pandas中的concat函数拼接多张表时,为什么拼接后的结果除第一张表其他都是NaN
Posted 知行博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas中的concat函数拼接多张表时,为什么拼接后的结果除第一张表其他都是NaN相关的知识,希望对你有一定的参考价值。

例如在一个文件夹中有这样一些文件。在数据处理过程中,我们想要将它们拼接为一个文件。

其中每一个文件都有着相同列,如下:

我们使用了pandas中的concat函数进行拼接,拼接结果如下:

我们发现除了第一张表之外,其他都是表并未正确拼接,显示为NaN。这是因为在concat过程中如果不同的DataFrame具有不同的列名,则在默认情况下,那些在其他DataFrame中缺失的列将是NaN。 要解决这个问题,可以指定参数ignore_index=True,以在concat过程中忽略列名。
concat是 Pandas 中一个用于横向和纵向拼接 DataFrame 的方法。它的使用方法如下:
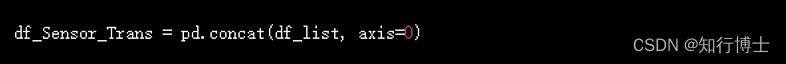
其中,df1, df2, df3 是要拼接的 DataFrame,axis=0 表示纵向拼接(合并行)。如果要横向拼接(合并列),则 axis=1。
另外,还有其它的几种可能:
-
在读取每个文件之前,检查文件是否具有相同的数据类型,以确保每个文件都具有相同的列名和相同的数据类型。
-
在调用pd.concat()函数之前,检查每个数据框是否具有相同的列名(包括有否列名前是否有空格),如果存在列名不匹配的问题,您可以将其修改为相同的列名,以确保数据帧可以正确合并。
-
如果上述方法都不起作用,请考虑打印数据帧并手动检查是否存在任何错误,然后再尝试修复它们。
这里官方文档关于concat函数的解释:pandas.concat — pandas 1.5.3 documentation
想进一步了解的可以去看一下。
以上是关于pandas中的concat函数拼接多张表时,为什么拼接后的结果除第一张表其他都是NaN的主要内容,如果未能解决你的问题,请参考以下文章