Ubuntu安装hadoop(3.2.4),hbase(2.4.0),hive(3.1.0),phoenix(5.1.2)集群
Posted fan_bigdata
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ubuntu安装hadoop(3.2.4),hbase(2.4.0),hive(3.1.0),phoenix(5.1.2)集群相关的知识,希望对你有一定的参考价值。
集群安装
1. 环境准备
1.1 服务器的准备
192.168.12.253 ds1
192.168.12.38 ds2
192.168.12.39 ds3
1.2 修改hostname(所有节点)
在192.168.12.253 节点上 hostnamectl set-hostname ds1
在192.168.12.38 节点上 hostnamectl set-hostname ds2
在192.168.12.39 节点上 hostnamectl set-hostname ds3
1.3 配置节点的IP-主机名映射信息(所有节点)
vi /etc/hosts
新增下面内容
192.168.12.253 ds1
192.168.12.38 ds2
192.168.12.39 ds3
1.4 关闭防火墙(所有节点)
sudo systemctl stop ufw
sudo systemctl disable ufw
1.5 修改SSH配置(所有节点)
vim /etc/ssh/sshd_config
将 PermitEmptyPasswords no 改为 PermitEmptyPasswords yes

1.6 配置免密登录(所有节点)
生成ssh key:(每个节点执行)
ssh-keygen -t rsa
ds1、ds2、ds3上操作互信配置:(每个节点执行)
ssh-copy-id -i ~/.ssh/id_rsa.pub ds1
ssh-copy-id -i ~/.ssh/id_rsa.pub ds2
ssh-copy-id -i ~/.ssh/id_rsa.pub ds3
上同上面操作类似,完成互信配置
1.7 安装jdk(所有节点)
安装命令:
sudo apt-get install openjdk-8-jre
查看jdk版本:
java -version
安装路径:
/usr/lib/jvm/java-8-openjdk-amd64
1.8 安装mysql(ds1)
安装命令:
sudo apt-get update
sudo apt-get install mysql-server
初始化配置:
sudo mysql_secure_installation
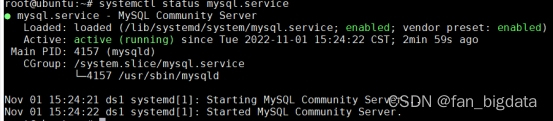
查看mysql的服务状态:
systemctl status mysql.service
修改配置文件 mysqld.cnf
cd /etc/mysql/mysql.conf.d
vim mysqld.cnf
将 bind-address = 127.0.0.1注释掉

配置mysql的环境变量
vim /etc/profile
添加
export MYSQL_HOME=/usr/share/mysql
export PATH=$MYSQL_HOME/bin:$PATH
刷新环境变量
source /etc/profile
启动和停止mysql服务
停止:
sudo service mysql stop
启动:
sudo service mysql start
进入mysql数据库
mysql -u root -p introcks1234
2. 安装zookeeper集群
2.1 下载zookeeper安装包
下载地址: https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
2.2 上传与解压
上传到 /home/intellif中
解压 :
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt
修改文件权限:
chmod -R 755 apache-zookeeper-3.8.0-bin
2.3 修改配置文件
cd apache-zookeeper-3.8.0-bin/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
新增下面内容:
server.1=ds1:2888:3888
server.2=ds2:2888:3888
server.3=ds3:2888:3888
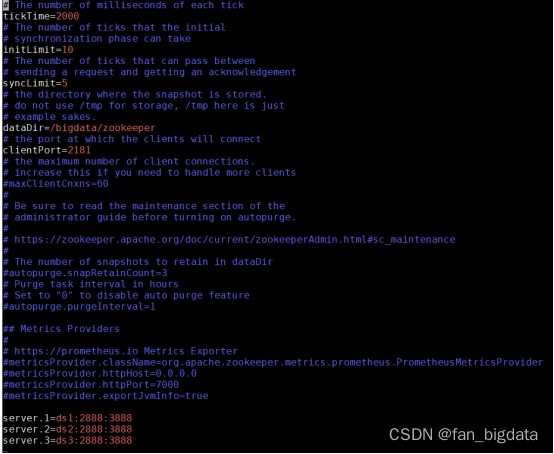
注意3888后面不能有空格,否则后面启动时会报错: Address unresolved: ds1:3888
2.4 分发到ds2,ds3中
将zookeeper分发到ds2,ds3中
scp -r apache-zookeeper-3.8.0-bin ds2:/opt
scp -r apache-zookeeper-3.8.0-bin ds3:/opt
2.5 配置环境变量(所有节点)
vim ~/.profile
添加下面两行:
export ZOOKEEPER_HOME=/opt/apache-zookeeper-3.8.0-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH

环境变量生效
source /etc/profile
2.6 创建myid文件
先创建目录/bigdata/zookeeper (所有节点)
mkdir -p /bigdata/zookeeper
cd /bigdata/zookeeper
在ds1上执行
echo 1 > myid
在ds2上执行
echo 2 > myid
在ds3上执行
echo 3 > myid
2.7 启动与停止、查看状态命令(所有节点)
启动:
zkServer.sh start
停止:
zkServer.sh stop
查看状态:
zkServer.sh status
3. 安装hadoop高可用集群
3.1集群规划
| ds1 | ds2 | ds3 | |
|---|---|---|---|
| NameNode | yes | yes | no |
| DataNode | yes | yes | yes |
| JournalNode | yes | yes | yes |
| NodeManager | yes | yes | yes |
| ResourceManager | yes | no | no |
| Zookeeper | yes | yes | yes |
| ZKFC | yes | yes | no |
3.2下载安装包
hadoop版本: 3.2.4
下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
3.3上传与解压
上传到服务器/home/intellif下
解压 :
tar -zxvf hadoop-3.2.4.tar.gz
mv hadoop-3.2.4/ /opt
3.4修改配置文件
Hadoop核心配置文件介绍:
| 文件名称 | 描述 |
|---|---|
| hadoop-env.sh | 脚本中要用到的环境变量,以运行hadoop |
| mapred-env.sh | 脚本中要用到的环境变量,以运行mapreduce(覆盖hadoop-env.sh中设置的变量) |
| yarn-env.sh | 脚本中要用到的环境变量,以运行YARN(覆盖hadoop-env.sh中设置的变量) |
| core-site.xml | Hadoop Core的配置项,例如HDFS,MAPREDUCE,YARN中常用的I/O设置等 |
| hdfs-site.xml | Hadoop守护进程的配置项,包括namenode和datanode等 |
| mapred-site.xml | MapReduce守护进程的配置项,包括job历史服务器 |
| yarn-site.xml | Yarn守护进程的配置项,包括资源管理器和节点管理器 |
| workers | 具体运行datanode和节点管理器的主机名称 |
cd /opt/hadoop-3.2.4/etc/hadoop
3.4.1 hadoop-env.sh配置修改
vim hadoop-env.sh
在最后添加:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=hdfs
export HDFS_DATANODE_USER=hdfs
export HDFS_ZKFC_USER=hdfs
export HDFS_JOURNALNODE_USER=hdfs
3.4.2 yarn-env.sh 配置修改
vim yarn-env.sh
在最后添加(jdk的路径):
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
3.4.3 core-site.xml 配置修改
vim core-site.xml
将替换为如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/hadoop/tmpdir</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>ds1:2181,ds2:2181,ds3:2181</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
</configuration>
3.4.4 hdfs-site.xml配置修改
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 与前面core-site.xml配置的匹配-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--给两个namenode起别名nn1,nn2这个名字不固定,可以自己取 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>ds1:8020</value>
</property>
<!-- nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>ds1:50070</value>
</property>
<!--nn2的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>ds2:8020</value>
</property>
<!--nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>ds2:50070</value>
</property>
<!--设置共享edits文件夹:告诉集群哪些机器要启动journalNode -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ds1:8485;ds2:8485;ds3:8485/mycluster</value>
</property>
<!-- journalnode的edits文件存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/bigdata/hadoop/journal</value>
</property>
<!--该配置开启高可用自动切换功能 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置切换的实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value> org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--生成的秘钥所存储的目录 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
<!-- 配置namenode存储元数据的目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///bigdata/hadoop/namenode </value>
</property>
<!-- 配置datanode存储数据块的目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///bigdata/hadoop/datanode </value>
</property>
<!--指定block副本数为3,该数字不能超过主机数。 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置hdfs的操作权限,设置为false表示任何用户都可以在hdfs上操作并且可以使用插件 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
3.4.5 mapred-site.xml配置修改
vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/hadoop-3.2.4/share/hadoop/common/*,
/opt/hadoop-3.2.4/share/hadoop/common/lib/*,
/opt/hadoop-3.2.4/share/hadoop/hdfs/*,
/opt/hadoop-3.2.4/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.2.4/share/hadoop/mapreduce/*,
/opt/hadoop-3.2.4/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.2.4/share/hadoop/yarn/*,
/opt/hadoop-3.2.4/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
3.4.6 yarn-site.xml配置修改
vim yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<!--配置启用fair调度器-->
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- yarn ha configuration-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 定义集群名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!-- 定义本机在在高可用集群中的id 要与 yarn.resourcemanager.ha.rm-ids 定义的值对应,如果不作为resource manager 则删除这项配置。-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 定义高可用集群中的 id 列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 定义高可用RM集群具体是哪些机器 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ds1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ds2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ds1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>ds2:8088</value>
</property>
<property>
<name>hadoop.zk.address</name>
<value>ds1:2181,ds2:2181,ds3:2181</value>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!--设置该节点上yarn可使用的内存,默认为8G,如果节点内存资源不足8G,要减少这个值,yarn不会智能的去检测内存资源,一般这个设置yarn的可用内存资源-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>204800</value>
</property>
<!--单个任务最小申请物理内存量,默认1024MB,根据自己的业务设定-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>8192</value>
</property>
<!--单个任务最大申请物理内存量,默认为8291MB-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>614400</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>8192</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx6553m</value>
</property>
<!--表示该节点服务器上yarn可以使用的虚拟CPU个数,默认是8-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
<!--单个任务最大可申请的虚拟核数,默认为4,如果申请资源时,超过这个配置,会抛出InvalidResourceRequestException-->
<property>