终于有人把分布式机器学习讲明白了
Posted 大数据v
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于有人把分布式机器学习讲明白了相关的知识,希望对你有一定的参考价值。
导读:分布式机器学习与联邦学习。
作者:薄列峰 黄恒 顾松庠 陈彦卿 等
来源:大数据DT(ID:hzdashuju)
分布式机器学习也称分布式学习,是指利用多个计算节点(也称工作节点,Worker)进行机器学习或者深度学习的算法和系统,旨在提高性能、保护隐私,并可扩展至更大规模的训练数据和更大的模型。
联邦学习可以看作分布式学习的一种特殊类型,它可以进一步解决分布式机器学习遇到的一些困难,从而构建面向隐私保护的人工智能应用和产品。
01 分布式机器学习的发展历史
近年来,新技术的快速发展导致数据量空前增长。机器学习算法正越来越多地用于分析数据集和建立决策系统。而由于问题的复杂性,例如控制自动驾驶汽车、识别语音或预测消费者行为(参考Khandani等人2010年发表的文章),算法解决方案并不可行。
在某些情况下,单个机器上模型训练的较长运行时间促使解决方案设计者使用分布式系统,以增加并行度和I/O带宽总量,因为复杂应用程序所需的训练数据可以很容易就达到TB级。
在其他情况下,当数据本身是分布式的或量太大而不能存储在单个机器上时,集中式解决方案甚至不可取。例如,大型企业对存储在不同位置的数据进行事务处理,或者由于数据量太大而无法移动和集中。
为了使这些类型的数据集可以作为机器学习问题的训练数据被访问,必须选择并实现能够并行计算、适应多种数据分布和拥有故障恢复能力的算法。
近年来,机器学习技术得到了广泛应用。虽然出现了各种相互竞争的方法和算法,但使用的数据表示在结构上非常相似。机器学习工作中的大部分计算都是关于向量、矩阵或张量的基本转换,这些都是线性代数中常见的问题。
几十年来,对这种操作进行优化的需求一直是高性能计算(High Performance Computing,HPC)领域高度活跃的研究方向。因此,一些来自HPC社区的技术和库(例如,BLAS或MPI)已经被机器学习社区成功地采用并集成到系统中。
与此同时,HPC社区已经确定机器学习是一种新兴的高价值工作负载,并开始将HPC方法应用于机器学习。
Coates等人在他们的商用高性能计算(COTSHPC)系统上用短短三天训练了一个含有10亿个参数的网络。
You等人于2017年提出在Intel的Knights Landing上优化神经网络的训练,Knights Landing是一种为高性能计算应用设计的芯片。
Kurth等人于2017年演示了深度学习问题(如提取天气模式)是如何在大型并行HPC系统上进行优化和扩展的。
Yan等人于2016年提出通过借用HPC的轻量级分析等技术建模工作负载需求,可解决在云计算基础设施上调度深度神经网络应用的挑战。
Li等人于2017年研究了深度神经网络在加速器上运行时针对硬件错误的恢复特性(加速器经常部署在主要的高性能计算系统中)。
同其他大规模计算挑战一样,我们有两种基本不同且互补的方式来加速工作负载:向一台机器添加更多资源(垂直扩展,比如GPU/TPU计算核心的不断提升),向系统添加更多节点(水平扩展,成本低)。
传统的超级计算机、网格和云之间的界限越来越模糊,尤其在涉及机器学习等高要求的工作负载的最佳执行环境时。例如,GPU和加速器在主要的云数据中心中更加常见。因此,机器学习工作负载的并行化对大规模实现可接受的性能至关重要。然而,当从集中式解决方案过渡到分布式系统时,分布式计算在性能、可伸缩性、故障弹性或安全性方面面临严峻挑战。
02 分布式机器学习概述
由于每种算法都有独特的通信模式,因此设计一个能够有效分布常规机器学习的通用系统是一项挑战。尽管目前分布式机器学习有各种不同的概念和实现,但我们将介绍一个覆盖整个设计空间的公共架构。一般来说,机器学习问题可以分为训练阶段和预测阶段(见图1-5)。
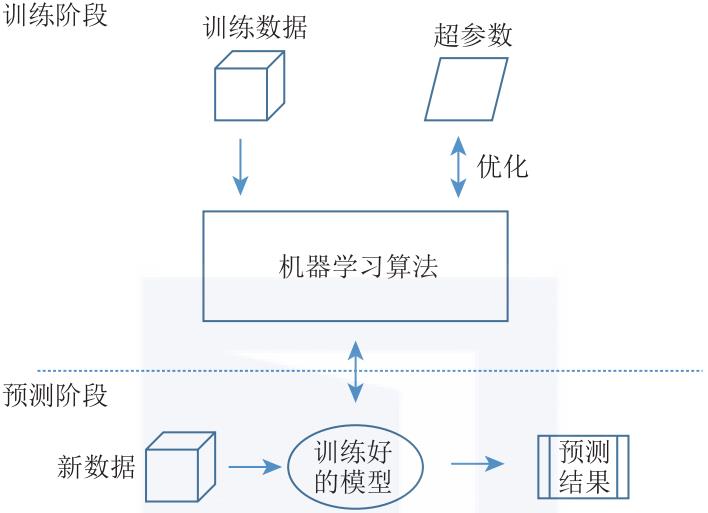
▲图1-5 机器学习结构。在训练阶段,使用训练数据和调整超参数对ML模型进行优化。然后,将训练好的模型部署到系统中,为输入的新数据提供预测
训练阶段包括训练一个机器学习模型,通过输入大量的训练数据,并使用常用的ML算法,如进化算法(Evolutionary Algorithm,EA)、基于规则的机器学习算法(Rule-based Machine Learning algorithm,比如决策树和关联规则)、主题模型(Topic Model,TM)、矩阵分解(Matrix Factorization)和基于随机梯度下降(Stochastic Gradient Descent,SGD)的算法等,进行模型更新。
除了为给定的问题选择一个合适的算法之外,我们还需要为所选择的算法进行超参数调优。训练阶段的最终结果是获得一个训练模型。预测阶段是在实践中部署经过训练的模型。经过训练的模型接收新数据(作为输入),并生成预测(作为输出)。
虽然模型的训练阶段通常需要大量的计算,并且需要大量的数据集,但是可以用较少的计算能力来执行推理。训练阶段和预测阶段不是相互排斥的。增量学习(Incremental learning)将训练阶段和预测阶段相结合,利用预测阶段的新数据对模型进行连续训练。
当涉及分布式时,我们可以用两种不同的方法将问题划分到所有机器上,即数据或模型并行(见图1-6)。这两种方法也可以同时应用。
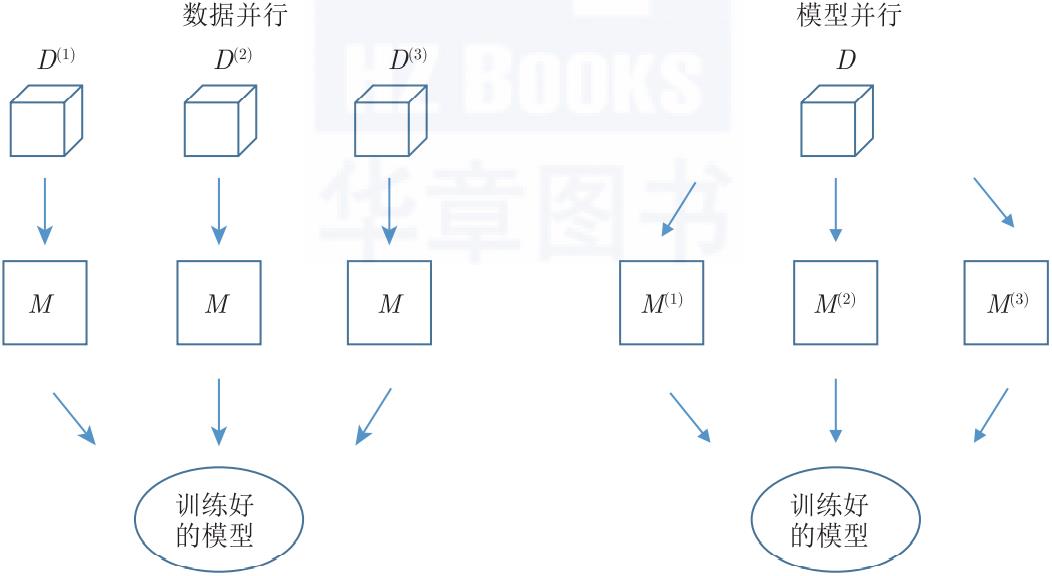
▲图1-6 分布式机器学习中的并行性。数据并行性是在训练数据集的不同子集上训练同一模型的多个实例,而模型并行性是将单个模型的并行路径分布到多个节点上
在数据并行(Data Parallel)方法中,系统中有多少工作节点,数据就被分区多少次,然后所有工作节点都会对不同的数据集应用相同的算法。相同的模型可用于所有工作节点(通过集中化或复制),因此可以自然地产生单个一致的输出。该方法可用于在数据样本上满足独立同分布假设的每个ML算法(即大多数ML算法)。
在模型并行(Model Parallel)方法中,整个数据集的精确副本由工作节点处理,工作节点操作模型的不同部分。因此,模型是所有模型部件的聚合。模型并行方法不能自动应用于每一种机器学习算法,因为模型参数通常不能被分割。
一种选择是训练相同或相似模型的不同实例,并使用集成之类的方法(如Bagging、Boosting等)聚合所有训练过的模型的输出。最终的架构决策是分布式机器学习系统的拓扑结构。组成分布式系统的不同节点需要通过特定的体系结构模式进行连接,以实现丰富的功能。这是一个常见的任务。然而,模式的选择对节点可以扮演的角色、节点之间的通信程度以及整个部署的故障恢复能力都有影响。
图1-7显示了4种可能的拓扑,符合Baran对分布式通信网络的一般分类。集中式结构(图1-7a)采用一种严格的分层方法进行聚合,它发生在单个中心位置。去中心化的结构允许中间聚合,当聚合被广播到所有节点时(如树拓扑),复制模型会不断更新(图1-7b),或者使用在多个参数服务器上分片的分区模型(图1-7c)。完全分布式结构(图1-7d)由独立的节点网络组成,这些节点将解决方案集成在一起,并且每个节点没有被分配特定的角色。

▲图1-7 分布式机器学习拓扑结构
03 分布式机器学习与联邦学习的共同发展
分布式机器学习发展到现在,也产生了隐私保护的一些需求,从而与联邦学习产生了一些内容上的交叉。常见的加密方法,如安全多方计算、同态计算、差分隐私等也逐渐应用在分布式机器学习中。总的来说,联邦学习是利用分布式资源协同训练机器学习模型的一种有效方法。
联邦学习是一种分布式机器学习方法,其中多个用户协同训练一个模型,同时保持原始数据分散,而不移动到单个服务器或数据中心。在联邦学习中,原始数据或基于原始数据进行安全处理生成的数据被用作训练数据。联邦学习只允许在分布式计算资源之间传输中间数据,同时避免传输训练数据。分布式计算资源是指终端用户的移动设备或多个组织的服务器。
联邦学习将代码引入数据,而不是将数据引入代码,从技术上解决了隐私、所有权和数据位置的基本问题。这样,联邦学习可以使多个用户在满足合法数据限制的同时协同训练一个模型。
本文摘编自《联邦学习:算法详解与系统实现》(ISBN:978-7-111-70349-5),经出版方授权发布。

延伸阅读《联邦学习:算法详解与系统实现》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:本书首先介绍联邦学习的定义和发展历史,按类别介绍联邦学习算法和发展现状,介绍联邦学习的应用场景,以及相关安全机器学习的技术。然后我们将介绍新的最前沿的联邦学习算法,用京东数科系统作为实例,对联邦学习系统构建和实现进行讲解。最后我们将介绍京东数科自研的基于区块链的联邦学习技术。
关于作者:薄列峰,京东科技集团副总裁、硅谷研发部负责人。曾担任包括Neu-rIPS、CVPR、ICCV、ECCV、AAAI、SDM等在内的多个顶级人工智能会议程序委员会委员。在国际顶级会议和期刊上合计发表论文80余篇,论文被引用10186次,H指数44。其博士学位论文荣获国内百篇优秀博士论文奖,RGB-D物体识别论文荣获机器人领域学术会议ICRA最佳计算机视觉论文奖。
黄恒,大数据、机器学习、人工智能等领域的国际学术带头人,美国匹兹堡大学电子及计算机工程系杰出讲座终身教授,AIMBE Fellow。作为会议程序主席或主席团成员,组织了超过20个国际学术会议。在国际顶级会议和期刊上发表了超过220篇文章,文章引用超过18000次,作为项目负责人领导了超过20个国际领先的科研项目。
顾松庠,计算机博士,京东科技联邦学习部负责人。对机器学习算法和大规模并行系统有深入研究,曾在美国FDA任高级机器学习及统计科学家,建设放射成像医疗仪器的评价体系;先后加入 WalmartLabs和Linkedln公司,负责机器学习平台架构设计。2018年加入京东科技,并带领多个团队先后建设了智能客服、知识图谱和联邦学习系统。
陈彦卿,京东技术总监,毕业于北京大学,并在纽约州立大学石溪分校获得计算机博士学位。作为排头兵投身联邦学习领域,探究加密信息的合理应用,坚信面向隐私保护的机器学习技术将引领未来。

刷刷视频👇
▲人工智能、机器学习、深度学习的关系,终于有人讲明白了
直播预告👇

干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
以上是关于终于有人把分布式机器学习讲明白了的主要内容,如果未能解决你的问题,请参考以下文章