了一个高质量脚后跟参考线检测数据集。然后我们针对业务需求,对MLSD直线检测算法进行精简优化,使其聚焦于直线中心点坐标的预测和左右端点相对于中心点的位移的预测,实现更优检测效果。同时针对图像中检测出多条直线的情况,我们使用弗雷歇距离[6]来衡量直线之间的近似度,选择和屏幕参考线最近似的直线作为最终检测结果。视频效果如下所示。
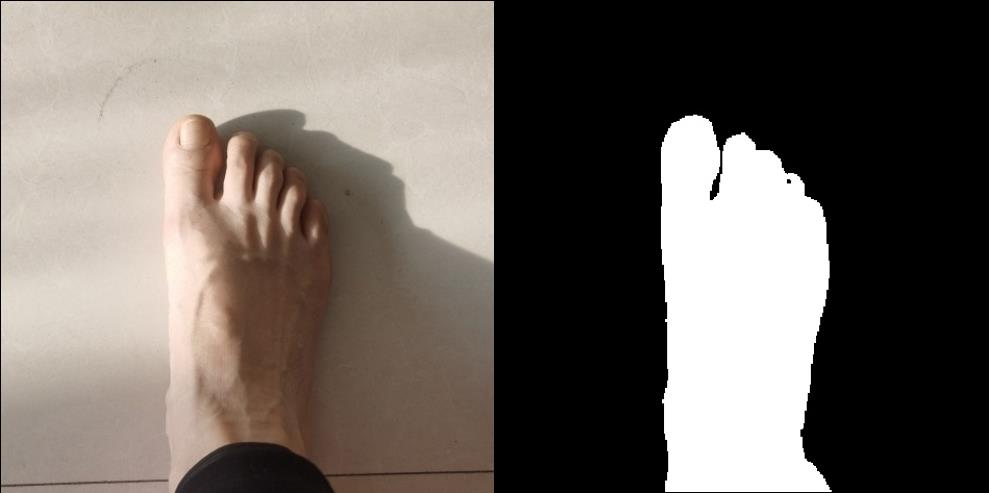
脚部分割算法
脚部分割的准确型会影响脚部三维点云重建的完整度,所以脚部分割算法至关重要。我们针对业务场景自制了一个高质量脚部分割数据集。然后我们对各种成熟的分割算法的调研和实验[7],权衡计算量、准确性等指标后,选出最优分割网络U2-Net[8]进行部署。结构和效果如下图所示。

脚部3D点云重建及脚长测量
在获得脚部分割mask图后,结合深度图,就可以重建脚部三维点云。具体步骤如下所述。

step1:通过分割mask图和深度图对脚部进行3维点云重建。
step2:计算脚部三维点云中每个点距离地面的距离,只保留距离小于0.18m的点云,剔除小腿部的噪点。
step3:将脚部三维点云的每个点投影到地面所在平面,根据投影点集合计算脚部的bbox和脚长宽。
校准微调
由于分割算法、深度图、相机内外参数等输入数据可能存在一定误差,会导致bbox没有完美贴合脚部,导致脚部长度不准,我们增加一个bbox校准操作,通过移动5个校准点,让bbox完美框住脚部,并在移动过程中实时更新脚长值,获得最准确的脚长数据。微调效果如下视频所示。

AR手部试戴
手部试戴相关场景包括AR手表试戴,AR手机体验,用户可以在天猫App 3D空间中体验。

手表试戴
手机试玩
以AR戒指试戴为例,下图展示了算法相关的流程。首先是基于深度神经网络的PixelAI手部3D重建算法,目的是从用户摄像头拍摄的输入图像中恢复用户手对应的3D顶点的坐标;然后是AR层算法,目的是基于重建后的3D手,得到商品需要旋转的Transform矩阵,用来将商品旋转到正确的位姿。AR层算法不涉及深度神经网络。旋转后的3D商品模型会与用户拍摄的手部照片进行合图,得到最终的AR试戴效果。

下面的两个部分将分别介绍手部3D重建算法和AR层算法。
▐ 手部3D重建算法
手部3D重建算法是从单张手部图像恢复手部3D几何信息的深度学习算法。也就是说,输入是一张手部照片或者视频,输出是手部的3D几何信息(输出手部纹理信息的方法不在本文讨论范围内)。
几何信息通常以3D Mesh(网格)顶点坐标的形式表示,以学术界使用最多的手部3D模型MANO[12]为例,输入一组模型的系数,就可以得到768个3D顶点的坐标。基于3D顶点和固定的三角面顶点索引,就能重建整个3D手模型;同样地,基于3D顶点和固定的蒙皮权重,就能得到手部21个关节点的3D坐标。

MANO模型示意图,每个白色的顶点代表一个Mesh点,绿色的点表示手部关节点
技术选型
考虑到MANO模型包含768个稠密的手部顶点,满足大部分手部AR试戴场景的需求,因此我们也采用了MANO模型来进行手部3D重建。实际中,基于神经网络的手部3D重建主要分成两大类方法。
第一类是网络只学习MANO的参数。具体来说,包括表征姿态的pose系数和表针手部形状的shape系数,然后通过后处理中的MANO前向过程,得到手部3D 顶点坐标。第一类方法可以看作是间接学习的方法,优势是得到的3D 顶点坐标包含MANO模型训练数据集中的大量真实手的先验知识,符合手的结构,不会出现怪异的姿势,但缺点是3D顶点坐标投影到图像坐标系后与原始图像中的手不够贴合。
第二类方法是网络直接输出手部3D Mesh顶点,即网络直接回归得到768个顶点的3D坐标(768x3个浮点数)。这种方案的优点是省去了后处理中的MANO前向过程,简化流程,同时这种方案能更精准地建模手的动作。
基于实际的应用场景,我们认为,手部模型更多的是存在比较多的自遮挡,而不容易出现某些顶点偏离很多造成的鬼畜问题。因此我们采用第二类方法,即显式地学习手部3D Mesh的方案。
网络设计
现有SOTA模型(Mesh Graphormer[17], METRO[18])大多采用ResNet50或者HRNet系列的Backbone,因而计算量太大,无法应用到移动端。小模型中精度较高的是快手在CVPR2022上发表的MobRecon[10],这篇论文通过采用2D Keypoints Prediction + 2D-to-3D Lifting的方案,先用真实数据和大量的合成数据预训练Backbone和2D关键点分支,再一起训练网络的全部参数,其中3D部分采用了螺旋卷积模块,用于提高3D部分网络对手部图形结构的感知能力,提高3D重建的精度。
在测试中我们发现,MobRecon存在两方面的问题:1)虽然论文中提出MobRecon的模型在iPhone 12 Pro机型上可以达到83FPS,但实际上,MobRecon转换后的MNN模型在中端android机型vivo Y50上耗时59.6ms,未能达到实时。核心原因是MobRecon的螺旋卷积模块使用了scatter_add 算子,运行比较慢。另一个问题是MobRecon没有学习相机参数的分支,无法将3D顶点准确地投影到图像坐标系。
结合上述的调研分析,我们根据已有方案,从下面三个方面来设计网络:
设计轻量型Backbone+3D Head,采用成熟的残差网络结构,以便能在移动设备上达到实时
借鉴MobRecon网络,增加2D手部关节点坐标预测分支,用于在预训练阶段提高网络对手部特征的提取能力
借鉴SMPL[8]中的弱透视相机学习思路,新增相机参数预测分支,用于将3D手部Mesh顶点投影回2D图像上
基于这些改进思路,我们的算法框架如下:

实验结果
这里是我们的方案与一些SOTA方案的对比:
算法名称 | FLOPs | PA-MPJPE(mm) ↓ | 预测相机内参 | 预测2D关节点 | 是否移动端实时 |
Mesh Graphormer[17] | 4G | 5.9 | ✗ | ✗ | ✗ |
METRO[18] | 4G | 6.7 | ✗ | ✗ | ✗ |
I2L-MeshNet[14] | 4G | 7.3 | ✗ | ✗ | ✗ |
MobRecon[10] | 480M | 6.9 | ✗ | ✓ | ✗ |
Ours | 680M | 6.7 | ✓ | ✓ | ✓ |
可以看到,我们的方案在误差上小于一些服务器端大模型,在精度和速度上达到比较好的折衷。
▐ AR层算法设计
手部3D重建完成后,我们可以实时重建手部的3D模型,并且将手投影回2D图像上。但这距离手部AR试戴还差一步,我们还需要设计利用3D重建结果来调整3D商品位姿的AR层算法,例如常见的PnP[15]算法,PA[19]算法等。这些算法的核心目的是得到一个用来变换3D商品的Transform矩阵,再利用渲染引擎的接口来实时改变3D商品的位置和姿态。实际中对于不同的试戴商品,我们进行了不同的上层AR算法设计。
手表试戴
手表试戴中我们采用了手腕关键点估计算法和PnP算法。概括来说,根据手腕关键点和虚拟手腕模型的对应关系,计算手腕的旋转矩阵R和平移矩阵t,再将R和t作用到手表上,就能得到正确的试戴结果。
手机上手
考虑手机上手到应用场景,我们评估基于PnP的方案是满足业务需求的。借鉴手表试戴的思路,我们将PnP算法迁移迁移到手掌区域上来。由于在试玩手机的过程中,手指是可以变动的,而手掌区域可以近似看作刚体,因此我们利用手掌区域的关键点进行PnP算法。具体来说,选择MANO手模的手掌区域顶点,与当前图像重建的3D顶点的2D投影点进行PnP计算,得到旋转矩阵R和平移向量t,再作用到与标准手模匹配好的手机模型上,就能得到正确的手机位姿。
戒指试戴
戒指试戴的功能是将虚拟的戒指商品放置到用户对应的手指上,达到真实的试戴效果。
相比手机上手中的手掌区域,戒指试戴采用的手指指节区域更小,采用2D投影点误差会更大。同时与手机上手只需要支持手掌不同,戒指试戴需要支持前置和后置摄像头,手掌和手背,以及360度旋转下的效果。在这种设置下,不可避免地会出现许多指节被遮挡的情景,采用PnP的方案效果会比较差。
因此我们进一步提出了利用3D指节坐标来进行试戴的新方案,具体来说:
戒指与手指关节的绑定
在重建好的3D手部模型基础上,我们选择需要试戴的指节的顶点编号,并设置好与戒指正反面的对应关系。
根据手指关节构建forward和up向量
forward和up向量是构建一个局部坐标系的两个参数。我们采用指节的轴向方向为foward,指节的径向方向为forward,构建局部坐标系。
根据局部坐标系旋转戒指
利用LookRotation函数,就可以根据forward和up向量,得到戒指对应的旋转矩阵。

总结
作为提升用户体验的重要技术之一,AR技术在未来的电商、教育、医疗等领域拥有巨大的潜力。随着技术朝着3D化的发展,以及业务上AR和3D需求的增加,PixelAI算法团队正在不断深耕AR相关算法,加速研发各类AR试、AR量、AR扫等算法,充实优化移动端算法库,以更好地支持3D和AR算法在淘宝天猫等各项业务中的落地。

参考论文
[1] RangiLyu K. NanoDet-Plus: Super fast and high accuracy lightweight anchor-free object detection model[J]. 2021.
[2] Glenn J , Ayush C , Alex S , et al. Ultralytics/yolov5: v7.0 - YOLOv5 SOTA Realtime Instance Segmentation[J]. 2022.
[3] Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021[J]. arXiv preprint arXiv:2107.08430, 2021.
[4] Gu G , Ko B , Go S H , et al. Towards Light-weight and Real-time Line Segment Detection[J]. 2021.
[5] Huang S , Qin F , Xiong P , et al. TP-LSD: Tri-Points Based Line Segment Detector[C]// European Conference on Computer Vision. Springer, Cham, 2020.
[6] Fréchet M M. Sur quelques points du calcul fonctionnel[J]. Rendiconti del Circolo Matematico di Palermo (1884-1940), 1906, 22(1): 1-72.
[7] Hao S, Zhou Y, Guo Y. A brief survey on semantic segmentation with deep learning[J]. Neurocomputing, 2020, 406: 302-321.
[8] Qin X , Zhang Z , Huang C , et al. U2-Net: Going deeper with nested U-structure for salient object detection[J]. Pattern Recognition, 2020, 106:107404.
[9] Chen X, Liu Y, Ma C, et al. Camera-space hand mesh recovery via semantic aggregation and adaptive 2d-1d registration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13274-13283.
[10] Chen X, Liu Y, Dong Y, et al. MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 20544-20554.
[11] Zimmermann C, Ceylan D, Yang J, et al. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 813-822.
[12] Romero J, Tzionas D, Black M J. Embodied hands: Modeling and capturing hands and bodies together[J]. arXiv preprint arXiv:2201.02610, 2022.
[13] Tang X, Wang T, Fu C W. Towards accurate alignment in real-time 3d hand-mesh reconstruction[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 11698-11707.
[14] Moon G, Lee K M. I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image[C]//European Conference on Computer Vision. Springer, Cham, 2020: 752-768.
[15] https://en.wikipedia.org/wiki/Perspective-n-Point
[16] Loper M, Mahmood N, Romero J, et al. SMPL: A skinned multi-person linear model[J]. ACM transactions on graphics (TOG), 2015, 34(6): 1-16.
[17] Lin K, Wang L, Liu Z. Mesh graphormer[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 12939-12948.
[18] Lin K, Wang L, Liu Z. End-to-end human pose and mesh reconstruction with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1954-1963.
[19] https://en.wikipedia.org/wiki/Procrustes_analysis

团队介绍
大淘宝技术Meta团队,目前负责面向消费场景的3D/XR基础技术建设和创新应用探索,创造以手机及XR 新设备为载体的消费购物新体验。团队在端智能、端云协同、商品三维重建、3D引擎、XR引擎等方面有着深厚的技术积累,先后发布深度学习引擎MNN、端侧实时视觉算法库PixelAI、商品三维重建工具Object Drawer、端云协同系统Walle等。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。欢迎视觉算法、3D/XR引擎、深度学习引擎研发、终端研发等领域的优秀人才加入,共同走进3D数字新时代。感兴趣的同学可以发送邮件至zhiwen.czw@alibaba-inc.com进行交流。
本文作者:孙泽锋(蛰锋)、王云峰(蔚山)
¤ 拓展阅读 ¤
以上是关于本周推荐 | 电商3D购物新体验:AR量脚和AR试戴背后的算法技术的主要内容,如果未能解决你的问题,请参考以下文章