大数据NiFi(十九):实时Json日志数据导入到Hive
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据NiFi(十九):实时Json日志数据导入到Hive相关的知识,希望对你有一定的参考价值。

文章目录
3、连接“TailFile”处理器和“EvaluateJsonPath”处理器
1、新建“ReplaceText”处理器,配置“PROPERTIES”处理器
2、连接“EvaluateJsonPath”处理器与“ReplaceText”处理器,同时设置
2、连接“ReplaceText”处理器与“PutHDFS”处理器并配置
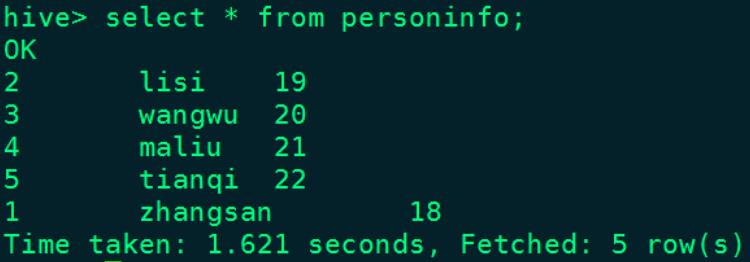
1、在Hive中创建外表personinfo在Hive中创建外表personinfo
2、配置“PROPERTIES”中“Record Reader”配置
3、配置“PROPERTIES”中“Record Writer”:
4、连接“TailFile”处理器和“ConvertRecord”处理器
5、连接“ConvertRecord”处理器与“PutHDFS”处理器
实时Json日志数据导入到Hive
案例:使用NiFi将某个目录下产生的json类型的日志文件导入到Hive。这里首先将数据通过NiFi将Json数据解析属性,然后手动设置数据格式,将数据导入到HDFS中,Hive建立外表映射此路径实现外部数据导入到Hive中。
使用到的处理器有:“TailFile”、“EvaluateJsonPath”、“ReplaceText”、“PutHDFS”四个处理器。
一、配置“TailFile”处理器
“TailFile”处理器作用是"Tails"一个文件或文件列表,在文件写入文件时从文件中摄取数据。监控的文件为文本格式,当写入新行时会接收数据。如果要Tail的文件是定期"rolled over(滚动)"的(日志文件通常是这样),则可以使用可选的"Rolling Filename Pattern"从已滚动的文件中检索数据,NiFi未运行时产生的滚动文件在NiFi重启后仍会监控到。建议将运行计划设置为几秒,不使用默认0秒运行,否则此处理器将消耗大量资源。此处理器不支持监控压缩的文件。
关于“TailFile”处理器的“Properties”配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
| Tailing mode (监控模式) | Single file | ▪Single file ▪Multiple files | single file只会tail一个文件, multiple file将tail一个文件列表。在multiple file模式下,需要配置"Base directory"。 |
| File(s) to Tail (监控文件) | 在Single file模式下,配置文件的全路径名称。如果使用multiple file模式,这里配置正则表达式,在Base directory中匹配查找要tail的文件,如果"Recursive lookup"设置为true,则正则表达式将用于匹配从"Base directory"开始的路径递归查找。 | ||
| Rolling Filename Pattern (滚动文件名匹配) | 配置滚动文件匹配名称,支持通配符*和?,支持$filename属性指定模式。如果NiFi重启,已经滚动的文件也能从停止的位置监控到。 | ||
| Base directory (基本目录) | 用于查找需要tail的文件的基本目录。使用multiple file模式时,必需设置。 | ||
| Initial Start Position (初始监控位置) | Beginning of File | 当处理器首次开始tail数据时,此属性指定处理器应在何处开始读取数据。当处理器从文件中提取数据后,处理器将从上一次接收数据的最位置继续tail数据。 有如下可选项: ▪Beginning of File ▪Beginning of Time ▪Beginning of File ▪Current Time | |
| State Location (数据位置) | Local | ▪Local ▪Remote | 指定状态位于本地或群集的位置,以便可以适当地存储状态,保证数据不被重复tail。 |
| Recursive lookup(递归查找) | false | ▪Local ▪Remote | 使用"multiple file"模式时,此属性定义是否必须在基目录中递归列出文件。 |
| Lookup frequency(查询频率) | 10 minutes | 仅用于"multiple file"模式。它指定处理器在再次列出需要tail的文件之前将等待的最短时间。 | |
| Maximum age (最大时间) | 24 hours | 仅用于"multiple file"模式。如果自文件最后一次修改以来经过的时间大于此配置时间段,则不会tail文件。 |
配置步骤如下:
1、创建“TailFile”处理器
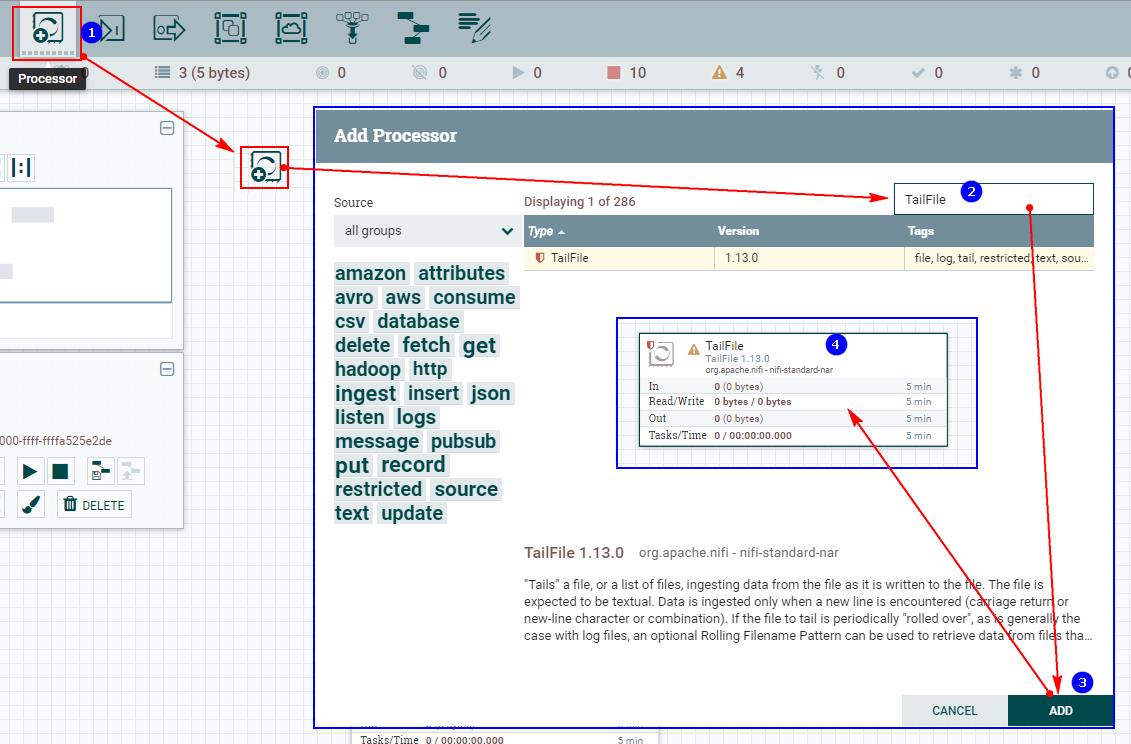
2、配置“PROPERTIES”
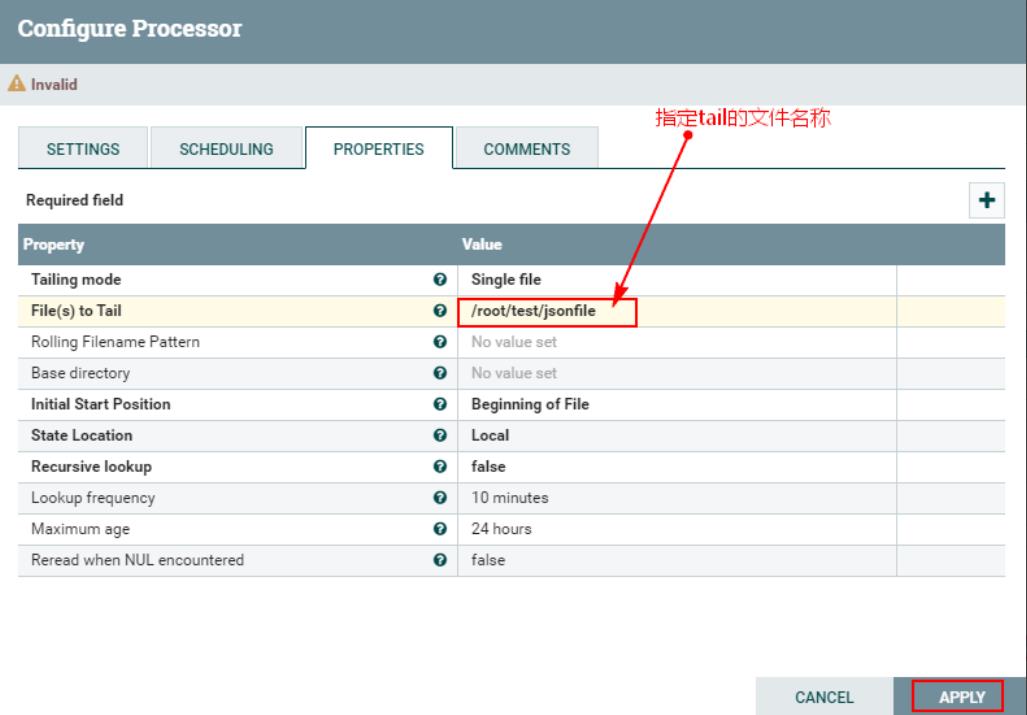
注意:以上需要在NiFi集群中的每个节点上创建“/root/test/jsonfile”文件,“jsonfile”是文件,而非目录。
二、配置“EvaluateJsonPath”处理器
“EvaluateJsonPath”处理器根据FlowFile的内容计算一个或多个JsonPath表达式。根据处理器的配置,这些表达式的结果被赋值给FlowFile属性,或者被写入FlowFile本身的内容。
通过添加用户自定义的属性来输入Jsonpath,添加的属性的名称映射到输出流中的属性名称,属性的值必须是有效的JsonPath表达式(例如:$.name)。"auto-detect"的返回类型将根据配置的目标进行确定。当"Destination"被设置为"flowfile-attribute"时,将使用"scalar"(标量)的返回类型。当"Destination"被设置为"flowfile-content"时,将使用"JSON"返回类型。
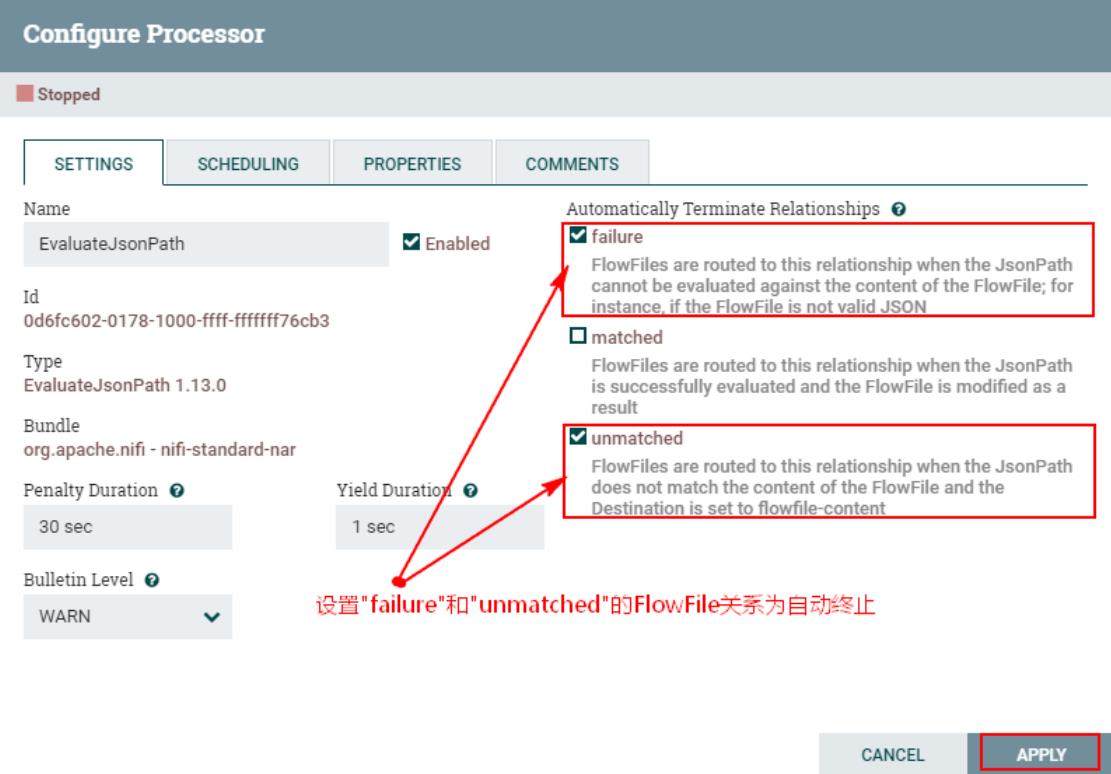
如果JsonPath计算为JSON数组或JSON对象,并且返回类型设置为"scalar",则流文件将不进行修改,并将路由到失败。如果所提供的JsonPath计算为指定的值,JSON的返回类型可以返回"scalar"。如果目标是"flowfile-content",并且JsonPath没有计算到对应的值,那么流文件将被路由到"unmatched",无需修改其内容。如果目标是"flowfile-attribute",而表达式不匹配任何内容,那么将使用空字符串作为属性的值,并且FlowFile将始终被路由到"matched"。
关于“EvaluateJsonPath”处理器的“Properties”配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
| Destination (目标) | flowfile-content | ▪flowfile-content ▪flowfile-attribute | 指示是否将JsonPath计算结果写入FlowFile内容或FlowFile属性;如果使用flowfile-attribute,则必须指定属性名称。如果设置为flowfile-content,则只能指定一个JsonPath,并且忽略属性名。 |
| Return Type (返回类型) | auto-detect | ▪auto-detect ▪json ▪scalar | 指示JSON路径表达式的期望返回类型。选择"auto-detect","flowfile-content"的返回类型自动设置为"json","flowfile-attribute"的返回类型自动设置为"scalar"标量。 |
| Path Not Found Behavior (未找到路径) | ignore | ▪warn ▪ignore | 指示在将Destination设置为"flowfile-attribute"时如何处理丢失的JSON路径表达式。当没有找到JSON路径表达式时,选择"warn"将生成一个警告。 |
| Null Value Representation (Null值表示) | empty string | ▪empty string ▪the string 'null' | 指示产生空值的JSON路径表达式的所需表示形式。 |
示例说明:
- 提取流文件json内容,作为输出流的属性。(注意:当输出选择flowfile-attribute时,即使jsonpath匹配不到值,流文件也会路由到matched)
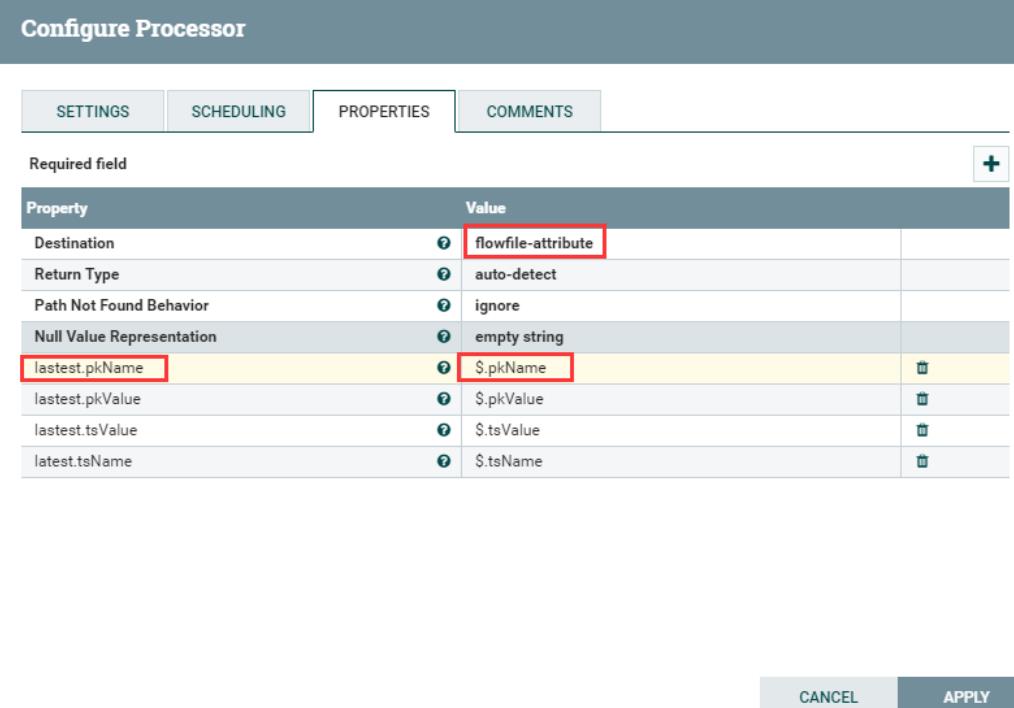
输入json如下:
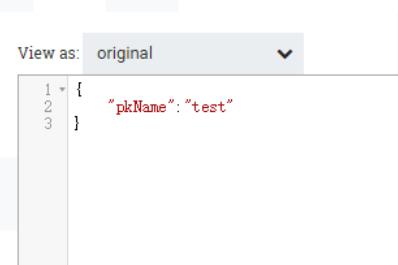
输出结果如下:
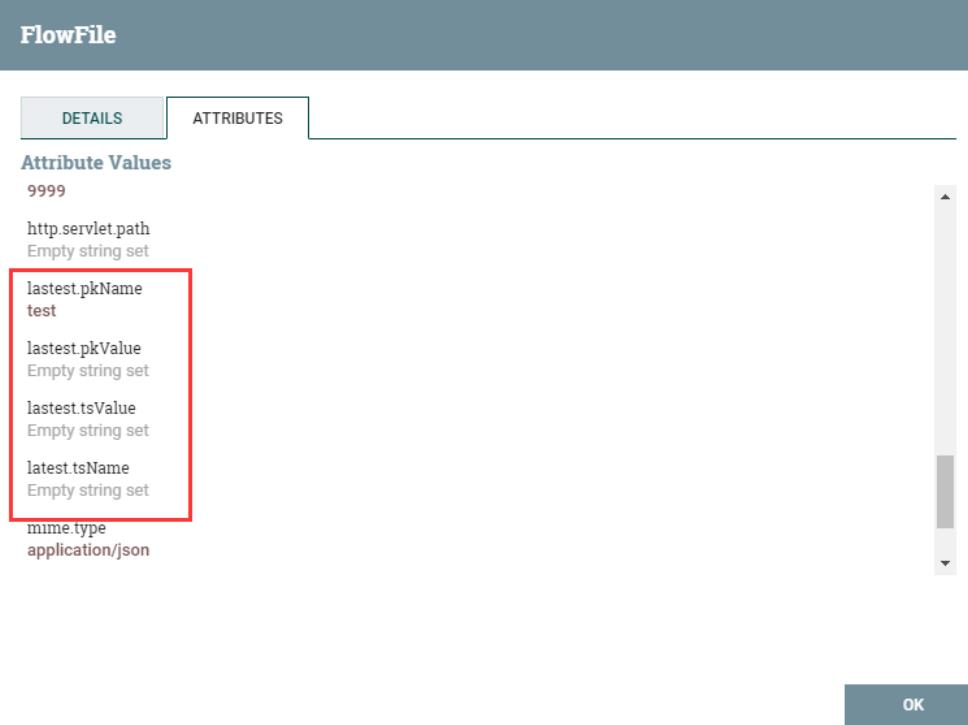
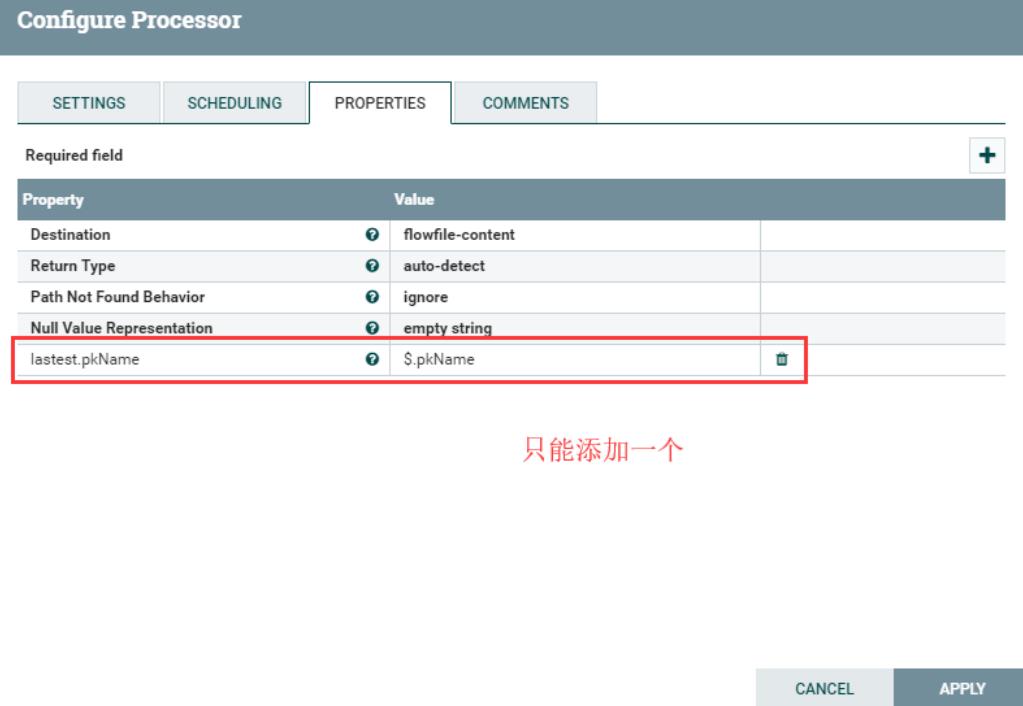
- 提取流文件json内容,作为输出流的内容。(注意:当选择flowfile-content时,用户只能自定义添加一个属性;如果jsonPath匹配不到,会路由到unmatched)
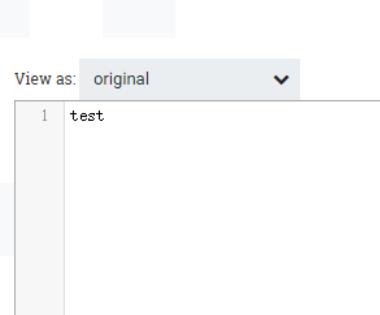
输出流内容:
介绍完“EvaluateJsonPath”如何使用,下面来配置,配置步骤如下:
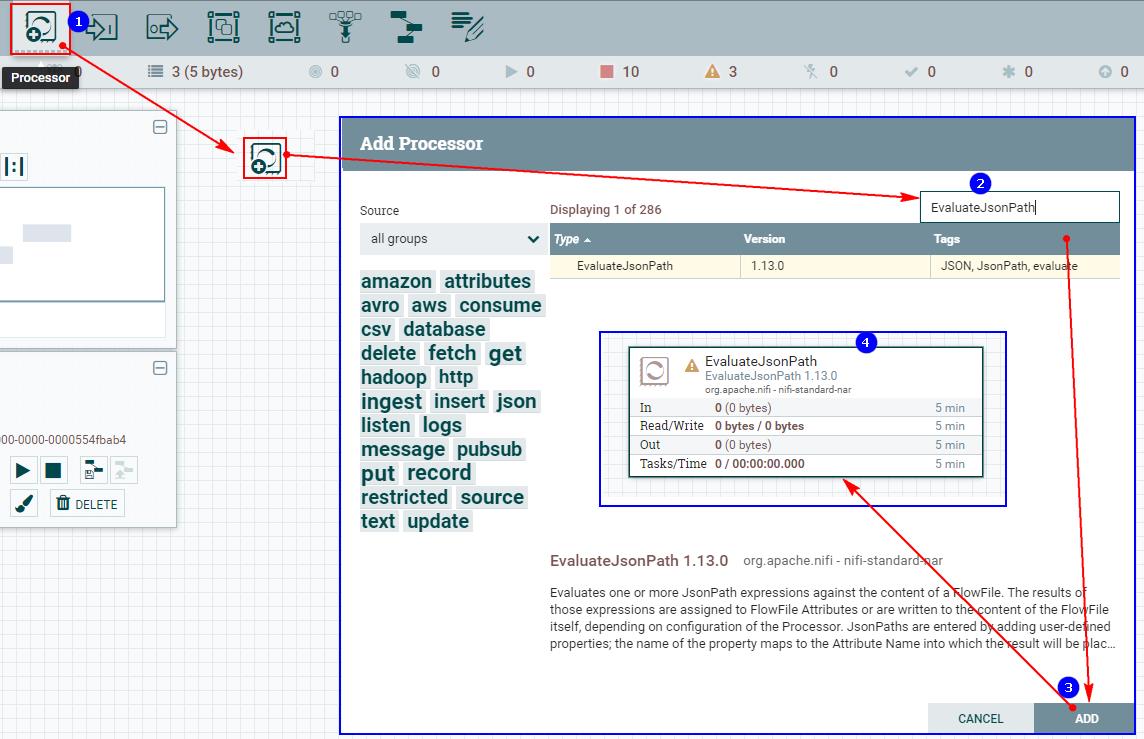
1、创建“EvaluateJsonPath”处理器
2、配置“PROPERTIES”
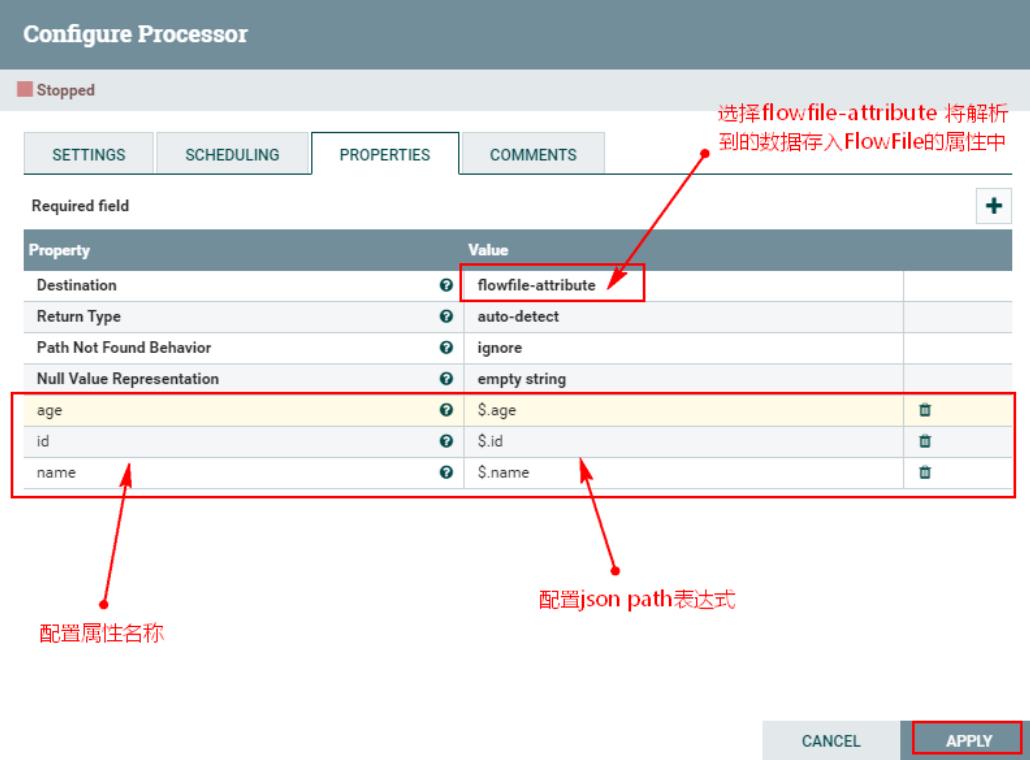
3、连接“TailFile”处理器和“EvaluateJsonPath”处理器

三、配置“ReplaceText”处理器
“ReplaceText”处理器会替换正则表达式匹配到的FlowFile中的内容,生成新的FlowFile内容。这里我们使用“ReplaceText”处理器将上个处理器“EvaluateJsonPath”处理后的每个FlowFile内容替换成自定义的内容,这里自定义内容都是从FlowFile的属性中获取的值,按照“\\t”制表符隔开,方便后期存储到HDFS中映射Hive表。
配置步骤如下:
1、新建“ReplaceText”处理器,配置“PROPERTIES”处理器
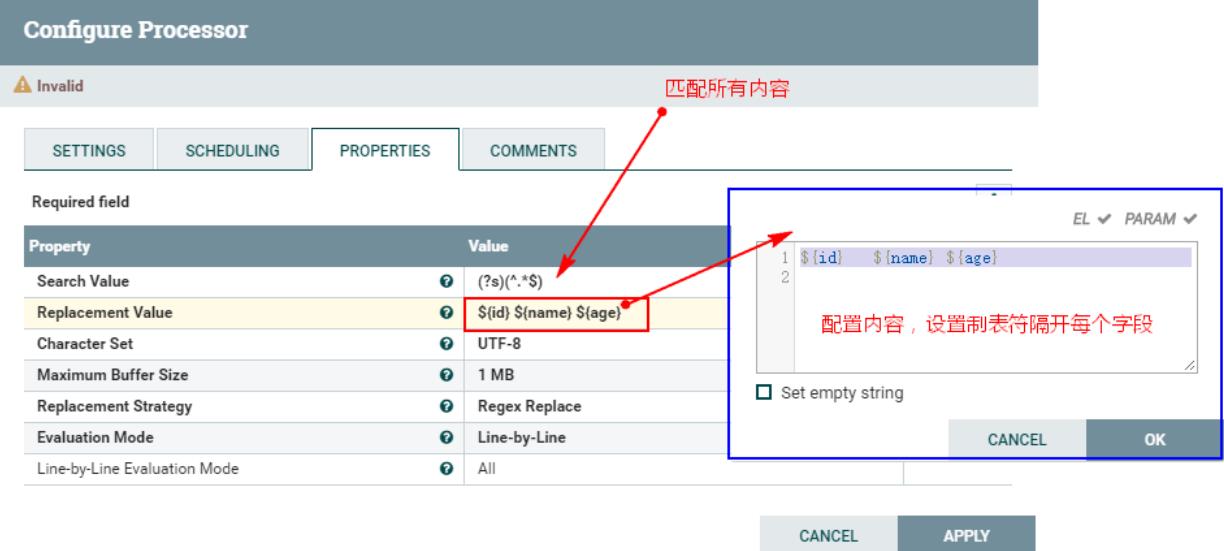
2、连接“EvaluateJsonPath”处理器与“ReplaceText”处理器,同时设置
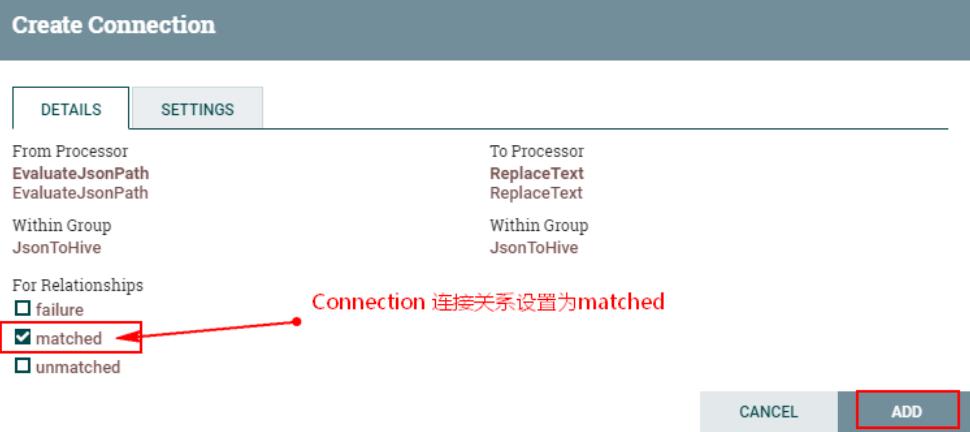
在“EvaluateJsonPath”中设置“failure”与“unmatched”的传递关系为自动终止:
四、配置“PutHDFS”处理器
这里创建“PutHDFS”处理器将上游处理的数据写入HDFS目录中。配置步骤如下:
1、创建“PutHDFS”处理器并配置
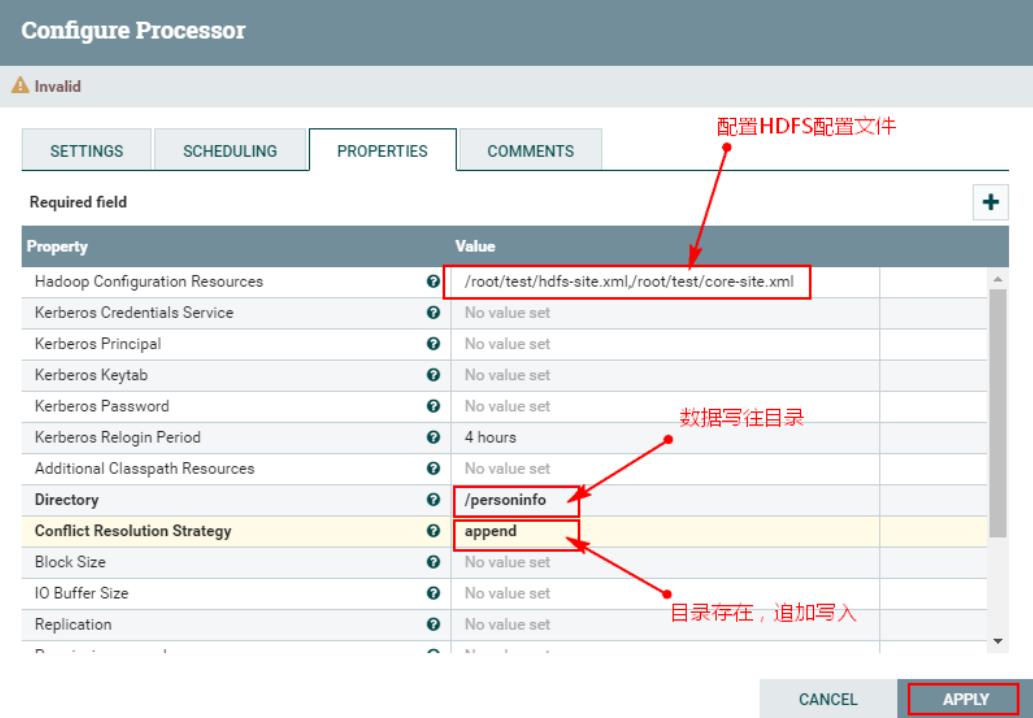
2、连接“ReplaceText”处理器与“PutHDFS”处理器并配置


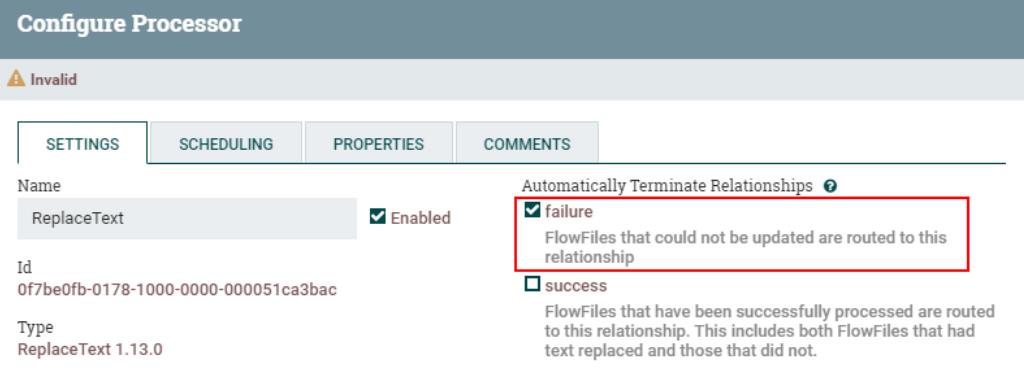
配置“ReplaceText”处理器“failure”的FlowFile传递关系为自动终止:
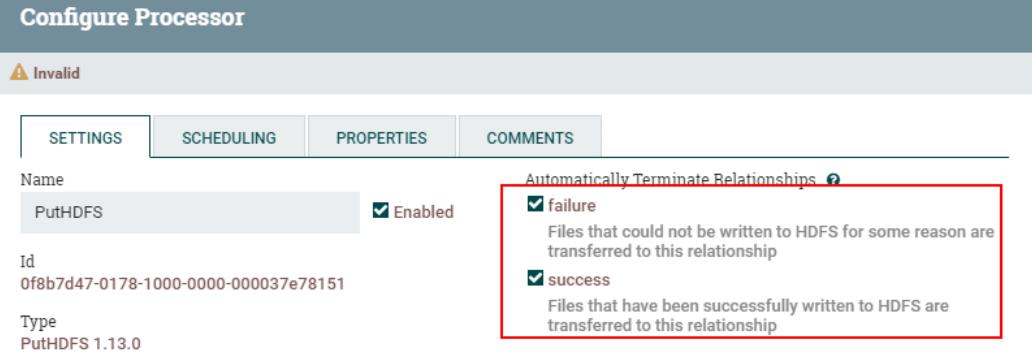
配置“PutHDFS”处理器“failure”和“success”的FlowFile传递关系为自动终止:
五、运行测试
1、在Hive中创建外表personinfo在Hive中创建外表personinfo
CREATE TABLE personinfo(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
LOCATION '/mycluster/personinfo'2、启动NiFi处理数据流程,处理数据
向任意NiFi节点/root/test/jsonfile文件中写入以下数据写入以下数据:
echo "\\"id\\":1,\\"name\\":\\"zhangsan\\",\\"age\\":18" >> /root/test/jsonfile
echo "\\"id\\":2,\\"name\\":\\"lisi\\",\\"age\\":19" >> /root/test/jsonfile
echo "\\"id\\":3,\\"name\\":\\"wangwu\\",\\"age\\":20" >> /root/test/jsonfile
echo "\\"id\\":4,\\"name\\":\\"maliu\\",\\"age\\":21" >> /root/test/jsonfile
echo "\\"id\\":5,\\"name\\":\\"tianqi\\",\\"age\\":22" >> /root/test/jsonfile3、查看结果
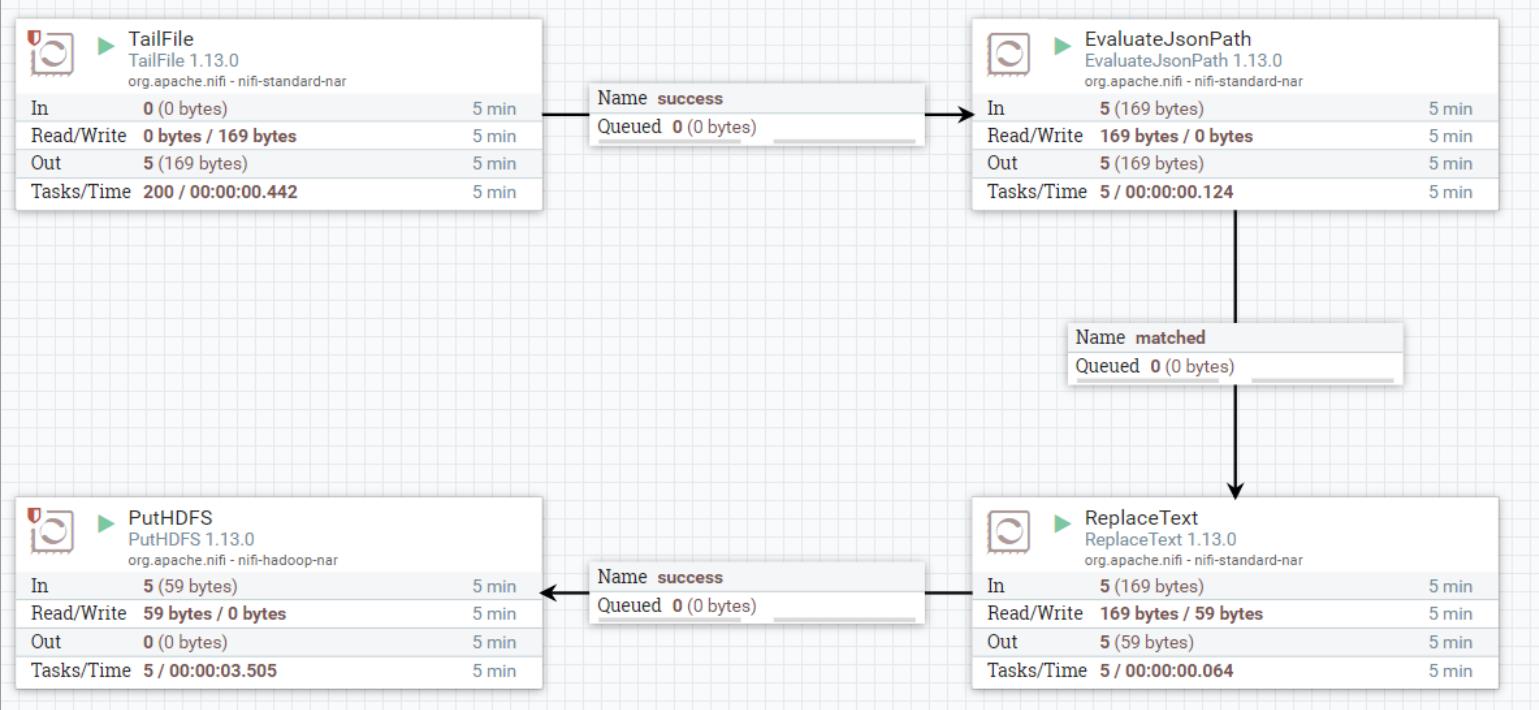
NiFi页面:
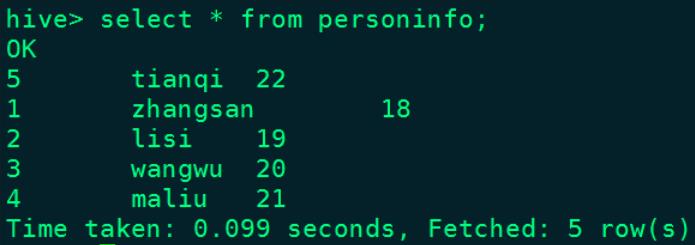
hive中结果:
问题:当我们一次性向某个NiFi节点的“/root/test/jsonfile”文件中写入数据时,这时“EvaluateJsonPath”一个FlowFile中会有多条json数据,当获取json属性时,只会获取第一条json对应的属性。当数据流向下游“ReplaceText”处理器时,由于设置每行替换成指定格式的行,这时会出现将本批次所有行数据都替换成了第一行的json格式数据。如下图:
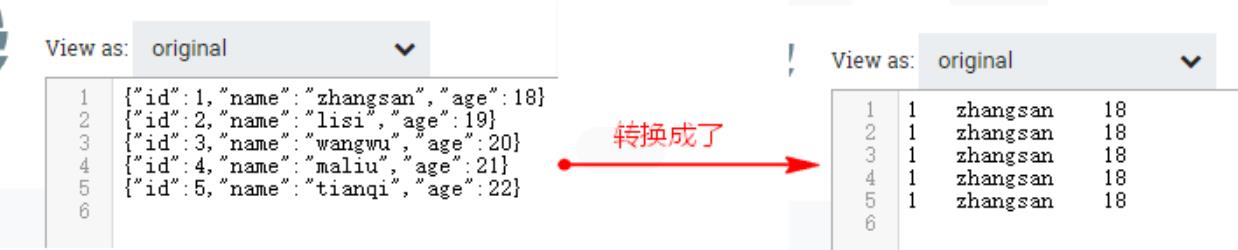
当一次性向tail的文件输入多条数据,我们不希望全部json行内容替换成第一行json内容,那么可以将“TailFile”处理器处理的数据直接传递给“ConvertRecord”处理器,将数据由json格式转换成自定义文本格式数据,再传递到“PutHDFS”处理器即可,所以解决以上问题,我们这里复用之前的“TailFile”和“PutHDFS”处理器即可,下面只需要配置“ConvertRecord”处理器即可。
六、配置“ConvertRecord”处理器
“ConvertRecord”根据配置的“记录读取器”和“记录写出控制器”来将记录从一种数据格式转换为另一种数据格式。
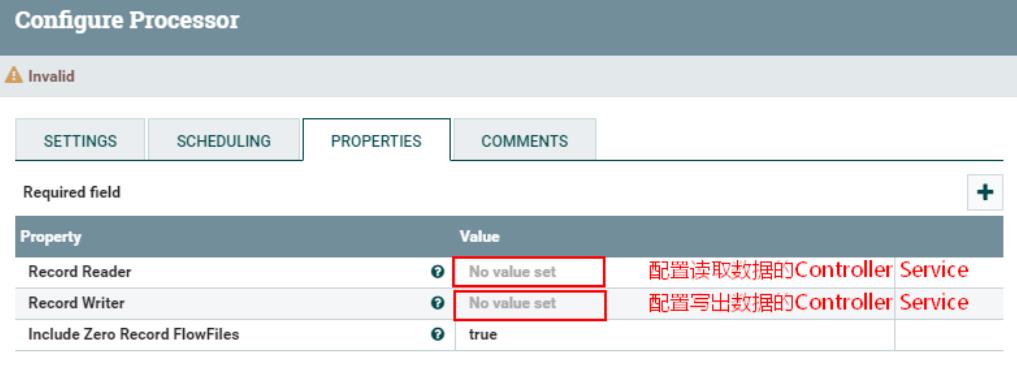
关于“ConvertRecord”处理器的“Properties”配置的说明如下:
| 配置项 | 默认值 | 允许值 | 描述 |
| Record Reader (记录读取器) | 指定读取数据的Controller Service。 | ||
| Record Writer (记录写出) | 指定写出数据的Controller Service。 | ||
| Include Zero Record FlowFiles(没有记录的FlowFiles) | true | ▪true ▪false | 在转换传入的流文件时,如果转换没有产生数据,则此属性指定是否将流文件发送到相应的关系。 |
配置步骤如下:
1、创建“ConvertRecord”处理器
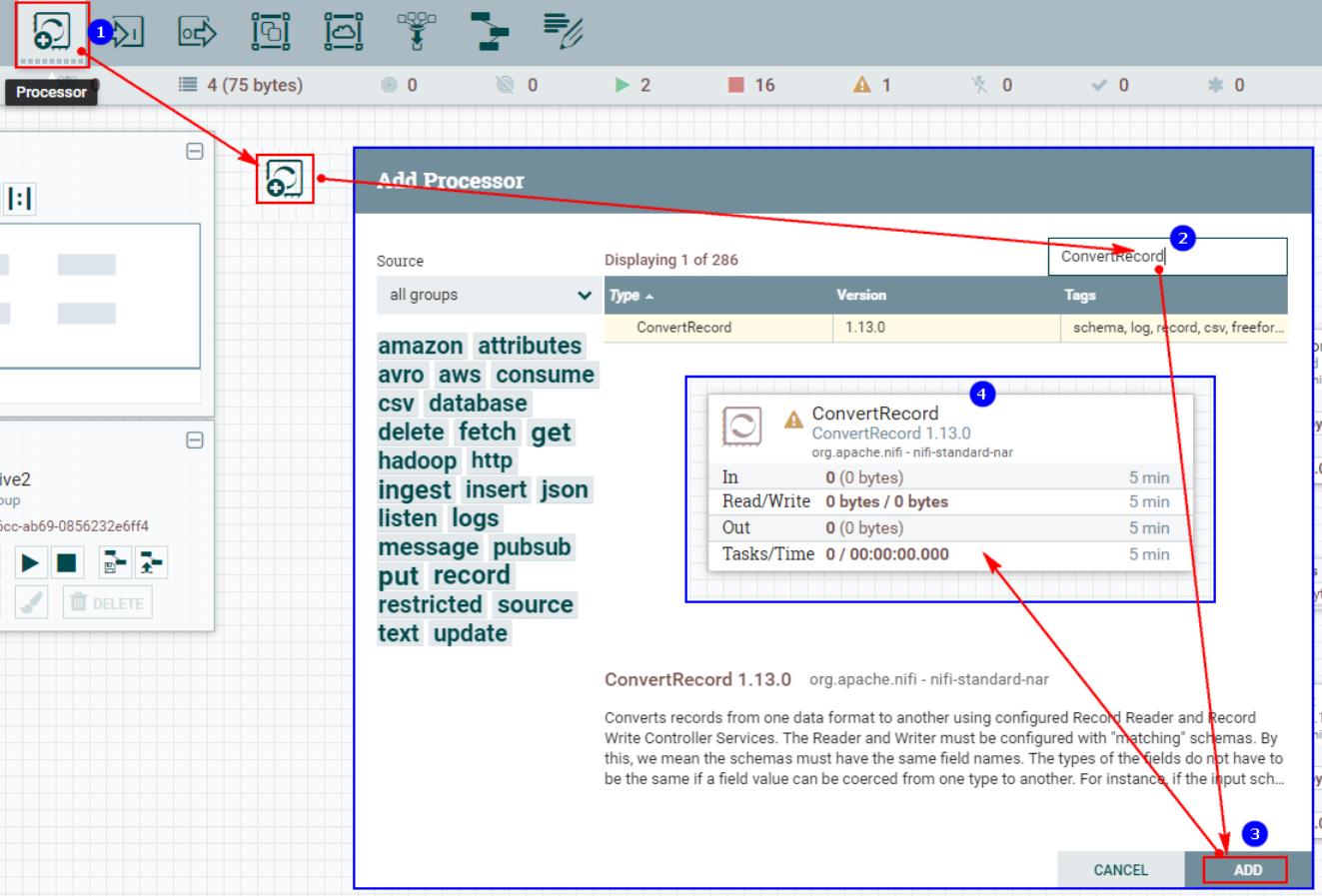
2、配置“PROPERTIES”中“Record Reader”配置
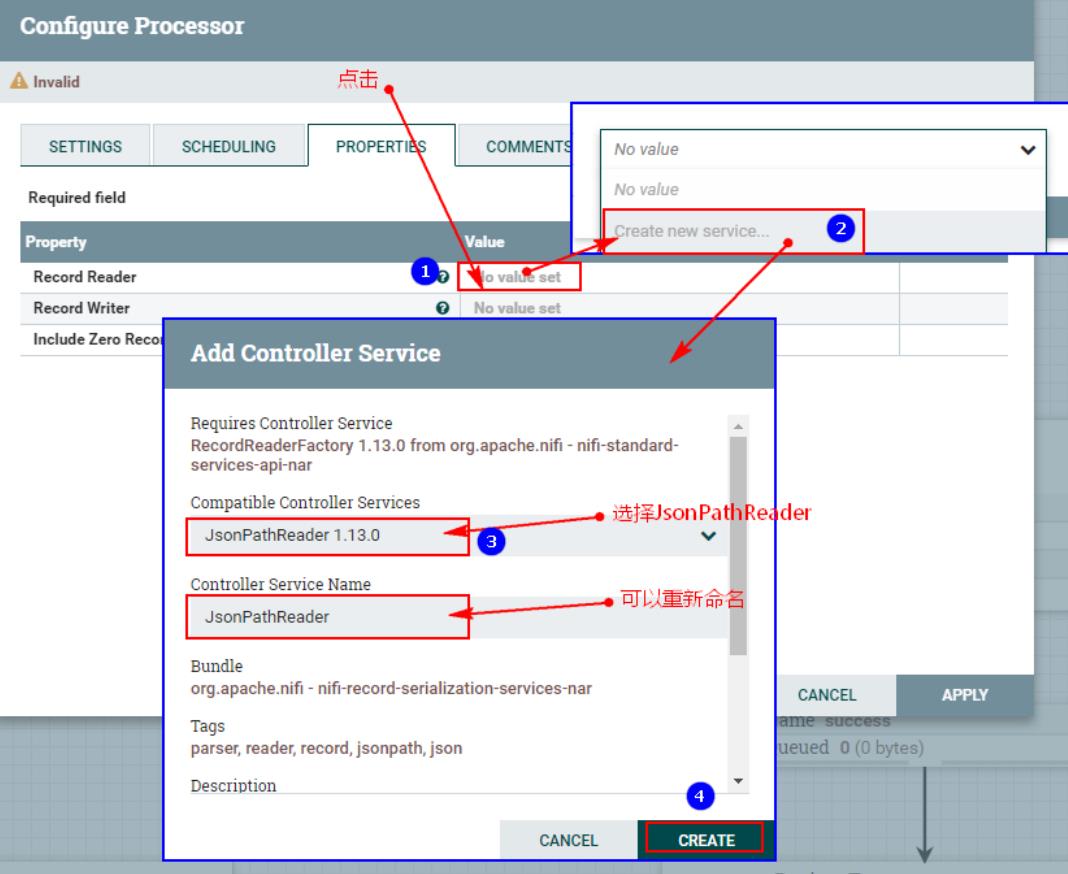
点击以上之后,进入配置:
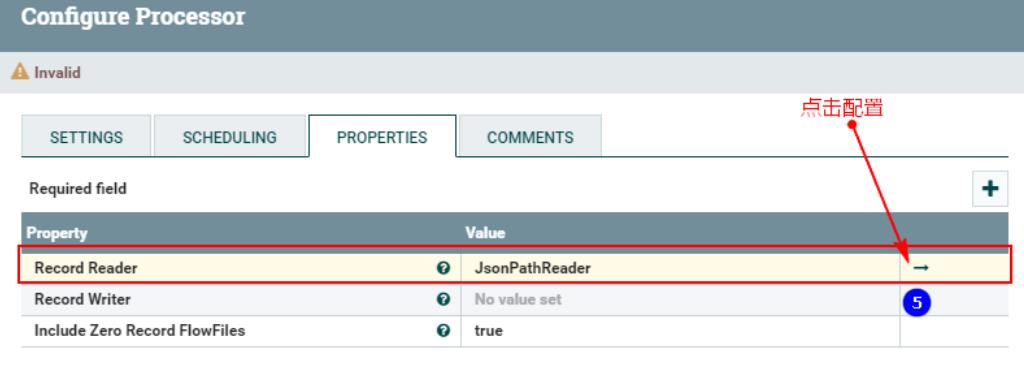
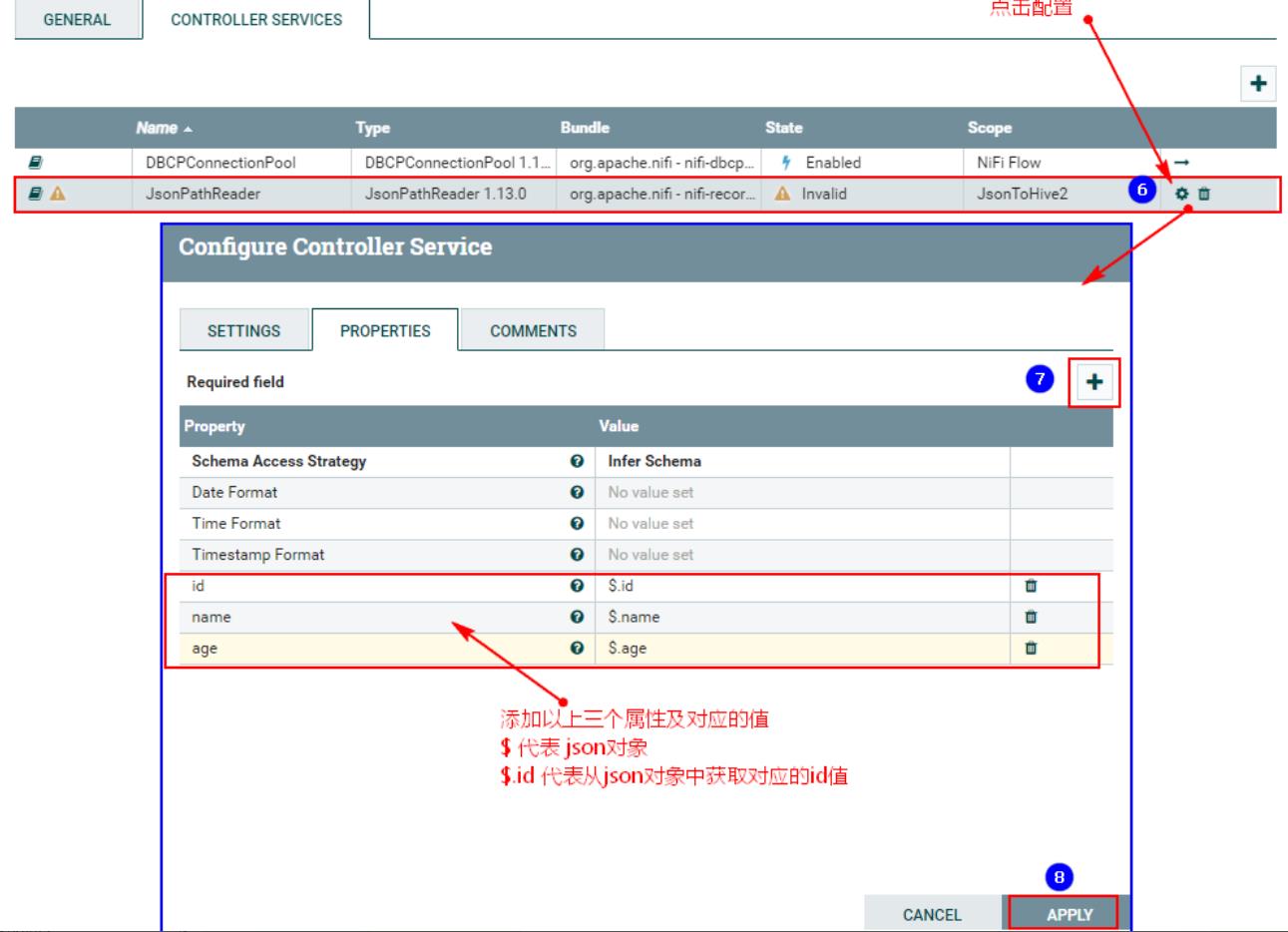
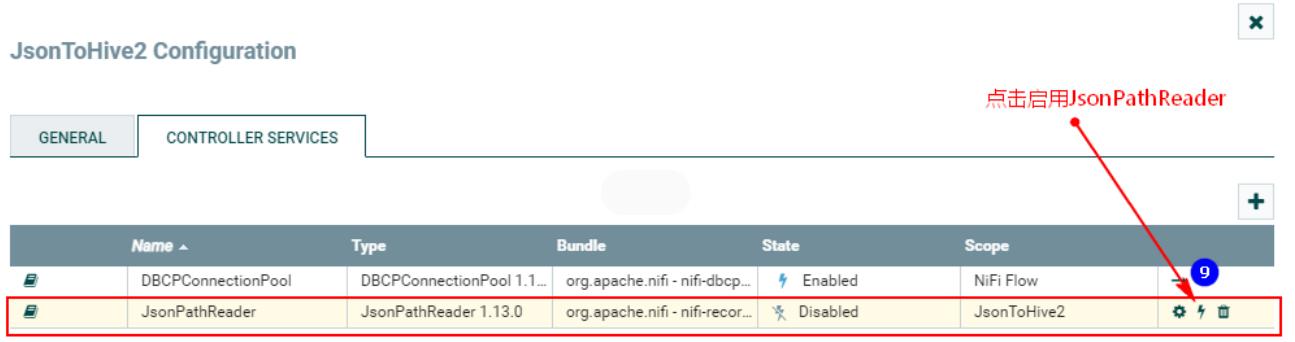
配置好以上之后,需要启动:
3、配置“PROPERTIES”中“Record Writer”:
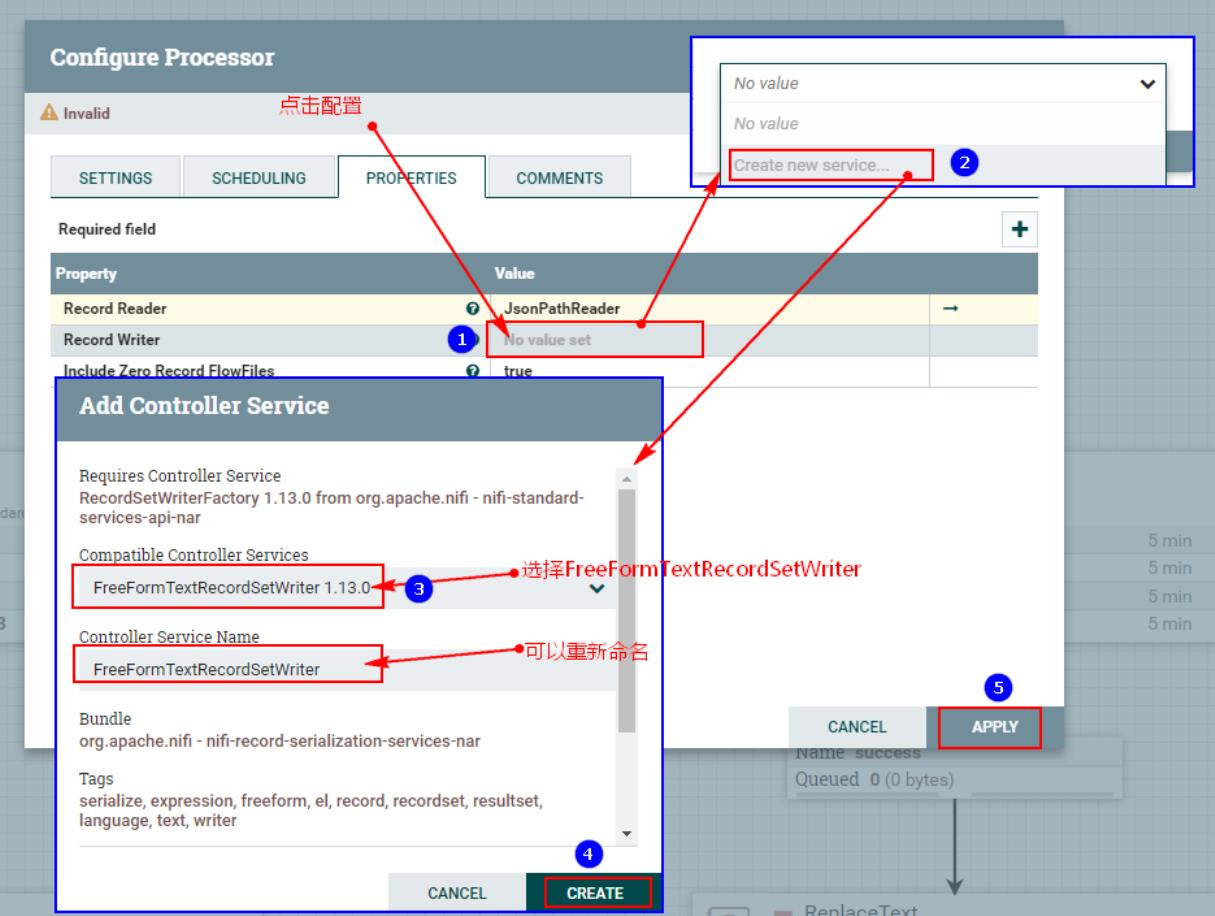
点击以上之后进入配置:
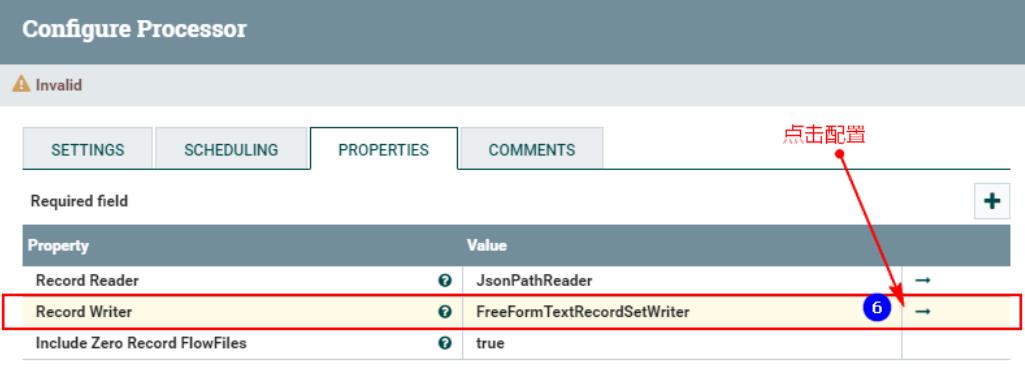
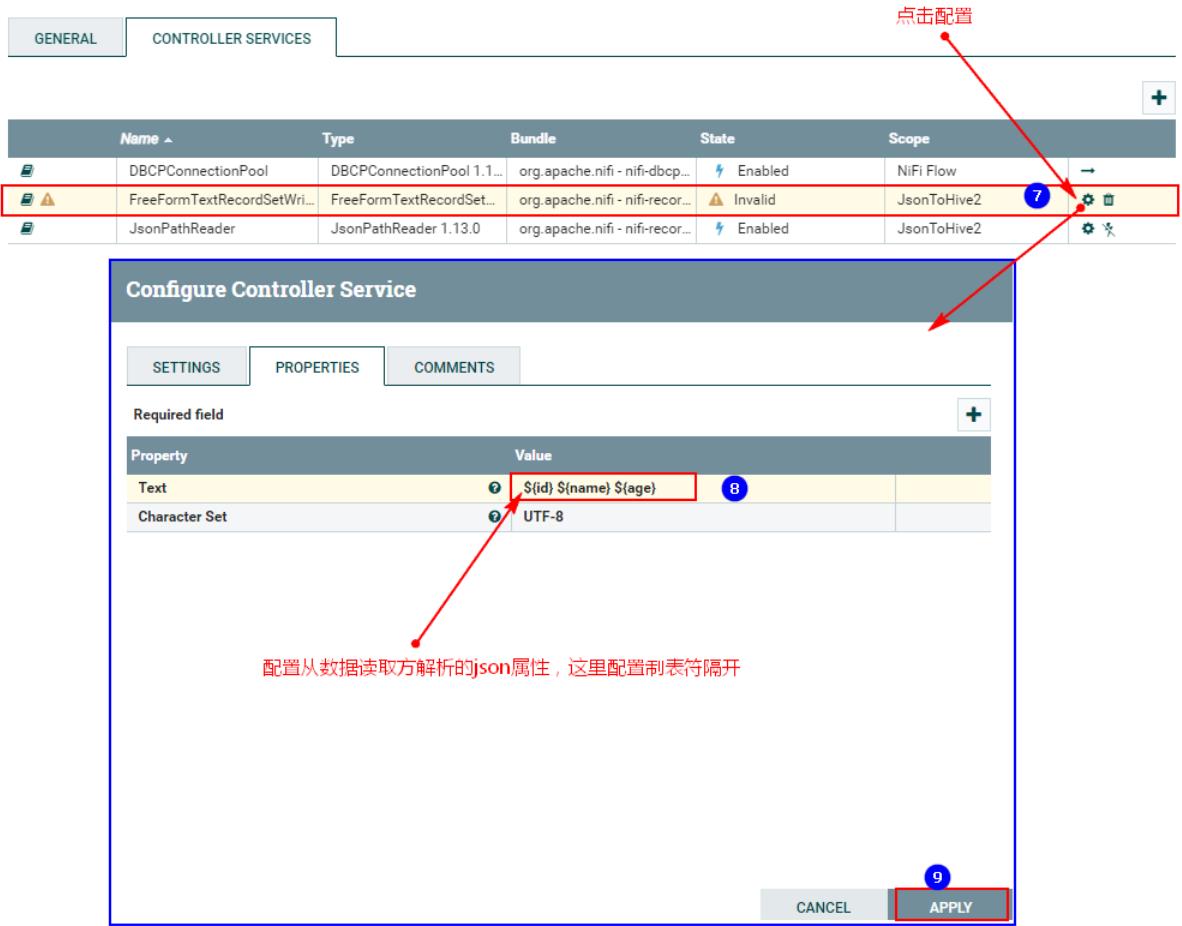
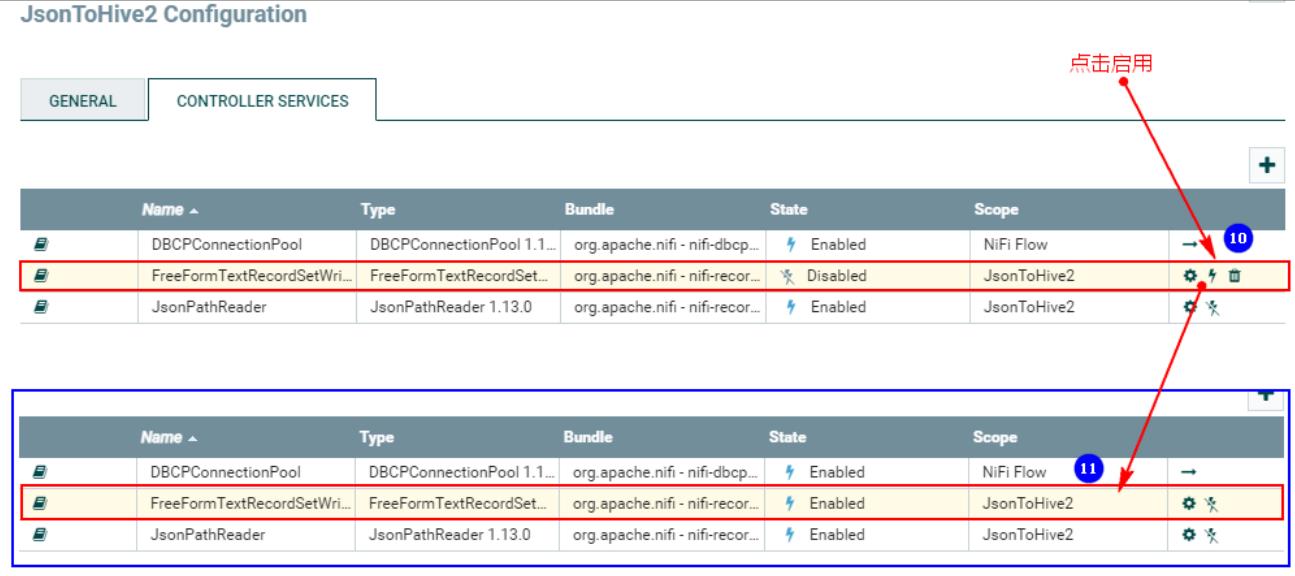
4、连接“TailFile”处理器和“ConvertRecord”处理器
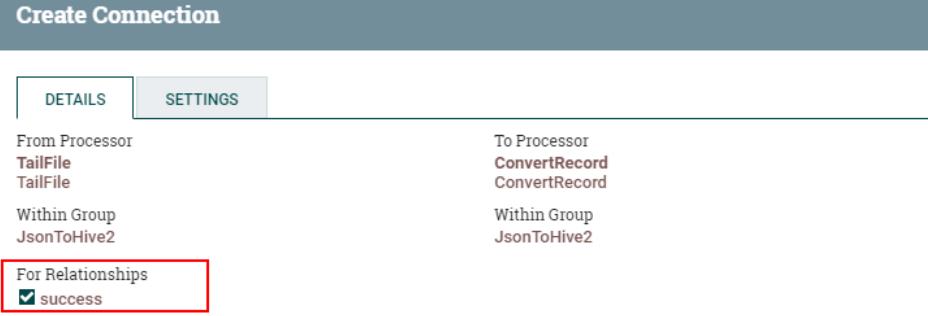
5、连接“ConvertRecord”处理器与“PutHDFS”处理器
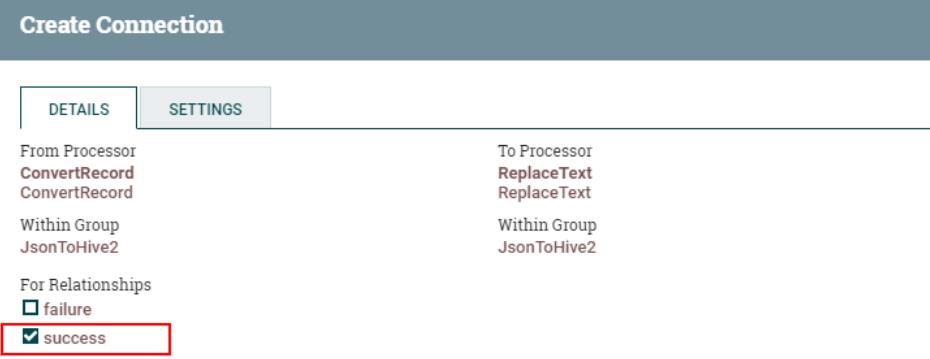
同时设置“ConvertRecord”的处理“failure”关系为自动终止:
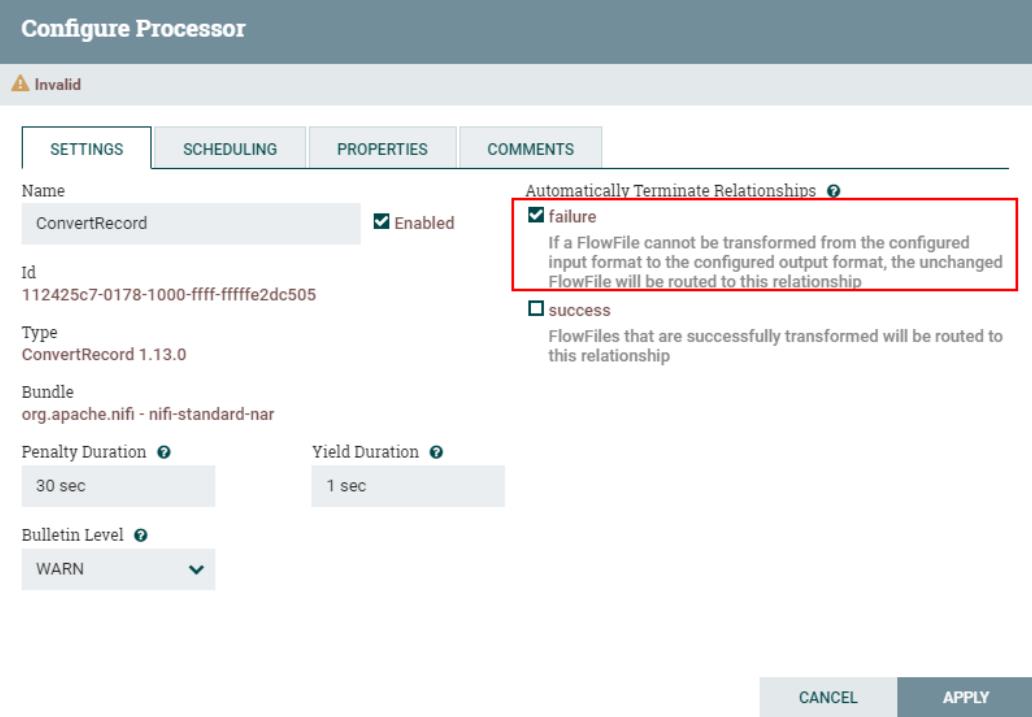
七、运行测试
删除HDFS中原有的“/personinfo”路径,启动NiFi处理数据流程,处理数据:
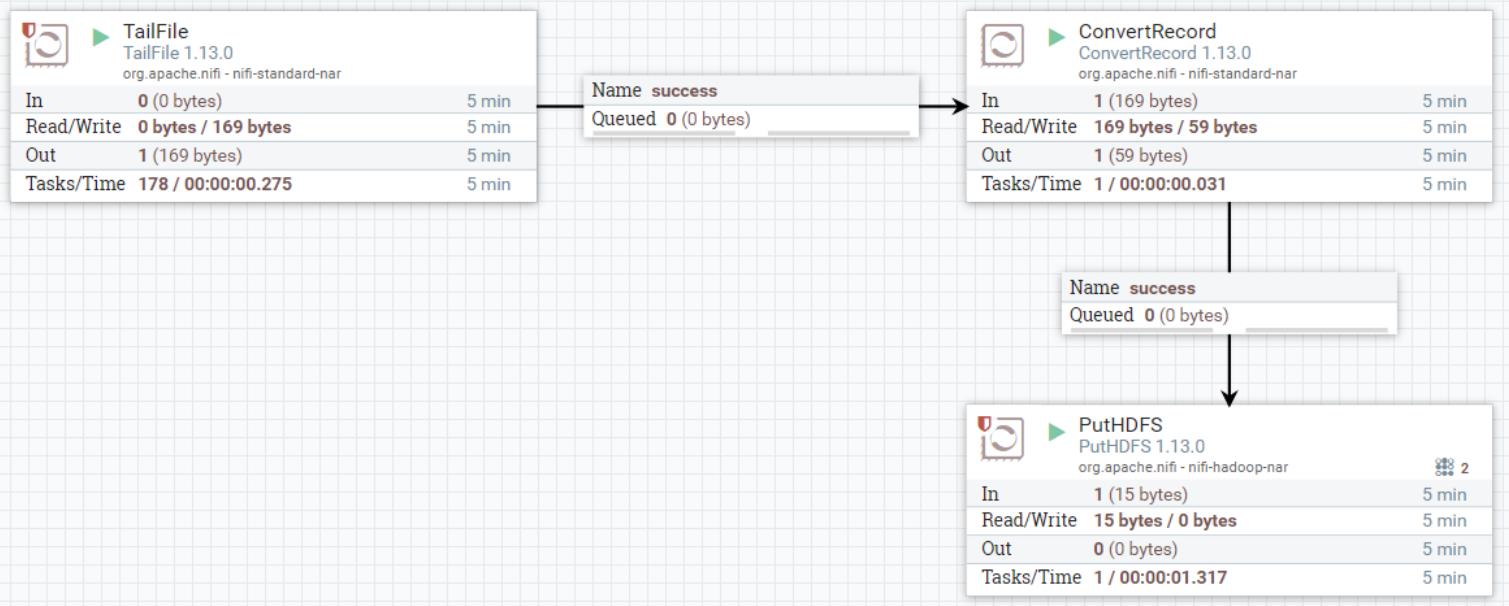
向任意NiFi集群节点“/root/test/jsonfile”中一次性写入以下数据:
echo "\\"id\\":1,\\"name\\":\\"zhangsan\\",\\"age\\":18" >> /root/test/jsonfile
echo "\\"id\\":2,\\"name\\":\\"lisi\\",\\"age\\":19" >> /root/test/jsonfile
echo "\\"id\\":3,\\"name\\":\\"wangwu\\",\\"age\\":20" >> /root/test/jsonfile
echo "\\"id\\":4,\\"name\\":\\"maliu\\",\\"age\\":21" >> /root/test/jsonfile
echo "\\"id\\":5,\\"name\\":\\"tianqi\\",\\"age\\":22" >> /root/test/jsonfile查询Hive表personinfo数据:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据NiFi(十九):实时Json日志数据导入到Hive的主要内容,如果未能解决你的问题,请参考以下文章