Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库
Posted 孤寒者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库相关的知识,希望对你有一定的参考价值。
目录:
1 数据持久化存储,写入mysql数据库
①定义结构化字段:
- (items.py文件的编写):
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NovelItem(scrapy.Item):
'''匹配每个书籍URL并解析获取一些信息创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field()
book_name = scrapy.Field()
author = scrapy.Field()
status = scrapy.Field()
book_nums = scrapy.Field()
description = scrapy.Field()
c_time = scrapy.Field()
book_url = scrapy.Field()
catalog_url = scrapy.Field()
class ChapterItem(scrapy.Item):
'''从每个小说章节列表页解析当前小说章节列表一些信息所创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
chapter_list = scrapy.Field()
class ContentItem(scrapy.Item):
'''从小说具体章节里解析当前小说的当前章节的具体内容所创建的字段'''
# define the fields for your item here like:
# name = scrapy.Field()
content = scrapy.Field()
chapter_url = scrapy.Field()
②重新编写爬虫文件:
- (将解析的数据对应到字段里,并将其yield返回给管道文件pipelines.py)
# -*- coding: utf-8 -*-
import datetime
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import NovelItem,ChapterItem,ContentItem
class Bh3Spider(CrawlSpider):
name = 'zh'
allowed_domains = ['book.zongheng.com']
start_urls = ['https://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html']
rules = (
# Rule定义爬取规则: 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则
# 源码:Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)
# 1.LinkExractor是scrapy框架定义的一个类,它定义如何从每个已爬网页面中提取url链接,并将这些url作为新的请求发送给引擎
# 引擎经过一系列操作后将response给到callback所指的回调函数。
# allow=r'Items/'的意思是提取链接的正则表达式 【相当于findall(r'Items/',response.text)】
# 2.callback='parse_item'是指定回调函数。
# 3.follow=True的作用:LinkExtractor提取到的url所生成的response在给callback的同时,还要交给rules匹配所有的Rule规则(有几条遵循几条)
# 拿到了书籍的url 回调函数 process_links用于处理LinkExtractor匹配到的链接的回调函数
# 匹配每个书籍的url
Rule(LinkExtractor(allow=r'https://book.zongheng.com/book/\\d+.html',
restrict_xpaths=("//div[@class='bookname']")), callback='parse_book', follow=True,
process_links="process_booklink"),
# 匹配章节目录的url
Rule(LinkExtractor(allow=r'https://book.zongheng.com/showchapter/\\d+.html',
restrict_xpaths=('//div[@class="fr link-group"]')), callback='parse_catalog', follow=True),
# 章节目录的url生成的response,再来进行具体章节内容的url的匹配 之后此url会形成response,交给callback函数
Rule(LinkExtractor(allow=r'https://book.zongheng.com/chapter/\\d+/\\d+.html',
restrict_xpaths=('//ul[@class="chapter-list clearfix"]')), callback='get_content',
follow=False, process_links="process_chapterlink"),
# restrict_xpaths是LinkExtractor里的一个参数。作用:过滤(对前面allow匹配到的url进行区域限制),只允许此参数匹配的allow允许的url通过此规则!!!
)
def process_booklink(self, links):
for index, link in enumerate(links):
# 限制一本书
if index == 0:
print("限制一本书:", link.url)
yield link
else:
return
def process_chapterlink(self, links):
for index,link in enumerate(links):
#限制21章内容
if index<=20:
print("限制20章内容:",link.url)
yield link
else:
return
def parse_book(self, response):
print("解析book_url")
# 字数:
book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]
# 书名:
book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()
category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]
author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]
status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]
description = "".join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').extract())
c_time = datetime.datetime.now()
book_url = response.url
catalog_url = response.css("a").re("https://book.zongheng.com/showchapter/\\d+.html")[0]
item=NovelItem()
item["category"]=category
item["book_name"]=book_name
item["author"]=author
item["status"]=status
item["book_nums"]=book_nums
item["description"]=description
item["c_time"]=c_time
item["book_url"]=book_url
item["catalog_url"]=catalog_url
yield item
def parse_catalog(self, response):
print("解析章节目录", response.url) # response.url就是数据的来源的url
# 注意:章节和章节的url要一一对应
a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')
chapter_list = []
for index, a in enumerate(a_tags):
title = a.xpath("./text()").extract()[0]
chapter_url = a.xpath("./@href").extract()[0]
ordernum = index + 1
c_time = datetime.datetime.now()
catalog_url = response.url
chapter_list.append([title, ordernum, c_time, chapter_url, catalog_url])
item=ChapterItem()
item["chapter_list"]=chapter_list
yield item
def get_content(self, response):
content = "".join(response.xpath('//div[@class="content"]/p/text()').extract())
chapter_url = response.url
item=ContentItem()
item["content"]=content
item["chapter_url"]=chapter_url
yield item
③编写管道文件:
- (pipelines.py文件)
- 数据存储到MySql数据库分三步走:
①存储小说信息;
②存储除了章节具体内容以外的章节信息(因为:首先章节信息是有序的;其次章节具体内容是在一个新的页面里,需要发起一次新的请求);
③更新章节具体内容信息到第二步的表中。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
import logging
from .items import NovelItem,ChapterItem,ContentItem
logger=logging.getLogger(__name__) #生成以当前文件名命名的logger对象。 用日志记录报错。
class ZonghengPipeline(object):
def open_spider(self,spider):
# 连接数据库
data_config = spider.settings["DATABASE_CONFIG"]
if data_config["type"] == "mysql":
self.conn = pymysql.connect(**data_config["config"])
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 写入数据库
if isinstance(item,NovelItem):
#写入书籍信息
sql="select id from novel where book_name=%s and author=%s"
self.cursor.execute(sql,(item["book_name"],item["author"]))
if not self.cursor.fetchone(): #.fetchone()获取上一个查询结果集。在python中如果没有则为None
try:
#如果没有获得一个id,小说不存在才进行写入操作
sql="insert into novel(category,book_name,author,status,book_nums,description,c_time,book_url,catalog_url)"\\
"values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(
item["category"],
item["book_name"],
item["author"],
item["status"],
item["book_nums"],
item["description"],
item["c_time"],
item["book_url"],
item["catalog_url"],
))
self.conn.commit()
except Exception as e: #捕获异常并日志显示
self.conn.rollback()
logger.warning("小说信息错误!url=%s %s")%(item["book_url"],e)
return item
elif isinstance(item,ChapterItem):
#写入章节信息
try:
sql="insert into chapter (title,ordernum,c_time,chapter_url,catalog_url)"\\
"values(%s,%s,%s,%s,%s)"
#注意:此处item的形式是! item["chapter_list"]====[(title,ordernum,c_time,chapter_url,catalog_url)]
chapter_list=item["chapter_list"]
self.cursor.executemany(sql,chapter_list) #.executemany()的作用:一次操作,写入多个元组的数据。形如:.executemany(sql,[(),()])
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章节信息错误!%s"%e)
return item
elif isinstance(item,ContentItem):
try:
sql="update chapter set content=%s where chapter_url=%s"
content=item["content"]
chapter_url=item["chapter_url"]
self.cursor.execute(sql,(content,chapter_url))
self.conn.commit()
except Exception as e:
self.conn.rollback()
logger.warning("章节内容错误!url=%s %s") % (item["chapter_url"], e)
return item
def close_spider(self,spider):
# 关闭数据库
self.cursor.close()
self.conn.close()
④辅助配置(修改settings.py文件):
第一个:关闭robots协议;
第二个:开启延迟;
第三个:加入头文件;
第四个:开启管道:
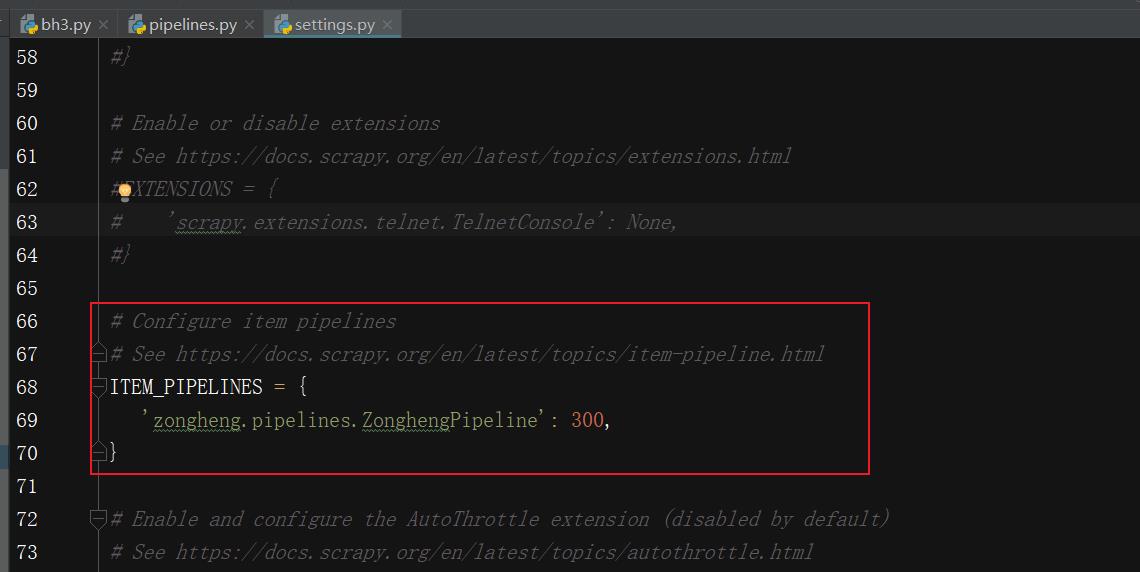
第五个:配置连接Mysql数据库的参数:
DATABASE_CONFIG=
"type":"mysql",
"config":
"host":"localhost",
"port":3306,
"user":"root",
"password":"123456",
"db":"zongheng",
"charset":"utf8"
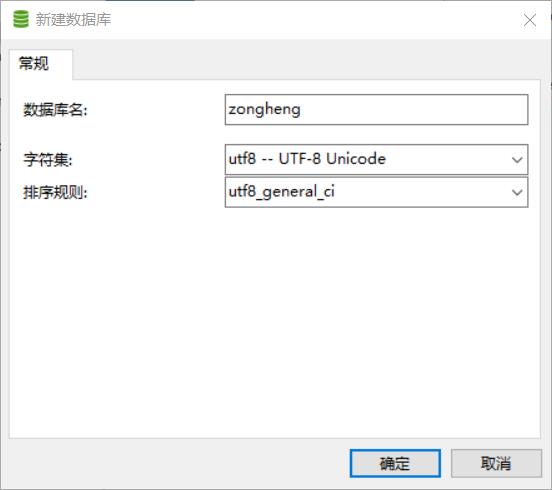
⑤navicat创库建表:
(1)创库:
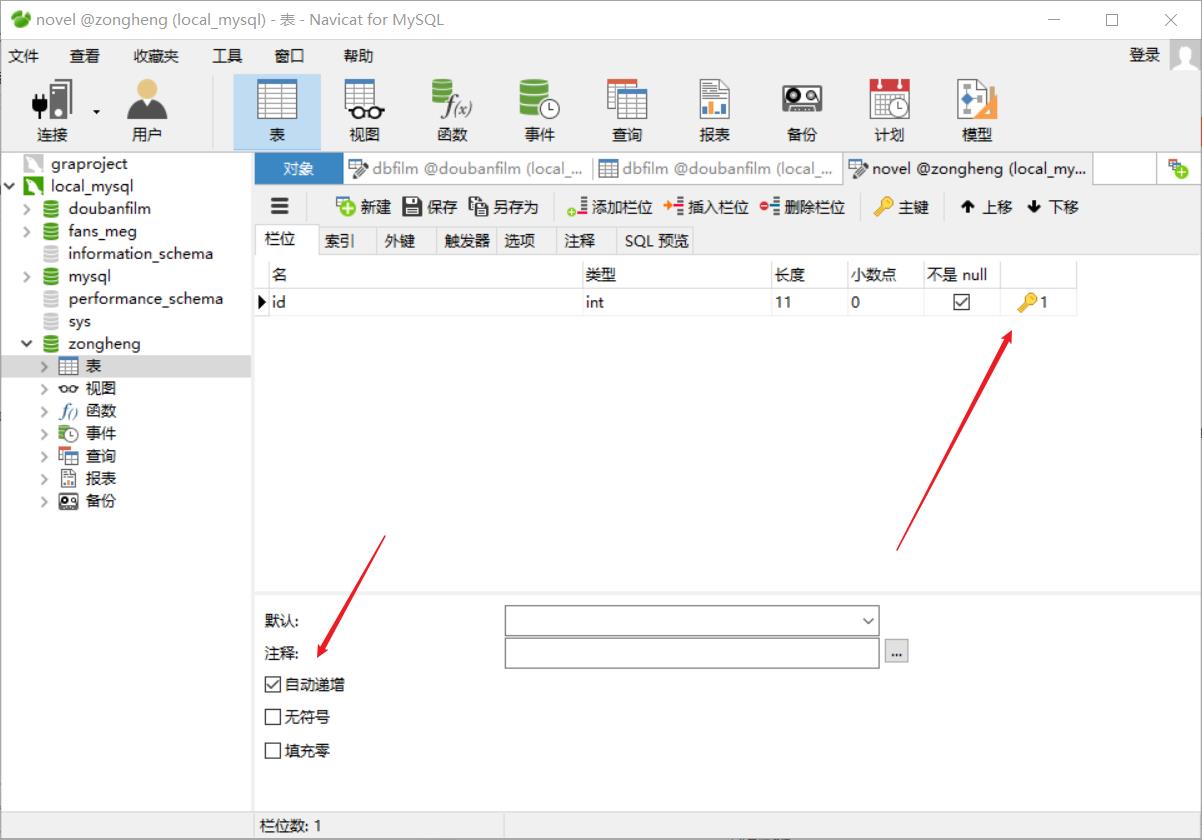
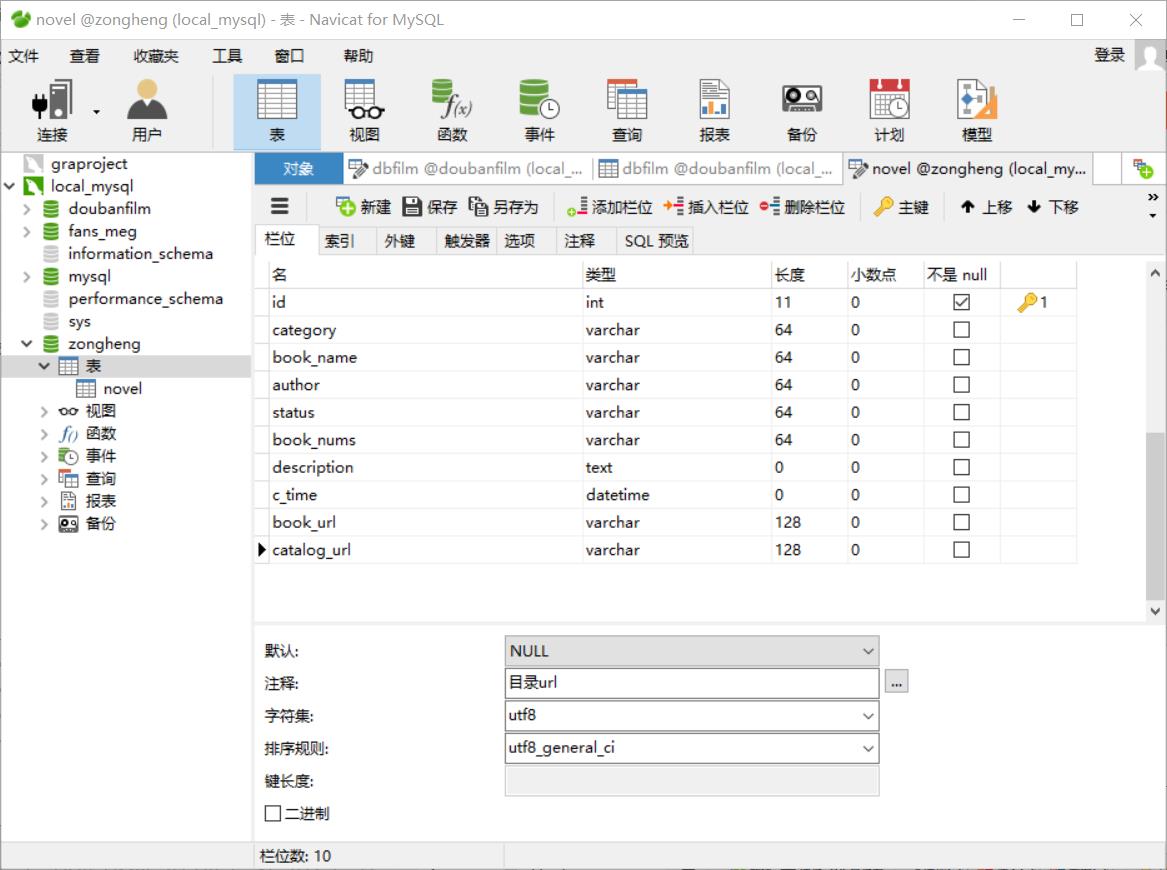
(2)建表:(注意:总共需要建两张表!)
-
存储小说基本信息的表,表名为novel
-
存储小说具体章节内容的表,表名为chapter:
- 注意id不要忘记设自增长了!
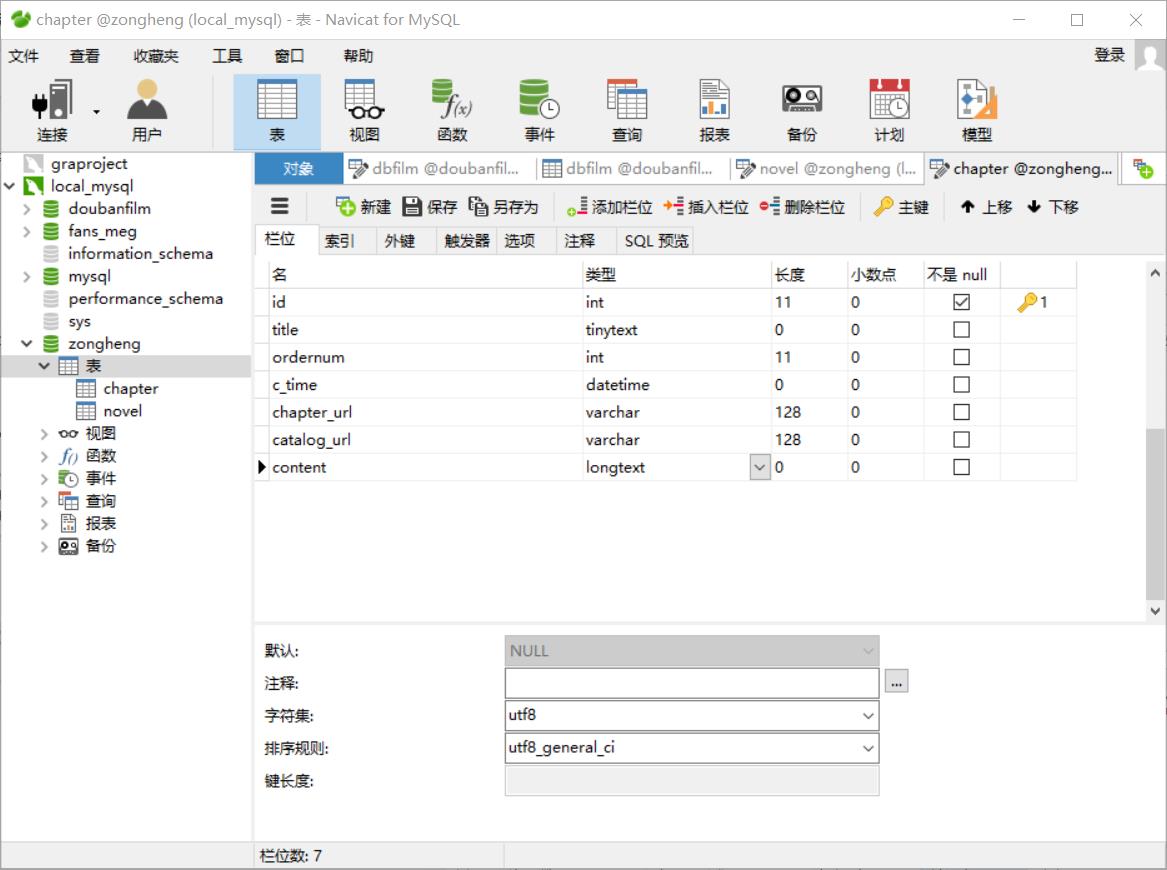
⑥ 效果如下:

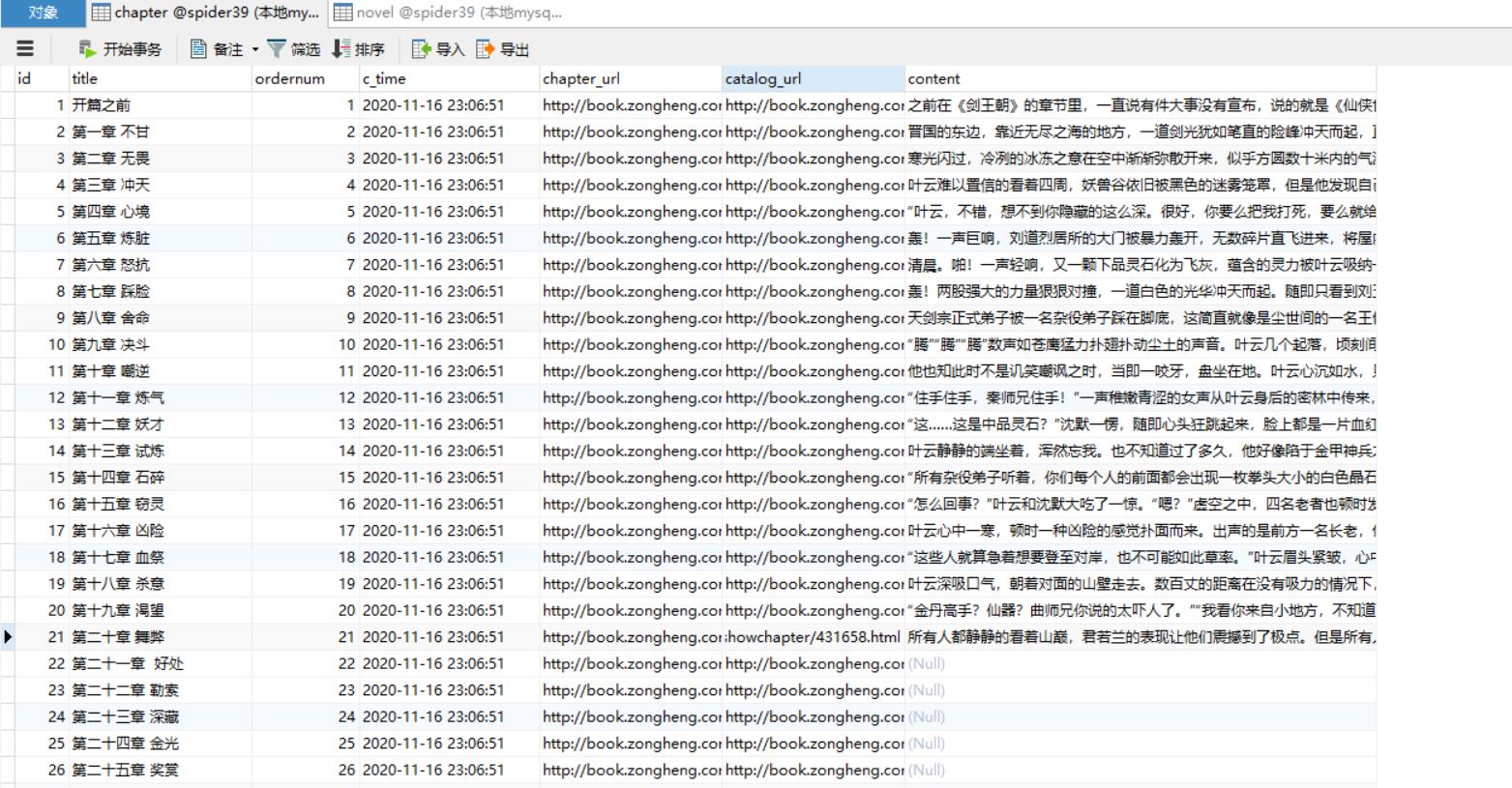
- 拓展操作:
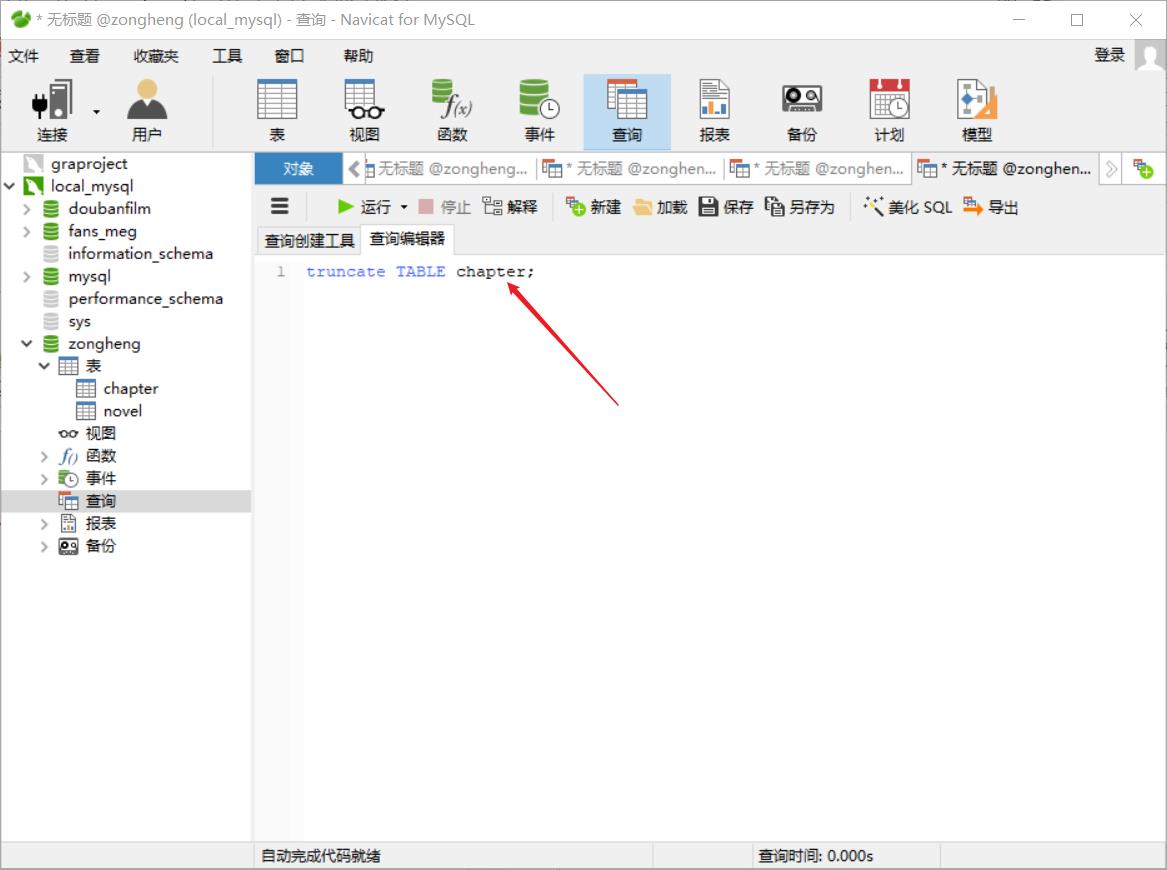
如果来回调试有问题的话,需要删除表中所有数据重新爬取,直接使用navicate删除表中所有数据(即delete操作),那么id自增长就不会从1开始了。
这该咋办呢?
以上是关于Python爬虫之Scrapy框架系列(13)——实战ZH小说爬取数据入MySql数据库的主要内容,如果未能解决你的问题,请参考以下文章