Django ORM数据库查询操作
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django ORM数据库查询操作相关的知识,希望对你有一定的参考价值。
Django ORM数据库查询操作
基础条件查询
1 基本查询
get 查询单一结果,如果不存在会抛出 模型类.DoesNotExist异常。
all 查询多个结果。
count 查询结果数量。
>>> BookInfo.objects.get(id=1)
<BookInfo: 射雕英雄传>
>>> BookInfo.objects.get(pk=2)
<BookInfo: 天龙八部>
>>> BookInfo.objects.get(pk=20)
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/home/python/.virtualenvs/py3_django_1.11/lib/python3.5/site-packages/django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "/home/python/.virtualenvs/py3_django_1.11/lib/python3.5/site-packages/django/db/models/query.py", line 380, in get
self.model._meta.object_name
book.models.DoesNotExist: BookInfo matching query does not exist.
>>> BookInfo.objects.all()
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 雪山飞狐>]>
>>> BookInfo.objects.count()
4
2 过滤查询
实现SQL中的where功能,包括
- filter 过滤出多个结果
- exclude 排除掉符合条件剩下的结果
- get 过滤单一结果
对于过滤条件的使用,上述三个方法相同,故仅以 filter 进行讲解。
过滤条件的表达语法如下:
属性名称__比较运算符=值
# 属性名称和比较运算符间使用两个下划线,所以属性名不能包括多个下划线
查询编号为1的图书
查询书名包含'湖'的图书
查询书名以'部'结尾的图书
查询书名为空的图书
查询编号为1或3或5的图书
查询编号大于3的图书
查询1980年发表的图书
查询1990年1月1日后发表的图书
1 )相等
exact :表示判等。
例:查询编号为1的图书。
BookInfo.objects.filter(id__exact=1)
可简写为:
BookInfo.objects.filter(id=1)
2 )模糊查询
contains :是否包含。
说明:如果要包含%无需转义,直接写即可。
例:查询书名包含’传’的图书。
BookInfo.objects.filter(name__contains='传')
<QuerySet [<BookInfo: 射雕英雄传>]>
startswith 、endswith:以指定值开头或结尾。
例:查询书名以’部’结尾的图书
>>> BookInfo.objects.filter(name__endswith='部')
<QuerySet [<BookInfo: 天龙八部>]>
以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith.
3 ) 空查询
isnull :是否为null。
例:查询书名为空的图书。
>>> BookInfo.objects.filter(name__isnull=True)
<QuerySet []>
4 ) 范围查询
in :是否包含在范围内。
例:查询编号为1或3或5的图书
>>> BookInfo.objects.filter(id__in=[1,3,5])
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>]>
5 )比较查询
- gt 大于 (greater then)
- gte 大于等于 (greater then equal)
- lt 小于 (less then)
- lte 小于等于 (less then equal)
例:查询编号大于3的图书
BookInfo.objects.filter(id__gt=3)
不等于的运算符,使用exclude()过滤器。
例:查询编号不等于3的图书
>>> BookInfo.objects.filter(id__gt=3)
<QuerySet [<BookInfo: 雪山飞狐>]>
6 )日期查询
year 、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询1980年发表的图书。
>>> BookInfo.objects.filter(pub_date__year=1980)
<QuerySet [<BookInfo: 射雕英雄传>]>
例:查询1990年1月1日后发表的图书。
>>> BookInfo.objects.filter(pub_date__gt='1990-1-1')
<QuerySet [<BookInfo: 笑傲江湖>]>
F和Q对象
F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 答:使用F对象,被定义在django.db.models中。
语法如下:
F(属性名)
例:查询阅读量大于等于评论量的图书。
>>> from django.db.models import F
>>> BookInfo.objects.filter(readcount__gt=F('commentcount'))
<QuerySet [<BookInfo: 雪山飞狐>]>
可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。
>>> BookInfo.objects.filter(readcount__gt=F('commentcount')*2)
<QuerySet [<BookInfo: 雪山飞狐>]>
Q对象
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询阅读量大于20,并且编号小于3的图书。
>>> BookInfo.objects.filter(readcount__gt=20,id__lt=3)
<QuerySet [<BookInfo: 天龙八部>]>
或者
>>> BookInfo.objects.filter(readcount__gt=20).filter(id__lt=3)
<QuerySet [<BookInfo: 天龙八部>]>
如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)
例:查询阅读量大于20的图书,改写为Q对象如下。
BookInfo.objects.filter(Q(readcount__gt=20))
Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
例:查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
>>> BookInfo.objects.filter(Q(readcount__gt=20)|Q(id__lt=3))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。
>>> BookInfo.objects.filter(~Q(id=3))
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
聚合函数和排序函数
1. 聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括: Avg 平均, Count 数量, Max 最大, Min
最小, Sum 求和,被定义在django.db.models中。
例:查询图书的总阅读量。
>>> from django.db.models import Sum
>>> BookInfo.objects.aggregate(Sum('readcount'))
'readcount__sum': 126
注意aggregate的返回值是一个字典类型,格式如下:
'属性名__聚合类小写':值
如:'readcount__sum': 126
使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
BookInfo.objects.count()
注意count函数的返回值是一个数字。
2. 排序
使用 order_by 对结果进行排序
# 默认升序
>>> BookInfo.objects.all().order_by('readcount')
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 笑傲江湖>, <BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
# 降序
>>> BookInfo.objects.all().order_by('-readcount')
<QuerySet [<BookInfo: 雪山飞狐>, <BookInfo: 天龙八部>, <BookInfo: 笑傲江湖>, <BookInfo: 射雕英雄传>]>
关联查询
查询书籍为1的所有人物信息
查询人物为1的书籍信息
由一到多的访问语法:
一对应的模型类对象.多对应的模型类名小写_set 例:
>>> book = BookInfo.objects.get(id=1)
>>> book.peopleinfo_set.all()
<QuerySet [<PeopleInfo: 郭靖>, <PeopleInfo: 黄蓉>, <PeopleInfo: 黄药师>, <PeopleInfo: 欧阳锋>, <PeopleInfo: 梅超风>]>
由多到一的访问语法:
多对应的模型类对象.多对应的模型类中的关系类属性名 例:
person = PeopleInfo.objects.get(id=1)
person.book
<BookInfo: 射雕英雄传>
访问一对应的模型类关联对象的id语法:
多对应的模型类对象.关联类属性_id
例:
>>> person = PeopleInfo.objects.get(id=1)
>>> person.book_id
1
关联过滤查询
由多模型类条件查询一模型类数据:
语法如下:
关联模型类名小写__属性名__条件运算符=值
注 意:如果没有"__运算符"部分,表示等于。
查询图书,要求图书人物为"郭靖"
查询图书,要求图书中人物的描述包含"八"
例:
查询图书,要求图书人物为"郭靖"
>>> book = BookInfo.objects.filter(peopleinfo__name='郭靖')
>>> book
<QuerySet [<BookInfo: 射雕英雄传>]>
查询图书,要求图书中人物的描述包含"八"
>>> book = BookInfo.objects.filter(peopleinfo__description__contains='八')
>>> book
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>
由一模型类条件查询多模型类数据:
语法如下:
一模型类关联属性名__一模型类属性名__条件运算符=值
注意:如果没有"__运算符"部分,表示等于。
查询书名为"天龙八部"的所有人物
查询图书阅读量大于30的所有人物
例:
查询书名为"天龙八部"的所有人物。
>>> people = PeopleInfo.objects.filter(book__name='天龙八部')
>>> people
<QuerySet [<PeopleInfo: 乔峰>, <PeopleInfo: 段誉>, <PeopleInfo: 虚竹>, <PeopleInfo: 王语嫣>]>
查询图书阅读量大于30的所有人物
>>> people = PeopleInfo.objects.filter(book__readcount__gt=30)
>>> people
<QuerySet [<PeopleInfo: 乔峰>, <PeopleInfo: 段誉>, <PeopleInfo: 虚竹>, <PeopleInfo: 王语嫣>, <PeopleInfo: 胡斐>, <PeopleInfo: 苗若兰>, <PeopleInfo: 程灵素>, <PeopleInfo: 袁紫衣>]>
查询集QuerySet
1 概念
Django的ORM中存在查询集的概念。
查询集,也称查询结果集、QuerySet,表示从数据库中获取的对象集合。
当调用如下过滤器方法时,Django会返回查询集(而不是简单的列表):
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据。
- order_by():对结果进行排序。
对查询集可以再次调用过滤器进行过滤,如
>>> books = BookInfo.objects.filter(readcount__gt=30).order_by('pub_date')
>>> books
<QuerySet [<BookInfo: 天龙八部>, <BookInfo: 雪山飞狐>]>
也就意味着查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果。
从 SQL的角度讲,查询集与select语句等价,过滤器像where、limit、order by子句。
判断某一个查询集中是否有数据:
exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
2 两大特性
1)惰性执行
创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
例如,当执行如下语句时,并未进行数据库查询,只是创建了一个查询集books
books = BookInfo.objects.all()
继续执行遍历迭代操作后,才真正的进行了数据库的查询
for book in books:
print(book.name)
2)缓存
使用同一个查询集,第一次使用时会发生数据库的查询,然后Django会把结果缓存下来,再次使用这个查询集时会使用缓存的数据,减少了数据库的查询次数。
情况一:如下是两个查询集,无法重用缓存,每次查询都会与数据库进行一次交互,增加了数据库的负载。
from book.models import BookInfo
[book.id for book in BookInfo.objects.all()]
[book.id for book in BookInfo.objects.all()]


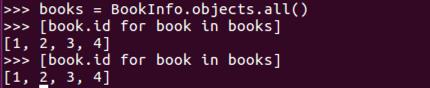
情 况二:经过存储后,可以重用查询集,第二次使用缓存中的数据。
books=BookInfo.objects.all()
[book.id for book in books]
[book.id for book in books]

3 限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:获取第1、2项,运行查看。
>>> books = BookInfo.objects.all()[0:2]
>>> books
<QuerySet [<BookInfo: 射雕英雄传>, <BookInfo: 天龙八部>]>
4.分页
#查询数据
books = BookInfo.objects.all()
#导入分页类
from django.core.paginator import Paginator
#创建分页实例
paginator=Paginator(books,2)
#获取指定页码的数据
page_skus = paginator.page(1)
#获取分页数据
total_page=paginator.num_pages
加油!
感谢!
努力!
以上是关于Django ORM数据库查询操作的主要内容,如果未能解决你的问题,请参考以下文章