Python爬虫之Scrapy框架系列(14)——实战ZH小说爬取多页爬取
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之Scrapy框架系列(14)——实战ZH小说爬取多页爬取相关的知识,希望对你有一定的参考价值。
目录:
实现多页爬取,此处以两页举例!
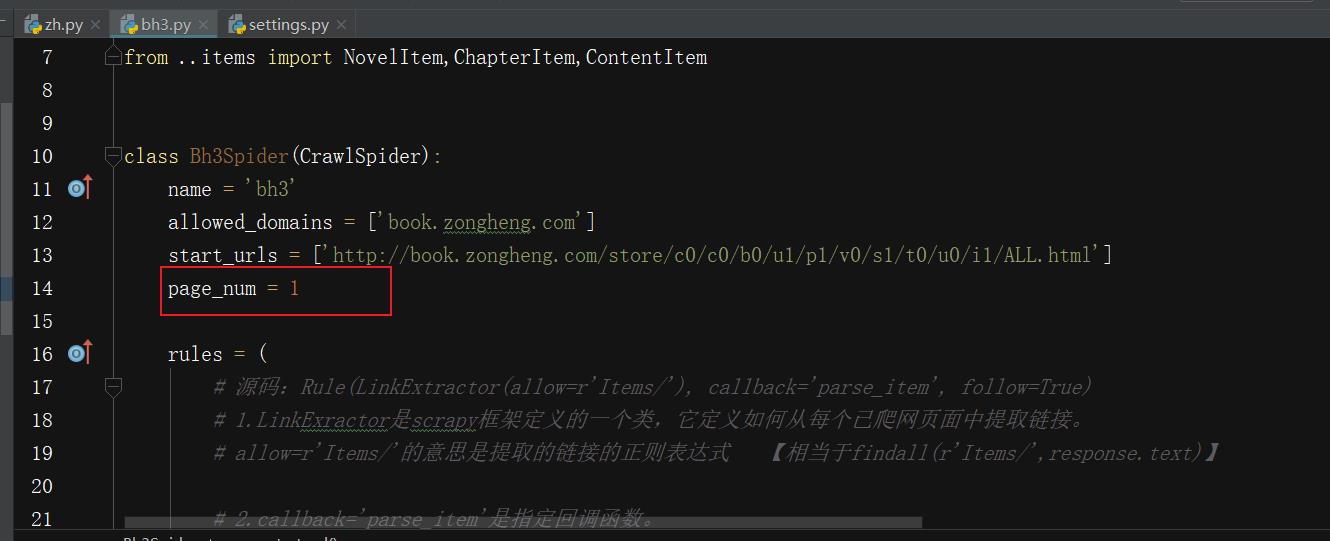
①编写爬虫文件:
- (加入对start_urls处理的函数,通过翻页观察每页URL的规律,在此函数中拼接得到多页的URL,并将请求发送给引擎!)
# start_urls的回调函数
# 作用:拼接得到每页小说的url。实现多页小说获取。
def parse_start_url(self, response):
print(self.page_num,response)
# 可以解析star_urls的response 相当于之前的parse函数来用
# 拼接下一页的url
self.page_num+=1
next_pageurl='https://book.zongheng.com/store/c0/c0/b0/u1/p/v0/s1/t0/u0/i1/ALL.html'.format(self.page_num)
if self.page_num == 3:
return
yield scrapy.Request(next_pageurl)
注意:给定page_num赋初值!并且为了方便观察,我们将每本书具体章节内容的获取限制为6章!
②观察效果:
-
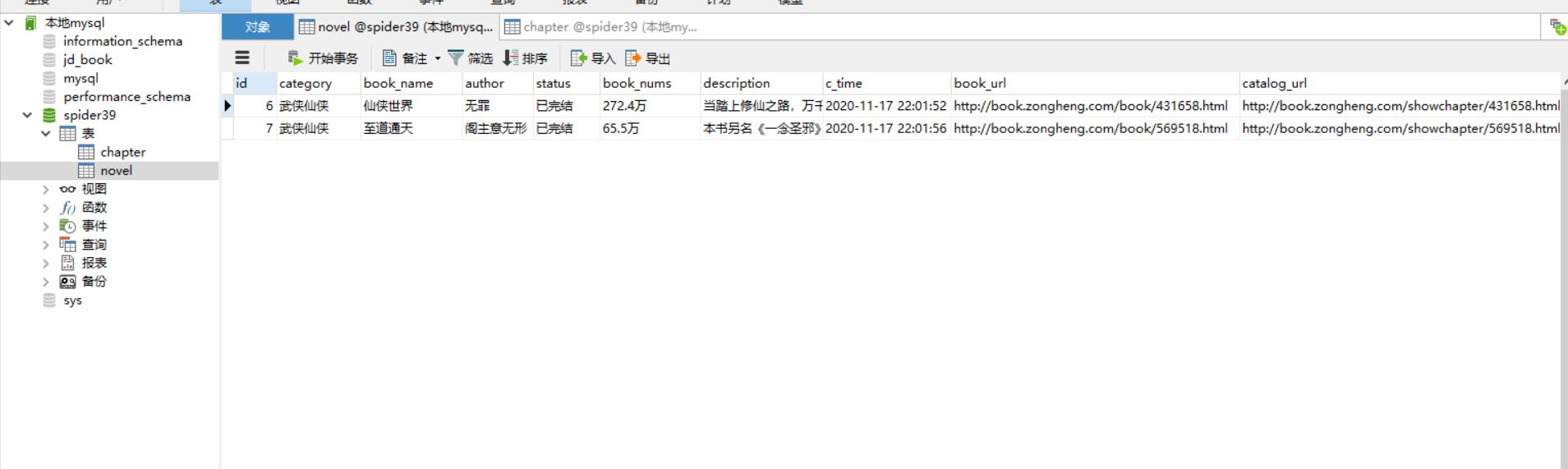
观察novel表发现刚好拿到我们限制的两页里的第一本小说,共两本小说信息:
-
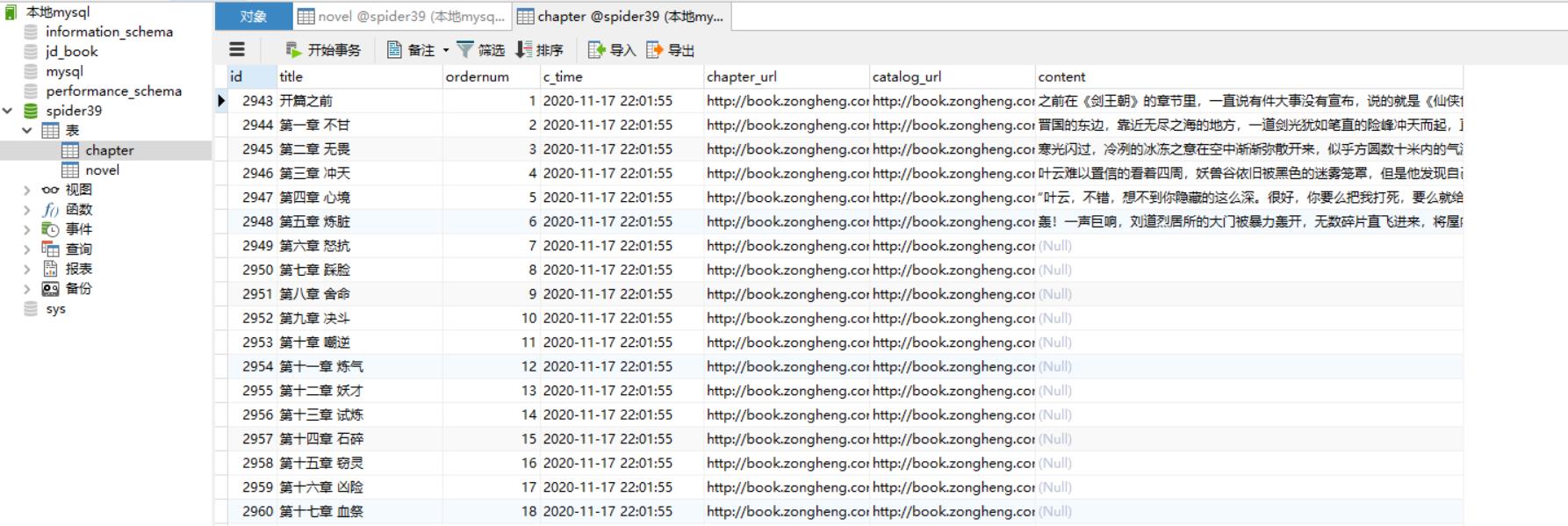
观察chapter表会发现刚好拿到两本书的前六章内容!
到此为止,ZH小说项目源码:
百度网盘项目源码:
链接:https://pan.baidu.com/s/1AS6dno6VpPQsHcQojBqXnw
提取码:uwph
以上是关于Python爬虫之Scrapy框架系列(14)——实战ZH小说爬取多页爬取的主要内容,如果未能解决你的问题,请参考以下文章