ElasticSearch+Kibana+Filebeat 采集日志内的json数据
Posted 之举
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch+Kibana+Filebeat 采集日志内的json数据相关的知识,希望对你有一定的参考价值。
方式有很多,以下是我学习中自己写的。
要被采集的日志:
"time":"2023-02-07T10:11:20+08:00","type":"info","msg":"\\"business\\":\\"elk\\",\\"module\\":\\"demo\\",\\"action\\":\\"test\\",\\"level\\":\\"info\\",\\"date\\":\\"2023-02-07 10:11:20\\",\\"second\\":\\"0.899408\\",\\"data\\":\\"id\\":233,\\"name\\":\\"张三\\",\\"gender\\":24,\\"phone\\":13511112222"
[2023-02-07T10:11:39+08:00][info] "business":"elk","module":"demo","action":"test","level":"info","date":"2023-02-07 10:11:39","second":"0.493702","data":"id":233,"name":"张三","gender":24,"phone":13511112222
两条不同格式的日志是为了测试不同格式的采集方式
第一条是纯json格式日志
第二条是Thinkphp6的默认日志格式,符合大多数的日志格式在ElasticSearch创建pipeline(管道):
在“Kibana->Stack Management->采集管道->创建管道”
或者
在“Kibana->开发工具->控制台”运行以下代码
PUT _ingest/pipeline/elk-test-pipeline
"description" : "解析混合日志",
"processors" :
[
"grok":
"field": "message",
"description": "正常日志格式解析",
# grok表达式,注意空格
"patterns": ["\\\\[%TIMESTAMP_ISO8601:time\\\\]\\\\[%LOGLEVEL:type\\\\] %GREEDYDATA:msg"],
# 出错时增加该字段,方便筛查是否出错了
"on_failure": [
"append":
"field": "log_grok_error",
"value": ["正常日志格式解析失败"]
]
,
"json":
"field": "message",
"add_to_root": true,
"description": "json日志格式解析",
# 出错时增加该字段,方便筛查是否出错了
"on_failure": [
"append":
"field": "log_json_error",
"value": ["json日志格式解析失败"]
]
,
"json":
"field": "msg",
"add_to_root": true,
"description": "解析日志内的json",
# 出错时增加该字段,方便筛查是否出错了
"on_failure": [
"append":
"field": "data_json_error",
"value": ["json数据解析失败"]
]
]
# processors (处理器)
# 更多处理器类型:
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/json-processor.htmlFilebeat指定output.elasticsearch的pipeline(管道)
filebeat配置文件filebeat.yml
filebeat.inputs:
# type: log在elasticsearch7.16.0中已弃用
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /www/wwwroot/elk_demo/runtime/log/*.log # 日志路径
# output.elasticsearch指定了pipeline时,index勿填,除非在elasticsearch设置该index的默认pipeline
#index: "elk_demo_test"
# 解析json格式的日志。由于日志是混合的格式,所以注释了,否则pipeline的处理器只需要json一个就够了
#parsers:
#- ndjson:
# target: ""
# add_error_key: true
processors:
# 过滤字段
- drop_fields:
fields: ["ecs", "agent", "host"]
output.elasticsearch:
hosts: ["192.168.0.111:9200"]
pipeline: "elk_test_pipeline" # 刚刚在elasticsearch创建的启动Filebeat后,在要被采集的文件写入上面的2条日志,然后在Kiban创建视图数据就可以看到了
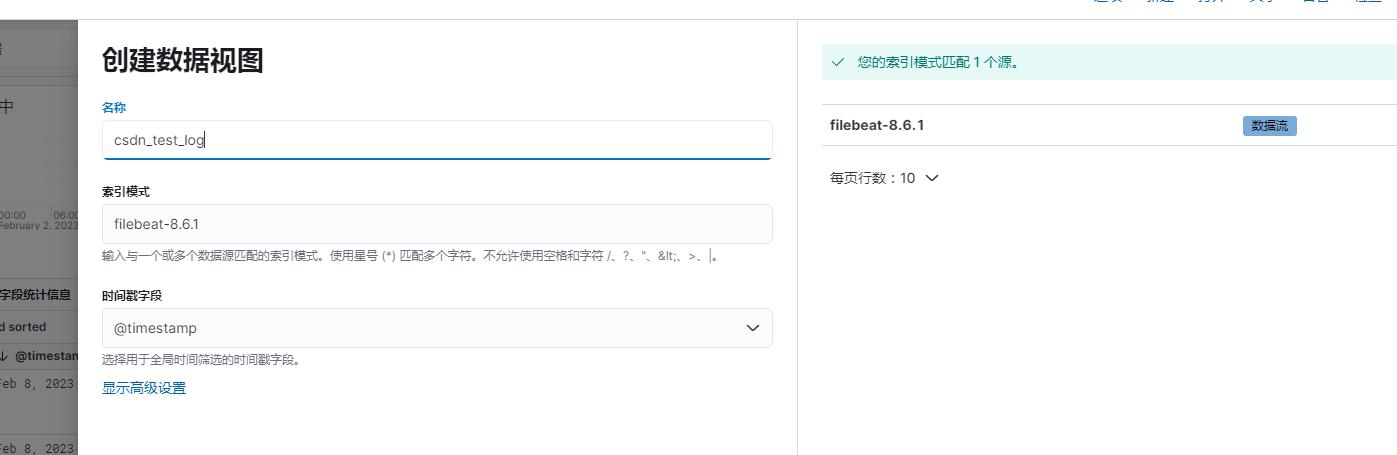
采集到日志后,就会显示出右边的filebeat-8.6.1了,接下来创建看看
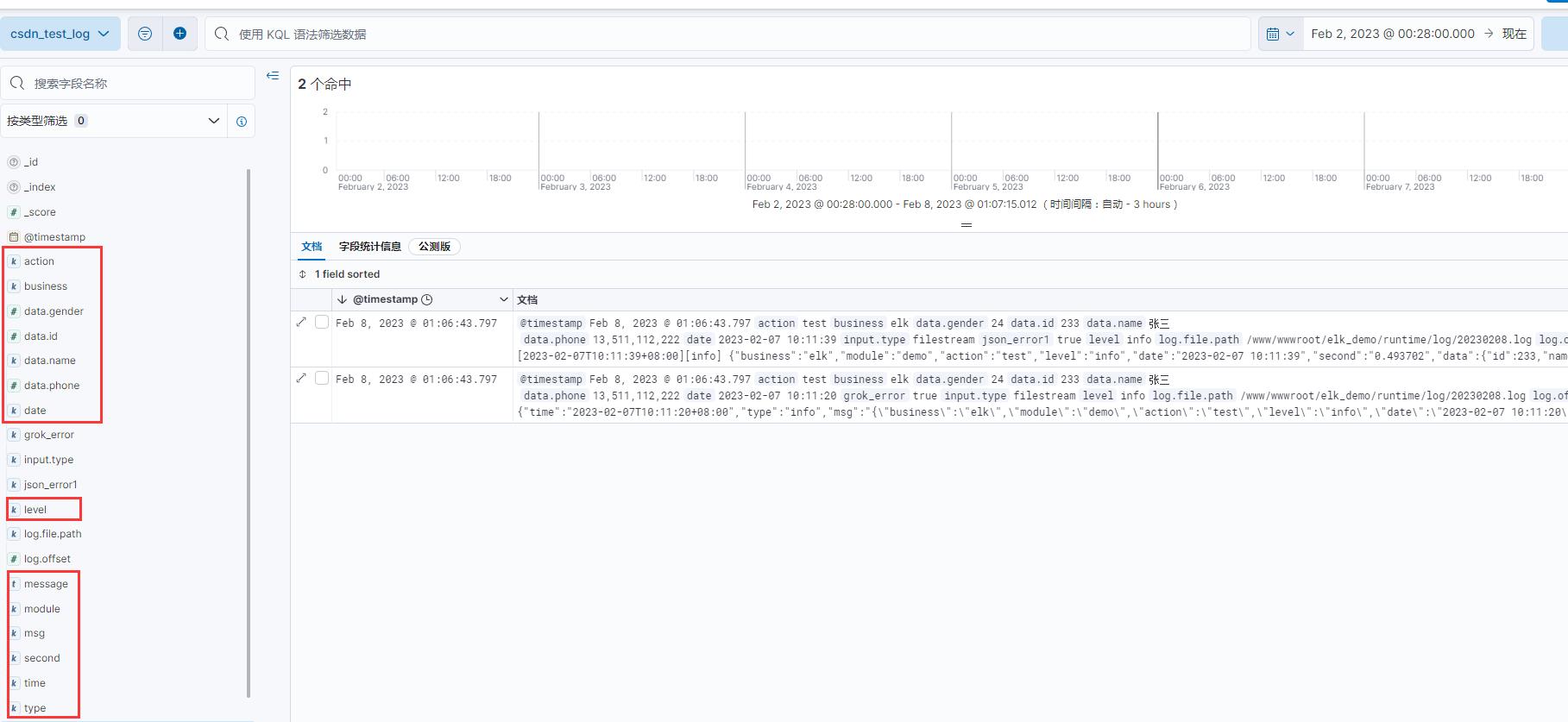
两条日志都采集并解析成功了,右边的字段也都是日志里的json数据。
另外一种自定义索引的方式:
第一步照旧,第二步的filebeat.yml改为:
filebeat.inputs:
# type: log在elasticsearch7.16.0中已弃用
- type: filestream
id: my-filestream-id
enabled: true
paths:
- /www/wwwroot/elk_demo/runtime/log/*.log # 日志路径
# 索引名称
index: "elk_demo_test"
processors:
# 过滤字段
- drop_fields:
fields: ["ecs", "agent", "host"]
output.elasticsearch:
hosts: ["192.168.0.111:9200"]
# pipeline在ElasticSearch中设置接下来启动Filebeat,然后写入一条日志,采集到日志之后,就会出现该索引
"Kibana->Stack Management->索引管理"
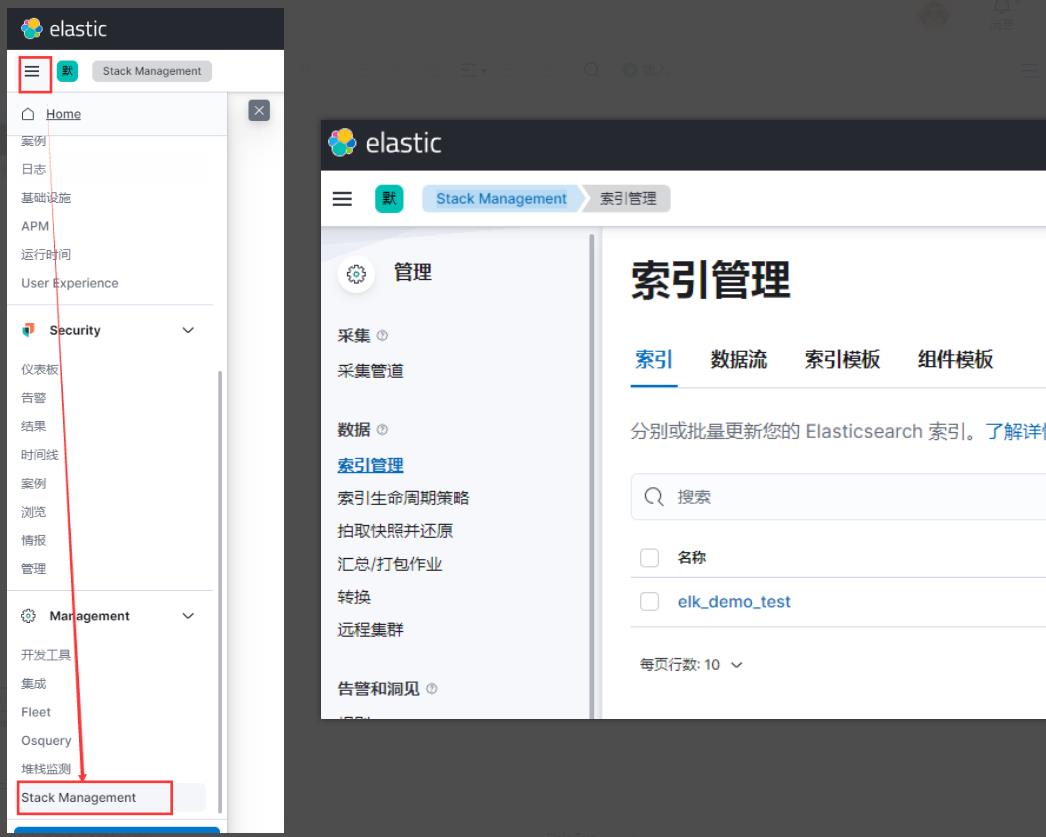
然后再给该索引设置pipeline
在“Kibana->开发工具->控制台”运行以下代码
PUT elk_demo_test/_settings
"index":
"default_pipeline": "elk-test-pipeline"
# 这样就给elk_demo_test索引设置了pipeline,Filebeat采集时就都会使用该pipeline
创建视图数据
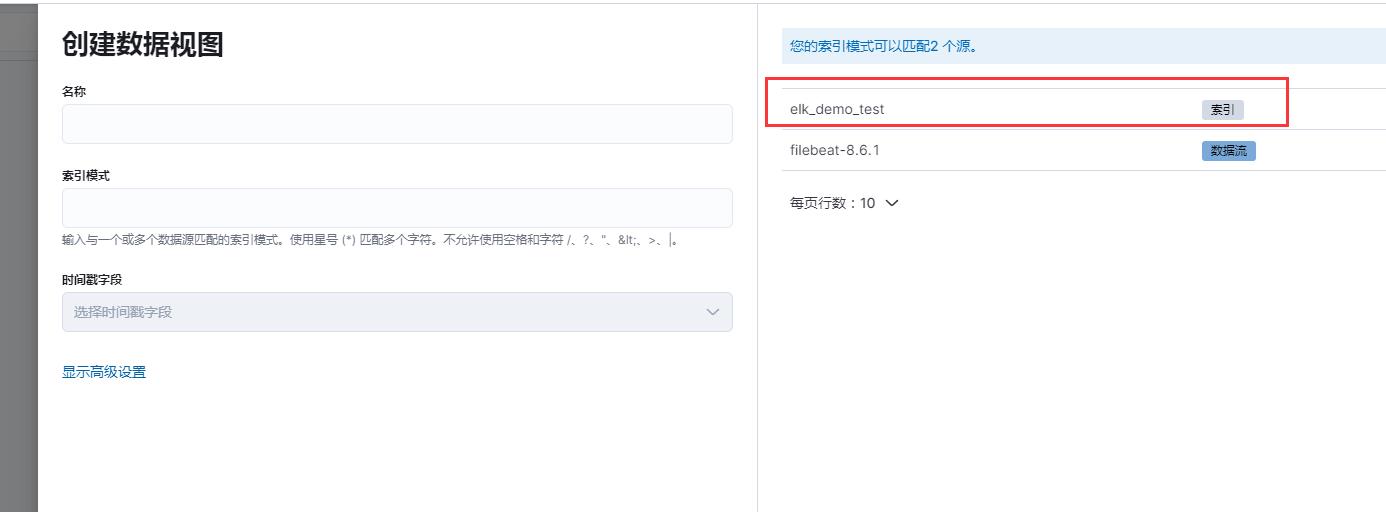
索引模式填入索引elk_demo_test,名称csdn_test_log2
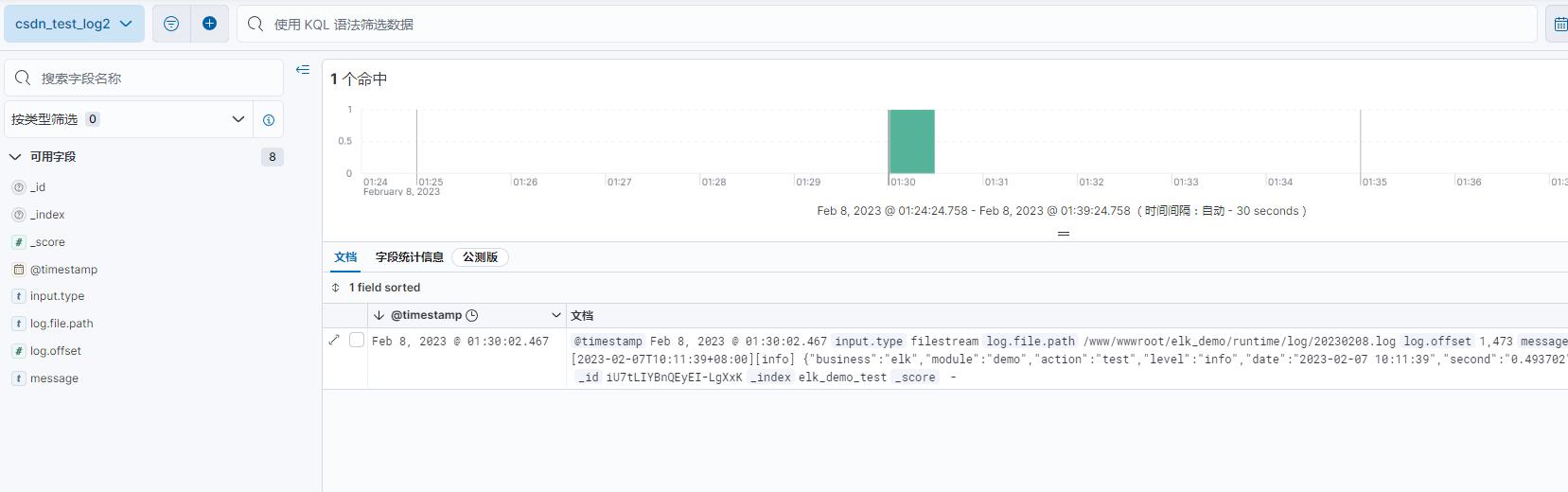
创建好了之后有一条日志,是前面为了看到该索引写入的一条,该数据是没有经过pipeline的。
所以现在再写入文章开头的那2条示例日志到要被采集的文件里,然后在看看数据视图
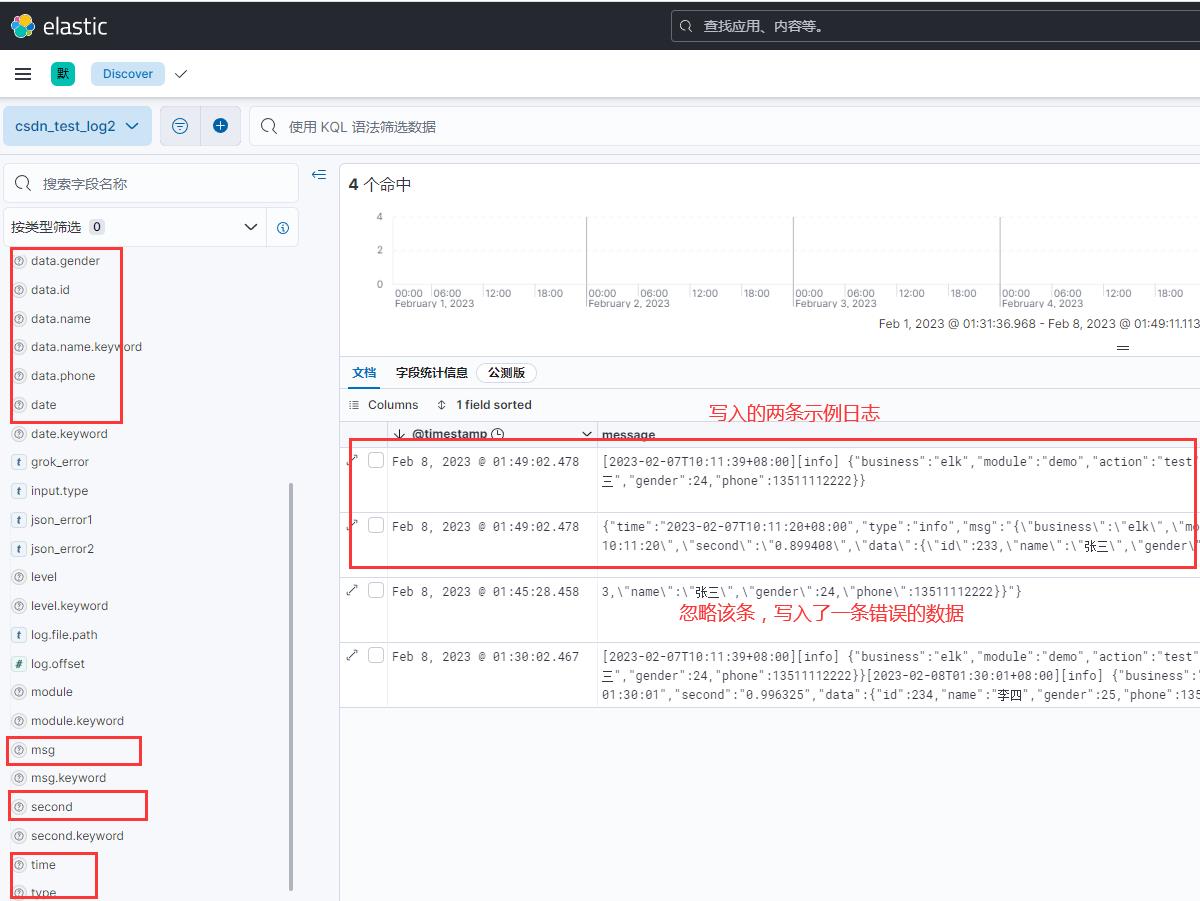
都采集并解析成功了。
如有错误,欢迎大家的纠正
官方文档:
pipeline(管道) https://www.elastic.co/guide/en/elasticsearch/reference/8.6/ingest.html
以上是关于ElasticSearch+Kibana+Filebeat 采集日志内的json数据的主要内容,如果未能解决你的问题,请参考以下文章