服务端开发之Java备战秋招面试篇2-HashMap底层原理篇
Posted nuist__NJUPT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务端开发之Java备战秋招面试篇2-HashMap底层原理篇相关的知识,希望对你有一定的参考价值。
现在Java应届生和实习生就业基本上必问HashMap的底层原理和扩容机制等,可以说是十分常见的面试题了,今天我们来好好整理一下这些知识,为后面的秋招做足准备,加油吧,少年。
目录
1、HashMap集合介绍
基于Hash表的Map接口的实现,此实现提供了所有可选的映射操作,并且允许使用null键和null值,不保证存储顺序。
JDK1.8之前是数组+链表的形式,数组是主体,链表用来解决hash冲突,jdk1.8之后引入红黑树提高查询效率(链表长度大于8时候,数组长度大于64,链表转换成红黑树)。

2、HashMap的存储过程
我们看一下HashMap的存储过程,每次根据key的值进行进行相应的hash算法计算出hash值,对应数组下标的位置,如果对应位置没有元素,则直接存取,对应位置有链表,则遍历链表,用equals比对,若为true,则覆盖原来的键值对,否则在链表后划出一个节点存储数据。

在不断添加数据的过程中,可能会涉及到扩容,当超出临界值(且存放的位置非空时)扩容,默认的扩容方式:原始容量为16,扩容为原来的两倍,将原有的数据复制过来。
注意:使用resize()进行扩容,size超过临界数目就需要扩容,临界数目=容量*加载因子。

3、HashMap的成员变量
HashMap的初始容量为什么是2的n次幂呢?其实就是为了减少hash碰撞,因为根据key计算hash值,hash碰撞,就要检索同一个链表,这样存取性能就比较低,尽量减少碰撞,使得数据分布均匀。
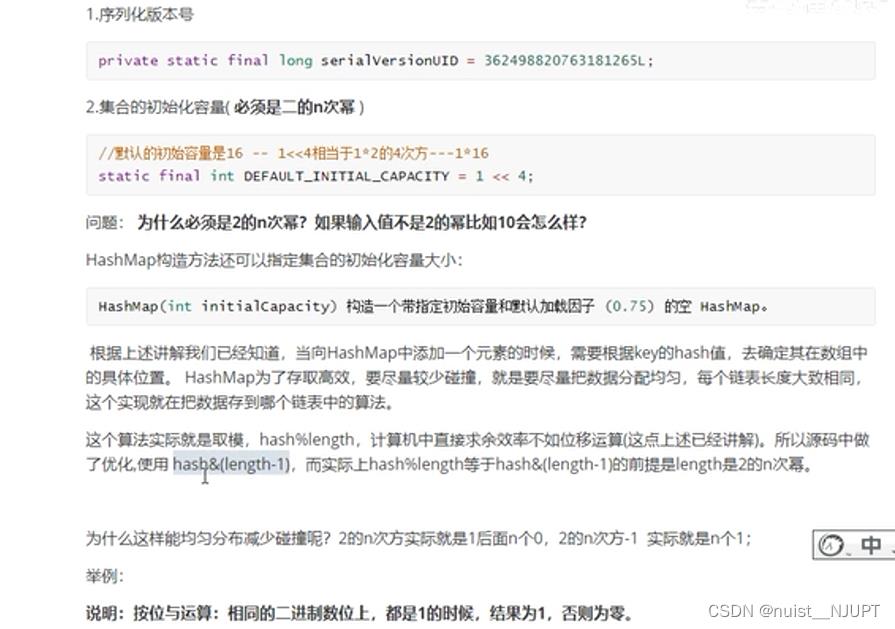
我们做个总结吧,其实可以发现数组长度不是2的n次幂的情况下,会增大hash冲突,导致很多数组位置上一直不会插入数据,这样就会浪费空间,而链表的长度会越来越长。为了提升性能,通过位运算代替取余的方式确定位置。

0.75是一个时间和空间的折衷,再看一下这个负载因子,默认0.75,初始容量默认16,当存储数据大于初始容量*负载因子时,需要对hashMap进行扩容。链表中的值超过8的时候会转变为红黑树,节点少的时候不应该用红黑树,因为红黑树插入和删除元素要通过变色和旋转保持平衡,节点少的时候反而得不偿失。

加载因子默认是0.75,当元素达到HashMap的75%时,就需要扩容,扩容相对来说耗费性能,应尽量减少扩容次数,通过创建HashMap集合对象指定初始容量来尽量避免扩容次数。

我们再看一个面试题,为什么加载因子设置0.75,初始化临界值为12呢。因为如果加载因子过大,会导致链表比较长,元素查找的性能比较低,如果加载因子过小,那么数组稀疏,扩容会导致空间的浪费。
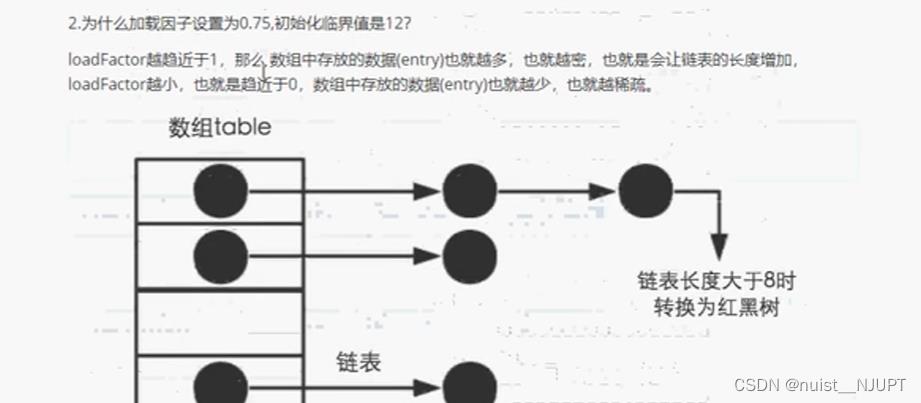
扩容的计算公式如下,每次大于容量的75%就扩容,每次扩容变成之前的两倍,如下:

4、put()方法底层实现
我们先大概看一下put()方法底层实现的基本原理,首先通过hash算法计算出hash值,映射到对应的数组空间,若没有发生hash碰撞 ,则直接插入,否则遍历链表或红黑树,用equals去比对,如果为true则覆盖原来的键值对,否则直接插入链表或红黑树中,当数组容量大于阈值的时候,需要进行扩容。

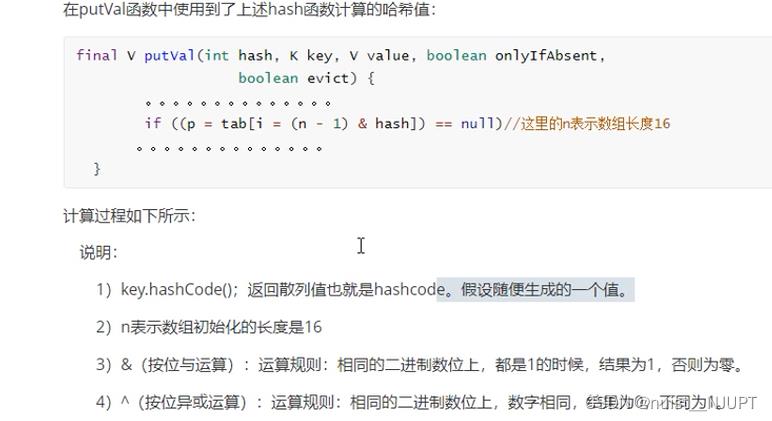
我们先看一下这个计算hash值得源码,是先计算hashCode()值,在与这个hash值的无符号右移进行异或操作,即可计算出hash值,这样可以减少hash碰撞。即映射到数组的位置更好,即hashMap得数组下标。

我们调用put()方法底层调用得是putVal()方法,在putVal()方法中,使用到了之前计算出来得hash值,若没有发生hash碰撞 ,则直接插入,否则遍历链表或红黑树,用equals去比对,如果为true则覆盖原来的键值对,否则直接插入链表或红黑树中,当数组容量大于阈值的时候,需要进行扩容。
5、将链表转换为红黑树
如果链表的长度大于8且数组的长度大于64则将链表转换成为红黑树,根据hash表中的元素决定是要扩容还是要变成红黑树,如果是变成红黑树,是需要创建相同个数的树形节点,然后复制内容,建立连接,让数组中的元素指向新创建的树的根节点,将链表的内容替换为树。

6、HashMap的扩容机制与原理
HashMap的扩容方法是resize(),我们先看一下扩容机制,即什么时候需要扩容,当元素个数大于数组长度 *0.75时候会选择扩容,每次扩容为原来的两倍。一般来说,扩容是非常消耗性能的。

下面看一下扩容的原理,在进行hashMap扩充的时候,不需要重新计算Hash值,只需要看原来的hash值新增的bit是1还是0就可以了,是0就是原来的位置,是1就是原位置+旧容量。

我们看一下原来16位的扩充为32的一个示意图,如果计算出高位是0,比如蓝色的15,就存储在原来的位置,比如绿色的15,就存储在原位置+旧容量=31的位置,如下:
这种rehash的方式,省去了重新计算hash的时间,由于新增的1和0bit是随机的,所以在扩容的过程中保证了每个桶中的节点树少于之前的,减少hash冲突。

7、remove()方法底层原理
remove()方法是根据key通过hash算法找到数组下标,如果没有元素返回为空,如果是链表就遍历链表后删除,如果是红黑树就遍历红黑树后删除。链表长度大于8转树,树的节点小于6转链表,根据统计学泊松分布得到。

8、get()方法底层原理
这个get()方法的底层原理和remove()方法很像,也是通过hash算法计算key的映射位置,若该位置就是key,则直接返回,若是红黑树或者链接,则应该遍历红黑树或链表,红黑树的查找性能类似于二分查找,效率更高,链表的话,就是顺序遍历,性能较低。


9、ConcurrentHashMap底层原理
ConcurrentHashMap是在HashMap的基础之上对Node节点进行加锁的方式保证了线程的安全性,在JDK1.7中锁的粒度是segment片段,在JDK1.8中锁的粒度是数组中的某个节点,性能提升了,引入的红黑树降低检索的复杂度。锁的实现:JDK7的锁是segment,是基于ReentronLock实现的,包含多个HashEntry;而JDK8 降低了锁的粒度,采用 table 数组元素作为锁,从而实现对每行数据进行加锁,进一步减少并发冲突的概率,并使用 synchronized 来代替 ReentrantLock,因为在低粒度的加锁方式中,synchronized 并不比 ReentrantLock 差,在粗粒度加锁中ReentrantLock 可以通过 Condition 来控制各个低粒度的边界,更加的灵活。

10、算法题:最长公共子序列
题目链接:力扣
class Solution
public int longestCommonSubsequence(String text1, String text2)
//最长公共子序列
int n = text1.length(), m = text2.length() ;
int [][] dp = new int[n+1][m+1] ;
for(int i=1; i<=n; i++)
for(int j=1; j<=m; j++)
if(text1.charAt(i-1) == text2.charAt(j-1))
dp[i][j] = dp[i-1][j-1] + 1 ;
else
dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]) ;
return dp[n][m] ;
以上是关于服务端开发之Java备战秋招面试篇2-HashMap底层原理篇的主要内容,如果未能解决你的问题,请参考以下文章