XXL-JOB分布式任务调度框架-策略详解
Posted IT-熊猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XXL-JOB分布式任务调度框架-策略详解相关的知识,希望对你有一定的参考价值。

文章目录
1.引言
本篇文章承接上文《XXL-JOB分布式任务调度框架(一)-基础入门》,上一次和大家简单介绍了下 xxl-job 的由来以及使用方法,本篇文章将会详细介绍一些高级使用方法及特性。
上文中我们在新建一个任务的时候发现有很多的选项,现在我们来详细聊一聊他们的作用。
)
2.任务详解
2.1.执行器
执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能;
另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器
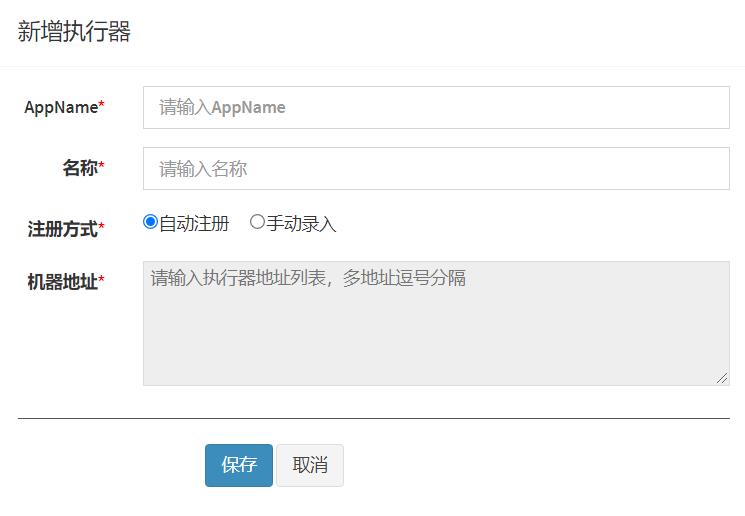
2.2.基础配置
-
执行器:每个任务必须绑定一个执行器, 方便给任务进行分组。任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置
-
任务描述:任务的描述信息,便于任务管理
-
报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
-
负责人:任务的负责人;

-
调度类型
- 无:该类型不会主动触发调度;
- CRON:该类型将会通过CRON,触发任务调度;
- 固定速度:该类型将会以固定速度,触发任务调度;按照固定的间隔时间,周期性触发;

-
运行模式:

-
BEAN模式:以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务;
-
GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
-
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “shell” 脚本;
-
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “python” 脚本;
-
GLUE模式(php):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “php” 脚本;
-
GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 “nodejs” 脚本;
-
GLUE模式(PowerShell):以源码方式维护在调度中心;该模式的任务实际上是一段 “PowerShell” 脚本;
-
JobHandler:运行模式为 “BEAN模式” 时生效,对应执行器中新开发的
JobHandler类“@JobHandler”注解自定义的value值; -
执行参数:任务执行所需的参数;
-
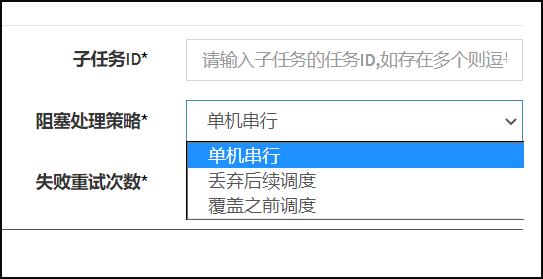
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
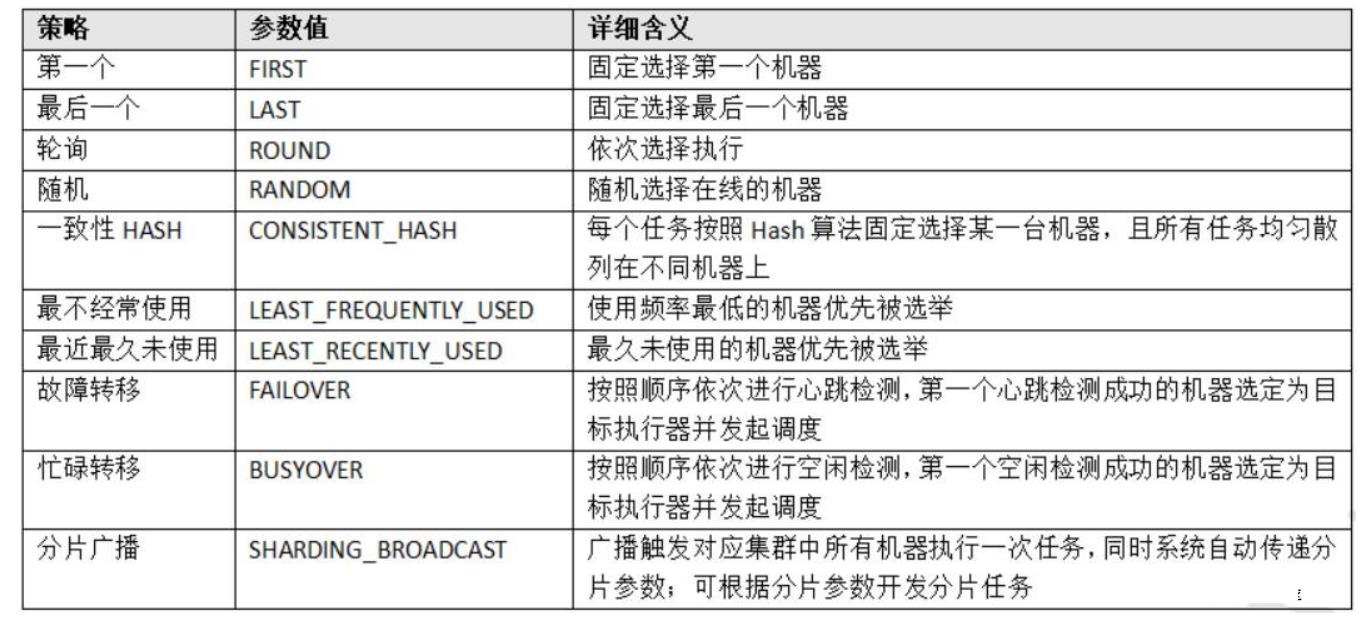
路由策略:当执行器集群部署时,提供丰富的路由策略
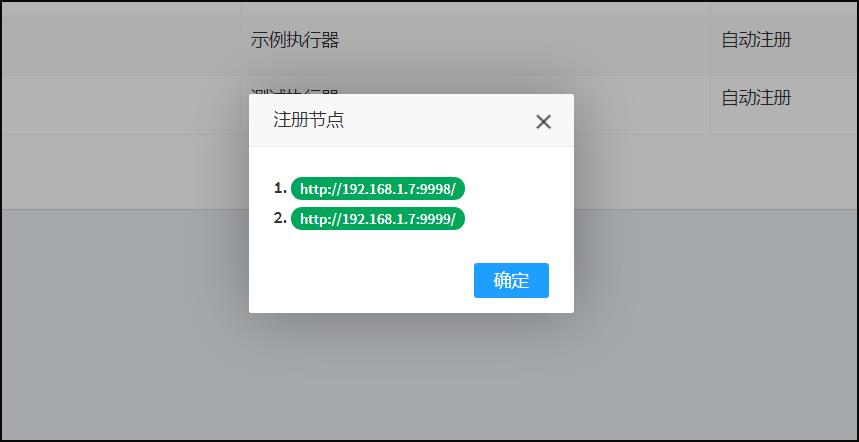
路由策略是指一个任务可以由多个执行器完成,那具体由哪一个完成呢,这就要看我们指定的路由策略了,这个参数当执行器做集群部署的时候才有意义。
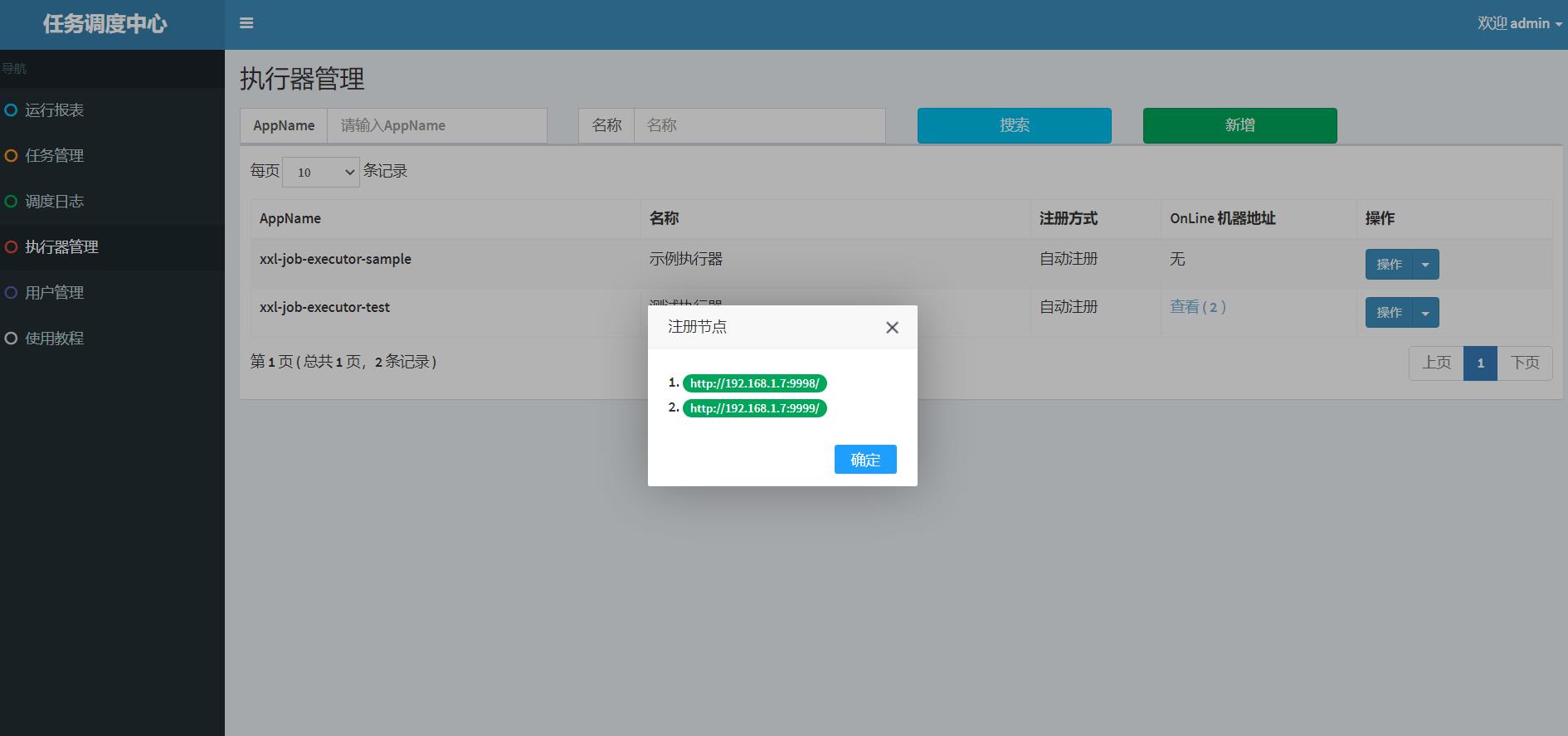
那么这里的第一个,最后一个是按什么顺序来的呢,就是点击查看-注册节点中的1,2,3,4,第一个指的就是1,最后一个指的就是4。

-
子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
-
任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
-
失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
3.路由策略(第一个)-案例
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteFirst extends ExecutorRouter
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
return new ReturnT<String>(addressList.get(0));
看代码就很容易理解,获取当前传入的执行器的注册地址集合的第一个。
执行器部署集群

配置路由规则

任务执行效果:第一个执行器执行任务

4.路由策略(最后一个)-案例
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteLast extends ExecutorRouter
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
return new ReturnT<String>(addressList.get(addressList.size()-1));
这个也很容易理解,选取当前传入得执行器的注册地址集合的最后一个,下标从0开始 最后一个为addressList.size()-1
执行器部署集群
配置路由规则
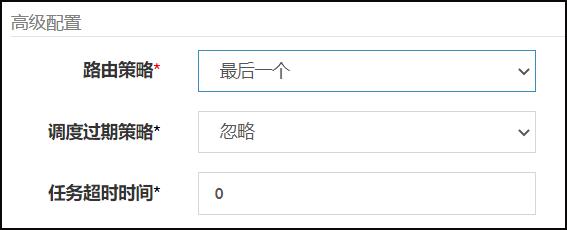
任务执行效果:最后一个执行器执行任务
5.轮询策略-案例
执行器部署集群
配置路由规则
任务执行效果:轮询执行任务(一共执行4次,各执行2次)

6.随机选取
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.List;
import java.util.Random;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteRandom extends ExecutorRouter
private static Random localRandom = new Random();
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
String address = addressList.get(localRandom.nextInt(addressList.size()));
return new ReturnT<String>(address);
整个算法核心部分就是通过一个Random对象的nextInt方法在求出[0,addressList.size())区间内的任意一个地址
7.轮询选取
源码:
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.IntStream;
/**
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteRound extends ExecutorRouter
private static ConcurrentMap<Integer, AtomicInteger> routeCountEachJob = new ConcurrentHashMap<>();
private static long CACHE_VALID_TIME = 0;
private static int count(int jobId)
// cache clear
if (System.currentTimeMillis() > CACHE_VALID_TIME)
routeCountEachJob.clear();
CACHE_VALID_TIME = System.currentTimeMillis() + 1000*60*60*24;
AtomicInteger count = routeCountEachJob.get(jobId);
if (count == null || count.get() > 1000000)
// 初始化时主动Random一次,缓解首次压力
count = new AtomicInteger(new Random().nextInt(100));
else
// count++
count.addAndGet(1);
routeCountEachJob.put(jobId, count);
return count.get();
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
String address = addressList.get(count(triggerParam.getJobId())%addressList.size());
return new ReturnT<String>(address);
这里注意到创建了一个静态的ConcurrentMap对象,这个routeCountEachJob就是用来存放路由任务的,而且还设置了缓存时间,有效期为24小时,当超过24小时的时候,自动的清空当前的缓存。
其中ConcurrentMap的key为jobId,value为当前jobId所对应的计数器,每访问一次就自增一,最大增到100000,然后又从[0,100)的随机数开始重新自增。
这个算法的思想就是取余数,每次先计算出当前jobId所对应的计数器的值,然后 计数器的值 % addressList.size() 求得这一次轮询的地址。
8.一致性hash
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 分组下机器地址相同,不同JOB均匀散列在不同机器上,保证分组下机器分配JOB平均;且每个JOB固定调度其中一台机器;
* a、virtual node:解决不均衡问题
* b、hash method replace hashCode:String的hashCode可能重复,需要进一步扩大hashCode的取值范围
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteConsistentHash extends ExecutorRouter
private static int VIRTUAL_NODE_NUM = 100;
/**
* get hash code on 2^32 ring (md5散列的方式计算hash值)
* @param key
* @return
*/
private static long hash(String key)
// md5 byte
MessageDigest md5;
try
md5 = MessageDigest.getInstance("MD5");
catch (NoSuchAlgorithmException e)
throw new RuntimeException("MD5 not supported", e);
md5.reset();
byte[] keyBytes = null;
try
keyBytes = key.getBytes("UTF-8");
catch (UnsupportedEncodingException e)
throw new RuntimeException("Unknown string :" + key, e);
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
//通过md5算出的hashcode % 2^32 余数,将hash值散列在一致性hash环上 这个环分了2^32个位置
long truncateHashCode = hashCode & 0xffffffffL;
return truncateHashCode;
public String hashJob(int jobId, List<String> addressList)
// ------A1------A2-------A3------
// -----------J1------------------
TreeMap<Long, String> addressRing = new TreeMap<Long, String>();
for (String address: addressList)
for (int i = 0; i < VIRTUAL_NODE_NUM; i++)
//为每一个注册的节点分配100个虚拟节点,并算出这些节点的一致性hash值,存放到TreeMap中
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
//第二步求出job的hash值 通过jobId计算
long jobHash = hash(String.valueOf(jobId));
//通过treeMap性质,所有的key都按照从小到大的排序,即按照hash值从小到大排序,通过tailMap 求出>=hash(jobId)的剩余一部分map,
SortedMap<Long, String> lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty())
//若找到则取第一个key,为带路由的地址
return lastRing.get(lastRing.firstKey());
//若本身hash(jobId)为treeMap的最后一个key,则找当前treeMap的第一个key
return addressRing.firstEntry().getValue();
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList)
String address = hashJob(triggerParam.getJobId(), addressList);
return new ReturnT<String>(address);
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
为什么要引入这个算法那,这个算法就是为了解决目前分布式所存在的问题,举个例子:
现在我们有三台Redis服务器,假设编号为0,1,2,每台服务器都缓存了当前最热门的商品详情信息,我们的映射规则是按照 hash(商品的id)%(redis服务器数量)的结果来映射到某一台编号的redis服务器中,
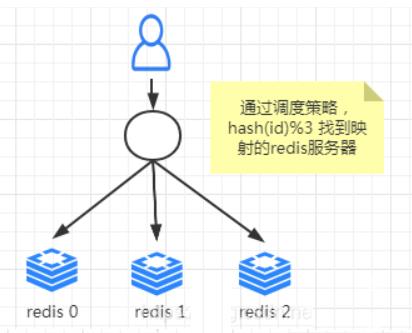
但是突然由于有一天公司商品越来越多,客户流量也越来越大,三台服务器扛不住怎么办啊,那我们就加一台服务器,那么服务器数量就发生了变动,那肯定我们的取余数这个算法重新计算映射的编号就发生了变动,很容易造成大面积缓存失效,造成缓存雪崩,
把所有请求都请求到后端数据库,造成压力过大。为了解决这个问题,就引入了一致性hash算法,即服务节点的变更不会造成大量的哈希重定位。一致性哈希算法由此而生~。
这个一致性hash引入之后,若服务器节点数量过少,有几率出现数据倾斜的情况,既大量的数据映射到某一区间,其它区间没有数据映射,造成了资源分配不均匀,为了解决这个问题,xxl-job源码引入了虚拟节点,既将每台服务器的节点都生成所对应的100个虚拟节点,这应少量的服务器节点通过引入虚拟节点,就会加大节点的数量,这样大量的节点分配到hash环上是比较均匀的,从而很容易的解决数据分配不均匀问题。
9.最不经常使用 (LFU)
package com.xxl.job.admin.core.route.strategy;
import com.xxl.job.admin.core.route.ExecutorRouter;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.biz.model.TriggerParam;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
/**
* 单个JOB对应的每个执行器,使用频率最低的优先被选举
* a(*)、LFU(Least Frequently Used):最不经常使用,频率/次数
* b、LRU(Least Recently Used):最近最久未使用,时间
*
* 算法思想:
* 构建一个作业和地址map jobid -> addressList
* 第一次随机的将任务所对应的执行器的注册地址编一个序列号
* 然后将执行器的注册地址按照从小到大进行排序
* 筛选过程找第一个序列号最小的作为下一次的路由地址
* 随后将当前选中的地址编号值+1
* 这样最终我们都会挑选编号最小的注册器地址作为下一个路由地址,既最不常使用的
*
* Created by xuxueli on 17/3/10.
*/
public class ExecutorRouteLFU extends ExecutorRouter
private static ConcurrentMap<Integer, HashMap<String, Integer>> jobLfuMap = new ConcurrentHashMap<Integer, HashMap<String, Integer>>();
private static long CACHE_VALID_TIME = 0;
public String route(int jobId, List<String> addressList)
// cache clear
if (System.以上是关于XXL-JOB分布式任务调度框架-策略详解的主要内容,如果未能解决你的问题,请参考以下文章