YOLOv8模型调试记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv8模型调试记录相关的知识,希望对你有一定的参考价值。
前言
新年伊始,ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
值得一提的是,在博主的印象中,YOLO系列都是完成目标检测方面的任务,而YOLOv8中还可进行分类与语义分割任务。
无论哪个YOLOv8模型都有对应的预训练模型。目标检测和分割模型是在 COCO 数据集上预训练的,而分类模型是在 ImageNet 数据集上预训练的。大家只需要下载对应模型即可。
前期准备
首先我们需要下载其源代码:
https://github.com/ultralytics/ultralytics
随后我们使用Pycharm打开下载后的文件。
创建conda环境:conda create -n yolov8 python=3.8
在Pycharm中为项目选择conda环境
安装依赖
随后在我们的pycharm的Terminal中安装所需环境:
这里由于博主将控制台改为了Linux系统的形式,大家使用windows命令即可。
source activate yolov8 Linux下激活
activate yolov8 Windows下激活

对于使用Pycharm连接远程服务器的安装方式,可以先激活conda环境,然后再切换到对应的文件目录下再执行安装命令:

安装所需依赖包:
pip install -r requirements.txt -i https://mirrors.bfsu.edu.cn/pypi/web/simple/
安装成功了,在setting中会显示出来。
注意:其默认下载最新版的,该版本中pytorch下载的为1.13,由于博主没有与之对应的conda环境,导致只能使用CPU进行运行,因此博主需要自己再手动安装一下,大家按照自己所需的即可。
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
简单测试
首先使用他自带的权重文件进行检测测试。
下载权重文件:
https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt
方法一
这里虽然在运行时会自动下载,但有时却容易出错,我们手动下载即可,下载完成后将其放入ultralytics-main\\ultralytics\\yolo\\v8\\detect\\yolov8n.pt目录:同时运行该文件下的predict文件。

运行成功,结果保存在下图箭头所指示的文件夹中:

查看运行结果:总体而言相比较博主原本的模型要强一些。

方法二
在该项目的readme中提到,可以使用一下命令在控制台进行执行
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg"
但这个前提是需要安装:ultralytics
pip install ultralytics
使用自制数据集进行训练
博主的数据集使用的时cadc数据集,其标注方式为VOC格式,我们需要将其转换为yolo格式,并对其进行划分训练集,验证集,测试集。这里我们一定要将其转换为官方格式,避免出错。
注意:大家尽量按照我的这个步骤来进行数据集制作,否则在进行训练时会报错:
FileNotFoundError: train: No labels found in data\\labels.cache, can
not start training.
博主首先来讲一下流程,首先我们需要得到VOC数据集的图像与标注文件,随后我们要将该数据集的标注文件格式转换为YOLO标准格式,随后我们将对数据集进行划分,将图片保存在images中,将标注文件放在labels中,train与val文件夹内的文件分别对应训练集与验证集。
按照上面的说法,我们在使用时只需要给出Annotations和JPEGImage文件夹即可。其余的文件都是通过voc2yolo8.py文件生成的。
完成后的文件目录格式如下:
我们将使用voc2yolo文件来执行该过程:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
# 根据自己的数据标签修改
classes=['car', 'truck', 'bus', 'person']
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('D:/Paper2023/ultralytics-main/ultralytics-main/data/Annotations/%s.xml' %image_id)
out_file = open('D:/Paper2023/ultralytics-main/ultralytics-main/data/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
#difficult = obj.find('difficult').text
cls = obj.find('name').text
#if cls not in classes or int(difficult) == 1:
#continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "")
print(data_base_dir)
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov8_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov8_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov8_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov8_val.txt"), 'a')
print(image_dir)
list_imgs = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("1Probobility: %d" % probo)
print(list_imgs)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
probo = random.randint(1, 100)
print("2Probobility: %d" % probo)
if(probo < 80): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
只需要修改代码中的路径就OK了。
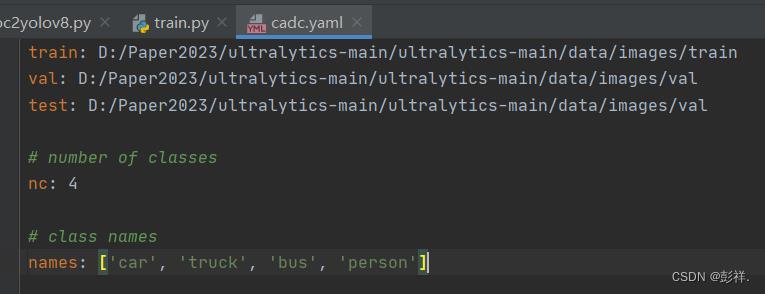
随后还要创建一个yaml配置文件,给出我们数据集路径与数据集相关信息
开始训练
找到train.py文件,修改下图中框选的部分即可,分别为权重文件与数据集配置文件。
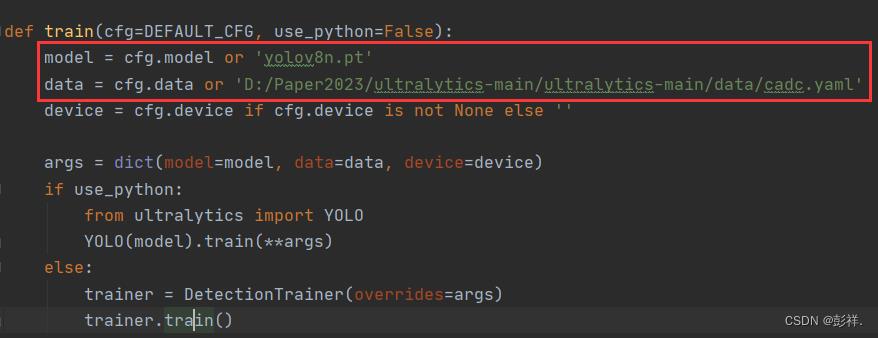
此外,关于batch-size,epoch等参数的配置在cfg文件夹下的default文件中。
修改完成后运行train.py即可。
值得一提的是,在本地的环境配置中要求pytorch和cuda ,cudnn相对应,而在安装时容易出问题,而在服务器上安装时,却十分轻松。
至于连接远程服务器的调试也是如法炮制。

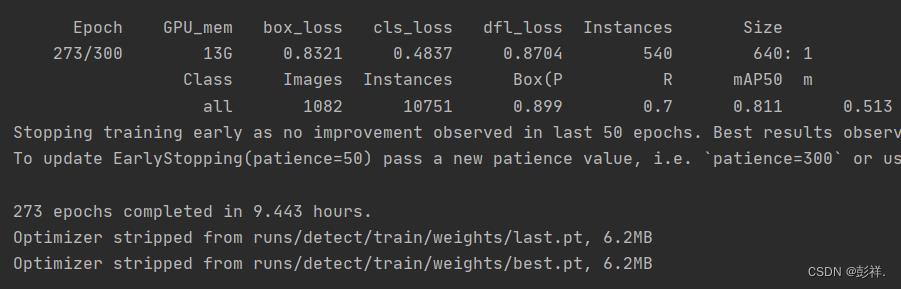
训练完成:
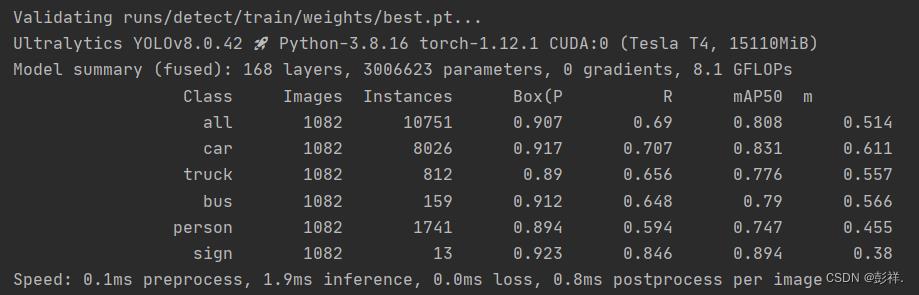
验证结果:
推理结果:

以上便是YOLOv8的调试训练与推理过程,接下来博主还会对YOLOv8相关模型进行学习,以期进行模型修改。
此外,最后在运行完成时转换结果(将csv作图)时出现错误:这个无伤大雅,不用理会。
File "/home/ubuntu/.conda/envs/yolov8/lib/python3.8/site-packages/matplotlib/pyplot.py", line 208, in _get_backend_mod
switch_backend(rcParams._get("backend"))
File "/home/ubuntu/.conda/envs/yolov8/lib/python3.8/site-packages/matplotlib/pyplot.py", line 331, in switch_backend
manager_pyplot_show = vars(manager_class).get("pyplot_show")
TypeError: vars() argument must have __dict__ attribute
以上是关于YOLOv8模型调试记录的主要内容,如果未能解决你的问题,请参考以下文章