:Partitioning Concepts 读书笔记
Posted dingdingfish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:Partitioning Concepts 读书笔记相关的知识,希望对你有一定的参考价值。
本文为Oracle 19c VLDB and Partitioning Guide第2章Partitioning Concepts的读书笔记。
分区可提高各种应用程序的性能、可管理性和可用性,并有助于降低存储大量数据的总拥有成本。
分区允许将表、索引和按索引组织的表细分为更小的部分,从而能够以更精细的粒度级别管理和访问这些数据库对象。 Oracle 提供了丰富多样的分区策略和扩展来满足每个业务需求。 因为它是完全透明的,所以分区几乎可以应用于任何应用程序,而不需要潜在的昂贵和耗时的应用程序更改。
2.1 Partitioning Overview
分区提供了一种将对象细分为更小块的技术。
分区允许将表、索引或索引组织的表细分为更小的块,其中每个这样的数据库对象都称为一个分区。 每个分区都有自己的名称,并且可以选择拥有自己的存储特性。
2.1.1 Basics of Partitioning
分区可以集中或单独管理对象。
从数据库管理员的角度来看,一个分区对象有多个可以集中或单独管理的部分。 这为管理员管理分区对象提供了相当大的灵活性。 但是,从应用程序的角度来看,分区表与非分区表是相同的; 使用 SQL 查询和 DML 语句访问分区表时无需进行任何修改。
图 2-1 提供了分区表与非分区表的区别的图形视图。
图 2-1 分区表和非分区表的视图
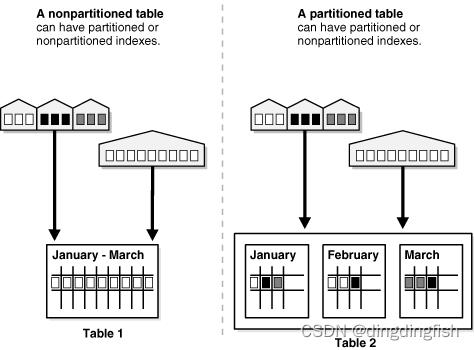
该图显示分区表和非分区表都可以具有分区索引或非分区索引。
2.1.2 Partitioning Key
分区表中的每一行都使用键明确分配给单个分区。分区键决定了某一行位于哪个分区
分区键由一个或多个列组成,这些列确定存储每一行的分区。 Oracle 使用分区键自动将插入、更新和删除操作定向到适当的分区。
验证分区内容
您可以使用 ORA_PARTITION_VALIDATION SQL 函数识别分区中的行是否符合分区定义,或者该行的分区键是否违反分区定义。 SQL 函数将 rowid 作为输入,如果该行位于正确的分区中,则返回 1,否则返回 0。 该功能适用于内部和外部分区和子分区的内部、外部和混合分区表。
SQL> CREATE TABLE test1 (column1 NUMBER)
PARTITION BY RANGE(column1)
(PARTITION p1 VALUES LESS THAN (10),
PARTITION p2 VALUES LESS THAN (20));
SQL> CREATE TABLE test2 (column1 NUMBER);
SQL> INSERT INTO test1 VALUES (1);
SQL> INSERT INTO test2 VALUES (99);
SQL> ALTER TABLE test1 EXCHANGE PARTITION p2 WITH TABLE test2 WITHOUT VALIDATION;
SQL> SELECT test1.*, ORA_PARTITION_VALIDATION(rowid) FROM test1;
COL1 ORA_PARTITION_VALIDATION(ROWID)
---------- -------------------------------
1 1
99 0
上例出现不在正确分区的情况,原因是EXCHANGE PARTITION 时没有做VALIDATION。
2.1.3 Partitioned Tables
大多数表都可以分区。
除了那些包含 LONG 或 LONG RAW 数据类型的列的表之外,任何表都最多可以分区为一百万个单独的分区。 但是,您可以使用包含具有 CLOB 或 BLOB 数据类型的列的表。
注意:为了减少磁盘和内存的使用(特别是缓冲区缓存),您可以在数据库中以压缩格式存储表和分区表的分区。 这通常会提高只读操作的scale-up。 表压缩还可以加快查询执行速度。 但是,CPU 开销有一点成本。
2.1.3.1 When to Partition a Table
在某些情况下,您希望对表进行分区。
对于应该考虑(但不是必须)对表进行分区的情况,以下是一些建议:
- 大于 2 GB 的表。
这些表应始终被视为分区的候选者。 - 包含历史数据的表,其中新数据被添加到最新的分区中。
一个典型的例子是一个历史表,其中只有当前月份的数据是可更新的,而其他 11 个月是只读的。 - 其内容必须分布在不同类型的存储设备上的表。
2G有点太小,在OOW 2017和OCW 2022上,都提到分区的大小至少要为5GB。
2.1.3.2 When to Partition an Index
在某些情况下,您希望对索引进行分区。
以下是关于何时考虑对索引进行分区的一些建议:
- 删除数据时避免索引维护。
- 在不使整个索引失效的情况下对部分数据进行维护。
- 减少索引对具有单调递增值的列造成的索引倾斜的影响。
2.1.4 Partitioned Index-Organized Tables
分区索引组织表对于为索引组织表提供改进的性能、可管理性和可用性非常有用。
对索引组织表进行分区:
- 分区列必须是主键列的子集。
- 二级索引可以分区(本地和全局)。
- OVERFLOW 数据段总是与表分区等分。
2.1.5 System Partitioning
系统分区支持应用程序控制的分区,而无需数据库控制数据放置。
数据库只是提供了将表分解为分区的能力,而无需知道各个分区将用于什么。 分区的所有方面都必须由应用程序控制。 例如,在没有明确指定分区的情况下尝试插入系统分区表会失败。
系统分区提供了众所周知的分区优势(可扩展性、可用性和可管理性),但分区和实际数据放置由应用程序控制。
也可以看下:Oracle Database Data Cartridge Developer’s Guide 了解有关系统分区的更多信息
有点象分表的方案。
2.1.6 Partitioning for Information Lifecycle Management
信息生命周期管理 (ILM) 关注在其生命周期内管理数据。
分区在 ILM 中起着关键作用,因为它使数据组(即分区)能够分布在不同类型的存储设备上并单独管理。
2.1.7 Range Partitioning for Hash Clusters
Oracle 数据库支持分区哈希集群。
分区哈希集群仅支持单级范围分区。
2.1.8 Partitioning and LOB Data
存储在数据库的 LOB 列中的非结构化数据(例如图像和文档)也可以进行分区。
当一个表被分区时,所有的列都驻留在该分区的表空间中,除了 LOB 列,它可以存储在它们自己的表空间中。那么是否分区后,LOB列专用的分区也从1个变成多个,即分区的数量?
当表由大型 LOB 组成时,此技术非常有用,因为它们可以与主数据分开存储。 如果主数据经常更新但 LOB 数据没有更新,这可能是有益的。 例如,员工记录可能包含一张不太可能经常更改的照片。 但是,员工的人事详细信息(例如地址、部门、经理等)可能会发生变化。 这种方法还意味着您可以使用更便宜的存储来存储 LOB 数据,并且可以使用更昂贵、更快的存储来存储员工记录。
2.1.9 Partitioning on External Tables
外部表支持分区。一个外部分区对应一个外部文件。多个外部分区不可能同时对应一个外部文件。
此功能支持优化,例如静态分区修剪、动态修剪和按分区的连接,以对分区外部表进行查询。 此功能还为每个外部表分区提供基于分区的增量统计信息收集,从而实现更好的优化器计划。
提示:对于云端的数据源,您可以手动创建外部表,但 Oracle 建议您使用 DBMS_CLOUD 包来执行此操作。MOS上有专门的文档,谈DBMS_CLOUD 包的安装与配置。
2.1.10 Hybrid Partitioned Tables
Oracle 混合分区表将经典的内部分区表与 Oracle 外部分区表相结合,形成更通用的分区,称为混合分区表。
混合分区表使您能够轻松地将内部分区和外部分区(驻留在数据库外部源上的分区)集成到单个分区表中。 使用此功能还可以让您轻松地将非活动分区移动到外部文件,以获得更便宜的存储解决方案。
混合分区表的分区可以驻留在 Oracle 表空间和外部源上,例如具有逗号分隔值 (CSV) 记录的 Linux 文件、具有 Java 服务器的 Hadoop 分布式文件系统 (HDFS) 上的文件或云上的对象存储。 混合分区表支持外部分区的所有现有外部表类型:ORACLE_DATAPUMP、ORACLE_LOADER、ORACLE_HDFS、ORACLE_HIVE。 外部分区的外部表类型使用以下访问驱动程序类型:
- ORACLE_DATAPUMP
- ORACLE_LOADER
- ORACLE_HDFS
- ORACLE_HIVE
其实还有一个驱动是ORACLE_BIGDATA,就是前面提到的DBMS_CLOUD包。但是混合分区表不支持
对于 ORACLE_LOADER 和 ORACLE_DATAPUMP 访问驱动类型的外部分区,您必须授予用户以下权限:
- 数据文件所在目录的 READ 权限
- 日志记录和坏文件所在目录的 WRITE 权限
- 预处理程序所在目录的 EXECUTE 权限
表级外部参数适用于混合分区表的所有外部分区。 例如,在 EXTERNAL PARTITION ATTRIBUTES 子句中定义的 DEFAULT DIRECTORY 值是数据文件、日志记录和坏文件的默认位置。 您可以在分区子句中使用 DEFAULT DIRECTORY 值覆盖默认目录位置。 对于 ORACLE_HIVE 和 ORACLE_HDFS 访问驱动类型的外部分区,DEFAULT DIRECTORY 仅用于存储日志文件的规范。
不支持对存储在外部分区中的数据执行约束,因为约束适用于整个表。 例如,不能对混合分区表强制执行主键或外键约束。 混合分区表只支持 RELY DISABLE 模式下的约束,例如 NOT NULL、主键、唯一和外主键。 要激活基于这些约束的优化,请将会话参数 QUERY_REWRITE_INTEGRITY 设置为 TRUSTED 或 STALE_TOLERATED。
混合分区表可以跨内部和外部分区使用基于分区的优化。 基于分区的优化包括以下跨内部和外部数据源:
- 静态分区修剪
- 动态分区修剪
- Bloom修剪
混合分区表为用户提供了在内部和外部分区之间移动数据的能力,以实现经济高效的目的。 但是,在表级别定义的自动数据优化 (ADO) 仅对表的内部分区有影响。
混合分区表支持的操作
以下是混合分区表支持的操作。
- 创建单级 RANGE 和 LIST 分区方法
- 使用 ALTER TABLE … DDL,例如 ADD、DROP 和 RENAME 分区
- 在分区级别为外部分区修改外部数据源的位置
- 将现有的分区内部表更改为包含内部和外部分区的混合分区表
- 将现有位置更改为空位置,导致外部分区为空
- 在内部分区上创建全局非唯一索引
- 在内部分区上创建物化视图
- 仅在 QUERY_REWRITE_INTEGRITY 陈旧容忍模式下创建包含外部分区的物化视图
- 外部分区上的完整分区智能刷新
- DML 触发对内部分区上的混合分区表的操作
- 仅在混合分区表上使用 ANALYZE TABLE … VALIDATE STRUCTURE 验证内部分区
- 将没有外部分区的现有混合分区表更改为仅具有内部分区的分区表
- 外部分区可以与外部非分区表交换。此外,内部分区可以与内部非分区表交换。
混合分区表的限制
以下是混合分区表的限制和局限(原文为restrictions and limitations,Google翻译为限制和限制)。
- 除非明确说明,否则适用于外部表的限制也适用于混合分区表
- 不支持 REFERENCE 和 SYSTEM 分区方法
- 仅支持单级 LIST 和 RANGE 分区。
- 没有唯一索引或全局唯一索引。只允许局部索引并且唯一索引不能是局部的。
- HIVE 仅支持单级列表分区。
- 不允许属性聚类(CLUSTERING 子句)。
- 仅对混合分区表的内部分区进行 DML 操作(外部分区被视为只读分区)
- 在表级别定义的in-memory只对混合分区表的内部分区有影响。也许在分区级别可以定义,待查
- 无列默认值
- 不允许使用不可见的列。
- 不允许使用 CELLMEMORY 子句。
- 不允许在外部分区上进行 SPLIT、MERGE 和 MOVE 维护操作。
- 不允许使用 LOB、LONG 和 ADT 类型。
- 只允许 RELY 约束
2.1.11 Collections in XMLType and Object Data
略。
2.2 Benefits of Partitioning
通过提高性能、可管理性和可用性,分区可以为各种应用程序提供巨大的好处。
分区大大提高某些查询或维护操作的性能并不罕见。 此外,分区可以大大简化常见的管理任务。
分区还使数据库设计人员和管理员能够解决尖端应用程序带来的一些难题。 分区是构建多TB 级系统或具有极高可用性要求的系统的关键工具。
2.2.1 Partitioning for Performance
您可以使用分区来提高性能。
通过限制要检查或操作的数据量,并通过为并行执行提供数据分布,分区提供了多种性能优势。
2.2.1.1 Partition Pruning for Performance
分区修剪是使用分区提高性能的最简单也是最实质的方法。
就按照Google的默认翻译,以下将Partition Pruning翻译为分区修剪
分区修剪通常可以将查询性能提高几个数量级。 例如,假设一个应用程序包含一个包含订单历史记录的 Orders 表,并且该表已按周分区。 请求单周订单的查询只会访问 Orders 表的单个分区。 如果 Orders 表有 2 年的历史数据,那么此查询将访问一个分区而不是 104 个分区。 仅仅因为分区修剪,该查询的执行速度可能会提高 100 倍。
分区修剪适用于所有 Oracle 性能特性。 Oracle 使用任何索引或连接技术或并行访问方法进行分区修剪。
2.2.1.2 Partition-Wise Joins for Performance
分区还可以通过使用称为按分区的连接的技术来提高多表连接的性能。
以下将partition-wise join翻译为按分区的连接,这里wise不是智能的意思
依据参考这里:
-wise is a suffix that is attached to a noun with a hyphen to form an adjective or adverb that means with respect to or concerning, in the manner of or in the direction of.
当正在连接两个表并且两个表都在连接键上进行分区时,或者当引用分区表与其父表连接时,可以应用按分区的连接。 分区连接将大连接分解为每个分区之间发生的较小连接,从而在更短的时间内完成整体连接。 这为串行和并行执行提供了显着的性能优势。
2.2.2 Partitioning for Manageability
分区使您能够将表和索引分区为更小、更易于管理的单元,从而使数据库管理员能够采用分而治之的方法进行数据管理。
通过分区,维护操作可以集中在表的特定部分。 例如,您可以备份表的单个分区,而不是备份整个表。 对于跨整个数据库对象的维护操作,可以在每个分区的基础上执行这些操作,从而将维护过程划分为更易于管理的块。
用于可管理性的分区的典型用法是支持数据仓库中的滚动窗口加载过程。 假设您每周将新数据加载到表中。 可以对该表进行分区,以便每个分区包含一周的数据。 加载过程只是使用分区交换加载添加新分区。 添加单个分区比修改整个表要高效得多,因为您不需要修改任何其他分区。
2.2.3 Partitioning for Availability
分区数据库对象提供分区独立性。 分区独立性的这一特性可能是高可用性策略的重要组成部分。
例如,如果分区表的一个分区不可用,则该表的所有其他分区都保持在线且可用。 应用程序可以继续对表的可用分区执行查询和事务,并且这些数据库操作可以成功运行,前提是它们不需要访问不可用的分区。
数据库管理员可以指定每个分区存储在单独的表空间中; 最常见的情况是将这些表空间存储在不同的存储层上。 将不同的分区存储在不同的表空间中,使您可以对每个单独的分区进行备份和恢复操作,而与表中的其他分区无关。 因此,允许数据库的活动部分更快地可用,以便可以继续访问系统,同时仍在恢复非活动数据。 此外,分区可以减少计划的停机时间。 分区提供的性能提升可能使您能够在相对较小的批处理窗口中完成对大型数据库对象的维护操作。
2.3 Partitioning Strategies
Oracle Partitioning 提供了三种基本数据分布方法作为基本分区策略,用于控制如何将数据放入各个分区。
这些策略是:
- 范围
- 哈希
- 列表
使用这些数据分布方法,可以将表分区为单级或复合分区表:
- 单级分区
- 复合分区
每种分区策略都有不同的优势和设计考虑。 因此,每种策略都更适合特定情况。
2.3.1 Single-Level Partitioning
单级分区包括范围、哈希和列表分区。
通过指定以下数据分布方法之一,使用一个或多个列作为分区键来定义表:
- 范围分区
- 哈希分区
- 列表分区
例如,考虑一个表,其类型为 NUMBER 列作为分区键,两个分区 less_than_five_hundred 和 less_than_one_thousand。 less_than_one_thousand 分区包含满足以下条件的行:
500 <= partitioning key < 1000
注意左侧有等号而右侧没有
图 2-2 提供了单级分区表的基本分区策略的图形视图。
图 2-2 列表、范围和哈希分区
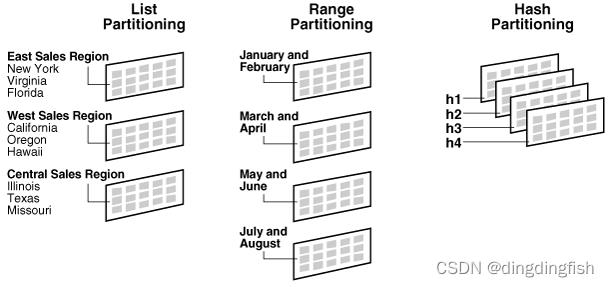
2.3.1.1 Range Partitioning
范围分区根据您为每个分区建立的分区键值的范围将数据映射到分区。
范围分区是最常见的分区类型,通常与日期一起使用(当然字符类型的日期也是可以的,反正是用于比较)。 对于以日期列作为分区键的表,January-2017 分区将包含分区键值从 2017 年 1 月 1 日到 2017 年 1 月 31 日的行。
每个分区都有一个 VALUES LESS THAN 子句,它为分区指定一个不包含在内的上限。 等于或高于此文字的分区键的任何值都将添加到下一个更高的分区。 除第一个分区外,所有分区都具有由前一个分区的 VALUES LESS THAN 子句指定的隐式下限。
可以为最高分区定义 MAXVALUE 文字。 MAXVALUE 表示一个虚拟的无限值,它的排序高于分区键的任何其他可能值,包括 NULL 值。
2.3.1.2 Hash Partitioning
散列分区根据 Oracle 应用于您标识的分区键的散列算法将数据映射到分区。
散列算法在分区之间均匀分布行,使分区大小大致相同。
哈希分区是跨设备均匀分布数据的理想方法。 哈希分区也是范围分区的一种易于使用的替代方案,尤其是当要分区的数据不是历史数据或没有明显的分区键时。
注意:您不能更改分区使用的散列算法。
2.3.1.3 List Partitioning
列表分区使您能够通过在每个分区的描述中为分区键指定离散值列表来显式控制行映射到分区的方式。
列表分区的优点是您可以以自然的方式对无序和不相关的数据集进行分组和组织。 对于以 region 列作为分区键的表,East Sales Region 分区可能包含值 New York、Virginia 和 Florida。
DEFAULT 分区通过使用默认分区使您能够避免为列表分区表指定所有可能的值,因此未映射到任何其他分区的行不会生成错误。
2.3.2 Composite Partitioning
复合分区是基本数据分布方法的组合。
使用复合分区,表通过一种数据分布方法进行分区,然后使用第二种数据分布方法将每个分区进一步细分为子分区。 给定分区的所有子分区表示数据的逻辑子集。
复合分区支持历史操作,例如添加新的范围分区,但还通过子分区提供更高程度的潜在分区修剪和更精细的数据放置粒度。 图 2-3 提供了范围哈希和范围列表复合分区的图形视图,作为示例。
图 2-3 复合范围 - 列表分区
复合分区的类型有:
- 复合范围-范围分区
- 复合范围哈希分区
- 复合范围列表分区
- 复合列表范围分区
- 复合列表-哈希分区
- 复合列表-列表分区
- 复合散列-散列分区
- 复合哈希表分区
- 复合哈希范围分区
2.3.2.1 Composite Range-Range Partitioning
复合范围-范围分区允许沿两个维度进行逻辑范围分区。
复合范围-范围分区的一个示例是按 order_date 分区和按 shipping_date 进行范围子分区。
2.3.2.2 Composite Range-Hash Partitioning
复合范围哈希分区使用范围方法对数据进行分区,并在每个分区内使用哈希方法对其进行子分区。
复合范围哈希分区提供了范围分区的改进可管理性以及哈希分区的数据放置、条带化和并行性优势。
2.3.2.3 Composite Range-List Partitioning
复合范围列表分区使用范围方法对数据进行分区,并在每个分区内使用列表方法对其进行子分区。
复合范围列表分区提供范围分区的可管理性和子分区的列表分区的显式控制。
2.3.2.4 Composite List-Range Partitioning
复合列表范围分区允许在给定列表分区策略内进行逻辑范围子分区。
组合列表-范围分区的一个示例是按 country_id 进行列表分区和按 order_date 进行范围子分区。
2.3.2.5 Composite List-Hash Partitioning
复合列表哈希分区启用列表分区对象的哈希子分区。
复合列表哈希分区对于启用按分区的连接很有用。
2.3.2.6 Composite List-List Partitioning
复合列表-列表分区允许沿两个维度进行逻辑列表分区。
组合列表-列表分区的一个示例是按 country_id 的列表分区和按 sales_channel 的列表子分区。
2.3.2.7 Composite Hash-Hash Partitioning
复合哈希-哈希分区允许沿两个维度进行哈希分区。
复合哈希-哈希分区技术有利于实现沿二维的按分区连接。
2.3.2.8 Composite Hash-List Partitioning
复合哈希列表分区允许沿两个维度进行哈希分区。
2.3.2.9 Composite Hash-Range Partitioning
复合哈希范围分区允许沿两个维度进行散列分区。
2.4 Partitioning Extensions
除了基本的分区策略之外,Oracle 数据库还提供了分区扩展。
2.4.1 Manageability Extensions
以下扩展显着增强了分区表的可管理性:
- 间隔分区
- 分区顾问
2.4.1.1 Interval Partitioning
间隔分区是范围分区的扩展。
间隔分区指示数据库在插入到表中的数据超过所有现有范围分区时自动创建指定间隔的分区。 您必须至少指定一个范围分区。 范围分区键值确定范围分区的高值,称为过渡点,数据库为值超出该过渡点的数据创建间隔分区。 每个间隔分区的下边界是前一个范围或间隔分区的非包含上边界。
例如,如果您创建具有每月间隔的间隔分区表并将转换点设置为 2007 年 1 月 1 日,则 2007 年 1 月间隔的下限为 2007 年 1 月 1 日。2007 年 7 月间隔的下限为 7 月 2007 年 1 月,无论是否创建了 2007 年 6 月的分区。
您可以创建单级间隔分区表和以下复合分区表:
- 区间范围
- 区间哈希
- 间隔列表
间隔分区支持范围分区功能的一个子集。
2.4.1.2 Partition Advisor
分区顾问是 SQL 访问顾问的一部分。
这里的访问实际指的是访问路径。
分区顾问可以根据提供的 SQL 语句工作负载为表推荐分区策略,这些工作负载可以由 SQL 缓存、SQL 调整集提供或由用户定义。
2.4.2 Partitioning Key Extensions
以下扩展扩展了定义分区键的灵活性:
- 参考分区
- 基于虚拟列的分区
2.4.2.1 Reference Partitioning
引用分区允许对通过引用约束相互关联的两个表进行分区。
分区键通过现有的父子关系解析,由启用和活动的主键和外键约束强制执行。
此扩展的好处是具有父子关系的表可以通过从父表继承分区键进行逻辑均分,而无需复制键列。逻辑依赖还自动级联分区维护操作,从而使应用程序开发更容易,更不容易出错。
引用分区的一个示例是通过引用约束 orderid_refconstraint 相互关联的 Orders 和 LineItems 表。即 LineItems.order_id 引用 Orders.order_id。 Orders 表在 order_date 进行范围分区。 LineItems 的 orderid_refconstraint 上的引用分区导致创建以下分区表,该分区表在 Orders 表上进行了等分区,如图 2-4 和图 2-5 所示。
图 2-4 参考分区前
图 2-5 使用参考分区后

所有基本分区策略都可用于参考分区。 间隔分区也可以与参考分区一起使用。
注意:在线重定义包 (DBMS_REDEFINITION) 不支持引用分区。
2.4.2.2 Virtual Column-Based Partitioning
Oracle 分区包括在虚拟列上定义的分区策略。
虚拟列使分区键能够由表达式定义,使用表的一个或多个现有列。 表达式仅存储为元数据。 例如,十位数的账户 ID 可以包括账户分行信息作为前三位数字。 随着基于虚拟列的分区的扩展,包含 ACCOUNT_ID 列的 ACCOUNTS 表可以使用虚拟(派生)列 ACCOUNT_BRANCH 进行扩展。 ACCOUNT_BRANCH 派生自 ACCOUNT_ID 列的前三位,它成为该表的分区键。
所有基本分区策略都支持基于虚拟列的分区,包括参考分区以及区间和区间-* 复合分区。
2.5 Indexing on Partitioned Tables
分区表上的索引可以是非分区的,也可以是分区的。
与分区表一样,分区索引提高了可管理性、可用性、性能和可伸缩性。 它们既可以独立分区(全局索引),也可以自动链接到表的分区方法(本地索引)。 通常,您应该为 OLTP 应用程序使用全局索引,为数据仓库或决策支持系统 (DSS) 应用程序使用本地索引。
全局索引与分区无关,例如主键必须是全局索引。
2.5.1 Deciding on the Type of Partitioned Index to Use
应在查看各种因素后选择要使用的分区索引类型。
在决定使用哪种分区索引时,应按此顺序考虑以下准则:
- 如果表分区列是索引键的子集,则使用本地索引。 如果是这种情况,那么你就完成了。 如果不是这种情况,则继续执行准则 2。
- 如果索引是唯一的并且不包括分区键列,则使用全局索引。 如果是这种情况,那么你就完成了。 否则,继续执行准则 3。
- 如果您的首要任务是可管理性,那么请考虑使用本地索引。 如果是这种情况,那么你就完成了。 如果不是这种情况,请继续执行指南 4。
- 如果应用程序是 OLTP 类型并且用户需要快速响应时间,则使用全局索引。 如果应用程序是 DSS 类型并且用户对吞吐量更感兴趣,那么使用本地索引。
2.5.2 Local Partitioned Indexes
本地分区索引比其他类型的分区索引更容易管理。
它们还提供更高的可用性并且在 DSS 环境中很常见。这样做的原因是均分:本地索引的每个分区都与表的一个分区相关联。此功能使 Oracle 能够自动保持索引分区与表分区同步,并使每个表索引对独立。任何使一个分区的数据无效或不可用的操作只会影响单个分区。
当对表进行分区或子分区维护操作时,本地分区索引支持更高的可用性。一种称为本地无前缀索引的索引对历史数据库非常有用。在这种类型的索引中,分区不在索引列的左前缀上。
您不能将分区显式添加到本地索引。相反,仅当您将分区添加到基础表时,才会将新分区添加到本地索引。同样,您不能从本地索引中显式删除分区。相反,仅当您从基础表中删除分区时,才会删除本地索引分区。
本地索引可以是唯一的。但是,为了使本地索引唯一,表的分区键必须是索引键列的一部分。
图 2-6 提供了本地分区索引的图形视图。
图 2-6 本地分区索引

2.5.3 Global Partitioned Indexes
Oracle 提供全局范围分区索引和全局哈希分区索引。
2.5.3.1 Global Range Partitioned Indexes
全局范围分区索引的灵活性在于分区程度和分区键与表的分区方法无关。
全局索引的最高分区必须有一个分区界限,其所有值都是 MAXVALUE。 这确保了基础表中的所有行都可以在索引中表示。 全局前缀索引可以是唯一的或非唯一的。
您不能将分区添加到全局索引,因为最高分区的分区界限始终为 MAXVALUE。 要添加新的最高分区,请使用 ALTER INDEX SPLIT PARTITION 语句。 如果全局索引分区为空,您可以通过发出 ALTER INDEX DROP PARTITION 语句显式删除它。 如果全局索引分区包含数据,则删除该分区会导致下一个最高分区被标记为不可用。 您不能删除全局索引中的最高分区。
2.5.3.2 Global Hash Partitioned Indexes
全局哈希分区索引通过在索引单调增长时分散争用来提高性能。
换句话说,大多数索引插入只发生在索引的右边缘,对于全局哈希分区索引,它均匀分布在 N 个散列分区中。
2.5.3.3 Maintenance of Global Partitioned Indexes
默认情况下,对堆组织表上的分区执行以下操作会将所有全局索引标记为不可用:
ADD (HASH)
COALESCE (HASH)
DROP
EXCHANGE
MERGE
MOVE
SPLIT
TRUNCATE
可以通过将子句 UPDATE INDEXES 附加到操作的 SQL 语句来维护这些索引。 但是请注意,附加 UPDATE INDEXES 子句将维护全局索引作为分区维护操作的一部分,可能会延长操作的运行时间并增加资源需求。
维护全局索引的两个优点是:
- 该索引在整个操作过程中保持可用和在线。 因此,此操作不会影响其他应用程序。
- 操作后不必重建索引。
- DROP 和 TRUNCATE 的全局索引维护是作为仅元数据操作实现的。
注意:仅堆组织表支持此功能。
图 2-7 提供了全局分区索引的图形视图。
图 2-7 全局分区索引
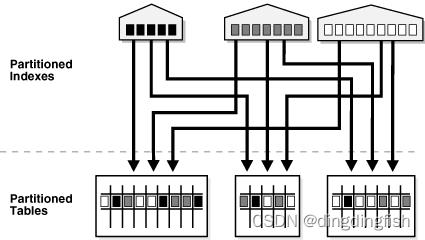
2.5.4 Global Nonpartitioned Indexes
全局非分区索引的行为与本地非分区索引一样。
图 2-8 提供了全局非分区索引的图形视图。
图 2-8 全局非分区索引

2.5.5 Miscellaneous Information about Creating Indexes on Partitioned Tables
您可以在分区表上创建位图索引,但有一些限制。
位图索引必须是分区表的本地索引。 它们不能是全局索引。
全局索引可以是唯一的。 仅当分区键是索引键的一部分时,本地索引才能唯一。
2.5.6 Partial Indexes for Partitioned Tables
您可以在表的分区子集上创建本地和全局索引,从而在创建索引时提供更大的灵活性。
使用默认表索引属性支持此功能。 创建或更改表时,可以为表或其分区指定默认索引属性。 表索引属性仅用于部分索引。
当索引在表上创建为 PARTIAL 时:
- 本地索引:如果为表分区打开索引,则创建的索引分区可用,否则不可用。 您可以通过在索引或索引分区级别指定 USABLE/UNUSABLE 来覆盖此行为。
- 全局索引:仅包括打开索引的分区,排除其他分区。
唯一索引或用于强制唯一约束的索引不支持此功能。 如果未指定 FULL 或 PARTIAL,则 FULL 是默认值。
默认情况下,任何索引都创建为 FULL 索引,这将索引与表索引属性分离。
也可以在分区和子分区级别指定 INDEXING 子句。
以下 SQL DDL 创建包含这些项目的表:
分区 ORD_P1 和 ORD_P3 包含在所有部分全局索引中
与上述两个表分区对应的本地索引分区(对于创建 PARTIAL 的索引)默认创建可用。
其他分区从所有部分全局索引中排除,并在本地索引中创建不可用(对于创建 PARTIAL 的索引)。
CREATE TABLE orders (
order_id NUMBER(12),
order_date DATE CONSTRAINT order_date_nn NOT NULL,
order_mode VARCHAR2(8),
customer_id NUMBER(6) CONSTRAINT order_customer_id_nn NOT NULL,
order_status NUMBER(2),
order_total NUMBER(8,2),
sales_rep_id NUMBER(6),
promotion_id NUMBER(6),
CONSTRAINT order_mode_lov CHECK (order_mode in ('direct','online')),
CONSTRAINT order_total_min CHECK (order_total >= 0))
INDEXING OFF
PARTITION BY RANGE (ORDER_DATE)
(PARTITION ord_p1 VALUES LESS THAN (TO_DATE('01-MAR-1999','DD-MON-YYYY'))
INDEXING ON,
PARTITION ord_p2 VALUES LESS THAN (TO_DATE('01-JUL-1999','DD-MON-YYYY'))
INDEXING OFF,
PARTITION ord_p3 VALUES LESS THAN (TO_DATE('01-OCT-1999','DD-MON-YYYY'))
INDEXING ON,
PARTITION ord_p4 VALUES LESS THAN (TO_DATE('01-MAR-2000','DD-MON-YYYY')),
PARTITION ord_p5 VALUES LESS THAN (TO_DATE('01-MAR-2010','DD-MON-YYYY')));
通过指定 INDEXING PARTIAL 子句,可以创建本地或全局部分索引以遵循前面 SQL 示例的表索引属性。
CREATE INDEX ORDERS_ORDER_TOTAL_GIDX ON ORDERS (ORDER_TOTAL)
GLOBAL INDEXING PARTIAL;
创建 ORDERS_ORDER_TOTAL_GIDX 索引以仅索引那些具有 INDEXING ON 的分区,并排除剩余的分区。
对视图的更新包括以下内容:
- 表索引属性 - 列 INDEXING 添加到 *_PART_TABLES、*_TAB_PARTITIONS 和 *_TAB_SUBPARTITIONS 视图。
此列具有两个值之一 ON 或 OFF,指定索引打开或索引关闭。 - 部分全局索引作为索引级别属性 - 将新列 INDEXING 添加到 USER_INDEXES 视图。 此列可以设置为 FULL 或 PARTIAL。
- 部分全局索引优化 - 列 ORPHANED_ENTRIES 添加到字典视图 USER_INDEXES 和 USER_IND_PARTITIONS 以表示全局索引(分区)是否包含由于在 DROP/TRUNCATE PARTITION 期间延迟索引维护或 MODIFY PARTITION INDEXING OFF 而导致的过时条目。 该列可以具有以下值之一:
- YES => 索引(分区)包含孤立条目
- NO => 索引(分区)不包含任何孤立条目
2.5.7 Partitioned Indexes on Composite Partitions
在复合分区上进行分区索引时需要考虑一些事项
在复合分区上使用分区索引时,请注意以下几点:
- 子分区索引始终是本地的,默认情况下与表子分区一起存储。
- 可以在索引或索引子分区级别指定表空间。
以上是关于:Partitioning Concepts 读书笔记的主要内容,如果未能解决你的问题,请参考以下文章