maxwell解析mysql的binlog数据并保存到kafka使用
Posted 捡黄金的少年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了maxwell解析mysql的binlog数据并保存到kafka使用相关的知识,希望对你有一定的参考价值。
通过maxwell来实现binlog的实时解析,实现数据的实时同步
1、mysql创建一个maxwell用户
为mysql添加一个普通用户maxwell,因为maxwell这个软件默认用户使用的是maxwell这个用户,
进入mysql客户端,然后执行以下命令,进行授权
mysql -u root -p
set global validate_password_policy=LOW;
set global validate_password_length=6;
CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
flush privileges;
2:开启mysql的binlog机制
sudo vim /etc/my.cnf
添加或修改以下三行配置
log-bin= /var/lib/mysql/mysql-bin
binlog-format=ROW
server_id=1
数据库的服务器执行以下命令重启mysql服务:
sudo service mysqld restart
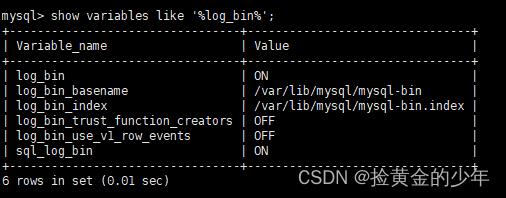
验证是否开启binlog
mysql -u root -p
show variables like '%log_bin%';
3、安装maxwell并启动
安装包地址
https://github.com/zendesk/maxwell/releases/download/v1.21.1/maxwell-1.21.1.tar.gz
1、解压到指定文件夹
cd /kkb/soft
tar -zxf maxwell-1.21.1.tar.gz -C /kkb/install/
2、修改配置文件
producer=kafka
kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092host=node03
user=maxwell
password=123456kafka_topic=maxwell_kafka
一定要注意:一定要保证我们使用maxwell用户和123456密码能够连接上mysql数据库
3、启动并创建kafka的topic
kafka-topics.sh --create --topic maxwell_kafka --partitions 3 --replication-factor 2 --zookeeper node01:2181
4、启动maxwell
cd /kkb/install/maxwell-1.21.1
bin/maxwell
5、测试是否成功
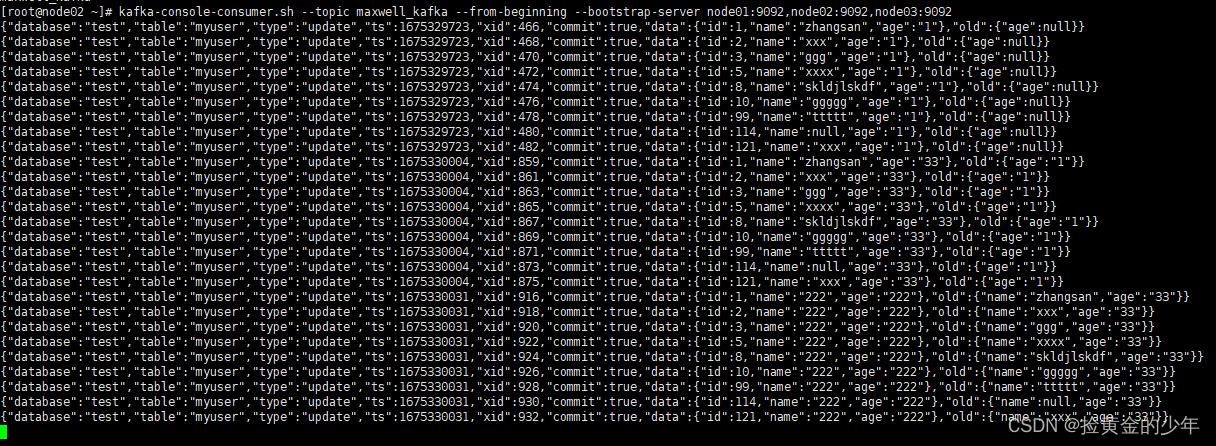
kafka-console-consumer.sh --topic maxwell_kafka --from-beginning --bootstrap-server node01:9092,node02:9092,node03:9092
创建mysql表并插入修改数据
CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `test`;
DROP TABLE IF EXISTS `myuser`;CREATE TABLE `myuser` (
`id` int(12) NOT NULL,
`name` varchar(32) DEFAULT NULL,
`age` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `myuser`(`id`,`name`,`age`) values (1,'zhangsan',NULL),(2,'xxx',NULL),(3,'ggg',NULL),(5,'xxxx',NULL),(8,'skldjlskdf',NULL),(10,'ggggg',NULL),(99,'ttttt',NULL),(114,NULL,NULL),(121,'xxx',NULL);
kafka中消费的json数据如下
4、插入到kafka的不同分区
由于maxwell(使用的分区策略是 dbname.hashCode % numPartitions )采用的是不同库的hashcode的值,对分区数目取模,得到数据存放的分区,这就很容易造成数据倾斜的问题,如一个库中数据很多,只分到同一个分区,所以我这里采用对主键取模的方式来均衡数据。
创建的配置文件如下
cd /kkb/install/maxwell-1.21.1
vim travel.properties
producer_partition_by=primary_key 分区策略,依据数据的主键分割
filter=exclude:*.*, include: 过滤数据,exclude:*.*表示排除所有的库表,include:表示只包含这后面的库表
log_level=INFO
producer=kafka
kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
host=node03.kaikeba.com
user=maxwell
password=123456
producer_ack_timeout = 600000
port=3306
######### output format stuff ###############
output_binlog_position=ture
output_server_id=true
output_thread_id=ture
output_commit_info=true
output_row_query=true
output_ddl=false
output_nulls=true
output_xoffset=true
output_schema_id=true
######### output format stuff ###############
kafka_topic= veche
kafka_partition_hash=murmur3
kafka_key_format=hash
kafka.compression.type=snappy
kafka.retries=5
kafka.acks=all
producer_partition_by=primary_key
############ kafka stuff #############
############## misc stuff ###########
bootstrapper=async
############## misc stuff ##########
############## filter ###############
filter=exclude:*.*, include: travel.order_info_201904,include: travel.order_info_201905,include: travel.order_info_201906,include: travel.order_info_201907,include: travel.order_info_201908,include: travel.order_info_201906,include: travel.order_info_201910,include: travel.order_info_201911,include: travel.order_info_201912,include: travel.renter_info,include: travel.driver_info ,include: travel.opt_alliance_business
############## filter ###############
以上是关于maxwell解析mysql的binlog数据并保存到kafka使用的主要内容,如果未能解决你的问题,请参考以下文章