MMsegmentation训练自己的voc数据集
Posted liuchen_chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MMsegmentation训练自己的voc数据集相关的知识,希望对你有一定的参考价值。
使用labelme标注数据并转化为voc格式
安装labelme并打开(这里我把labelme安装在Anaconda的虚拟环境中了),在Anacondaprompt中打开

选择文件夹进行标注
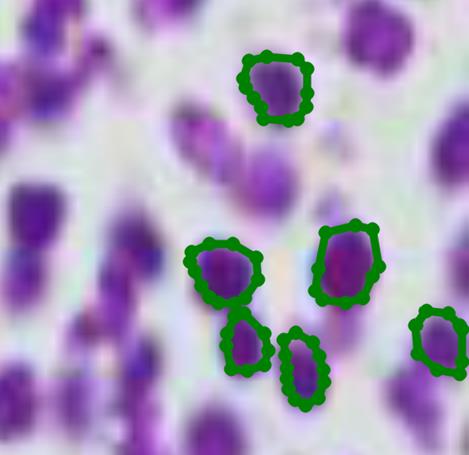
保存之后每个图片会有一个对应的json文件
进入网址https://github.com/wkentaro/labelme下载转换脚本

使用pycharm打开文件examples/semantic_segmentation/labelme2voc.py
可以将自己的数据文件夹复制在同一目录下,根据自己的数据集新建一个label文本

在转换脚本下指定参数:
cell cell_voc --labelscell-labels.txt分别表示:输入文件夹名称 输出文件夹名称 --labels 标签列表
执行之后结果为:

使用脚本提取图片名称并写入train.txt,val.txt,test.txt
file_list = [] #建立列表,用于保存图片信息
# txt文件地址
write_file_name = r'cell_voc/name.txt'
write_file = open(write_file_name, "w") #以只写方式打开write_file_name文件
for file in os.listdir(data_base_dir): #file为current_dir当前目录下图片名
if file.endswith(".jpg"): #如果file以jpg结尾
write_name = file #图片路径 + 图片名 + 标签
file_list.append(write_name) #将write_name添加到file_list列表最后
sorted(file_list) #将列表中所有元素随机排列
number_of_lines = len(file_list) #列表中元素个数
#将图片信息写入txt文件中
for current_line in range(number_of_lines):
write_file.write(file_list[current_line] + '\\n')
#关闭文件
write_file.close()结果为:

复制到mmsegmentation中的data目录下
2. 根据预测类别数修改配置文件
在configs文件夹中选择合适的模型,我选择的是:pydeeplabv3plus_r50-d8_512x512_20k_voc12aug.py
在tools/train.py中传入参数(模型路径):
../configs/deeplabv3plus/deeplabv3plus_r50-d8_512x512_20k_voc12aug.py运行后会在当前文件夹下出现work_dirs文件夹,将文件夹下的deeplabv3plus_r50-d8_512x512_20k_voc12aug.py复制到/configs/deeplabv3plus文件夹下并改名
修改文件
num_classes=自己的数据类别数+1
data_root='.././data/cell_voc',#修改为自己的文件夹路径
split='train.txt',val,test同理
ann_dir=’SegmentationClassPNG’
修改文件mmseg/datasets/voc.py
CLASSES = ('background', 'cell')#分割类别
PALETTE = [[0, 0, 0], [128, 0, 0]]#分割颜色
修改文件:mmseg/core/evaluation/class_names.py中的voc_classes
def voc_classes():
return [
'background', 'cell'
]
3.加载预训练模型进行训练
预训练模型下载:https://github.com/open-mmlab/mmsegmentation
Benchmark and model zoo中选择运行的模型:

点击model下载到本地,复制到tools/work_dirs/deeplabv3plus_r50-d8_512x512_20k_voc12aug中
在my-deeplabv3plus_r50-d8_512x512_20k_voc12aug.py中修改预训练模型路径
load_from ='./work_dirs/deeplabv3plus_r50-d8_512x512_20k_voc12aug/deeplabv3plus_r50-d8_512x512_20k_voc12aug_20200617_102323-aad58ef1.pth'
在train.py中传入参数:自己的路径:
../configs/deeplabv3plus/my-deeplabv3plus_r50-d8_512x512_20k_voc12aug.py运行结果为:

运行完成之后,会在tools/work_dirs/deeplabv3plus_r50-d8_512x512_20k_voc12aug/iter_500.pth有一个训练模型,由于我训练了500次迭代,保存了第500次的模型
4.预测demo演示
在demo/image_demo.py中传如参数:
../data/cell_voc/JPEGImages/4cbd6c37f3a55a538d759d440344c287cac66260d3047a83f429e63e7a0f7f20.jpg
../configs/deeplabv3plus/my-deeplabv3plus_r50-d8_512x512_20k_voc12aug.py
../tools/work_dirs/deeplabv3plus_r50-d8_512x512_20k_voc12aug/iter_500.pth
--palette voc
分别代表:图片路径,网络路径,模型路径,颜色为voc模式
结果:

一般有错误都是路径问题。
以上是关于MMsegmentation训练自己的voc数据集的主要内容,如果未能解决你的问题,请参考以下文章