Elasticsearch:使用 distance feature 查询提高分数
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:使用 distance feature 查询提高分数相关的知识,希望对你有一定的参考价值。
Elasticsearch 有一些专门用于提供专门功能的高级查询。 例如,使用 distance_feature 查询提高在指定位置提供冷饮的咖啡馆的分数 —— 本文的主题。
在搜索经典文学时,我们可能想添加一个子句来查找 1813 年出版的书籍。随着返回所有文学经典书籍,我们可以期望找到傲慢与偏见(简·奥斯汀的经典),但是想法是把傲慢与偏见排在榜首,因为它是 1813 年印刷的。排在榜首无非是提高了基于特定子句的查询结果的相关性得分; 在这种情况下,我们特别希望 1813 年出版的书籍具有更高的重要性。
通过使用 distance_feature 查询,可以在 Elasticsearch 中使用此类功能。 查询获取结果,如果它们更接近起始日期(在本例中为 1813),则用较高的相关性分数标记其中的一些结果。
distance_feature 查询也为位置提供类似的支持。 如果我们愿意,我们可以突出显示靠近特定地址的位置,并将其提升到列表的顶部。 假设我们要查找所有供应炸鱼和薯条的餐厅,但排在首位的餐厅应该位于伦敦桥附近的 Borough Market。
我们可以对此类用例使用 distance_feature 查询,该查询用于查找更接近原始位置或日期的结果。 日期和位置分别是声明为日期(我们也可以将其声明为 date_nanos)和 geo_point 数据类型的字段。 更接近给定日期或给定位置的结果在相关性得分中被评为更高。 让我们看几个例子来详细理解这个概念。
使用地理位置提高附近大学的分数
在寻找英国的大学时,我们希望优先选择离某个地方较近的大学; 例如,Knightsbridge 10 公里半径范围内的所有大学。 我们需要提高这些匹配的比分。
为了尝试这种情况,让我们为 universities 索引创建一个映射,并将位置声明为 geo_point 字段。 以下列表为四所大学创建映射和索引:两所在伦敦,两所在该国其他地方。
# Create a mapping of universities index with bare minimum fields
PUT universities
"mappings":
"properties":
"name":
"type": "text"
,
"location":
"type": "geo_point"
我们使用如下的命令来写入一些文档:
POST _bulk
"index" : "_index" : "universities", "_id" : "1"
"name" : "London School of Economics (LSE)", "location":[0.1165, 51.5144]
"index" : "_index" : "universities", "_id" : "2"
"name" : "Imperial College London", "location":[0.1749, 51.4988]
"index" : "_index" : "universities", "_id" : "3"
"name" : "University of Oxford", "location":[1.2544, 51.7548]
"index" : "_index" : "universities", "_id" : "4"
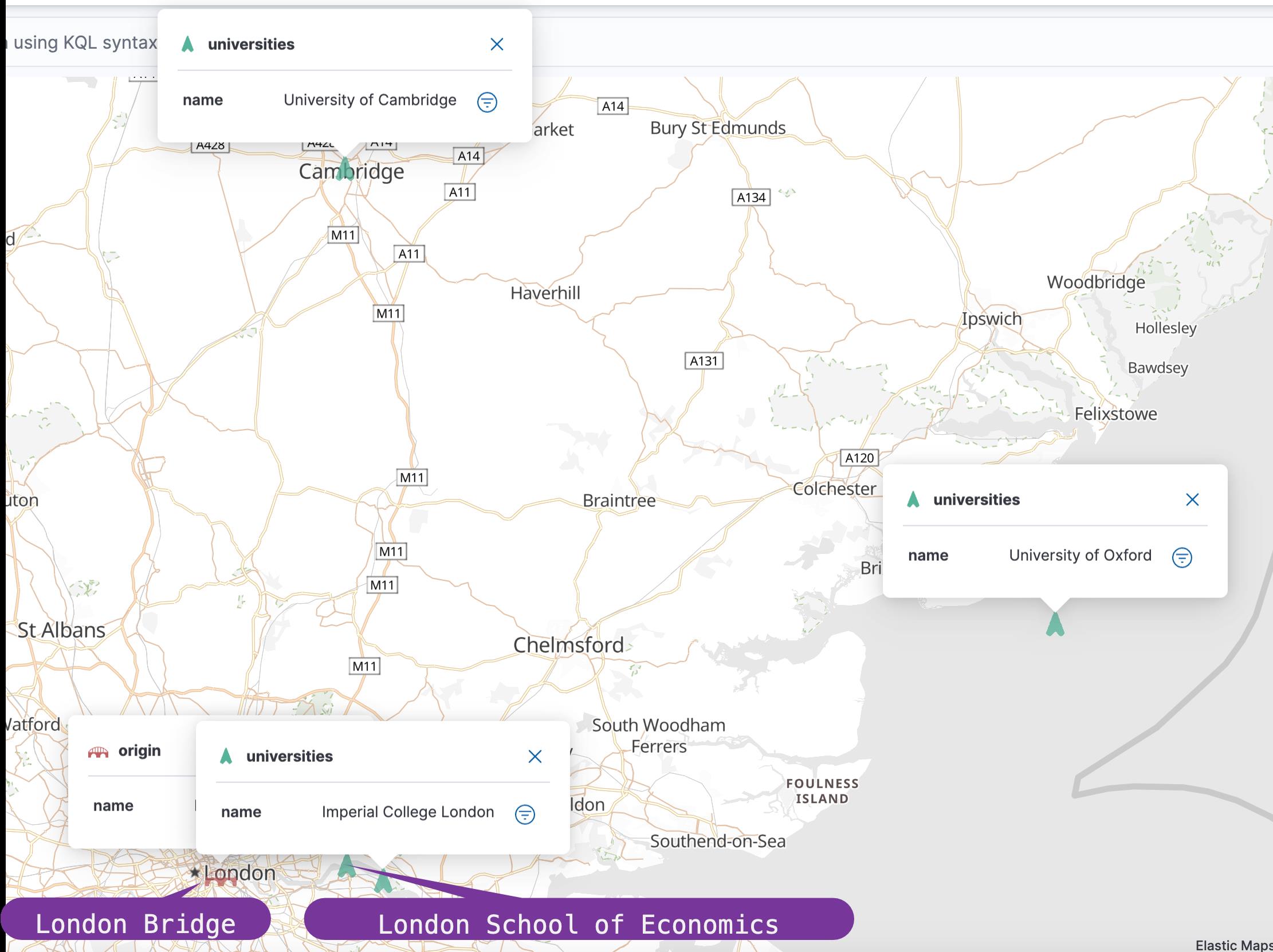
"name" : "University of Cambridge", "location":[0.1132, 52.2054]现在已经准备好索引和数据,让我们获取大学,提高相关性分数,使靠近伦敦桥(London Bridge)的大学位于列表的顶部。 请参见如下图中的伦敦地图,其中包含这些大学在上述地点附近的大致距离。 为此,我们使用 distance_feature 查询,它与查询条件匹配,但会根据查询中提供的附加参数提高相关性分数。

我们想搜索位于伦敦大桥位置 [-0.0860, 51.5048] 附近的所有大学。
首先,让我们编写查询,然后深入了解细节。 以下清单在 bool 查询中使用 distance_feature 查询来获取大学。
GET universities/_search?filter_path=**.hits
"query":
"distance_feature":
"field": "location",
"origin": [
-0.086,
51.5048
],
"pivot": "10 km"
上述命令返回结果:
"hits":
"hits": [
"_index": "universities",
"_id": "1",
"_score": 0.4157174,
"_source":
"name": "London School of Economics (LSE)",
"location": [
0.1165,
51.5144
]
,
"_index": "universities",
"_id": "2",
"_score": 0.3562365,
"_source":
"name": "Imperial College London",
"location": [
0.1749,
51.4988
]
,
"_index": "universities",
"_id": "4",
"_score": 0.11223929,
"_source":
"name": "University of Cambridge",
"location": [
0.1132,
52.2054
]
,
"_index": "universities",
"_id": "3",
"_score": 0.09380584,
"_source":
"name": "University of Oxford",
"location": [
1.2544,
51.7548
]
]
查询在执行时搜索所有返回我们四所大学。 此外,如果这些大学中的任何一所大学位于原点周围 10 公里附近(-0.0860,51.5048 代表英国的 London Bridge),它们的得分就会高于其他大学。
让我们暂停一下,看看 distance_feature 查询是由什么组成的。 distance_feature 查询需要这些属性:
- field - 文档中的 geo_point 字段
- origin — 测量距离的焦点(经度和纬度)
- pivot - 距焦点的距离
在上面的查询中,伦敦经济学院(LSE)大学比帝国理工学院更接近伦敦桥; 因此,LSE 以更高的分数返回顶部。
我们也可以使用带有日期的 distance_feature 查询,下一节的主题。
使用日期提高分数
在上一节中,distance_feature 查询帮助我们搜索大学,提高了离特定地理位置较近的大学的分数。 distance_feature 查询也可以满足类似的要求:如果结果围绕日期旋转,则提高结果的分数。
假设我们要搜索所有 iPhone 的发布日期,将 2020 年 12 月 1 日前后 30 天内发布的 iPhone 列在列表的首位(没有特别的原因,除了尝试这个概念)。 我们可以编写与上一节中类似的查询,但字段属性将基于日期。 让我们首先创建一个 iphones 映射并将一些 iPhone 索引到我们的索引中。 下面清单中的查询就是这样做的。
PUT iphones
"mappings":
"properties":
"name":
"type": "text"
,
"release_date":
"type": "date",
"format": "dd-MM-yyyy"
我们使用如下的 bulk 命令一次写入四个文档:
POST _bulk
"index" : "_index" : "iphones", "_id" : "1"
"name" : "iPhone", "release_date":"29-06-2007"
"index" : "_index" : "iphones", "_id" : "2"
"name" : "iPhone 12", "release_date":"23-10-2020"
"index" : "_index" : "iphones", "_id" : "3"
"name" : "iPhone 13", "release_date":"24-09-2021"
"index" : "_index" : "iphones", "_id" : "4"
"name" : "iPhone 12 Mini", "release_date":"13-11-2020"我们可以在 Kibana 中进行时域展示:
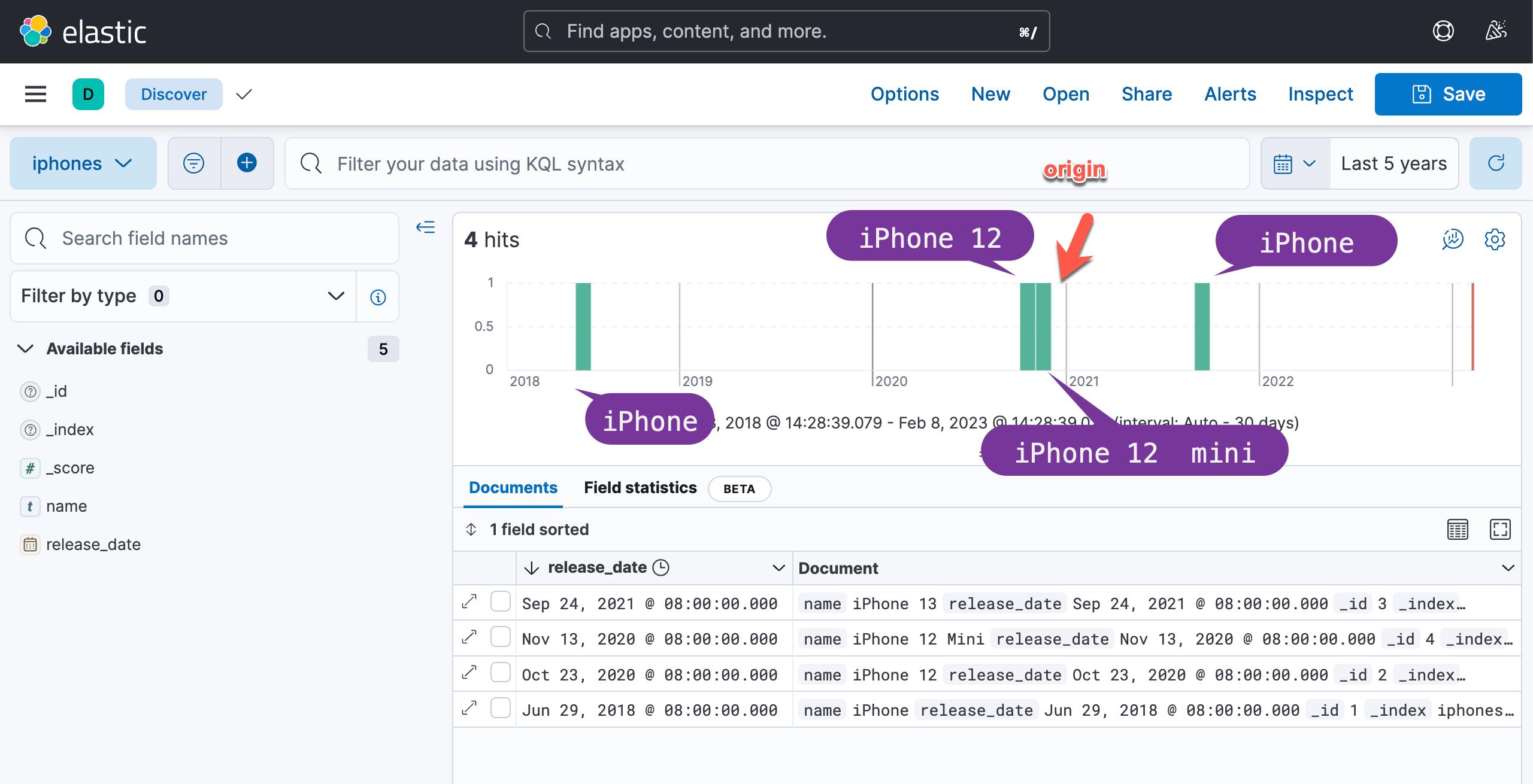
现在我们有了一个包含一堆 iphones 的索引,让我们开发一个查询来满足我们的要求:我们将获取所有 iPhone,但优先考虑在 2020 年 12 月 1 日前后 30 天发布的 iPhone。下一个清单中的查询做这个。
GET iphones/_search?filter_path=**.hits
"query":
"bool":
"must": [
"match":
"name": "12"
],
"should": [
"distance_feature":
"field": "release_date",
"origin": "01-12-2020",
"pivot": "30 d"
]
上述搜索的结果为:
"hits":
"hits": [
"_index": "iphones",
"_id": "4",
"_score": 1.1876879,
"_source":
"name": "iPhone 12 Mini",
"release_date": "13-11-2020"
,
"_index": "iphones",
"_id": "2",
"_score": 1.1217185,
"_source":
"name": "iPhone 12",
"release_date": "23-10-2020"
]
在上面的查询中,我们将 distance_feature 包装在一个带有 must 和 should 子句的 bool 查询中(我们在之前的文章中了解了 bool 查询)。 must 子句搜索名称字段中包含 12 的所有文档,并从我们的索引中返回 iPhone 12 和 iPhone 12 mini 文档。 我们的要求是优先考虑 12 月 1 日前后 30 天发布的手机(因此,可能是 2020 年 11 月至 12 月之间发布的所有手机)。
为了满足这个要求,should 子句使用 distance_feature 查询来提高最接近所提到的旋转日期的匹配文档的分数。 该查询从 iphones 索引中获取所有文档。 在 2020 年 12 月 1 日(原点)之前或之后 30 天发布的任何 iPhone 都会返回具有更高相关性分数的产品。
请记住,should 子句返回的所有匹配项都将添加到总分中。 因此,你应该会看到 iPhone 12 Mini 位居榜首,因为这款 iPhone 的发布日期(“release_date”:“13–11–2020”)更接近 pivot 日期(“origin”:“01–12–2020”) 30天)。
如你所见,iPhone 12 Mini 的得分高于 iPhone 12,因为它仅在我们的基准日期前 17 天发布,而 iPhone 12 的发布时间稍早于此(将近 5 周前)。
以上是关于Elasticsearch:使用 distance feature 查询提高分数的主要内容,如果未能解决你的问题,请参考以下文章